大数据------MapReduce 计算流程
ResourceManager
NodeManager:管理主机上计算资源Container负责向MR汇报自身的状态信息
MRAppMaster:计算任务的Master,负责申请计算资源,协调计算任务
YarnChild:负责做实际计算的任务/进程(MapTask/ReduceTask)
Container:是计算资源的抽象代表着一组内存/cpu/网络的占用,无论是MRAppMaster还是YranChild运势是都需要消耗一个Container逻辑
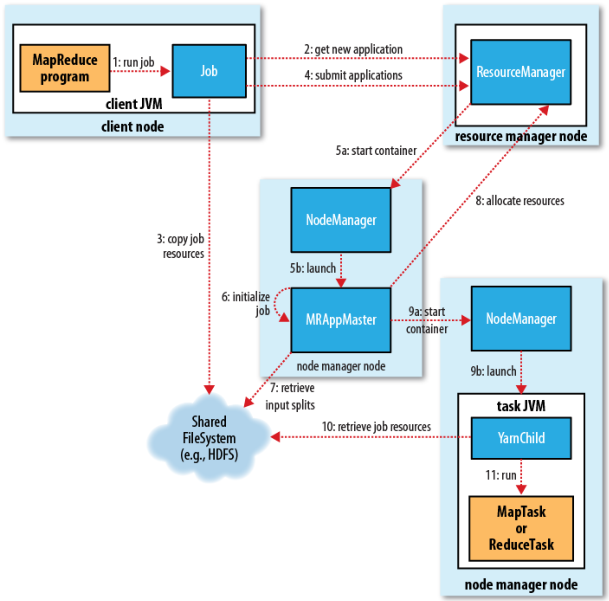
-
-
一个MR程序就是一个Job,Job的信息会给ResourceManager,ResourceManager注册Job信息
-
ResouceManager注册通过后,Job会拷贝相关的资源信息(从HDFS中)
-
Job紧接着会向ResourceManager提交完整的应用信息(包括资源信息)
-
ResourceManager通过Job信息计算出当前Job所需要的资源,为Job分配Container(资源的单位)
-
这个Container信息会分发给NodeManager,NodeManger会创建MRAppMaster进程
-
此时MRAppMaster会初始化Job
-
然后会查询任务的切片
-
连接RM,请求分配资源,得到对应的资源,连接对应的NodeManager,在YarnChild上启动对应的Container
-
从分布式文件系统上拷贝Job资源
-
执行MR程序

