3.3 Hive查询(Hadoop3.0系列)
3.3 Hive查询(Hadoop3.0系列)
【实验目的】
1.了解Hive的SQL基本语法
2.掌握Hive多种查询方式
【实验原理】
Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。
如下图Hive执行流程大致步骤为:
(1)用户提交查询等任务给Driver。
(2)编译器获得该用户的任务Plan。
(3)编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
(4)编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce),最后选择最佳的策略。
(5)将最终的计划提交给Driver。
(6)Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
(7)获取执行的结果。
(8)取得并返回执行结果。
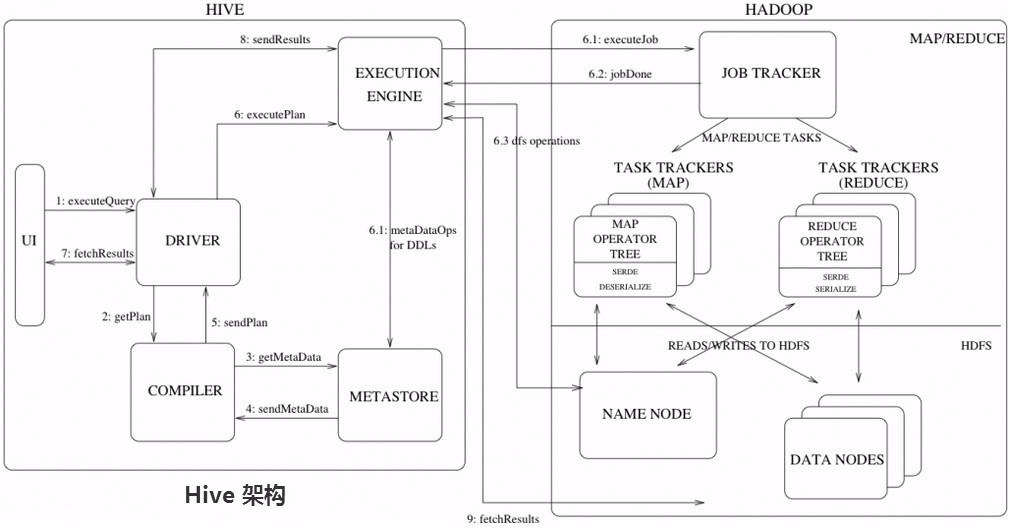
Hive的入口是Driver,执行的SQL语句首先提交到Driver驱动,然后调用Compiler解释驱动,最终解释成MapReduce任务执行,最后将结果返回。

(编译流程)
一条SQL进入Hive经过上述过程,使得一个编译过程变成了一个作业。
(1)首先,Driver会输入一个字符串SQL,然后经过Parser变成AST,这个变成AST的过程是通过Antlr来完成的,也就是Anltr根据语法文件来将SQL变成AST。
(2)AST进入Semantic Analyzer(核心)变成QB(QueryBlock)。一个最简的查询块,通常来讲,一个From子句会生成一个QB,生成QB是一个递归过程,生成的QB经过GenLogical Plan过程,变成了一个有向无环图。
(3)OP DAG经过逻辑优化器,对这个图上的边或者结点进行调整,顺序修订,变成了一个优化后的有向无环图。这些优化过程包括谓词下推(Predicate Push Down),分区剪裁(Partition Prunner),关联排序(Join Reorder)等等。
(4)经过了逻辑优化,这个有向无环图还要能够执行。所以有了生成物理执行计划的过程。Gen Tasks。Hive的作法通常是碰到需要分发的地方,切上一刀,生成一道MapReduce作业。如Group By切一刀,Join切一刀,Distribute By切一刀,Distinct切一刀。这么很多刀砍下去之后,这个逻辑有向无环图就被切成了很多个子图,每个子图构成一个结点。这些结点又连成了一个执行计划图,也就是Task Tree。
(5)对于Task Tree的优化,比如基于输入选择执行路径,增加备份作业等。可以由Physical Optimizer来完成。经过Physical Optimizer,每一个结点就是一个MapReduce作业或者本地作业,就可以执行了。
这就是一个SQL如何变成MapReduce作业的过程。
【实验环境】
AnolisOS8.8
Java 1.8.0
Hadoop-3.0.0
Eclipse-JEE 2022.03
HBase 1.4.10
mysql-8.0.26
Pycharm
apache-hive-2.3.5
【实验内容】
1.掌握Hive的普通查询、别名查询、限定查询与多表联合查询。
2.掌握Hive的多表插入、多目录输出以及使用Shell脚本查看Hive中的表。
【实验步骤】
切换到vmuser用户下,密码(vm123456)
1切换到/apps/hadoop/sbin目录下,启动Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
使用jps查看启动的进程
jps
然后执行启动以下命令,查看Mysql数据库服务是否开启(Mysql用于存放Hive的元数据)
sudo systemctl status mysqld
MYSQL 正在运行
启动Mysql后,在终端命令行界面,直接输入Hive命令,启动Hive命令行。
cd /apps/hive/bin
./hive

2.打开一个新的命令行,切换到vmuser用户(vm123456)
提前创建文件夹hive3。
sudo mkdir -p /data/hive3
sudo chown -R vmuser:vmuser /data/hive3
使用wget命令,下载文件。
cd /data/hive3
wget http://hive3/buyer_log
wget http://hive3/buyer_favorite

 浙公网安备 33010602011771号
浙公网安备 33010602011771号