摘要:  闭包引用 概念 所有编程语言都有闭包的概念,闭包就是在一个函数中引用了函数外的变量。 Spark中,普通的变量是在Driver程序中创建的,RDD的计算是在分布式集群中的task程序上进行的。因此,当分布式算子的函数引用了外部的变量时,Driver会把该变量序列化后通过网络发送给每一个task(只针 阅读全文
闭包引用 概念 所有编程语言都有闭包的概念,闭包就是在一个函数中引用了函数外的变量。 Spark中,普通的变量是在Driver程序中创建的,RDD的计算是在分布式集群中的task程序上进行的。因此,当分布式算子的函数引用了外部的变量时,Driver会把该变量序列化后通过网络发送给每一个task(只针 阅读全文
闭包引用 概念 所有编程语言都有闭包的概念,闭包就是在一个函数中引用了函数外的变量。 Spark中,普通的变量是在Driver程序中创建的,RDD的计算是在分布式集群中的task程序上进行的。因此,当分布式算子的函数引用了外部的变量时,Driver会把该变量序列化后通过网络发送给每一个task(只针 阅读全文
posted @ 2024-05-03 19:07
Ji_Lei
阅读(262)
评论(0)
推荐(0)
 Hive如何读写数据? 我们知道,hive表的数据是存储在hdfs文件系统中的。那么Hive是如何将hdfs上的数据文件,映射成一张张表呢,今天就来理清楚这个问题。 官方文档中对于Hive读数据的流程如下: 精炼一下:Hive的执行引擎首先通过InputFormat读取一条一条的数据记录,接着调用S
Hive如何读写数据? 我们知道,hive表的数据是存储在hdfs文件系统中的。那么Hive是如何将hdfs上的数据文件,映射成一张张表呢,今天就来理清楚这个问题。 官方文档中对于Hive读数据的流程如下: 精炼一下:Hive的执行引擎首先通过InputFormat读取一条一条的数据记录,接着调用S 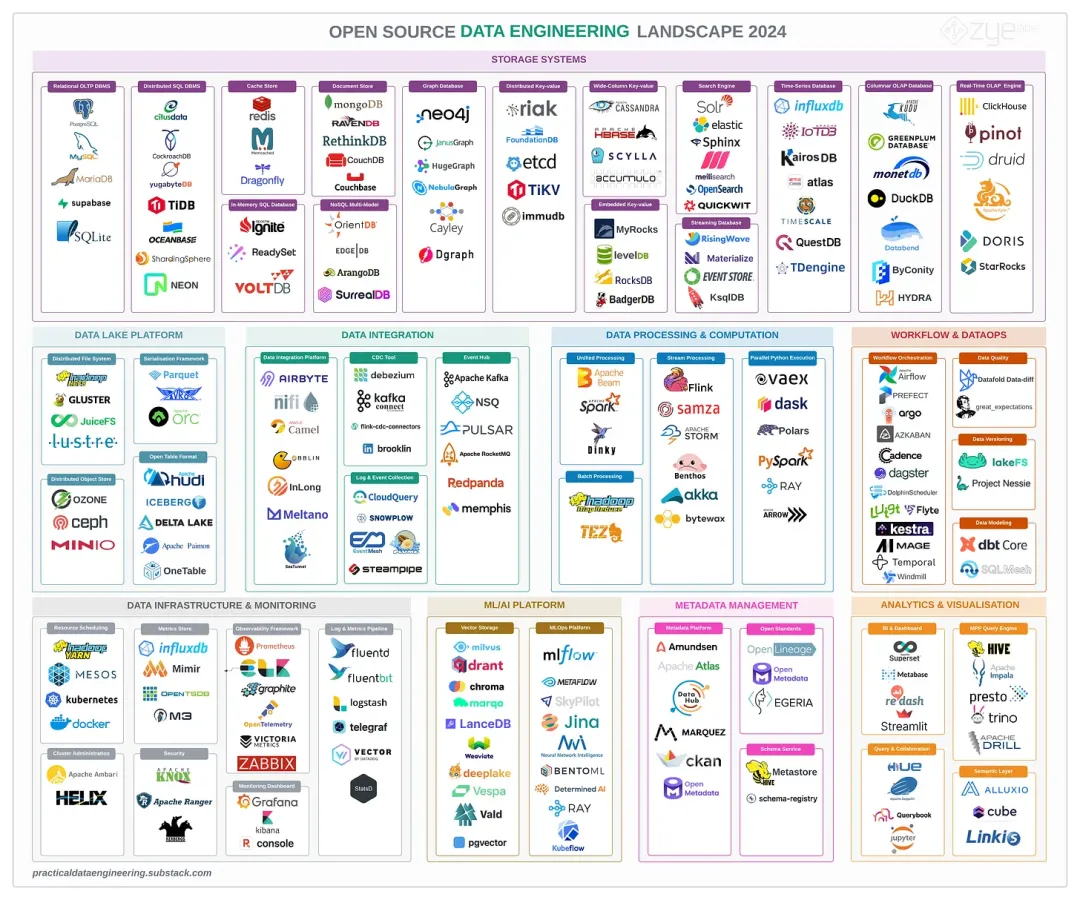 2024 开源数据工程生态系统全景图(转) 简介 虽然生成式人工智能和ChatGPT带来的沸沸扬扬的炒作令科技界为之一振,但在数据工程领域,2023年仍然是一个令人振奋和充满活力的一年,数据工程生态系统变得更加多样化和复杂化,系统中的所有层面都在不断创新和演进。 随着各种开源工具、框架和解决
2024 开源数据工程生态系统全景图(转) 简介 虽然生成式人工智能和ChatGPT带来的沸沸扬扬的炒作令科技界为之一振,但在数据工程领域,2023年仍然是一个令人振奋和充满活力的一年,数据工程生态系统变得更加多样化和复杂化,系统中的所有层面都在不断创新和演进。 随着各种开源工具、框架和解决  前言 OLAP概念诞生于1993年,工具则出现在更早以前,有史可查的第一款OLAP工具是1975年问世的Express,后来走进千家万户的Excel也可归为此类,所以虽然很多数据人可能没听过OLAP,但完全没打过交道的应该很少。 这个概念主要是在大数据圈里流传,而在大数据领域里,目前主流的OLAP开
前言 OLAP概念诞生于1993年,工具则出现在更早以前,有史可查的第一款OLAP工具是1975年问世的Express,后来走进千家万户的Excel也可归为此类,所以虽然很多数据人可能没听过OLAP,但完全没打过交道的应该很少。 这个概念主要是在大数据圈里流传,而在大数据领域里,目前主流的OLAP开  什么是数据漂移? 数据漂移是 ODS 数据的一个顽疾,通常指 ODS 表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。 实际场景 公司主营互联网金融业务,因此有了一张数据量庞大的申请人信息记录表。这张表里的时间字段非常多,因为整个业务场景涉及到好几段流程: 客户提交申
什么是数据漂移? 数据漂移是 ODS 数据的一个顽疾,通常指 ODS 表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。 实际场景 公司主营互联网金融业务,因此有了一张数据量庞大的申请人信息记录表。这张表里的时间字段非常多,因为整个业务场景涉及到好几段流程: 客户提交申  1、背景 数据开发、数据仓库工作和业务系统开发工作很大的一个不同是,业务系统功能开发一旦完成并通过测试,一般就可以比较稳定地长期运行,因为它的输入是相对稳定的。但是数据仓库开发加工的数据模型、数据指标和分析结论,却很难保持稳定。因为输入数据每天都在源源不断产生,很难保证数据没有大的波动,而输入的不稳
1、背景 数据开发、数据仓库工作和业务系统开发工作很大的一个不同是,业务系统功能开发一旦完成并通过测试,一般就可以比较稳定地长期运行,因为它的输入是相对稳定的。但是数据仓库开发加工的数据模型、数据指标和分析结论,却很难保持稳定。因为输入数据每天都在源源不断产生,很难保证数据没有大的波动,而输入的不稳 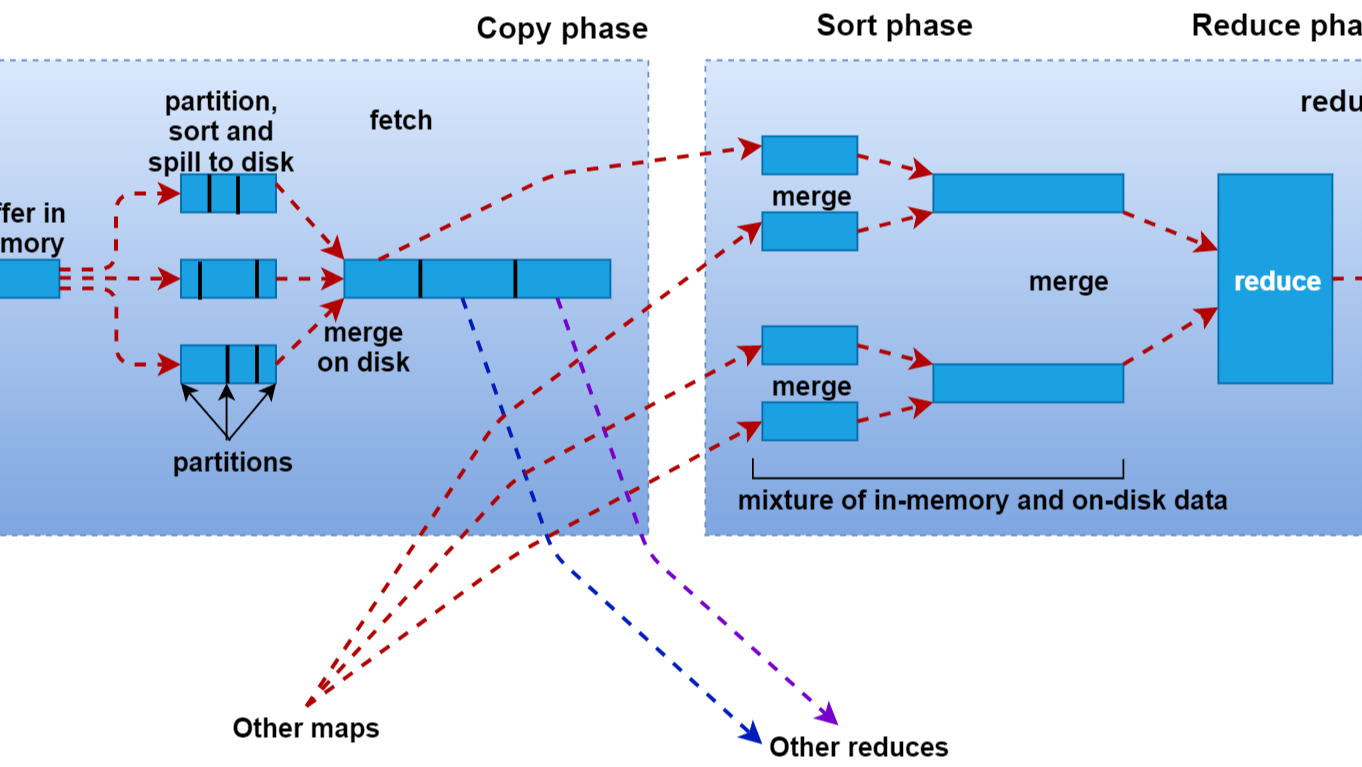 job提交阶段 1、准备好待处理文本。 2、客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划。 3、客户端向Yarn请求创建MrAppMaster并提交切片等相关信息:job.split、wc.jar、job.xml。Yarn调用ResourceManager
job提交阶段 1、准备好待处理文本。 2、客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划。 3、客户端向Yarn请求创建MrAppMaster并提交切片等相关信息:job.split、wc.jar、job.xml。Yarn调用ResourceManager  先看源码: numPartitions = conf.getNumReduceTasks(); if (numPartitions > 1) { //设置了ReduceTask个数后(大于1),默认通过下面的getPartition()对数据进行分区 partitioner = (Partition
先看源码: numPartitions = conf.getNumReduceTasks(); if (numPartitions > 1) { //设置了ReduceTask个数后(大于1),默认通过下面的getPartition()对数据进行分区 partitioner = (Partition  前面我们介绍了一种经典的排序算法——冒泡排序。通过依次比较、交换相邻元素,使最大值浮到数组末端。今天我们介绍另一种经典的排序算法:选择排序。
前面我们介绍了一种经典的排序算法——冒泡排序。通过依次比较、交换相邻元素,使最大值浮到数组末端。今天我们介绍另一种经典的排序算法:选择排序。  喝汽水时,大家会发现一个个小气泡从瓶底慢慢浮到水面。这一情景形象地反映了冒泡排序的过程。**冒泡排序**(Bubble Sort)是一种简单的排序算法。通过依次比较相邻两个元素的大小,逆序则交换,使较大(或较小)元素经过不断的交换慢慢移动到数列的末端,最终使全部元素达到有序的状态。
喝汽水时,大家会发现一个个小气泡从瓶底慢慢浮到水面。这一情景形象地反映了冒泡排序的过程。**冒泡排序**(Bubble Sort)是一种简单的排序算法。通过依次比较相邻两个元素的大小,逆序则交换,使较大(或较小)元素经过不断的交换慢慢移动到数列的末端,最终使全部元素达到有序的状态。  浙公网安备 33010602011771号
浙公网安备 33010602011771号