2.7 案例:用户价值分类结果可视化展示
2.7 案例:用户价值分类结果可视化展示
【实验目的】
将用户价值分类结果导入MySQL数据库
1.掌握Python连接数据库方式
2.掌握python导入数据到数据库的方式
【实验原理】
常见的Python读取数据源
文件格式和文件系统。对于存储在本地文件系统或分布式文件系统(比如HDFS)中的数据,Spark可以访问很多种不同的文件格式。包括文本文件、JSON、SequenceFile、以及protocol buffer。
Spark SQL中的结构化数据源。
数据库和键值存储。Spark自带的库以及一些第三方库,可以用来连接HBase、JDBC源。
Python连接MySql工具:PyMySQL
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb
【实验环境】
AnolisOS 8.8
hadoop-3.0.0
spark-2.4.3
pyspark
python3.5
mysql-5.7.26
Pycharm-2018.3.2
pymysql==0.10.1
【实验内容】
将用户价值分类结果导入MySQL数据库
【实验步骤】
切换用户vmuser(密码:vm123456)
1.打开Linux终端模拟器,创建目录,如果目录已经存在,则无需重复创建
mkdir -p /data/uservalue
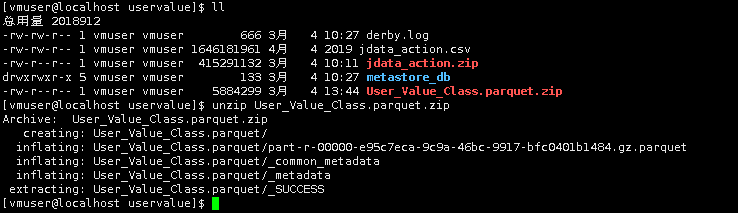
2.进入/data/uservalue,下载数据
cd /data/uservalue
wget http://uservalue/User_Value_Class.parquet.zip
3.解压文件
unzip User_Value_Class.parquet.zip
4.新打开一个终端,无需转换操作用户,直接执行如下命令
使用pip命令,安装pymysql到python3.5上。
pip3 install pymysql -i https://pypi.doubanio.com/simple
python3 -m pip install --upgrade pip
pip3 install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple

安装实验中所需要的库
pip3 install pyarrow
5.回到最开始的终端执行如下命令,在Linux终端,输入以下命令启动MySQL服务,密码:'strongs'
sudo service mysqld status
mysql -h localhost -P 3306 -u root -p
进入MySQL库,密码为:strongs
mysql -u root -p
6.创建uservalue 数据库
create database uservalue default charset utf8 collate utf8_general_ci;
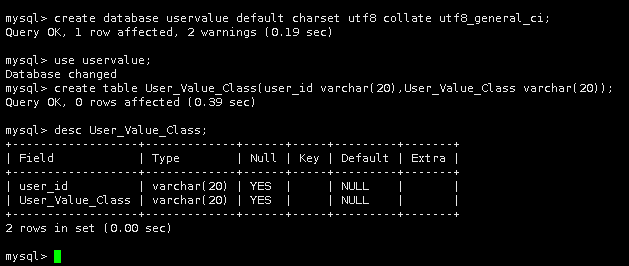
7.切换到uservalue 库
use uservalue;
8.创建表User_Value_Class
create table User_Value_Class(user_id varchar(20),User_Value_Class varchar(20));
9.查看User_Value_Class表数据结构
10.vmuser 账户进入图形界面
打开Pycharm,点击【新建项目】,位置修改为:/home/vmuser/PycharmProjects/UserValue,取消掉创建main.py的对号
11.在UserValue项目下,新建python文件,取名为User_Value_Class
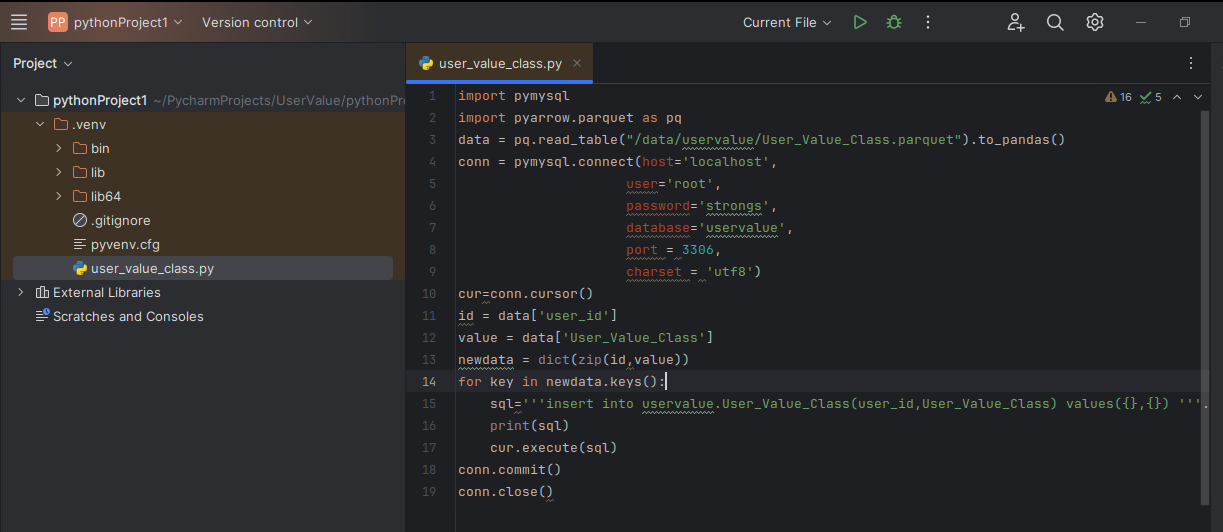
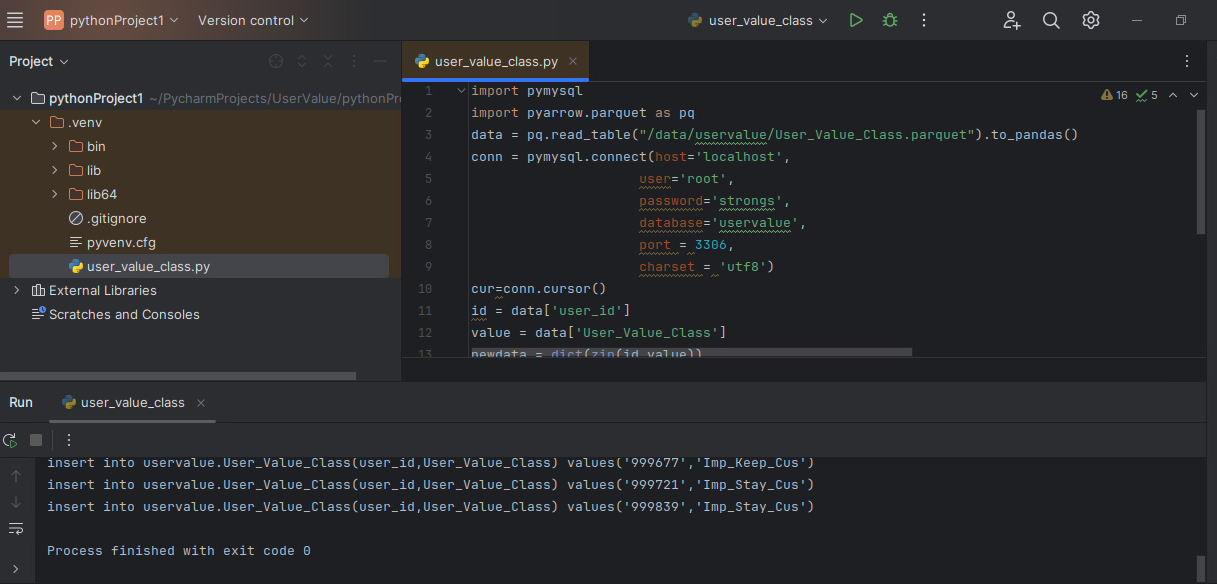
12.打开User_Value_Class.py编写代码
|
import pymysql import pyarrow.parquet as pq data = pq.read_table("/data/uservalue/User_Value_Class.parquet").to_pandas() conn = pymysql.connect(host='localhost', user='root', password='strongs', database='uservalue', port = 3306, charset = 'utf8') cur=conn.cursor() id = data['user_id'] value = data['User_Value_Class'] newdata = dict(zip(id,value)) for key in newdata.keys(): sql='''insert into uservalue.User_Value_Class(user_id,User_Value_Class) values({},{}) '''.format("'"+key+"'","'"+newdata.get(key)+"'") print(sql) cur.execute(sql) conn.commit() conn.close() |

13.运行文件,控制台显示插入sql命令,同时数据会插入数据库中
说明:由于数据量大,插入数据时间较长,请耐心等待。
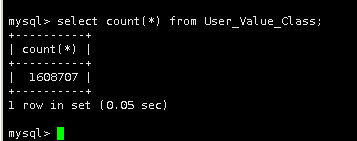
14.在数据库中查看结果
select count(*) from User_Value_Class;
15.查看前10条数据
select * from User_Value_Class limit 10;
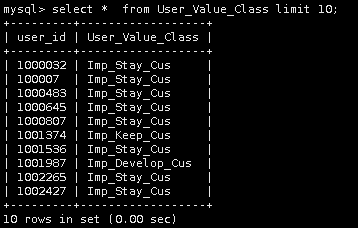
如上所示:数据已经插入MySQL数据库中。
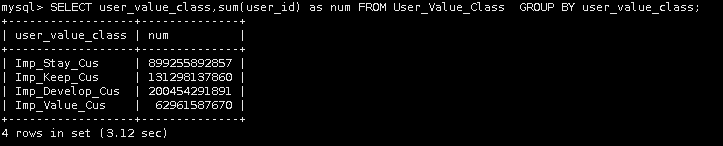
【一、统计不同类型价值用户的数量】
11.统计不同类型价值用户的数量
SELECT user_value_class,sum(user_id) as num FROM User_Value_Class GROUP BY user_value_class;
【二、将不同类型价值用户可视化展示】
12.在项目下新建python文件,取名为:User_Value_Class_pie
13.连接数据库
|
import pymysql # 打开数据库连接 db = pymysql.connect(host='localhost', user='root', password='strongs', database='user_value') |
14.查询数据
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据。
fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
fetchall(): 接收全部的返回结果行.
rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
|
# 2.使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 使用 execute() 方法执行 SQL 查询 cursor.execute("SELECT user_value_class,sum(user_id) as num FROM User_Value_Class GROUP BY user_value_class;") # 使用 fetchall() 方法获取多条数据 data = cursor.fetchall() #将不同类型用户的名称和数量分别存储在列表中 user_value_class=[] num=[] for row in data : user_value_class.append(row[0]) num.append(row[1]) |
15.Matplotlib绘制饼图
|
# 3.matplotlib绘制饼图 import matplotlib.pyplot as plt import matplotlib.font_manager as fm #字体管理器 my_font = fm.FontProperties(fname="/data/uservalue/simhei.ttf") colors = ['DarkGoldenrod','DarkSalmon','BurlyWood','DarkKhaki'] plt.figure(figsize=(10, 10)) plt.pie(num, labels=user_value_class, autopct="%1.2f%%", colors=colors, textprops={'fontsize': 14}, labeldistance=1.05) plt.legend(fontsize=10,loc=4) plt.title("用户价值分类数量占比", fontsize=24,fontproperties=my_font) plt.show() |
16.关闭数据库连接
|
#4. 关闭数据库连接 db.close() |
17.完整代码为:
|
import pymysql # 1.打开数据库连接 db = pymysql.connect(host='localhost', user='root', password='strongs', database='uservalue')
# 2.使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 使用 execute() 方法执行 SQL 查询 cursor.execute("SELECT user_value_class,sum(user_id) as num FROM User_Value_Class GROUP BY user_value_class;") # 使用 fetchall() 方法获取多条数据 data = cursor.fetchall()
#将不同类型用户的名称和数量分别存储在列表中 user_value_class=[] num=[] for row in data : user_value_class.append(row[0]) num.append(row[1]) # 3.matplotlib绘制饼图 import matplotlib.pyplot as plt colors = ['DarkGoldenrod','DarkSalmon','BurlyWood','DarkKhaki'] plt.figure(figsize=(10, 6)) plt.pie(num, labels=user_value_class, autopct="%1.2f%%", colors=colors, textprops={'fontsize': 14}, labeldistance=1.05) plt.legend(fontsize=10,loc=4) plt.title("User Value Classification", fontsize=24) #plt.show() plt.savefig("/data/uservalue/test.png") #4. 关闭数据库连接 db.close() |
到/data/uservalue/下载test.png文件
18.选中User_Value_Class_pie.py,【鼠标右键】-【运行】
19.结果如下所示:
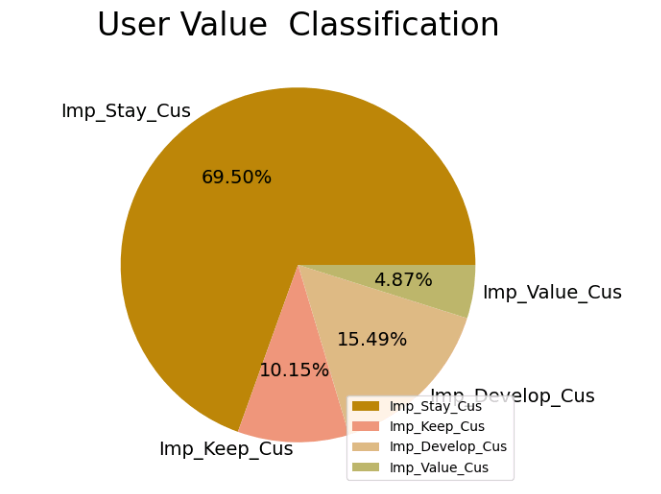
分析:
可以看出,重要价值用户Imp_Value_Cus,他们是最优质的用户,需要重点关注并保持, 应该提高满意度,增加留存;
对于重要保持用户Imp_Keep_Cus,他们最近有购买,但购买频率不高,可以通过活动等提高其购买频率;
对于重要发展用户Imp_Develop_Cus,他们虽然最近没有购买,但以往购买频率高,可以做优惠券或活动触达,以防止流失;
对于一般价值用户Imp_Stay_Cus,他们最近没有购买,以往购买频率也不高,特别容易流失,所以应该赠送优惠券或推送活动信息,唤醒购买意愿。
总结:
本次统计周期内,重要挽留客户占比最大,达到69.50%,其次是重要发展客户,比例为15.49%。重要价值客户和重要保持客户占比较低。大部分的用户消费频次较低,平台需加大推送宣传力度,采取多样营销措施,加强促销活动,提高重要挽留客户和重要发展客户的消费频次,促使其向其他用户价值类型转变。针对于重要价值客户和重要保持客户,提供差异化的VIP服务,提高VIP客户的购物体验,同时,将VIP服务作为一个重要的宣传渠道,吸引普通用户向VIP用户转变。
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号