2.5 PySpark SQL-数据表操作
2.5 PySpark SQL-数据表操作
【实验目的】
1.了解PySpark Shell
2.学习使用PySpark Shell模式,创建表及查询数据
【实验原理】
Spark SQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升,但是,随着Spark的发展,由于Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。SparkSQL抛弃了原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-MemoryColumnarStorage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
【实验环境】
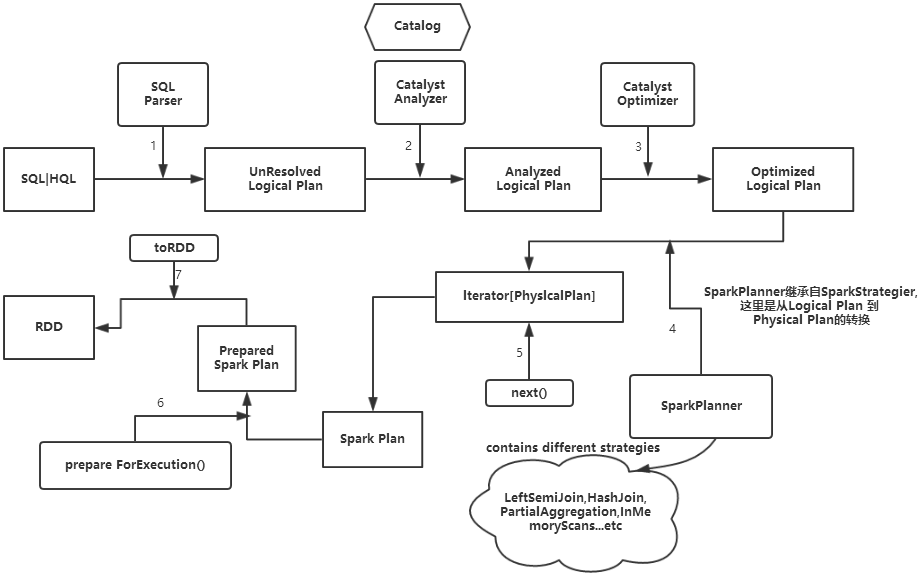
SQLContext具体的执行过程如下:
(1)SQL | HQL语句经过SqlParse解析成UnresolvedLogicalPlan。
(2)使用analyzer结合数据字典(catalog)进行绑定,生成resolvedLogicalPlan,在这个过程中,Catalog提取出SchemRDD,并注册类似case class的对象,然后把表注册进内存中。
(3)Analyzed Logical Plan经过Catalyst Optimizer优化器优化处理后,生成Optimized Logical Plan,该过程完成以后,以下的部分在Spark core中完成。
(4)Optimized Logical Plan的结果交给SparkPlanner,然后SparkPlanner处理后交给PhysicalPlan,经过该过程后生成Spark Plan。
(5)使用SparkPlan将LogicalPlan转换成PhysicalPlan。
(6)使用prepareForExecution()将PhysicalPlan转换成可执行物理计划。
(7)使用execute()执行可执行物理计划。
(8)生成DataFrame。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等。
【实验环境】
AnolisOS 8.8
Java 1.8.0
Hadoop-3.0.0
scala-2.12.8
spark-2.4.3
PySpark
【实验内容】
使用PySpark SQL演示创建表,查询数据的操作。
【实验步骤】
切换用户vmuser(密码:vm123456)
su – vmuser
1切换对应目录下,启动Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
2.使用jps查看启动的进程
jps
3.在Linux任意目录下启动pyspark
PYSPARK_PYTHON=python pyspark
PYSPARK_PYTHON=python3.6 pyspark
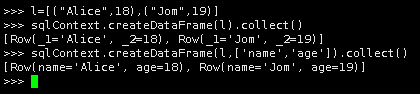
4.第一种创建DataFrame方法
l=[("Alice",18),("Jom",19)]
sqlContext.createDataFrame(l).collect()
sqlContext.createDataFrame(l,['name','age']).collect()
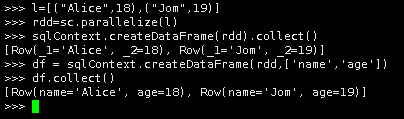
5.第二种创建DataFrame方法
l=[("Alice",18),("Jom",19)]
rdd=sc.parallelize(l)
sqlContext.createDataFrame(rdd).collect()
df = sqlContext.createDataFrame(rdd,['name','age'])
df.collect()
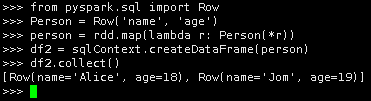
6.第三种创建DataFrame方法
from pyspark.sql import Row
Person = Row('name', 'age')
person = rdd.map(lambda r: Person(*r))
df2 = sqlContext.createDataFrame(person)
df2.collect()
7.第四种创建DataFrame方法
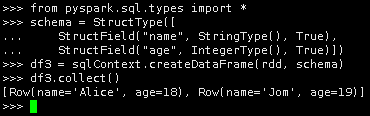
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)])
df3 = sqlContext.createDataFrame(rdd, schema)
df3.collect()
8.使用registerDataFrameAsTable(df, tableName)方法将DataFrame转换为table
sqlContext.registerDataFrameAsTable(df3, "table1")
<注意:这里需要安装Hive和Mysql ,具体内容参考3.1 Hive 安装部署(Hadoop3.0)>

9.使用sql查看表的全部信息,查看表的行数
sqlContext.sql("select * from table1").collect()
sqlContext.sql("select count(*) as count from table1").collect()

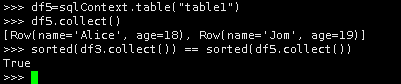
10.使用table(tableName)将表生成一个被声明表的DataFrame。
df5=sqlContext.table("table1")
df5.collect()
sorted(df3.collect()) == sorted(df5.collect())
11.使用tableNames(dbName=None)查看当前库中的所有表,返回一个布尔型。
"table1" in sqlContext.tableNames()

12.使用tables(dbName=None)查看当前库中的所有表,返回一个包含所有表名的DataFrame.
df6 = sqlContext.tables()
df6.filter("tableName = 'table1'").first()

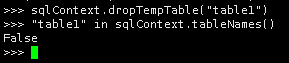
13.删除表dropTempTable(tableName)
sqlContext.dropTempTable("table1")
"table1" in sqlContext.tableNames()
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号