3.1 Hive 安装部署(Hadoop3.0)
3.1 Hive 安装部署(Hadoop3.0)
【实验目的】
1.了解Hive的安装部署
2.了解Hive的工作原理
【实验原理】
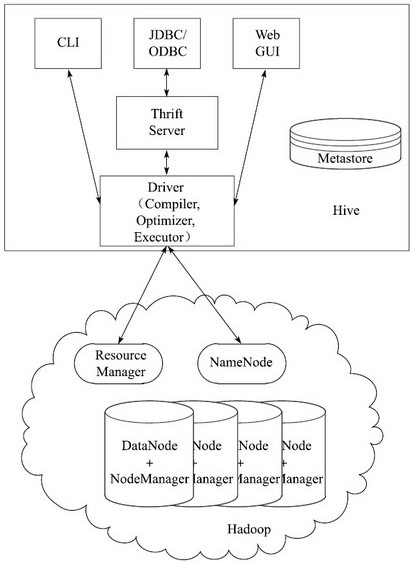
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive构建在基于静态批处理的Hadoop之上,由于Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不适合那些需要低延迟的应用,它最适合应用在基于大量不可变数据的批处理作业,例如,网络日志分析。
Hive的特点是:可伸缩(在Hadoop集群上动态的添加设备)、可扩展、容错、输出格式的松散耦合。
Hive将元数据存储在关系型数据库(RDBMS)中,比如MySQL、Derby中。
Hive有三种模式连接到数据,其方式是:单用户模式,多用户模式和远程服务模式。(也就是内嵌模式、本地模式、远程模式)。
【实验环境】
AnolisOS8.8
Java 1.8.0
Hadoop-3.0.0
Eclipse-JEE 2022.03
HBase 1.4.10
mysql-8.0.26
Pycharm
【实验内容】
在已安装好的Hadoop和MySQL环境基础上,安装并配置Hive。
【实验步骤】
切换到vmuser用户(vm123456)
su vmuser
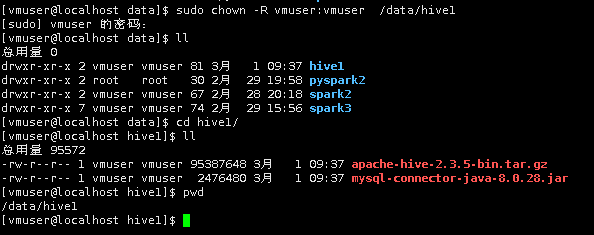
1首先在Linux本地,新建/HDFS/hive1目录,用于存放所需文件。
sudo mkdir -p /data/hive1
切换目录到/HDFS/hive1下,使用wget命令,下载hive所需安装包以及MySQL连接器。
cd /data/hive1
wget http://hadoop3/apache-hive-2.3.5-bin.tar.gz
wget http://hadoop3/mysql-connector-java-8.0.28.jar
2.将/HDFS/hive1目录下的apache-hive-2.3.5-bin.tar.gz,解压缩到/apps目录下。
sudo chown -R vmuser:vmuser /data/hive1
tar -xzvf apache-hive-2.3.5-bin.tar.gz -C /apps/
再切换到/apps目录下,将/apps/apache-hive-2.3.5-bin,重命名为hive。
cd /apps
mv /apps/apache-hive-2.3.5-bin/ /apps/hive
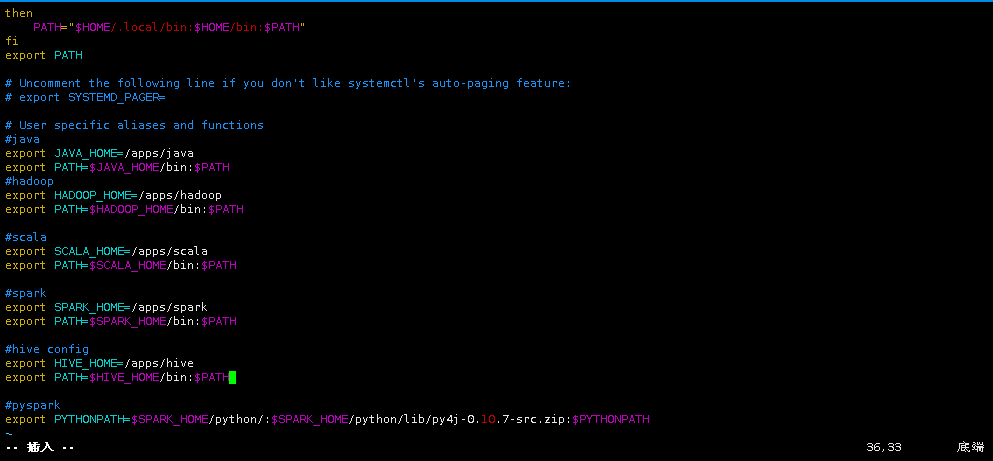
3.使用vim打开用户环境变量。(sudo命令密码:vm123456)
sudo vim ~/.bashrc
将Hive的bin目录,添加到用户环境变量PATH中,然后保存退出。
#hive config
export HIVE_HOME=/apps/hive
export PATH=$HIVE_HOME/bin:$PATH
执行source命令,使Hive环境变量生效。
source ~/.bashrc
4.由于Hive需要将元数据,存储到MySQL中。所以需要拷贝/data/hive1目录下的mysql-connector-java-8.0.28.jar到hive的lib目录下。
cp /data/hive1/mysql-connector-java-8.0.28.jar /apps/hive/lib/
5.下面配置Hive,切换到/apps/hive/conf目录下,并创建Hive的配置文件hive-site.xml。
cd /apps/hive/conf
touch hive-site.xml
使用vim打开hive-site.xml文件。
vim hive-site.xml
并将下列配置项,添加到hive-site.xml文件中。
|
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExsit=true&characterEncoding=latin1&useSSL=false&allowPublicKeyRetrieval=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>strongs</value> </property> </configuration> |
由于Hive的元数据会存储在Mysql数据库中,所以需要在Hive的配置文件中,指定mysql的相关信息。
javax.jdo.option.ConnectionURL:数据库链接字符串。
javax.jdo.option.ConnectionDriverName:连接数据库的驱动包。
javax.jdo.option.ConnectionUserName:数据库用户名。
javax.jdo.option.ConnectionPassword:连接数据库的密码。
此处的数据库的用户名及密码,需要设置为自身系统的数据库用户名及密码。
6.另外,还需要告诉Hive,Hadoop的环境配置。所以我们需要修改hive-env.sh文件。
首先我们将hive-env.sh.template重命名为hive-env.sh。
mv /apps/hive/conf/hive-env.sh.template /apps/hive/conf/hive-env.sh
使用vim打开hive-env.sh文件。
vim hive-env.sh
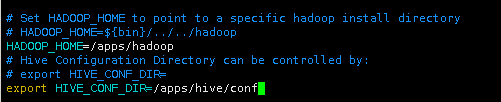
定位到文件末尾,追加Hadoop的路径,以及Hive配置文件的路径到文件中。
|
# Set HADOOP_HOME to point to a specific hadoop install directory # HADOOP_HOME=${bin}/../../hadoop HADOOP_HOME=/apps/hadoop # Hive Configuration Directory can be controlled by: # export HIVE_CONF_DIR= export HIVE_CONF_DIR=/apps/hive/conf |
Mysql安装
https://blog.csdn.net/weixin_40979518/article/details/132661876
https://blog.51cto.com/u_15064632/4842195
https://zhuanlan.zhihu.com/p/632935077
https://www.cnblogs.com/marineblog/p/16118916.html
https://blog.csdn.net/smile_pbb/article/details/135899500 <参考此文档>
https://blog.csdn.net/zhikanjiani/article/details/89072608
https://blog.csdn.net/Hi_Red_Beetle/article/details/88743821
https://blog.csdn.net/yuelai_217/article/details/123048748
https://blog.csdn.net/Hi_Red_Beetle/article/details/88743821
https://blog.csdn.net/weixin_45713608/article/details/128838956
yum -y install mysql-server –nogpgcheck
|
# service mysqld status 查看mysql当前的状态 # systemctl status mysqld # service mysqld stop 停止mysql # systemctl stop mysqld # service mysqld restart 重启mysql # systemctl restart mysqld # service mysqld start 启动mysql # systemctl start mysqld |
https://blog.csdn.net/weixin_46589575/article/details/127044881
<后部分>
|
mysql> use mysql; mysql> show tables; select user,authentication_string from user; ALTER USER 'root'@'localhost' IDENTIFIED BY 'strongs'; flush privileges; exit; |
mysql -h localhost -P 3306 -u root -p
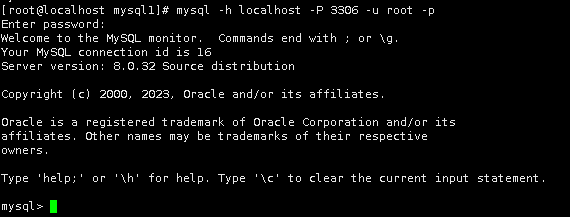

7.下一步是配置MySQL,用于存储Hive的元数据。
首先,需要保证MySQL已经启动。执行以下命令,查看MySQL的运行状态。
sudo service mysqld status
sudo systemctl status mysqld
若MySQL未启动,则执行启动命令。
sudo service mysqld start
service mysqld start
8.开启MySQL数据库。(密码为strongs)
sudo mysql -u root -p
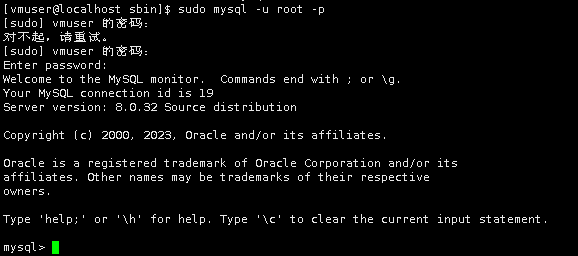
创建名为hive的数据库,编码格式为latin1,用于存储元数据。
create database hive CHARACTER SET latin1;

查看数据库是否创建成功。
show databases;
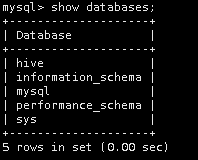
下面,输入exit退出Mysql。
9.执行测试。
由于Hive对数据的处理,依赖MapReduce计算模型,所以需要保证Hadoop相关进程已经启动。
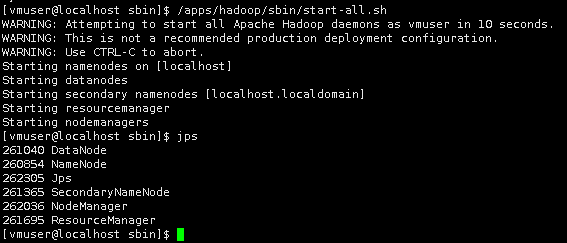
启动Hadoop。
/apps/hadoop/sbin/start-all.sh
输入jps,查看进程状态
jps
初始化元数据库
schematool -dbType mysql -initSchema

启动Hadoop后,在终端命令行界面,直接输入hive便可启动Hive命令行模式。
hive

输入HQL语句查询数据库,测试Hive是否可以正常使用。
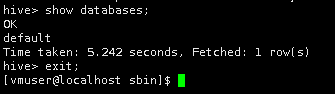
Hive安装完毕。
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号