《深入理解Spark:核心思想与源码分析》(第2章)
《深入理解Spark:核心思想与源码分析》一书前言的内容请看链接《深入理解SPARK:核心思想与源码分析》一书正式出版上市
《深入理解Spark:核心思想与源码分析》一书第一章的内容请看链接《第1章 环境准备》
本文主要展示本书的第2章内容:
Spark设计理念与基本架构
“若夫乘天地之正,而御六气之辩,以游无穷者,彼且恶乎待哉?”
——《庄子·逍遥游》
n 本章导读:
上一章,介绍了Spark环境的搭建,为方便读者学习Spark做好准备。本章首先从Spark产生的背景开始,介绍Spark的主要特点、基本概念、版本变迁。然后简要说明Spark的主要模块和编程模型。最后从Spark的设计理念和基本架构入手,使读者能够对Spark有宏观的认识,为之后的内容做一些准备工作。
Spark是一个通用的并行计算框架,由加州伯克利大学(UCBerkeley)的AMP实验室开发于2009年,并于2010年开源。2013年成长为Apache旗下为大数据领域最活跃的开源项目之一。Spark也是基于map reduce 算法模式实现的分布式计算框架,拥有Hadoop MapReduce所具有的优点,并且解决了Hadoop MapReduce中的诸多缺陷。
2.1 初识Spark
2.1.1 Hadoop MRv1的局限
早在Hadoop1.0版本,当时采用的是MRv1版本的MapReduce编程模型。MRv1版本的实现都封装在org.apache.hadoop.mapred包中,MRv1的Map和Reduce是通过接口实现的。MRv1包括三个部分:
q 运行时环境(JobTracker和TaskTracker);
q 编程模型(MapReduce);
q 数据处理引擎(Map任务和Reduce任务)。
MRv1存在以下不足:
q 可扩展性差:在运行时,JobTracker既负责资源管理又负责任务调度,当集群繁忙时,JobTracker很容易成为瓶颈,最终导致它的可扩展性问题。
q 可用性差:采用了单节点的Master,没有备用Master及选举操作,这导致一旦Master出现故障,整个集群将不可用。
q 资源利用率低:TaskTracker 使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,Hadoop 调度器负责将各个TaskTracker 上的空闲slot 分配给Task 使用。一些Task并不能充分利用slot,而其他Task也无法使用这些空闲的资源。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。有时会因为作业刚刚启动等原因导致MapTask很多,而Reduce Task任务还没有调度的情况,这时Reduce slot也会被闲置。
q 不能支持多种MapReduce框架:无法通过可插拔方式将自身的MapReduce框架替换为其他实现,如Spark、Storm等。
MRv1的示意如图2-1。

图2-1 MRv1示意图[1]
Apache为了解决以上问题,对Hadoop升级改造,MRv2最终诞生了。MRv2中,重用了MRv1中的编程模型和数据处理引擎。但是运行时环境被重构了。JobTracker被拆分成了通用的资源调度平台(ResourceManager,简称RM)和负责各个计算框架的任务调度模型(ApplicationMaste,简称AM)。MRv2中MapReduce的核心不再是MapReduce框架,而是YARN。在以YARN为核心的MRv2中,MapReduce框架是可插拔的,完全可以替换为其他MapReduce实现,比如Spark、Storm等。MRv2的示意如图2-2所示。

图2-2 MRv2示意图
Hadoop MRv2虽然解决了MRv1中的一些问题,但是由于对HDFS的频繁操作(包括计算结果持久化、数据备份及shuffle等)导致磁盘I/O成为系统性能的瓶颈,因此只适用于离线数据处理,而不能提供实时数据处理能力。
2.1.2 Spark使用场景
Hadoop常用于解决高吞吐、批量处理的业务场景,例如离线计算结果用于浏览量统计。如果需要实时查看浏览量统计信息,Hadoop显然不符合这样的要求。Spark通过内存计算能力极大地提高了大数据处理速度,满足了以上场景的需要。此外,Spark还支持SQL查询,流式计算,图计算,机器学习等。通过对Java、Python、Scala、R等语言的支持,极大地方便了用户的使用。
2.1.3 Spark的特点
Spark看到MRv1的问题,对MapReduce做了大量优化,总结如下:
q 快速处理能力。随着实时大数据应用越来越多,Hadoop作为离线的高吞吐、低响应框架已不能满足这类需求。Hadoop MapReduce的Job将中间输出和结果存储在HDFS中,读写HDFS造成磁盘IO成为瓶颈。Spark允许将中间输出和结果存储在内存中,节省了大量的磁盘IO。同时Spark自身的DAG执行引擎也支持数据在内存中的计算。Spark官网声称性能比Hadoop快100倍,如图2-3所示。即便是内存不足需要磁盘IO,其速度也是Hadoop的10倍以上。

图2-3 Hadoop与Spark执行逻辑回归时间比较
q 易于使用。Spark现在支持Java、Scala、Python和R等语言编写应用程序,大大降低了使用者的门槛。自带了80多个高等级操作符,允许在Scala,Python,R的shell中进行交互式查询。
q 支持查询。Spark支持SQL及Hive SQL对数据查询。
q 支持流式计算。与MapReduce只能处理离线数据相比,Spark还支持实时的流计算。Spark依赖Spark Streaming对数据进行实时的处理,其流式处理能力还要强于Storm。
q 可用性高。Spark自身实现了Standalone部署模式,此模式下的Master可以有多个,解决了单点故障问题。此模式完全可以使用其他集群管理器替换,比如YARN、Mesos、EC2等。
q 丰富的数据源支持。Spark除了可以访问操作系统自身的文件系统和HDFS,还可以访问Cassandra, HBase, Hive, Tachyon以及任何Hadoop的数据源。这极大地方便了已经使用HDFS、Hbase的用户顺利迁移到Spark。
2.2 Spark基础知识
1.版本变迁
经过4年多的发展,Spark目前的版本是1.4.1。我们简单看看它的版本发展过程。
1) Spark诞生于UCBerkeley的AMP实验室(2009)。
2) Spark正式对外开源(2010)。
3) Spark 0.6.0版本发布(2012-10-15),大范围的性能改进,增加了一些新特性,并对Standalone部署模式进行了简化。
4) Spark 0.6.2版本发布(2013-02-07),解决了一些bug,并增强了系统的可用性。
5) Spark 0.7.0版本发布(2013-02-27),增加了更多关键特性,例如:Python API、Spark Streaming的alpha版本等。
6) Spark 0.7.2版本发布(2013-06-02),性能改进并解决了一些bug,新的API使用的例子。
7) Spark接受进入Apache孵化器(2013-06-21)。
8) Spark 0.7.3版本发布(2013-07-16),一些bug的解决,更新Spark Streaming API等。
9) Spark 0.8.0版本发布(2013-09-25),一些新功能及可用性改进。
10) Spark 0.8.1版本发布(2013-12-19),支持Scala 2.9,YARN 2.2,Standalone部署模式下调度的高可用性,shuffle的优化等。
11) Spark 0.9.0版本发布(2014-02-02),增加了GraphX,机器学习新特性,流式计算新特性,核心引擎优化(外部聚合、加强对YARN的支持)等。
12) Spark 0.9.1版本发布(2014-04-09),增加使用YARN的稳定性,改进Scala和Python API的奇偶性。
13) Spark 1.0.0版本发布(2014-05-30),增加了Spark SQL、MLlib、GraphX和Spark Streaming都增加了新特性并进行了优化。Spark核心引擎还增加了对安全YARN集群的支持。
14) Spark 1.0.1版本发布(2014-07-11),增加了Spark SQL的新特性和堆JSON数据的支持等。
15) Spark 1.0.2版本发布(2014-08-05),Spark核心API及Streaming,Python,MLlib的bug修复。
16) Spark 1.1.0版本发布(2014-09-11)。
17) Spark 1.1.1版本发布(2014-11-26),Spark核心API及Streaming,Python,SQL,GraphX和MLlib的bug修复。
18) Spark 1.2.0版本发布(2014-12-18)。
19) Spark 1.2.1版本发布(2015-02-09),Spark核心API及Streaming,Python,SQL,GraphX和MLlib的bug修复。
20) Spark 1.3.0版本发布(2015-03-13)。
21) Spark 1.4.0版本发布(2015-06-11)。
22) Spark 1.4.1版本发布(2015-07-15),DataFrame API及Streaming,Python,SQL和MLlib的bug修复。
2.基本概念
要想对Spark有整体性的了解,推荐读者阅读Matei Zaharia的Spark论文。此处笔者先介绍Spark中的一些概念:
q RDD(resillient distributed dataset):弹性分布式数据集。
q Task:具体执行任务。Task分为ShuffleMapTask和ResultTask两种。ShuffleMapTask和ResultTask分别类似于Hadoop中的Map,Reduce。
q Job:用户提交的作业。一个Job可能由一到多个Task组成。
q Stage:Job分成的阶段。一个Job可能被划分为一到多个Stage。
q Partition:数据分区。即一个RDD的数据可以划分为多少个分区。
q NarrowDependency:窄依赖。即子RDD依赖于父RDD中固定的Partition。NarrowDependency分为OneToOneDependency和RangeDependency两种。
q ShuffleDependency:shuffle依赖,也称为宽依赖。即子RDD对父RDD中的所有Partition都有依赖。
q DAG(Directed Acycle graph):有向无环图。用于反映各RDD之间的依赖关系。
3.Scala与Java的比较
Spark为什么要选择Java作为开发语言?笔者不得而知。如果能对二者进行比较,也许能看出一些端倪。表2-1列出了对Scala与Java的比较。
表2-1 Scala与Java的比较
|
|
Scala |
Java |
|
语言类型 |
面向函数为主,兼有面向对象 |
面向对象(Java8也增加了lambda函数编程) |
|
简洁性 |
非常简洁 |
不简洁 |
|
类型推断 |
丰富的类型推断,例如深度和链式的类型推断、 duck type 、隐式类型转换等,但也因此增加了编译时长 |
少量的类型推断 |
|
可读性 |
一般,丰富的语法糖导致的各种奇幻用法,例如方法签名 |
好 |
|
学习成本 |
较高 |
一般 |
|
语言特性 |
非常丰富的语法糖和更现代的语言特性,例如 Option 、模式匹配、使用空格的方法调用 |
丰富 |
|
并发编程 |
使用Actor的消息模型 |
使用阻塞、锁、阻塞队列等 |
通过以上比较似乎仍然无法判断Spark选择开发语言的原因。由于函数式编程更接近计算机思维,因此便于通过算法从大数据中建模,这应该更符合Spark作为大数据框架的理念吧!
2.3 Spark基本设计思想
2.3.1 模块设计
整个Spark主要由以下模块组成:
q Spark Core:Spark的核心功能实现,包括:SparkContext的初始化(Driver Application通过SparkContext提交)、部署模式、存储体系、任务提交与执行、计算引擎等。
q Spark SQL:提供SQL处理能力,便于熟悉关系型数据库操作的工程师进行交互查询。此外,还为熟悉Hadoop的用户提供Hive SQL处理能力。
q Spark Streaming:提供流式计算处理能力,目前支持Kafka、Flume、Twitter、MQTT、ZeroMQ、Kinesis和简单的TCP套接字等数据源。此外,还提供窗口操作。
q GraphX:提供图计算处理能力,支持分布式, Pregel提供的API可以解决图计算中的常见问题。
q MLlib:提供机器学习相关的统计、分类、回归等领域的多种算法实现。其一致的API接口大大降低了用户的学习成本。
Spark SQL、Spark Streaming、GraphX、MLlib的能力都是建立在核心引擎之上,如图2-4。

图2-4 Spark各模块依赖关系
1. Spark核心功能
Spark Core提供Spark最基础与最核心的功能,主要包括:
q SparkContext:通常而言,Driver Application的执行与输出都是通过SparkContext来完成的,在正式提交Application之前,首先需要初始化SparkContext。SparkContext隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、测量系统、文件服务、Web服务等内容,应用程序开发者只需要使用SparkContext提供的API完成功能开发。SparkContext内置的DAGScheduler负责创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等功能。内置的TaskScheduler负责资源的申请、任务的提交及请求集群对任务的调度等工作。
q 存储体系:Spark优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘I/O,提升了任务执行的效率,使得Spark适用于实时计算、流式计算等场景。此外,Spark还提供了以内存为中心的高容错的分布式文件系统Tachyon供用户进行选择。Tachyon能够为Spark提供可靠的内存级的文件共享服务。
q 计算引擎:计算引擎由SparkContext中的DAGScheduler、RDD以及具体节点上的Executor负责执行的Map和Reduce任务组成。DAGScheduler和RDD虽然位于SparkContext内部,但是在任务正式提交与执行之前将Job中的RDD组织成有向无关图(简称DAG)、并对Stage进行划分决定了任务执行阶段任务的数量、迭代计算、shuffle等过程。
2. Spark扩展功能
为了扩大应用范围,Spark陆续增加了一些扩展功能,主要包括:
q Spark SQL:由于SQL具有普及率高、学习成本低等特点,为了扩大Spark的应用面,因此增加了对SQL及Hive的支持。Spark SQL的过程可以总结为:首先使用SQL语句解析器(SqlParser)将SQL转换为语法树(Tree),并且使用规则执行器(RuleExecutor)将一系列规则(Rule)应用到语法树,最终生成物理执行计划并执行的过程。其中,规则包括语法分析器(Analyzer)和优化器(Optimizer)。Hive的执行过程与SQ类似。
q Spark Streaming:Spark Streaming与Apache Storm类似,也用于流式计算。Spark Streaming支持Kafka、Flume、Twitter、MQTT、ZeroMQ、Kinesis和简单的TCP套接字等多种数据输入源。输入流接收器(Receiver)负责接入数据,是接入数据流的接口规范。Dstream是Spark Streaming中所有数据流的抽象,Dstream可以被组织为DStream Graph。Dstream本质上由一系列连续的RDD组成。
q GraphX:Spark提供的分布式图计算框架。GraphX主要遵循整体同步并行计算模式(Bulk Synchronous Parallell,简称BSP)下的Pregel模型实现。GraphX提供了对图的抽象Graph,Graph由顶点(Vertex)、边(Edge)及继承了Edge的EdgeTriplet(添加了srcAttr和dstAttr用来保存源顶点和目的顶点的属性)三种结构组成。GraphX目前已经封装了最短路径、网页排名、连接组件、三角关系统计等算法的实现,用户可以选择使用。
q MLlib:Spark提供的机器学习框架。机器学习是一门涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域的交叉学科。MLlib目前已经提供了基础统计、分类、回归、决策树、随机森林、朴素贝叶斯、保序回归、协同过滤、聚类、维数缩减、特征提取与转型、频繁模式挖掘、预言模型标记语言、管道等多种数理统计、概率论、数据挖掘方面的数学算法。
2.3.2 Spark模型设计
1. Spark编程模型
Spark 应用程序从编写到提交、执行、输出的整个过程如图2-5所示,图中描述的步骤如下:
1) 用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driver application程序。此外SQLContext、HiveContext及StreamingContext对SparkContext进行封装,并提供了SQL、Hive及流式计算相关的API。
2) 使用SparkContext提交的用户应用程序,首先会使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。然后由DAGScheduler将任务转换为RDD并组织成DAG,DAG还将被划分为不同的Stage。最后由TaskScheduler借助ActorSystem将任务提交给集群管理器(Cluster Manager)。
3) 集群管理器(Cluster Manager)给任务分配资源,即将具体任务分配到Worker上,Worker创建Executor来处理任务的运行。Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。

图2-5 代码执行过程
2. Spark计算模型
RDD可以看做是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,如图2-6。RDD的迭代计算过程非常类似于管道。分区数量取决于partition数量的设定,每个分区的数据只会在一个Task中计算。所有分区可以在多个机器节点的Executor上并行执行。

图2-6 RDD计算模型
2.4 Spark基本架构
从集群部署的角度来看,Spark集群由以下部分组成:
q Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
q Worker:Spark的工作节点。对Spark应用程序来说,由集群管理器分配得到资源的Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager。
q Executor:执行计算任务的一线进程。主要负责任务的执行以及与Worker、Driver App的信息同步。
q Driver App:客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。
这些组成部分之间的整体关系如图2-7所示。
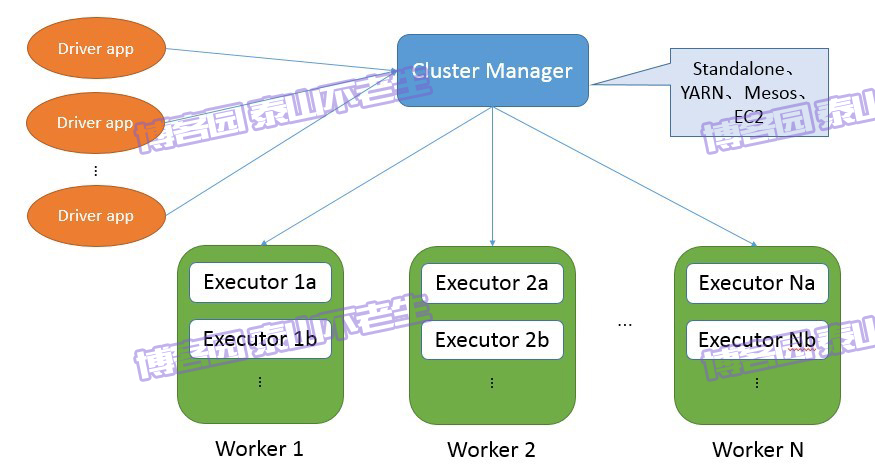
图2-7 Spark基本架构图
2.5 小结
每项技术的诞生都会由某种社会需求所驱动,Spark正是在实时计算的大量需求下诞生的。Spark借助其优秀的处理能力,可用性高,丰富的数据源支持等特点,在当前大数据领域变得火热,参与的开发者也越来越多。Spark经过几年的迭代发展,如今已经提供了丰富的功能。笔者相信,Spark在未来必将产生更耀眼的火花。
[1]图2-1和图2-2都来源自http://blog.chinaunix.net/uid-28311809-id-4383551.html。
后记:自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的《深入理解Spark:核心思想与源码分析》一书现在已经正式出版上市,目前亚马逊、京东、当当、天猫等网站均有销售,欢迎感兴趣的同学购买。我开始研究源码时的Spark版本是1.2.0,经过7个多月的研究和出版社近4个月的流程,Spark自身的版本迭代也很快,如今最新已经是1.6.0。目前市面上另外2本源码研究的Spark书籍的版本分别是0.9.0版本和1.2.0版本,看来这些书的作者都与我一样,遇到了这种问题。由于研究和出版都需要时间,所以不能及时跟上Spark的脚步,还请大家见谅。但是Spark核心部分的变化相对还是很少的,如果对版本不是过于追求,依然可以选择本书。

京东(现有满100减30活动):http://item.jd.com/11846120.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号