2.6 案例:PySpark实现用户价值分类
2.6 案例:PySpark实现用户价值分类
【实验目的】
1.分析RFM各自的含义
2.创建RFM(R值)得分表
3.创建RFM(F值)得分表
4.创建用户价值分类表
【实验原理】
RFM解读:
RFM分析法对用户进行量化分类,便于对客户进行差异化营销。RFM模型含义如下:
R,Recency,近度指标,表示客户最近一次交易时间到现在的间隔
F,Frequency,频度指标,表示客户在最近一段时间内交易的次数
M,Monetary,额度指标,表示客户在最近一段时间内交易的金额
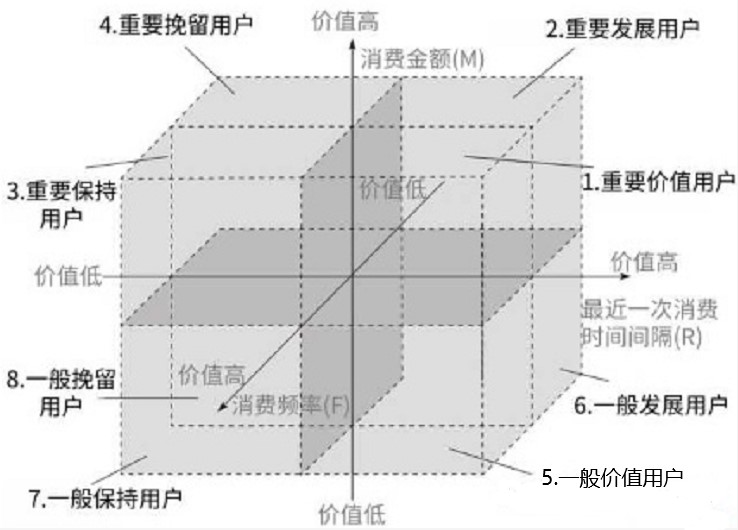
本次分析中,由于缺少消费金额数据,仅从R和F两个维度进行客户分类分析,分类原则如下表:
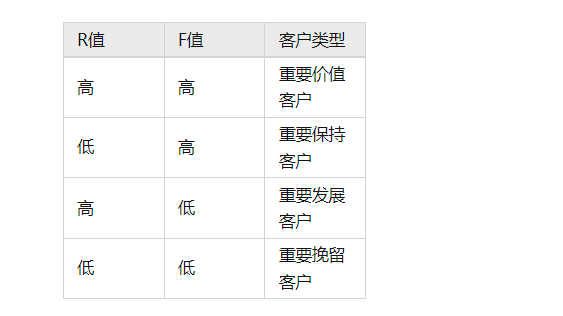
R值定义:
对于R值,作如下定义:
定义消费时间间隔为消费日期距统计周期内最近日期即2018-04-14的时间差;
消费时间间隔大于12天,R=1
消费时间间隔大于等于9天,小于12天,R=2
消费时间间隔大于等于6天,小于9天,R=3
消费时间间隔大于等于3天,小于6天,R=4
消费时间间隔小于3天,R=5
F值定义:
定义消费频次为统计周期内用户的消费天数,同一天多次消费记为1次
消费频次大于等于11,F=5
消费频次大于等于8,小于11,F=4
消费频次大于等于5,小于8,F=3
消费频次大于等于2,小于5,F=2
消费频次小于2,F=1
用户价值分类:
基于创建的用户分类表,根据用户的R,F得分进行分类:
|
SELECT r.用户ID, (CASE WHEN r.用户R值评价='高' AND f.用户F值评价='高' THEN '重要价值客户' WHEN r.用户R值评价='高' AND f.用户F值评价='低' THEN '重要发展客户' WHEN r.用户R值评价='低' AND f.用户F值评价='高' THEN '重要保持客户' WHEN r.用户R值评价='低' AND f.用户F值评价='低' THEN '重要挽留客户' ELSE NULL END) AS 用户价值分类 FROM 用户r值等级分类表 r INNER JOIN 用户f值等级分类表 f ON r.'用户ID'=f.'用户ID' |
【实验环境】
AnolisOS 8.8
hadoop-3.0.0
spark-2.4.3
pyspark
python2.7
【实验内容】
创建用户价值分类表
【实验步骤】
【步骤一:环境准备】
切换用户vmuser(密码:vm123456)
1.打开Linux终端模拟器,创建目录,如果目录已经存在,则无需重复创建
mkdir -p /data/uservalue
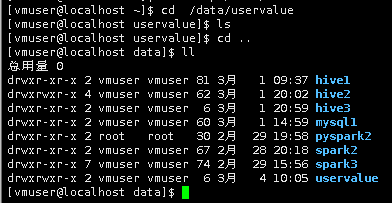
2.进入/data/uservalue,使用ls命令查看文件
cd /data/uservalue
ls
说明:如果jdata_action.zip文件已存在,则无需执行下面命令,重复下载数据
wget http://uservalue/jdata_action.zip
sudo chown -R vmuser:vmuser /data/uservalue/jdata_action.zip

3.解压文件
unzip jdata_action.zip
4.切换到/apps/hadoop/sbin目录下,启动hadoop相关进程(如果Hadoop进程已经启动,则无需执行下列启动命令)
cd /apps/hadoop/sbin
./start-all.sh
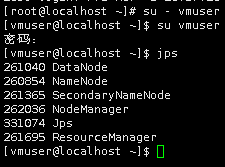
查看hadoop进程是否已经启动
jps
5.在HDFS上创建目录,将jdata_action.csv上传到HDFS中的uservalue目录下(如果HDFS中已经存在jdata_action.csv ,则无需执行下面命令)
hadoop fs -mkdir -p /uservalue
hadoop fs -put /data/uservalue/jdata_action.csv /uservalue
6.开启PySpark
PYSPARK_PYTHON=python3.6 pyspark
【步骤二:认识数据】
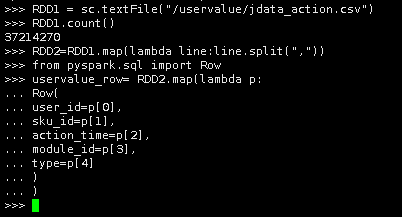
7.创建RDD
使用textFile()方法读取HDFS上的jdata_action.csv文件,赋值给RDD1并统计文件内容有多少行
RDD1 = sc.textFile("/uservalue/jdata_action.csv")
RDD1.count()
8.使用map函数处理每一项数据,用lambda语句创建匿名函数传入line参数,在匿名函数中,line.split(“,”)表示按照逗号分隔获取每一个字段
RDD2=RDD1.map(lambda line:line.split(","))

9.创建DataFrame
导入row模块,通过RDD2创建DataFrame,定义DataFrame的每一个字段名与数据类型
字段说明:
user_id:用户唯一标识
sku_id:商品唯一标识
action_Time:行为时间
module_id:如果是下单,存储订单号;如果是浏览,存储sessionid
type:行为类型:1.浏览;2.下单;3.关注;4.评论;5.加购物车
|
from pyspark.sql import Row uservalue_row= RDD2.map(lambda p: Row( user_id=p[0], sku_id=p[1], action_time=p[2], module_id=p[3], type=p[4] ) ) |
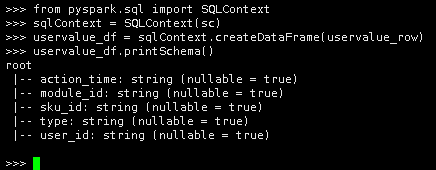
10.创建了uservalue_row之后,使用sqlContext.createDataFrame()方法写入uservalue_row数据,创建DataFrame,然后使用printSchema()方法查看DataFrames的Schema
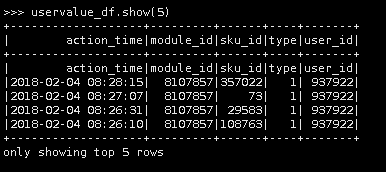
11.接下来,我们可以使用.show()方法来查看前5行数据
uservalue_df.show(5)
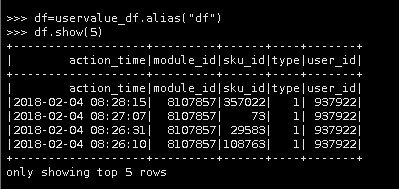
12.我们也可以使用.alias()方法来为DadaFrame创建别名,例如uservalue_df.alias("df"),后续我们就可以使用这个别名执行命令了
df=uservalue_df.alias("df")
df.show(5)
13.创建PySpark SQL
下面我们使用registerTempTable方法将df转换为uservalue_tb表
sqlContext.registerDataFrameAsTable(df, "uservalue_tb")
14.接下来,我们可以使用sqlContext.sql()输入sql语句,使用select关键字查询文件内容行数,并使用from关键字指定要查询的表,最后使用show()方法显示查询结果
sqlContext.sql("select count(*) counts from uservalue_tb").show()

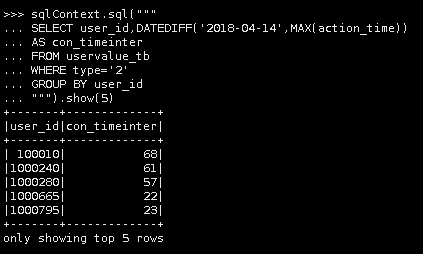
15.编写SQL,查询用户ID、消费时间间隔(从2018-04-14到用户行为时间(下单))。
SQL解读:
GROUP BY user_id:根据用户id分组
type=2:表示下单用户
DATEDIFF('2018-04-14',MAX(action_time)):返回日期从2018-04-14到用户行为时间间隔天数最大差值
|
sqlContext.sql(""" SELECT user_id,DATEDIFF('2018-04-14',MAX(action_time)) AS con_timeinter FROM uservalue_tb WHERE type='2' GROUP BY user_id """).show(5) |
【步骤三:创建用户R值等级分类表】
(1)创建R值得分表R_SCORE_TB(消费时间间隔得分表)
1.创建RFM得分表(R值),对于R值,作如下定义:
定义消费时间间隔为消费日期距统计周期内最近日期即2018-04-14的时间差;
消费时间间隔大于12天,R=1
消费时间间隔大于等于9天,小于12天,R=2
消费时间间隔大于等于6天,小于9天,R=3
消费时间间隔大于等于3天,小于6天,R=4
消费时间间隔小于3天,R=5
|
R_SCORE=sqlContext.sql(""" SELECT user_id, (CASE WHEN con_timeinter >= 12 THEN 1 WHEN con_timeinter >= 9 AND con_timeinter< 12 THEN 2 WHEN con_timeinter >= 6 AND con_timeinter< 9 THEN 3 WHEN con_timeinter >= 3 AND con_timeinter< 6 THEN 4 WHEN con_timeinter< 3 THEN 5 ELSE 0 END )AS R_SCORE FROM (SELECT user_id,DATEDIFF('2018-04-14',MAX(action_time)) AS con_timeinter FROM uservalue_tb WHERE type='2' GROUP BY user_id) rencency ORDER BY R_SCORE DESC """) |
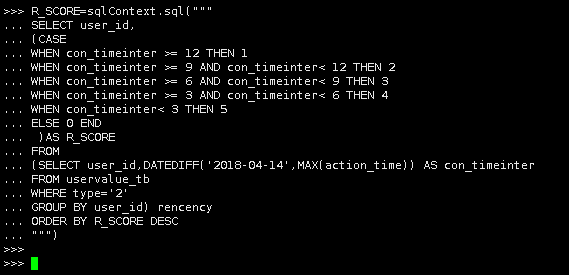
我们称R_SCORE为“消费时间间隔”
2. R_SCORE是一个DataFrame,将其转换为表R_SCORE_TB,称为“消费时间间隔得分表”
sqlContext.registerDataFrameAsTable(R_SCORE, "R_SCORE_TB")
3.查看表中数据
sqlContext.sql("select user_id,R_SCORE counts from R_SCORE_TB limit 5").show()
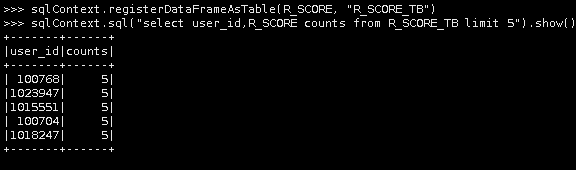
通过上述步骤,我们已经创建了用户RFM(R值)得分表R_SCORE_TB。
(2)创建R值等级分类表USER_R_RANK_TB
4.以平均值作为参照,各维度得分大于其平均值的定义为高,小于等于其平均值的定义为低。
创建“R得分值”平均值表
|
sqlContext.registerDataFrameAsTable( sqlContext.sql(""" SELECT AVG(R_SCORE) FROM R_SCORE_TB """) , "AVG_R_SCORE_TB") |
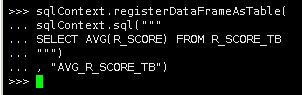
5.查询表中平均值
|
sqlContext.sql(""" select * from AVG_R_SCORE_TB """).show() |
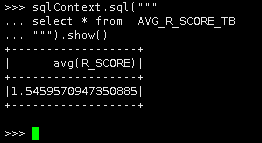
说明:平均值约为1.546
6.创建“用户R值等级分类”的DataFrame
|
USER_R_RANK=sqlContext.sql(""" SELECT user_id,R_SCORE, (CASE WHEN R_SCORE > 1.546 THEN 'high' ELSE 'low' END ) AS User_R_Assess FROM R_SCORE_TB """) |
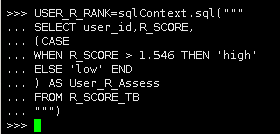
查看数据
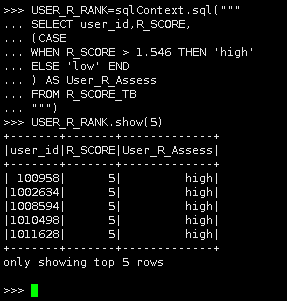
7.创建“用户R值等级分类表”,将USER_R_RANK转换为表"USER_R_RANK_TB"
sqlContext.registerDataFrameAsTable(USER_R_RANK, "USER_R_RANK_TB")
说明:通过上述步骤,已经完成了“用户R值等级分类表”的创建。
【步骤四:创建用户F值等级分类表】
(1)创建F值得分表F_SCORE_TB(消费频次得分表)
1.创建RFM(F值)得分表,对于F值,作如下定义:
定义消费频次为统计周期内用户的消费天数,同一天多次消费记为1次
消费频次小于2,F=1
消费频次大于等于2,小于5,F=2
消费频次大于等于5,小于8,F=3
消费频次大于等于8,小于11,F=4
消费频次大于等于11,F=5
|
F_SCORE=sqlContext.sql(""" SELECT user_id, (CASE WHEN con_freq >= 11 THEN 5 WHEN con_freq >= 8 AND con_freq< 11 THEN 4 WHEN con_freq >= 5 AND con_freq< 8 THEN 3 WHEN con_freq >= 2 AND con_freq< 5 THEN 2 WHEN con_freq< 2 THEN 1 ELSE 0 END )AS F_SCORE FROM (SELECT user_id,COUNT(DISTINCT action_time) AS con_freq FROM uservalue_tb WHERE type='2' GROUP BY user_id) frequency ORDER BY F_SCORE DESC """) |
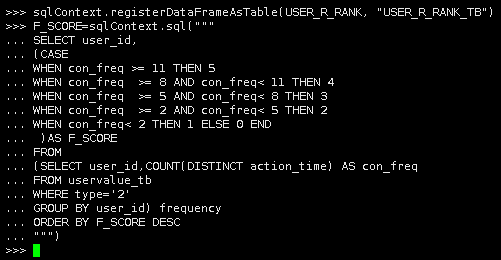
2.我们称F_SCORE为“消费频次得分”,F_SCORE是一个DataFrame,将其转换为表F_SCORE_TB,称为“消费频次得分表”
sqlContext.registerDataFrameAsTable(F_SCORE, "F_SCORE_TB")
3.查看表中数据
sqlContext.sql("select user_id,F_SCORE counts from F_SCORE_TB").show(5)
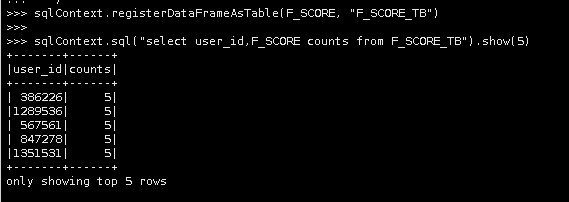
通过上述步骤,我们已经创建了用户RFM(R值)得分表F_SCORE_TB。
(2)创建F值等级分类表USER_F_RANK_TB
4.创建“F得分值”平均值表
|
sqlContext.registerDataFrameAsTable( sqlContext.sql(""" SELECT AVG(F_SCORE) FROM F_SCORE_TB """) , "AVG_F_SCORE_TB") |
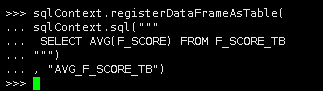
5.获取平均值
|
sqlContext.sql(""" select * from AVG_F_SCORE_TB """).show() |
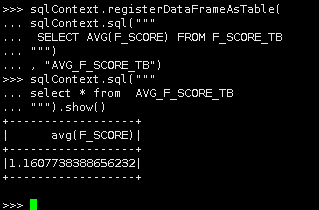
说明:平均值约为1.16
6.创建“用户F值等级分类”USER_F_RANK
|
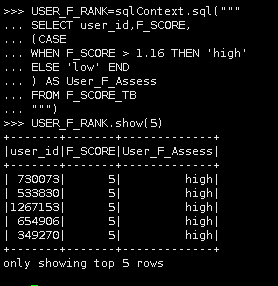
USER_F_RANK=sqlContext.sql(""" SELECT user_id,F_SCORE, (CASE WHEN F_SCORE > 1.16 THEN 'high' ELSE 'low' END ) AS User_F_Assess FROM F_SCORE_TB """) |
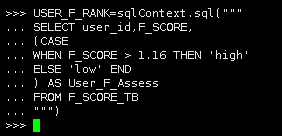
USER_F_RANK.show(5)
7.创建用户F值等级分类表,将USER_F_RANK转换为表USER_F_RANK_TB
sqlContext.registerDataFrameAsTable(USER_F_RANK, "USER_F_RANK_TB")
通过上述步骤,我们已经创建了用户R值等级分类表USER_R_RANK_TB和F值等级分类表USER_F_RANK_TB。
通过上述步骤,我们已经创建了用户R值等级分类表USER_R_RANK_TB和F值等级分类表USER_F_RANK_TB。
【步骤五:创建用户分类表】
1. 基于创建的用户分类表,根据用户的R,F得分进行分类:
重要价值客户:用户R值评价='高' 并且 用户F值评价='高'
重要发展客户:用户R值评价='高' 并且 用户F值评价='低'
重要保持客户:用户R值评价='低' 并且 用户F值评价='高'
重要挽留客户:用户R值评价='低' 并且 用户F值评价='低'
编写查询用户价值分类的SQL
|
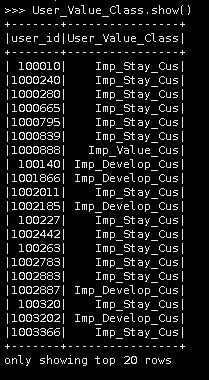
User_Value_Class= sqlContext.sql(""" SELECT r.user_id, (CASE WHEN r.User_R_Assess='high' AND f.User_F_Assess='high' THEN 'Imp_Value_Cus' WHEN r.User_R_Assess='high' AND f.User_F_Assess='low' THEN 'Imp_Develop_Cus' WHEN r.User_R_Assess='low' AND f.User_F_Assess='high' THEN 'Imp_Keep_Cus' WHEN r.User_R_Assess='low' AND f.User_F_Assess='low' THEN 'Imp_Stay_Cus' ELSE NULL END) AS User_Value_Class FROM USER_R_RANK_TB r INNER JOIN USER_F_RANK_TB f ON r.user_id=f.user_id """) |
2.查看数据
user_Value_Class.show()
3.创建用户价值分类表User_Value_Class_TB
sqlContext.registerDataFrameAsTable(User_Value_Class, "User_Value_Class_TB")
4.保存用户价值分类结果
User_Value_Class.coalesce(1).write.option("header","true").save("/uservalue/User_Value_Class.parquet")

参数解读:
coalesce(1):文件分区设置为1
write.mode("overwrite"):保存方式为覆盖
option("header","true"):保存表列名
save("/uservalue/User_Value_Class.parquet"):保存为parquet文件格式,存储路径为集群的/uservalue/
通过本实验任务,我们已经创建了用户价值分类表User_Value_Class_TB并查看分类后的结果。
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号