Kafka 性能
文件结构
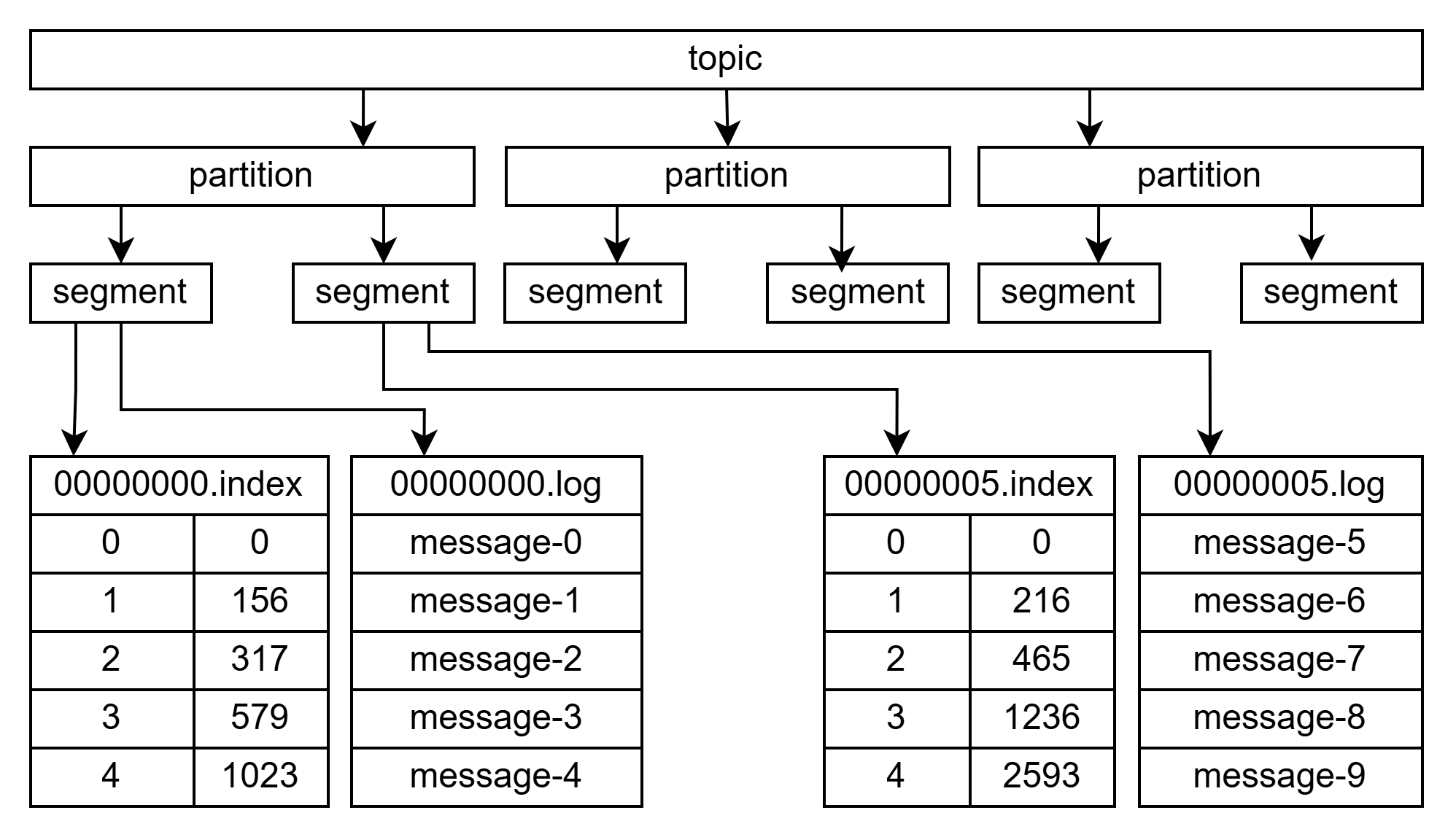
顺序写入
Comparing Random and Sequential Access in Disk and Memory(比较磁盘和内存中的随机存取和顺序存取)
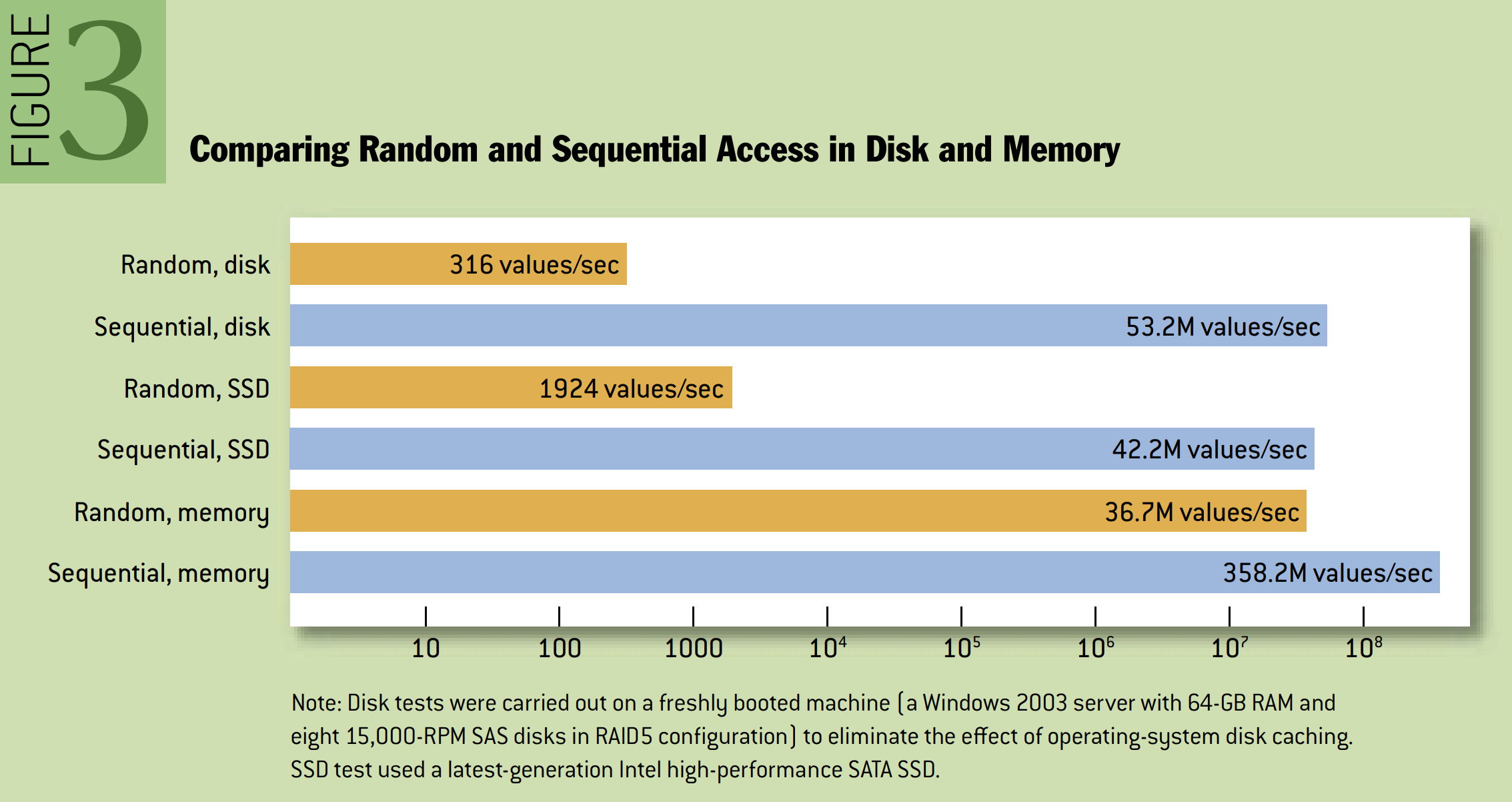
Note:磁盘测试是在新启动的机器(Windows Server 2003,64 GB RAM 和 8 个 15,000 RPM SAS 磁盘,配置为 RAID5)上进行的,以消除操作系统磁盘缓存的影响。SSD 测试使用最新一代 Intel 高性能 SATA SSD。
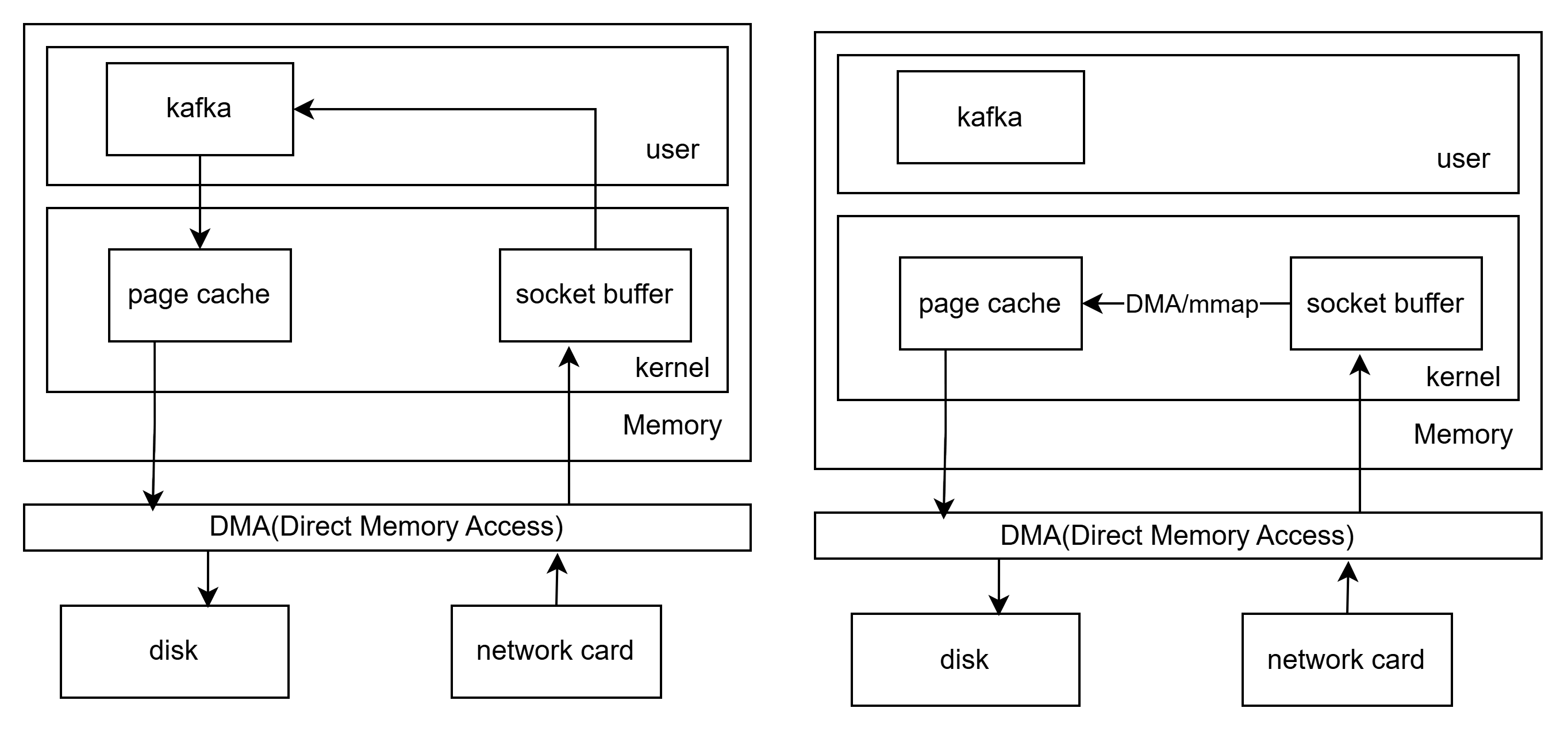
零拷贝
read/write 流程(2 次 cpu 拷贝):磁盘 → Page Cache → 用户缓冲区 → Socket Buffer → 网卡
mmap 流程(1 次 cpu 拷贝):磁盘 → Page Cache → 用户虚拟空间(mmap映射) → Socket Buffer → 网卡
sendfile 流程(0 次 cpu 拷贝):磁盘 → Page Cache → Socket Buffer(直接 DMA) → 网卡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号