

14. redis基础
redis
官方原版: https://redis.io/
中文官网:http://www.redis.cn
参考命令:http://doc.redisfans.com/
redis下载和安装
下载地址: https://github.com/MicrosoftArchive/redis/releases
启动内置客户端连接redis服务(Windows):
1.先启动服务端redis-server.exe
2.再启动客户端redis-cli.exe 就可以使用了
redis的配置
redis 安装成功以后,window下的配置文件保存在软件 安装目录下,如果是mac或者linux,则默认安装/etc/redis/redis.conf
1. redis的核心配置选项
-
绑定ip:如果需要远程访问,可将此⾏注释,或绑定⼀个真实ip
bind 127.0.0.1
-
端⼝,默认为6379
port 6379
-
是否以守护进程运⾏[这里的配置主要是linux和mac下面需要配置的]
- 如果以守护进程运⾏,则不会在命令⾏阻塞,类似于服务
- 如果以⾮守护进程运⾏,则当前终端被阻塞
- 设置为yes表示守护进程,设置为no表示⾮守护进程
- 推荐设置为yes
daemonize yes
-
数据⽂件
dbfilename dump.rdb
-
数据⽂件存储路径
dir .
-
⽇志⽂件
logfile "C:/tool/redis/redis-server.log"
-
数据库,默认有16个
database 16
-
主从复制,类似于双机备份。
slaveof
2. Redis的使用
Redis 是一个高性能的key-value数据格式的内存缓存,NoSQL数据库。
NOSQL:not only sql,泛指非关系型数据库。
关系型数据库: (mysql, oracle, sql server, sqlite)
1. 数据存放在表中,表之间有关系。
2. 通用的SQL操作语言。
3. 大部分支持事务。
非关系型数据库[ redis,hadoop,mangoDB]:
1. 没有数据表的概念,不同的nosql数据库存放数据位置不同。
2. nosql数据库没有通用的操作语言。
3. 基本不支持事务。 redis支持简单事务
redis:
内存型(数据存放在内存中)的非关系型(nosql)key-value(键值存储)数据库,
支持数据的持久化(注: 数据持久化时将数据存放到文件中,每次启动redis之后会先将文
件中数据加载到内存),经常用来做缓存(用来缓存一些经常用到的数据,提高读写速度)。
redis是一款基于CS架构的数据库,所以redis有客户端,也有服务端。
其中,客户端可以使用python等编程语言,也可以终端命令行工具
redis客户端连接服务器:
redis-cli -h `redis服务器ip` -p `redis服务器port`
redis数据类型
1. string类型:
字符串类型是 Redis 中最为基础的数据存储类型,它在 Redis 中是二进制安全的,也就是byte类型
最大容量是512M。
2. hash类型:
hash用于存储对象,对象的结构为属性、值,值的类型为string。
key:{
域:值[这里的值只能是字符串],
域:值,
域:值,
域:值,
...
}
3. list类型:
列表的元素类型为string。
key:[ 值1,值2,值3..... ]
4. set类型:
无序集合,元素为string类型,元素唯一不重复,没有修改操作。
{值1,值4,值3,值5}
5. zset类型:
有序集合,元素为string类型,元素唯一不重复,没有修改操作。
1. string
如果设置的键不存在则为添加,如果设置的键已经存在则修改
-
设置键值
set key value
-
例1:设置键为
name值为xiaoming的数据set name xiaoming

-
设置键值及过期时间,以秒为单位
setex key seconds value
-
例2:设置键为
aa值为aa过期时间为3秒的数据setex name 20 xiaoming
关于设置保存数据的有效期
# setex 添加保存数据到redis,同时设置有效期
格式:
setex key time value
# expire 给已有的数据重新设置有效期
格式:
expire key time
-
设置多个键值
mset key1 value1 key2 value2 ...
-
例3:设置键为
a1值为python、键为a2值为java、键为a3值为cmset a1 python a2 java a3 c
-
追加值
append key value
-
例4:向键为
a1中追加值hahaappend a1 haha
-
获取:根据键获取值,如果不存在此键则返回
nilget key
-
例5:获取键
name的值get name
-
根据多个键获取多个值
mget key1 key2 ...
-
例6:获取键
a1、a2、a3的值mget a1 a2 a3
2. 键操作
-
查找键,参数⽀持正则表达式
keys pattern
-
例1:查看所有键
keys *
-
例2:查看名称中包含
a的键keys a*
-
判断键是否存在,如果存在返回
1,不存在返回0exists key1
-
例3:判断键
a1是否存在exists a1
-
查看键对应的
value的类型type key
-
例4:查看键
a1的值类型,为redis⽀持的五种类型中的⼀种type a1
-
删除键及对应的值
del key1 key2 ...
-
例5:删除键
a2、a3del a2 a3
-
查看有效时间,以秒为单位
ttl key
-
例7:查看键
bb的有效时间ttl bb
3. hash
结构:
键key:{
域field:值value
}
-
设置单个属性
hset key field value
-
例1:设置键
user的属性name为xiaohonghset user name xiaohong
-
设置多个属性
hmset key field1 value1 field2 value2 ...
-
例2:设置键
u2的属性name为xiaohong、属性age为11hmset u2 name xiaohongage 11
-
获取指定键所有的属性
hkeys key
-
例3:获取键u2的所有属性
hkeys u2
-
获取⼀个属性的值
hget key field
-
例4:获取键
u2属性name的值hget u2 name
-
获取多个属性的值
hmget key field1 field2 ...
-
例5:获取键
u2属性name、age的值hmget u2 name age
-
获取所有属性的值
hvals key
-
例6:获取键
u2所有属性的值hvals u2
-
删除属性,属性对应的值会被⼀起删除
hdel key field1 field2 ...
-
例7:删除键
u2的属性agehdel u2 age
4. list
列表的元素类型为string
按照插⼊顺序排序
-
在左侧插⼊数据
lpush key value1 value2 ...
-
例1:从键为
a1的列表左侧加⼊数据a 、 b 、clpush a1 a b c
-
在右侧插⼊数据
rpush key value1 value2 ...
-
例2:从键为
a1的列表右侧加⼊数据0、1rpush a1 0 1
-
在指定元素的前或后插⼊新元素
linsert key before或after 现有元素 新元素
-
例3:在键为
a1的列表中元素b前加⼊3linsert a1 before b 3
从列表删除数据
lpush uu 1 2 3 4 # 列表插入数据
lrange uu 0 -1 # 遍历列表 -- 4, 3, 2, 1
lpop uu # 左侧删除
lrange uu 0 -1 # 遍历列表 -- 3, 2, 1
rpop uu # 右侧删除
lrange uu 0 -1 # 遍历列表 -- 3, 2
设置指定索引位置的元素值
-
索引从左侧开始,第⼀个元素为0
-
索引可以是负数,表示尾部开始计数,如
-1表示最后⼀个元素lset key index value
-
例5:修改键为
a1的列表中下标为1的元素值为zlset a 1 z
-
删除指定元素
- 将列表中前
count次出现的值为value的元素移除 - count > 0: 从头往尾移除
- count < 0: 从尾往头移除
- count = 0: 移除所有
lrem key count value

- 将列表中前
-
例6.1:向列表
a2中加⼊元素a、b、a、b、a、blpush a2 a b a b a b
-
例6.2:从
a2列表右侧开始删除2个blrem a2 -2 b
-
例6.3:查看列表
a2的所有元素lrange a2 0 -1
5. set(无序集合)
-
添加元素
sadd key member1 member2 ...
-
例1:向键
a3的集合中添加元素zhangsan、lisi、wangwusadd a3 zhangsan sili wangwu
-
返回所有的元素
smembers key
-
例2:获取键
a3的集合中所有元素smembers a3
-
删除指定元素
srem key value
-
例3:删除键
a3的集合中元素wangwusrem a3 wangwu
6.zset(有序集合)
添加数据(索引添值)
zadd key 索引 数值
例如:
zadd a 0 aa 3 bb 1 cc 5 aa
zrange 0 -1 # aa cc bb -- 自动去重,根据索引显示先后顺序
针对redis中的内容扩展(各种数据类型应用场景)
flushall 清空数据库中的所有数据
针对各种数据类型它们的特性,使用场景如下:
字符串string: 用于保存一些项目中的普通数据,只要键值对的都可以保存,例如,保存 session,定时记录状态
哈希hash:用于保存项目中的一些字典数据,但是不能保存多维的字典,例如,商城的购物车
列表list:用于保存项目中的列表数据,但是也不能保存多维的列表,例如,队列,秒杀,医院的挂号
无序集合set:用于保存项目中的一些不能重复的数据,可以用于过滤,例如,投票海选的时候,过滤候选人
有序集合zset:用于保存项目中一些不能重复,但是需要进行排序的数据,分数排行榜.
redis事务
Redis的事务是基于队列实现的;Redis是乐观锁机制。
而MySQL的事务是基于事务日志和锁机制实现;MySQL是悲观锁
乐观锁: 允许多个客户端同时操作同一个key
悲观锁: 当一个客户端在修改一条记录时,会加个锁, 别的客户端不能再同时修改该记录
-- 1.提交示例:
127.0.0.1:6379> multi # 使用multi开启事务
OK
127.0.0.1:6379> set t1 a # 操作,返回了queued,说明把操作放到了事务队列中了
QUEUED
127.0.0.1:6379> exec # 提交事务
1) OK
127.0.0.1:6379> get t1 # 获取数据结果正常
-- 2. 回滚示例:
127.0.0.1:6379> exists t1 # 首先,key不存在
(integer) 0
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set t1 a
QUEUED
127.0.0.1:6379> discard # 回滚,即把事务队列删除
OK
127.0.0.1:6379> exists t1 # 可以看到事务没有执行成功,key仍然不存在
redis 发布订阅
在发布订阅模式中,有三个角色:
- 生产者,它同样是一个redis客户端,负责生产消息。可以有一个或者多个生产者往一个或者多个频道中发布消息。
- channel,频道,类似于主题,接收来自于生产者产生的消息,为不同的消息打个标签,可以有多个频道。它维护在redis的server中。
- 消费者,也是一个Redis客户端,可以订阅感兴趣的消息,也就是可以(一个或者多个)订阅不同频道的消息。
基础命令
subscribe channel(频道名称) # 开启订阅
publish channel(频道) message(发布的消息) # 发布信息
示例 : 需要两个客户端
client1
127.0.0.1:6379> subscribe pingdao # 开启订阅 pingdao
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "pingdao"
3) (integer) 1
1) "message" # 接收消息
2) "pingdao"
3) "I am jiayinghe"
client2
127.0.0.1:6379> publish pingdao 'I am jiayinghe' # 发布消息
(integer) 1
redis持久化存储
参考网址: https://baijiahao.baidu.com/s?id=1654694618189745916&wfr=spider&for=pc
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)
1.存储过程
要有下面五个过程:
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
(4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
2.RDB存储
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
RDB三种触发机制
1.save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止
2.bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求.
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令
3.自动触发(自己配置)
RDB 的优势和劣势
优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
3.AOF存储
redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
优点:
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
缺点:
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
redis哨兵
哨兵(Sentinel):可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转移的功能。
复制(Replication):则是负责让一个Redis服务器可以配备多个备份的服务器。
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题。
Redis哨兵主要功能
(1)集群监控:负责监控Redis master和slave进程是否正常工作
(2)消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移:如果master node挂掉了,会自动转移到slave node上
(4)配置中心:如果故障转移发生了,通知client客户端新的master地址
Redis哨兵的高可用
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
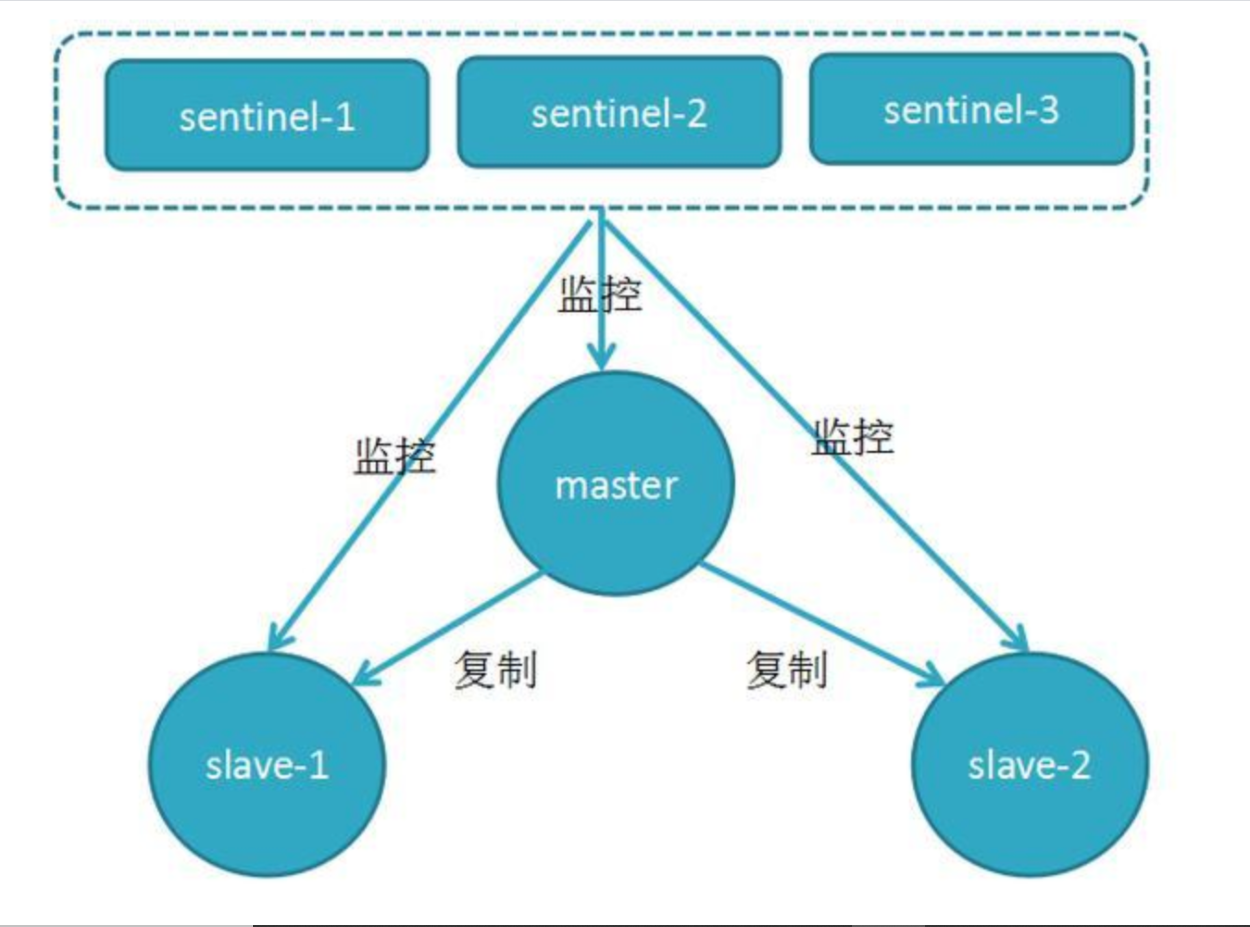
- 哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
- 同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
- 每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
