
写了一个flinkcdc的简单demo,大概说一下实现过程和建议点
架构图大致如下:
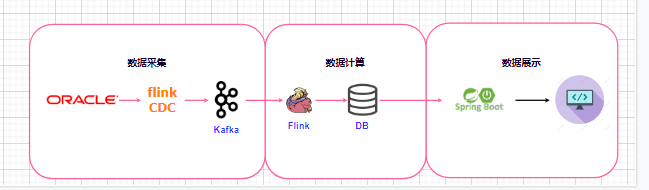
版本信息大致如下,具体版本信息根据自己的需求进行调整即可:
oracle:19c
flinkcdc:2.4.0
kafka:3.1.2
flink:1.15.4
mysql:8.0.27
springboot:2.5.6
实现需求:
1.使用flinkcdc采集oracle中的数据(历史数据+增量数据:含增删改)同步至kafka的某个topic中
2.使用flink消费kafka中的接收oracle同步数据的topic中的数据,并将数据sink到mysql数据库中
3.使用springboot程序读取mysql中的数据(根据需求写sql进行筛选)并在前台展示
架构中需要注意的几个点:
1.因为我的需求中需要同步到oracle的历史数据,所以在确定OracleSource的配置项中需要重点注意
2.oracle中的数据写入到kafka中,想要更好的在后续kafka的查数过程中数据更加具有可读性,我建议在配置OracleSource中使用自定义的反序列化器(其实我也是这么处理的)处理数据为自己想要的格式
3.自定义话数据格式后,后面插入mysql的JdbcSink中需要对获取的数据格式进行相应的处理
未完待续~~~~~~~~~~~~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~