
redis相关知识
Redis是NoSQL(非关系型数据库)类型数据库,在NoSQL数据库中数据之间是无联系的,无关洗的,数据的结构是松散的,可变的。
关系型数据库的瓶颈:
就像MySQL就是关系型数据库
(1)无法应对每秒上万次的读写请求,无法处理大量集中的高并发操作。关系型数据的是 IO密集的应用。硬盘 IO 也变为性能瓶颈
(2)表中存储记录数量有限,横向可扩展能力有限,一张表最大二百多列。纵向数据可承受能力也是有限的,一张表的数据到达百万级,读写的速度就会逐渐的下降。面对海量数据, 必须使用主从复制,分库分表。这样的系统架构是难以维护的。
(3)无法简单地通过增加硬件、服务节点来提高系统性能。数据整个存储在一个数据库中的。多个服务器没有很好的解决办法,来复制这些数据。
(4)关系型数据库大多是收费的,对硬件的要求较高。软件和硬件的成本花费比重较大。
因为关系型数据库有这些瓶颈,因此目前在互联网领域海量数据的项目中NoSQL应用非常的广泛
非关系型数据库优势:
-
大数据量,高性能
NoSQL 数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。关系型数据库(例如 MySQL)使用查询缓存。这种查询缓存在更新数据后,缓存就是失效了。在频繁的数据读写交互应用中。 缓存的性能不高。NoSQL 的缓存性能要高的多。
-
灵活的数据模型
NoSQL 无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。尤其在快速变化的市场环境中,用户的需求总是在不断变化的。
-
高可用
NoSQL 在不太影响性能的情况,就可以方便的实现高可用的架构。NoSQL 能很好的解决关系型数据库扩展性差的问题。弥补了关系数据(比如 MySQL) 在某些方面的不足,在某些方面能极大的节省开发成本和维护成本。
MySQL 和 NoSQL 都有各自的特点和使用的应用场景,两者结合使用。让关系数据库关注在关系上,NoSQL 关注在存储上。
-
低成本
这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的 License 成本
非关系型数据库的劣势:
-
无关系,数据之间是无联系的
-
不支持标准的 SQL,没有公认的 NoSQL 标准
-
没有关系型数据库的约束,大多数也没有索引的概念
-
没有事务,不能依靠事务实现 ACID.
-
没有丰富的数据类型(数值,日期,字符,二进制,大文本等)
Redis安装和使用
Redis是当今非常流行的基于KV结构的作为Cache使用的NoSQL数据库
Redis介绍:Remote Dictionary Server(Redis) 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的 Key-Value 数据库. Key 字符类型,其值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型,每种数据类型有自己的专属命令。所以它通常也被称为数据结构服务器。
Redis下载地址:http://www.redis.cn/download.html
安装步骤:https://www.cnblogs.com/jia-hao/p/15763482.html
redis的开启和关闭
开启
前台启动:./redis-server
后台启动:./redis-server &
1.前台启动下:启动redis的服务器端,切换到src目录下执行redis-server程序,如果以前台的方式启动,则不能退出当前窗口,如果退出窗口,应用就会终止。
2.后台启动下,在src目录下执行./redis-server & 然后这时候关闭窗口,查看redis进程,依然存在。ps -ef | grep redis
如果安装的时候执行了make install 语句,则不需要必须在src目录下执行。
关闭Redis
1.执行redis-cli shutdown 这种方式下redis先完成数据操作,然后在关闭。推荐使用
2.kill pid 或者 kill -9 pid,这种不会考虑当前是否有数据正在执行操作,直接关闭应用。
Redis操作命令
基本命令
-
沟通命令,查看状态:ping
输入ping,redis会返回PONG,表示redis服务运行正常。
-
查看当前数据库中key的数目:dbsize
语法:dbsize
作用:返回当前数据库的key的数量
-
Redis默认使用16个库,从0到15,如果对数据库的个数进行修改,在redis.conf文件中,修改databases 16语句中的数字
-
切换数据库:select index
命令:select n
-
删除当前库的所有数据:flushdb
-
redis自带的客户端退出当前redia连接:exit或者quit
Key的操作命令
keys:
语法:keys pattern
作用:查找所有符合模式pattern的key,pattern可以使用通配符
通配符:
*:表示0-多个字符,例如:keys * 查询所有的key,keys w* 查询所有以w开头的key
?: 表示单个字符,例如:wo?d,匹配word,wood等等。
exists
语法:exists key [key....]
作用:判断key是否存在
返回值:整数,存在key返回1,其他返回0,使用多个key时,返回存在的key的数量。
expire
语法:expire key seconds
作用:设置key的生存时间,如果超过时间,key自动删除,单位为秒
返回值:设置成功返回数字1,其他情况则为0.
例:已存在一个key为k1,设置其生存时间为10秒,则 expire k1 10
ttl
语法:ttl key
作用:以秒为单位,返回key的剩余生存时间
返回值:-1:没有设置key的生存时间,key永不过期
-2:key不存在
数字:key的剩余时间,以秒为单位
type
语法:type key
作用:查看key所存储值的数据类型
返回值:字符串表示的数据类型
1)none key不存在
2)string 字符串
3)list 列表
4)set 集合
5)zset 有序集
6)hash 哈希表
del
语法:del key [key......]
作用:删除存在的key,不存在的key忽略
返回值:数字,删除的key的数量
redis的5种数据类型
字符串数据类型string
字符串类型是Redis中最基本的数据类型,他能存储任何形式的字符串,包括二进制数据,序列化后的数据,JSON化的对象甚至是一张图片,最大是512M
哈希类型hash:
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
列表类型list
Redis列表是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边)。
集合类型set
Redis的Set是string类型的无序集合,集合成员是唯一的,即集合中不能出现重复的数据。
有序集合类型zset(sorted set)
Redis有序集合zset和集合set一样也是string类型元素的集合,且不允许重复的成员,不同的是zset的每个元素都会关联一个分数(分数可以重复),redis通过分数来为集合中的成员进行从小到大的排序。
Redis数据类型操作命令
字符串类型(string)
基本命令
set
将字符串值value设置到key中
语法:set key value
向已经存在的key设置新的value,会覆盖原来的值。
get
获取key中设置的字符串值
语法:get key
incr
将key中存储的数字值加1,如果key不存在,则key的值先被初始化为0再执行incr操作(只能对数字类型的数据操作),返回加1后的结果
语法:incr key
decr
将key中存储的数字值减1,如果key不存在,则key的值先被初始化为0再执行decr操作(只能对数字类型的数据操作),返回减1后的结果
append
语法:append key value
说明:如果key存在,则将value追加到key原来旧值的末尾,如果key不存在,则将key设置的值为value
返回值:追加字符串之后的总长度
常用命令
strlen
语法:strlen key
说明:返回key所存储的字符串值的长度
返回值:如果key存在,返回字符串值的长度,如果key不存在,返回0.
getrange
语法:getrange key start end
作用:获取key中字符串值从start到end结束的字符串,包括start和end,负数表示从字符串的末尾开始,-1表示最后一个字符
返回值:截取的子字符串
setrange
语法:setrange key offset value
说明:用value覆盖(替代)key的存储得值从offset开始,不存在的key做空白字符串。
返回值:修改后的字符串的长度
mset
语法:mset key value [key value....]
说明:同时设置一个或者多个 key-value对
返回值:ok
mget
语法:mget key [key....]
作用:获取所有(一个或者多个)给定key的值
返回值:包含所有key的列表
哈希类型hash
redis中hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
基本命令
hset
语法:hset hash表的key field value
作用:将哈希表 key 中的域 field 的值设为 value ,如果 key 不存在,则新建 hash 表,执行赋值,如果有 field ,则覆盖值。
返回值:1.如果field是hash表中新field,且设置成功,返回1
2.如果field已经存在,旧值覆盖新值,返回0
hget
语法:hget key field
作用:获取哈希表key中给定域field的值
返回值:field域的值,如果key不存在或者field不存在返回nil
hmset
语法:hmset key field value [field value.....]
说明:同时将多个field-value(域-值)设置到哈希表key中,此命令会覆盖已经存在field,如果hash 表 key 不存在,创建空的 hash 表,执行 hmset.
返回值:设置成功返回ok,如果失败返回一个错误。
hmget
语法:hmget key field [field....]
作用:获取哈希表key中一个或多个给定域的值
返回值:返回和field顺序对应的值,如果field不存在,返回nil
hgetall
语法:hgetall key
作用:获取哈希表key中所有的域和值
返回值:以列表形式返回hash中的域和域的值,如果key不存在,则返回空hash
hdel
语法:hdel key field [field....]
作用:删除哈希表key中的一个或者多个指定域field,不存在的field直接忽略
返回值:成功删除的field的数量
常用命令
hkeys
语法:hkeys key
作用:查看哈希表key中的所有的field域
返回值:包含所有的field的列表,key不存在的话返回空列表
hvals
语法:hvals key
作用:返回哈希表中所有域的值
返回值:包含哈希表所有域值的列表,key不存在的话返回空列表
hexists
语法:hexists key field
作用:查看哈希表key中,给定域field是否存在
返回值:如果field存在,返回1,其他情况返回0
列表类型list
Redis列表是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边)。
基本命令
lpush
语法:lpush key value [value......]
作用:将一个或者多个值value插入到列表key的表头(最左边),从左边开始加入智,从左到右的顺序依次插入到表头。
返回值:数字,新列表的长度
rpush
语法:rpush key value [value......]
作用:将一个或多个值value插入到列表key的表尾(最右边),各个value值按从左到右的顺序依次插入到表尾
返回值:数字,新列表的长度
lrange
语法:lrange key start stop
作用:获取列表 key 中指定区间内的元素,0 表示列表的第一个元素,以 1 表示列表的第二个元素;start , stop 是列表的下标值,也可以负数的下标, -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 start ,stop 超出列表的范围不会出现错误。
返回值:指定区间的列表
list
语法:lindex key index
作用:获取列表 key 中下标为指定 index 的元素,列表元素不删除,只是查询。0 表示列表的第一个元素,以 1 表示列表的第二个元素;start , stop 是列表的下标值,也可以负数的下标, -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推
返回值:指定下标的元素,index不在列表范围,则返回nil
llen
语法:llen key
作用:获取列表key的长度
返回值:数值,列表的长度,key不存在的话返回0
常用命令
lrem
语法:lrem key count value
作用:根据参数 count 的值,移除列表中与参数 value 相等的元素, count >0 ,从列表的左侧向右开始移除; count < 0 从列表的尾部开始移除;count = 0 移除表中所有与 value 相等的值。(例:count=2,表示从左侧开始找两个与value相同的元素删除,count=-2,从右侧开始找两个与value相同的元素删除)
返回值:数值,移除的元素个数
lset
语法:lset key index value
作用:将列表key下标为index的元素的值设置为value
返回值:设置成功返回 ok ; key 不存在或者 index 超出范围返回错误信息
linsert
语法:linsert key BEFORE|ALFTER pivot value
作用:将值value插入到列表key当中位于值pivot之前或之后的位置,如果key不存在,或者pivot不在列表中,则不执行任何操作
返回值:命令执行成功,返回新列表的长度,如果没有找到pivot,返回-1,如果key不存在,返回0.
集合类型set
redis的set是string类型的无序集合,集合成员是唯一的,即集合中不能出现重复的数据。
基本命令
sadd
语法:sadd key memeber [member]
作用:将一个或者多个member元素加入到集合key当中,已经存在于集合的member元素将被忽略,不会再加入
返回值:加入到集合的新元素的个数,不包括被忽略的元素。
smembers
语法:smembers key
作用:获取集合key中的所有成员元素,不存在的key视为空集合
sismember
语法:sismember key member
作用:判断member元素是否是集合key的成员
返回值:member是集合成员返回1,其他返回0
scard
语法:scard key
作用:获取集合里面的元素个数
返回值:数字,key的元素个数,其他情况返回0
srem
语法:srem key member [member....]
作用:删除集合key中的一个或多个member元素,不存在的元素被忽略。
返回值:数字,成功删除的元素个数,不包括被忽略的元素。
常用命令
srandmember
语法:srandmember key [count]
作用:只提供 key,随机返回集合中一个元素,元素不删除,依然在集合中;提供了 count 时,count 正数, 返回包含 count 个数元素的集合, 集合元素各不相同。count 是负数,返回一个 count 绝对值的长度的集合, 集合中元素可能会重复多次。
返回值:一个元素;多个元素的集合
spop
语法:spop key [count]
作用:随机从集合中删除一个元素,count是删除的元素个数。
返回值:被删除的元素,key不存在或空集合返回nil
有序集和类型zset(sorted set)
redis 有序集合zset和集合set一样也是string类型元素的集合,且不允许重复的成员。
不同的是 zset 的每个元素都会关联一个分数|数值(分数可以重复),redis 通过分数|数值来为集合中的成员进行从小到大的排序。
基本命令
zadd
语法:zadd key score member [score member…]
作用:将一个或多个 member 元素及其 score 值加入到有序集合 key 中,如果 member
存在集合中,则更新值;score 可以是整数或浮点数
返回值:数字,将添加的元素个数
zrange
语法:zrange key start stop [WITHSCORES]
作用:查询有序集合,指定区间的内的元素。集合成员按 score 值从小到大来排序。 start,stop 都是从 0 开始。0 是第一个元素,1 是第二个元素,依次类推。以 -1 表示最后一个成员,-2 表示倒数第二个成员。WITHSCORES 选项让 score 和 value 一同返回。
返回值:自定区间的成员集合
zrevrange
语法:zrevrange key start stop [withscores]
作用:返回有序集key中,指定区间内的成员,其中成员的位置按score值递减(从大到小)来排列(与zrange排列顺序相反)其他都和zrange命令一样。
返回值:自定区间的成员集合
zrem
语法:zrem key member [member.....]
作用:删除有序集合key中的一个或多个成员,不存在的成员被忽略
返回值:被成功删除的成员数量,不包括被忽略的成员
zcard
语法:zcard key
作用:获取有序集key的元素成员的个数
返回值:key存在返回集合元素的个数,key不存在,返回0
常用命令
zrangebyscore
语法:zrangebyscore key min max [withscores] [limit offset count]
作用:获取有序集 key 中,所有 score 值介于 min 和 max 之间(包括 min 和 max)的成员,有序成员是按递增(从小到大)排序。min ,max 是包括在内 , 使用符号“ (” 表示不包括。 min , max 可以使用 -inf +inf 表示最小和最大 ,limit 用来限制返回结果的数量和区间。withscores 显 示 score 和 value,limit用来显示分页,offset表示起始位置,count表示要显示的数据数量
返回值:指定区间的集合数据
zrevrangebyscore
语法:zrevrangebyscore key max min [withscores] [limit offset count]
作用:返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成员。有序集成员按 score 值递减(从大到小)的次序排列。其他同 zrangebyscore
zcount
语法:zcount key min max
作用:返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量
高级话题
事务
事务操作的命令
multi
语法:multi
作用:标记一个事务的开始,事务内的多条命令会按照先后顺序被放进一个队列当中
返回值:总是返回ok
exec
语法:exec
作用:执行所有事物块内的命令
返回值:事务内所有执行语句内容,事务被打断(影响)返回nil
discard
语法:discard
作用:取消事务,放弃执行事务块内的所有命令
返回值:总是返回ok
watch
语法:watch key [key......]
作用:监视一个(或多个)key,如果在事务执行之前这个(或这些)key被其他命令所改动,那么事务将被打断。
返回值:总是返回ok
unwatch
语法:unwatch
作用:取消watch命令对所有key的监视,如果在执行watch命令之后,exec命令或discard命令先被执行了的话,那么就不需要再执行unwatch了
返回值:总是返回ok
持久化
持久化可以理解为存储,就是将数据存储到一个不会丢失的地方,如果把数据放在内存中,电脑关闭或重启数据就会丢失,所以放在内存中的数据不是持久化的,而放在磁盘就算是一种持久化。
Redis 的数据存储在内存中,内存是瞬时的,如果 linux 宕机或重启,又或者 Redis 崩溃或重启,所有的内存数据都会丢失,为解决这个问题,Redis 提供两种机制对数据进行持久化存储,便于发生故障后能迅速恢复数据。
RDB方式持久化
Redis Database(RDB),就是在指定的时间间隔内将内存中的数据集快照写入磁盘,数据恢复时将快照文件直接再读到内存。
RDB 保存了在某个时间点的数据集(全部数据)。存储在一个二进制文件中,只有一个文件。默认是 dump.rdb。RDB 技术非常适合做备份,可以保存最近一个小时,一天,一个月的全部数据。保存数据是在单独的进程中写文件,不影响 Redis 的正常使用。RDB 恢复数据时比其他 AOF 速度快。
RDB方式优缺点
优点:由于存储的是数据快照文件,恢复数据很方便,也比较快
缺点:
1)会丢失最后一次快照以后更改的数据。如果你的应用能容忍一定数据的丢失,那么使用 rdb 是不错的选择;如果你不能容忍一定数据的丢失,使用 rdb 就不是一个很好的选择。
2)由于需要经常操作磁盘,RDB 会分出一个子进程。如果你的 redis 数据库很大的话, 子进程占用比较多的时间,并且可能会影响 Redis 暂停服务一段时间(millisecond 级别),如果 你的数据库超级大并且你的服务器 CPU 比较弱,有可能是会达到一秒。
AOF方式持久化
Append-only File(AOF),Redis 每次接收到一条改变数据的命令时,它将把该命令写到一个 AOF 文件中(只记录写操作,读操作不记录),当 Redis 重启时,它通过执行 AOF 文件中所有的命令来恢复数据。
总结:1.append-only 文件是另一个可以提供完全数据保障的方案;
2.AOF 文件会在操作过程中变得越来越大。比如,如果你做一百次加法计算,最后你只会 在数据库里面得到最终的数值,但是在你的 AOF 里面会存在 100 次记录,其中 99 条记录对 最终的结果是无用的;但 Redis 支持在不影响服务的前提下在后台重构 AOF 文件,让文件得以 整理变小
3.可以同时使用这两种方式,redis 默认优先加载 aof 文件(aof 数据最完整);
主从复制读写分离
通过持久化功能,Redis 保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现故障,比如硬盘坏了, 也会导致数据丢失。
为了避免单点故障,我们需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务。
这就要求当一台服务器上的数据更新后,自动将更新的数据同步到其他服务器上
Redis 提供了复制(replication)功能来自动实现多台 redis 服务器的数据同步(每天19 点 新闻联播,基本从 cctv1-8,各大卫视都会播放)
我们可以通过部署多台 redis,并在配置文件中指定这几台 redis 之间的主从关系,主负责写入数据, 同时把写入的数据实时同步到从机器, 这种模式叫做主从复制, 即master/slave,并且 redis 默认 master 用于写,slave 用于读,向 slave 写数据会导致错误
主从复制的实现(master/slave)
方式 1:修改配置文件,启动时,服务器读取配置文件,并自动成为指定服务器的从服务器,从而构成主从复制的关系
方式 2: ./redis-server --slaveof <master-ip> <master-port>,在启动 redis 时指定当前服务成为某个主 Redis 服务的从 Slave
方式1的实现步骤
模拟多 Reids 服务器, 在一台已经安装 Redis 的机器上,运行多个 Redis 应用模拟多个 Reids 服务器。一个 Master,两个 Slave.
A、新建三个 Redis 的配置文件
如果 Redis 启动,先停止。
作为 Master 的 Redis 端口是 6380
作为 Slaver 的 Redis 端口分别是 6382 , 6384
从原有的 redis.conf 拷贝三份,分别命名为 redis6380.conf, redis6382.conf , redis6384.conf
B、 编辑 Master 配置文件
编辑 Master 的配置文件 redis6380.conf : 在空文件加入如下内容
include /usr/local/redis-3.2.9/redis.conf
daemonize yes port 6380
pidfile /var/run/redis_6380.pid logfile 6380.log
dbfilename dump6380.rdb
配置项说明:
include : 包含原来的配置文件内容。/usr/local/redis-3.2.9/redis.conf 按照自己的目录设置。
daemonize:yes 后台启动应用,相当于 ./redis-server & , &的作用。
port : 自定义的端口号
pidfile : 自定义的文件,表示当前程序的 pid ,进程 id。
logfile:日志文件名
dbfilename:持久化的 rdb 文件名
C、 编辑 Slave 配置文件
编辑 Slave 的配置文件 redis6382.conf 和 redis6384.conf: 在空文件加入如下内容
①:redis6382.conf:
include /usr/local/redis-3.2.9/redis.conf
daemonize yes
port 6382
pidfile /var/run/redis_6382.pid logfile 6382.log
dbfilename dump6382.rdb slaveof 127.0.0.1 6380
配置项说明:
slaveof : 表示当前 Redis 是谁的从。当前是 127.0.0.0 端口 6380 这个 Master 的从。
②:redis6384.conf:
include /usr/local/redis-3.2.9/redis.conf daemonize yes
port 6384
pidfile /var/run/redis_6384.pid logfile 6384.log
dbfilename dump6384.rdb
slaveof 127.0.0.1 6380
D、启动服务器 Master/Slave 都启动
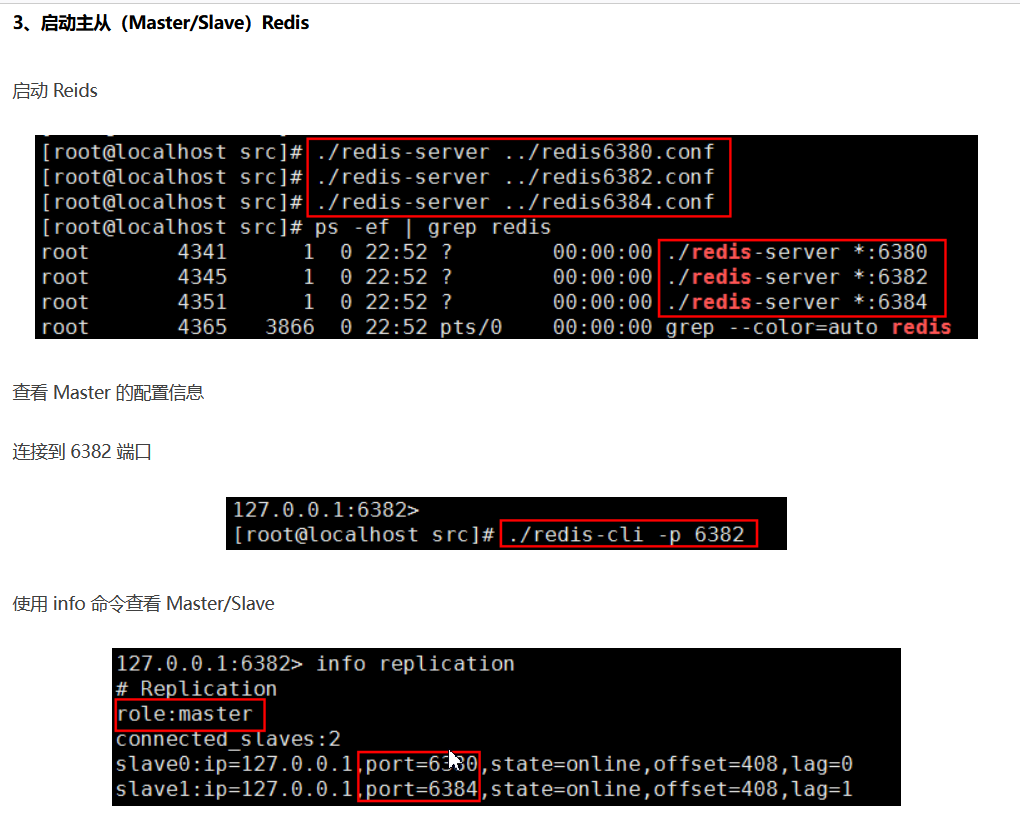
启动方式 ./redis-server 配置文件 (./redis-server ../redis6380.conf)(./redis-server ../redis6382.conf)(./redis-server ../redis6384.conf)
启动 Redis,并查看启动进程 ps -ef | grep redis
E、 查看配置后的服务信息
命令:
①: Redis 客户端使用指定端口连接 Redis 服务器
./redis-cli -p 端口
②:查看服务器信息
info replication
到此所有过程完成,可以开始测试,可以得知只有主服务器(6380)可以写数据,从服务器(6382,6384)不可以写数据。
容灾处理
master 上(冷处理:机器挂掉了,再处理)当 Master 服务出现故障,需手动将 slave 中的一个提升为 master, 剩下的 slave 挂至新的
命令:
①:slaveof no one,将一台 slave 服务器提升为 Master (提升某 slave 为 master)
②:slaveof 127.0.0.1 6381 (将 slave 挂至新的 master 上)
高可用sentinel哨兵
Sentinel 哨兵是 redis 官方提供的高可用方案,可以用它来监控多个 Redis 服务实例的运行情况。Redis Sentinel 是一个运行在特殊模式下的 Redis 服务器。Redis Sentinel 是在多个Sentinel 进程环境下互相协作工作的。
注意:哨兵的个数必须是奇数,因为当主服务器出现故障时候,必须由哨兵投票选取新的主服务器
sentinel哨兵系统的三个主要任务
● 监控:Sentinel 不断的检查主服务和从服务器是否按照预期正常工作。
● 提醒:被监控的 Redis 出现问题时,Sentinel 会通知管理员或其他应用程序。
● 自动故障转移:监控的主 Redis 不能正常工作,Sentinel 会开始进行故障迁移操作。将一个从服务器升级新的主服务器。 让其他从服务器挂到新的主服务器。同时向客户端提供新的主服务器地址。
1.sentinel配置
sentinel配置文件
复制三份sentinel.conf文件 (在redis安装目录下)
三个文件分别命名:
● sentinel26380.conf
● sentinel26382.conf
● sentinel26384.conf
● 执行复制命令 cp sentinel.conf xxx.conf
2、三份 sentinel 配置文件修改
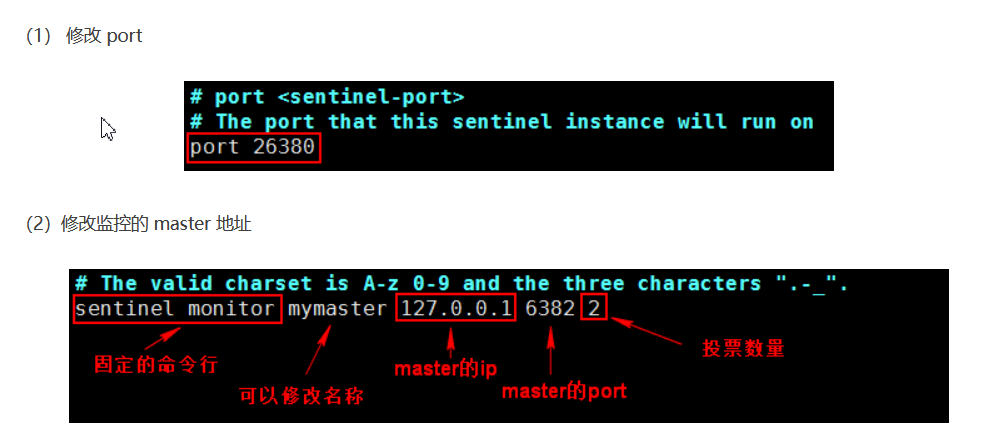
● 修改 port 26380、 port 26382、 port 26384
● 修改 sentinel monitor mymaster 127.0.0.1 6380 2
格式:sentinel monitor <name> <masterIP> <masterPort> <Quorum 投票数>
Sentinel监控主(Master)Redis, Sentinel根据Master的配置自动发现Master的Slave,Sentinel默认端口号为26379 。
vim sentinel26380.conf
sentinel26382.conf 修改port 26382 , master的port 6382
sentinel26384.conf 修改port 26384 , master的port 6382
4、启动 Sentinel
redis安装时make编译后就产生了redis-sentinel程序文件,可以在一个redis中运行多个sentinel进程。
启动一个运行在Sentinel模式下的Redis服务实例
./redis-sentinel sentinel 配置文件
执行以下三条命令,将创建三个监视主服务器的Sentinel实例:
./redis-sentinel ../sentinel26380.conf
./redis-sentinel ../sentinel26382.conf
./redis-sentinel ../sentinel26384.conf
在 XShell 开启三个窗口分别执行。
5.结果
之后就可以关闭主服务器查看哨兵的处理情况,再开开主服务器查看哨兵的处理情况。
安全设置
设置密码
访问 Redis 默认是没有密码的,这样不安全,任意用户都可以访问。可以启用使用密码才能访问 Redis。 设置 Redis 的访问密码,修改 redis.conf 中这行 requirepass 密码。密码要比较复杂,不容易破解,而且需要定期修改。因为 redis 速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行 150K 次的密码尝试,需要指定非常非常强大的密码来防止暴力破解。
开启访问密码设置
修改 redis.conf , 使用 vim 命令。 找到 requirepass 行去掉注释,requirepass 空格后就是密码。
访问有密码的redis
如果 Redis 已经启动,关闭后,重新启动。
访问有密码的 Redis 两种方式:
①:在连接到客户端后,使用命令 auth 密码 , 命令执行成功后,可以正常使用 Redis
②:在连接客户端时使用 -a 密码。例如 ./redis-cli -h ip -p port -a password
绑定ip
修改 redis.conf 文件,把# bind 127.0.0.1 前面的注释#号去掉,然后把 127.0.0.1 改成允许访问你 redis 服务器的 ip 地址,表示只允许该 ip 进行访问。多个 ip 使用空格分隔。
例如 bind 192.168.1.100 192.168.2.10
修改默认端口
修改 redis 的端口,这一点很重要,使用默认的端口很危险,redis.conf 中修改 port 6379
将其修改为自己指定的端口(可随意),端口 1024 是保留给操作系统使用的。用户可以使用的范围是 1024-65535

 浙公网安备 33010602011771号
浙公网安备 33010602011771号