3.4 Hive 分组排序(Hadoop3.0系列)
3.4 Hive 分组排序(Hadoop3.0系列)
【实验目的】
1.了解Hive中Order by 、Sort by的用法以及区别
2.了解Hive中Distribute by、Group by以及Cluster by的用法于区别
【实验原理】
Hive中支持多种分组操作:Order by、Sort by、Group by、Distribute by、Cluster by等
(1)Hive中的Order by和传统Sql中的Order by一样,对查询结果做全局排序,会新启动一个Job进行排序,会把所有数据放到同一个Reduce中进行处理,不管数据多少,不管文件多少,都启用一个Reduce进行处理。如果指定了hive.mapred.mode=strict(默认值是nonstrict),这时就必须指定limit来限制输出条数,原因是:所有的数据都会在同一个Reducer端进行,数据量大的情况下可能不出结果,那么在这样的严格模式下,必须指定输出的条数。
(2)Sort by是局部排序,会在每个Reduce端做排序,单个Reduce出来的数据是有序的,假设我设置了3个Reduce,那么这3个Reduce就会生成三个文件,每一个文件都会按Sort by后设置的条件排序,但是当这3个文件数据合在一起就不一定有序了,一般情况下可以先进行Sort by局部排序完成后,再进行全局排序,就会提高不少效率。
(3)Group by是分组查询,一般配合聚合函数一起使用,Group by有一个原则,就是Select后面的所有列中,没有使用聚合函数的列,必须出现在Group by后面。
(4)Hive中的Distribute by是控制在Map端如何拆分数据给Reduce端的。按照指定的字段对数据划分到不同的Reduce输出文件中,默认是采用Hash算法。对于Distribute by进行测试,一定要分配多Reduce进行处理,否则无法看到Distribute by的效果。
(5)Cluster by除了具有Distribute by的功能外还兼具Sort by的功能,相当于Distribute by+ Sort by的结合,但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
【实验环境】
AnolisOS8.8
Java 1.8.0
Hadoop-3.0.0
Eclipse-JEE 2022.03
HBase 1.4.10
mysql-8.0.26
Pycharm
apache-hive-2.3.5
【实验内容】
1.全局排序Order by与局部排序Sort by的用法,以及各自适用的场景。
2.分组查询Group by的应用场景与基本语法。
3.Cluster by与Distribute by和Sort by的关系及操作。
【实验步骤】
切换到vmuser用户下,密码(vm123456)
1首先检查Hadoop相关进程,是否已经启动。若未启动,切换到/apps/hadoop/sbin目录下,启动Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
使用jps查看启动的进程
2. 然后开启Mysql,用于存放Hive的元数据。
查看mysql服务是否开启
systemctl status mysqld
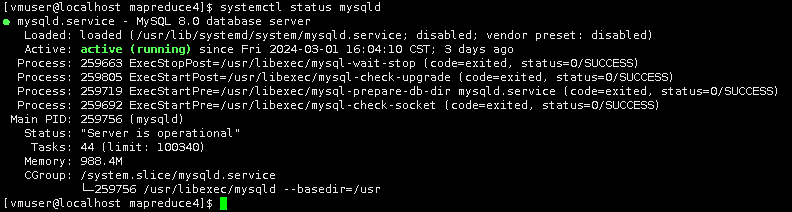
输出显示MySQL未启动。执行以下启动命令启动MySQL。(密码:vm123456)
systemctl start mysqld
3.切换到/data/hive4目录下,如不存在需提前创建hive4文件夹。
mkdir -p /data/hive4
cd /data/hive4
4.使用wget命令,下载http://hive4中的文件。
wget http://hive4/goods_visit
wget http://hive4/order_items
wget http://hive4/buyer_favorite
5.在终端命令行界面,直接输入Hive命令,启动Hive命令行。
hive

Order by的演示
1.在Hive中创建一个goods_visit表,有goods_id ,click_num 2个字段,字符类型都为string,以‘\t’为分隔符。
create table goods_visit(goods_id string,click_num int)
row format delimited fields terminated by '\t' stored as textfile;
创建完成,查询一下。
show tables;

2.将本地 /data/hive4下的表goods_visit中数据导入到Hive中的goods_visit表中。
sudo chown -R vmuser:vmuser /data/hive4/goods_visit
sudo chown -R vmuser:vmuser /data/hive4/buyer_favorite
sudo chown -R vmuser:vmuser /data/hive4/order_items
load data local inpath'/data/hive4/goods_visit' into table goods_visit;

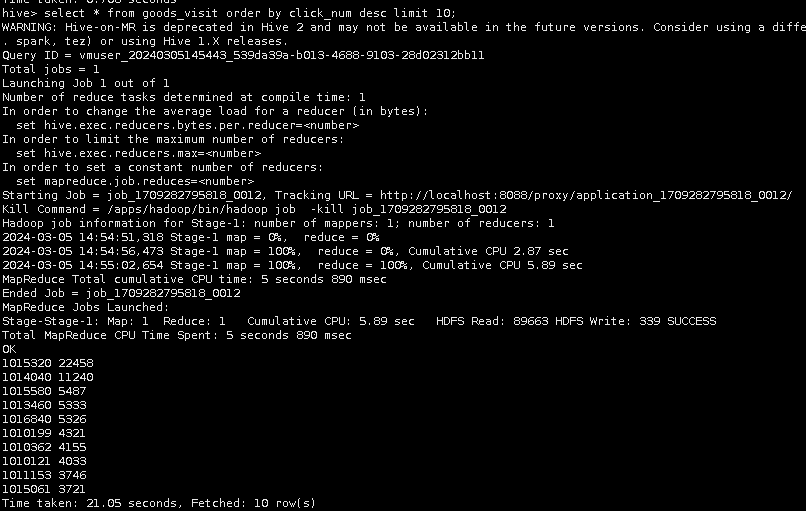
3.使用Order by对商品点击次数从大到小排序,并通过limit取出10条数据。
select * from goods_visit order by click_num desc limit 10;
Sort by 的演示
1为演示Sort by效果 ,我将Reduce个数设置为三个,命令如下:
set mapred.reduce.tasks=3;
2.为某电商创建一个订单明细表,名为order_items,包含item_id 、order_id 、goods_id 、goods_number 、shop_price 、goods_price 、goods_amount 七个字段,字符类型都为string,以‘\t’为分隔符。
create table order_items(item_id string,order_id string,goods_id string,goods_number string,
shop_price string,goods_price string,goods_amount string)
row format delimited fields terminated by '\t' stored as textfile;

3.将本地/data/hive4/下的表order_items中数据导入到Hive中的order_items表中。
load data local inpath '/data/hive4/order_items' into table order_items;

删除表中所有数据:
TRUNCATE TABLE order_items;
4.按商品ID(goods_id)进行排序。
select * from order_items sort by goods_id;
Group by的演示
1.为某电商创建一个买家收藏夹表,名为buy_favorite,有buyer_id 、goods_id 、dt 三个字段,字符类型都为string,以‘\t’为分隔符。
create table buyer_favorite(buyer_id string,goods_id string,dt string)
row format delimited fields terminated by '\t' stored as textfile;

2.将本地/data/hive4/下的表buyer_favorite中数据导入到Hive中的buyer_favorite表中。
load data local inpath '/data/hive4/buyer_favorite' into table buyer_favorite;

3.按dt分组查询每天的buyer_id数量。
select dt,count(buyer_id) from buyer_favorite group by dt;
Distribute by的演示
1为演示Distribute by效果 ,我将Reduce个数设置为三个,命令如下:
set mapred.reduce.tasks=3;
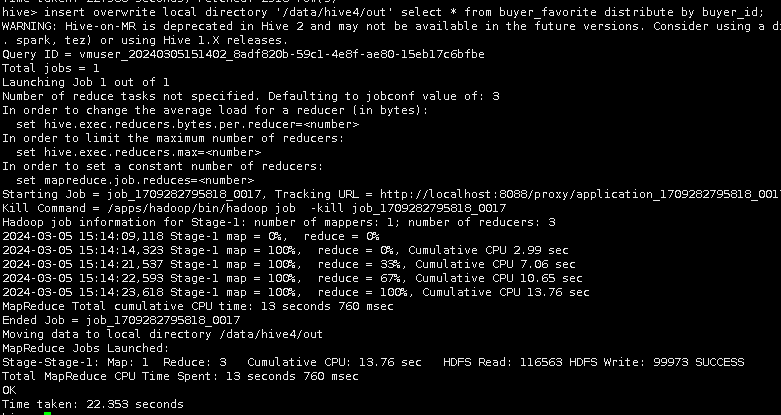
2.使用买家收藏夹表,按用户ID(buyer_id)做分发(distribute by),输出到本地/data/hive4/out中。
insert overwrite local directory '/data/hive4/out' select * from buyer_favorite distribute by buyer_id;
3.切换到linux本地窗口,查看目录/data/hive4/out下的文件。
cd /data/hive4/out
ls

数据按buyer_id分发到三个文件中。
Cluster by 的演示
Cluster by除了具有Distribute by的功能外还兼具Sort by的功能,相当于Distribute by+ Sort by的结合,但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
1.将Reduce个数设置为3个。
set mapred.reduce.tasks=3;
2.按buyer_id将buyer_favorite分发成三个文件,并按buyer_id排序。
select * from buyer_favorite cluster by buyer_id;
Order by 与Sort by 对比
Order by的查询结果是全部数据全局排序,它的Reduce数只有一个,Reduce任务繁重,因此数据量大的情况下将会消耗很长时间去执行,而且可能不会出结果,因此必须指定输出条数。
Sort by是在每个Reduce端做排序,它的Reduce数可以有多个,它保证了每个Reduce出来的数据是有序的,但多个Reduce出来的数据合在一起未必是有序的,因此在Sort by做完局部排序后,还要再做一次全局排序,相当于先在小组内排序,然后只要将各小组排序即可,在数据量大的情况下,可以提升不少的效率。
Distribute by 与Group by 对比
Distribute by是通过设置的条件在Map端拆分数据给Reduce端的,按照指定的字段对数据划分到不同的输出Reduce文件中。
Group by它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理,例如某电商想统计一年内商品销售情况,可以使用Group by将一年的数据按月划分,然后统计出每个月热销商品的前十名。
两者相比,都是按Key值划分数据,都使用Reduce操作,唯一不同的是Distribute by只是单纯的分散数据,而Group by把相同Key的数据聚集到一起,后续必须是聚合操作。
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号