2.4 PySpark SQL-DataFrame文件处理
2.4 PySpark SQL-DataFrame文件处理
【实验目的】
1.掌握PySpark SQL的基本操作
2.了解PySpark SQL对文件的存储
【实验原理】
Spark SQL重要的是操作DataFrame,DataFrame本身提供了Save和Load的操作,
Load:可以创建DataFrame。
Save:把DataFrame中的数据保存到文件或者说用具体的格式来指明我们要读取的文件类型,以及用具体的格式来指出我们要输出的文件是什么类型。
Spark SQL执行基本操作时,内部结构流程图如下:
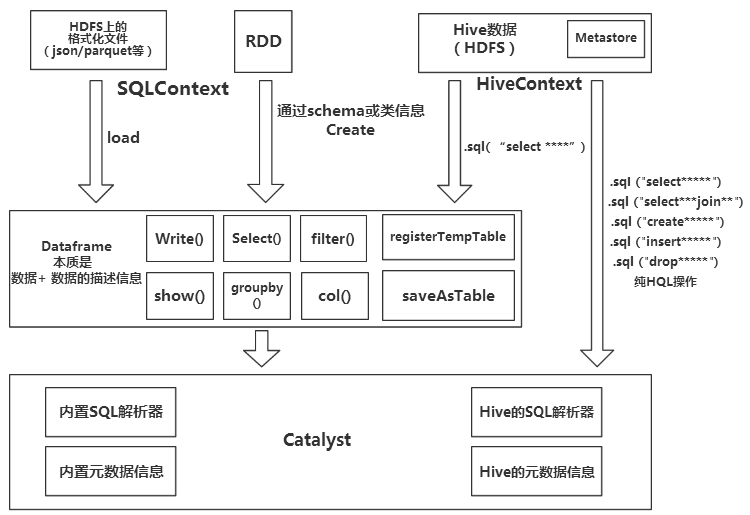
DataFrame本质是数据 + 数据的描述信息(结构元信息)。
所有的上述SQL及DataFrame操作最终都通过Catalyst翻译成Spark程序RDD操作代码。
Spark SQL前身是Shark,大量依赖Hive项目的jar包与功能,但在上面的扩展越来越难,因此出现了Spark SQL,它重写了分析器,执行器脱离了对Hive项目的大部分依赖,基本可以独立去运行,只用到Hive项目的两个地方:
(1)借用了Hive词汇分析的jar即HiveQL解析器
(2)借用了Hive的metastore和数据访问API即Hive Catalog
也就是说上图的左半部分的操作,全部用的是SparkSQL本身自带的内置SQL解析器解析SQL进行翻译,用到内置元数据信息(比如结构化文件中自带的结构元信息,RDD的schema中的结构元信息)右半部分则是走的Hive的HQL解析器,还有Hive元数据信息。因此左右两边的API调用的底层类会有不同。
SQLContext使用:
1.简单的解析器(Scala语言写的SQL解析器)比如:
(1)在半结构化的文件里面使用SQL查询时,是用这个解析器解析的。
(2)访问(半)结构化文件的时候,通过sqlContext使用schema,类生成DataFrame,然后DataFrame注册为表时,registerTempTable(注册临时表)然后从这个表里面进行查询时,即使用的简单的解析器。
simpleCatalog此对象中存放关系(表),比如我们指定的schema信息,类的信息,都是关系信息。
2.HiveContext使用:
(1)HiveQL解析器支持Hive的HQL语法,如只有通过HiveContext生成的DataFrame才能调用saveAsTable操作。
(2)hiveCatalog(存放数据库和表的元数据信息)
【实验环境】
Anolis OS 8.8
Java 1.8.0
Hadoop-3.0.0
scala-2.12.8
spark-2.4.3
PySpark
【实验内容】
将Linux本地的goods_visit.json文件上传到HDFS上/input/pyspark2目录下,使用Spark读取HDFS上/input/pyspark2目录下的goods_visit.json文件,然后用SparkSQL对goods_visit.json文件进行各种操作,最后将Spark上的goods_visit.json文件保存为parquet格式存储到HDFS上。
【实验步骤】
切换用户vmuser(密码:vm123456)
su – vmuser
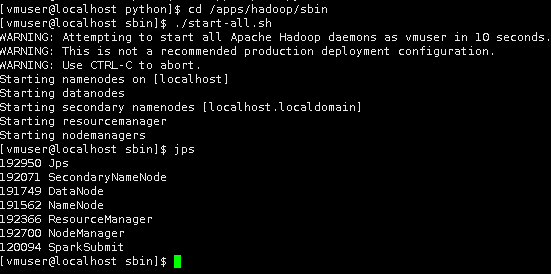
1切换到/apps/hadoop/sbin目录下,启动Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
使用jps查看启动的进程
sudo mkdir -p /data/pyspark2
切换到/data/pyspark2目录下,使用wget命令,下载文件。
cd /data/pyspark2
wget http://pyspark2/goods_visit.json
3.将文件goods_visit.json,上传到HDFS的/input/pyspark2目录下,若目录不存在则需提前创建。
hadoop fs -mkdir -p /input/pyspark2
hadoop fs -put /data/pyspark2/goods_visit.json /input/pyspark2
4.在Linux任意目录下启动pyspark
PYSPARK_PYTHON=python pyspark
PYSPARK_PYTHON=python3.6 pyspark
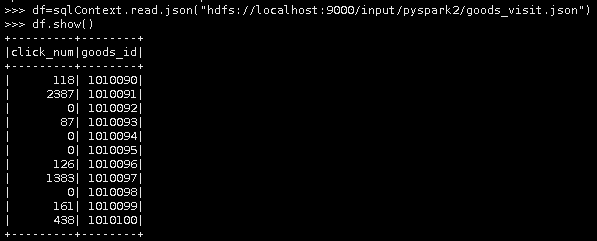
5.读取HDFS中/input/pyspark2的goods_visit.json文件。
df=sqlContext.read.json("hdfs://localhost:9000/input/pyspark2/goods_visit.json")
6.查看goods_visit.json中的所有数据。
df.show()
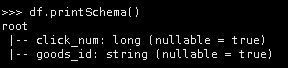
7.查看goods_visit.json的表结构。
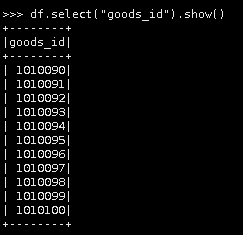
8.只查看商品ID(goods_id)。
df.select("goods_id").show()
9.统计文件行数。
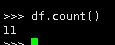
df.count()
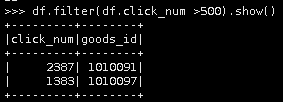
10.条件查询,查询点击次数超过500商品。(show是返回字段和表数据,collect是返回集合)
df.filter(df.click_num >500).show()
11.统计点击次数的最值、总和及平均数。
from pyspark.sql import functions as F
df.agg(F.max(df["click_num"]),F.sum(df["click_num"]),F.min(df["click_num"]),F.avg(df["click_num"])).show()

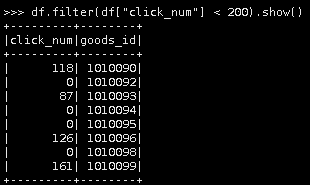
12.过滤点击次数小于200的商品。
df.filter(df["click_num"] < 200).show()
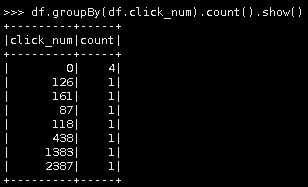
13.按点击次数进行分组统计。
df.groupBy(df.click_num).count().show()
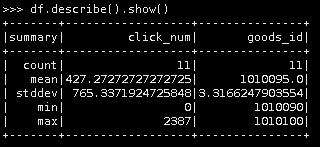
14 按点击次数进行描述性统计。
df.describe().show()
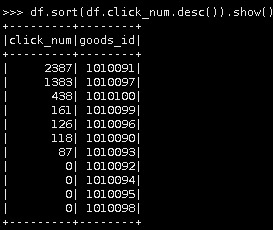
15.按点击次数进行降序排序(6种方法,任意选一种)。
第一种
df.sort(df.click_num.desc()).show()
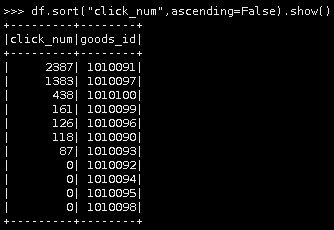
第二种
df.sort("click_num",ascending=False).show()
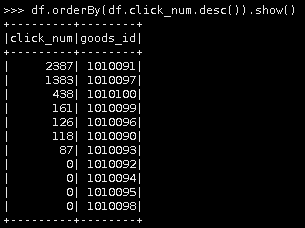
第三种
df.orderBy(df.click_num.desc()).show()
第四种
from pyspark.sql.functions import *
df.sort(desc("click_num")).show()
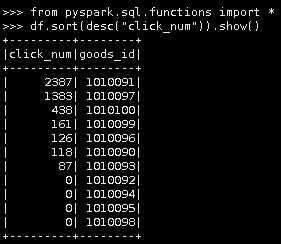
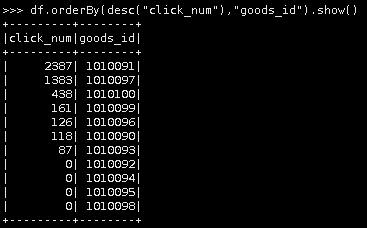
第五种
df.orderBy(desc("click_num"),"goods_id").show()
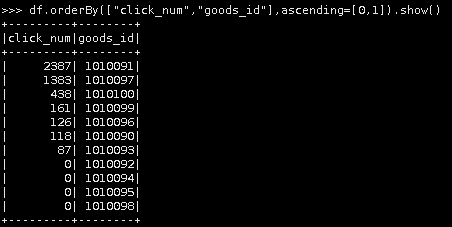
第六种
df.orderBy(["click_num","goods_id"],ascending=[0,1]).show()
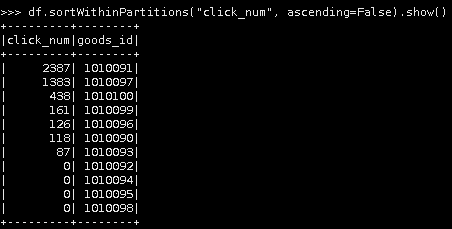
16.按分区对点击次数进行降序排序
df.sortWithinPartitions("click_num", ascending=False).show()
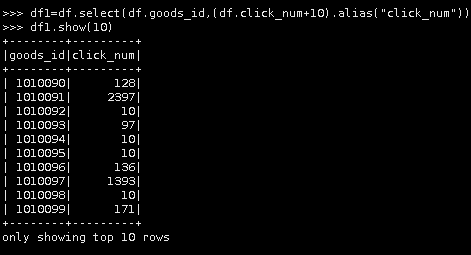
17.将点击次数都加10,然后输出点击次数与商品id的前10行数据。
df1=df.select(df.goods_id,(df.click_num+10).alias("click_num"))
df1.show(10)
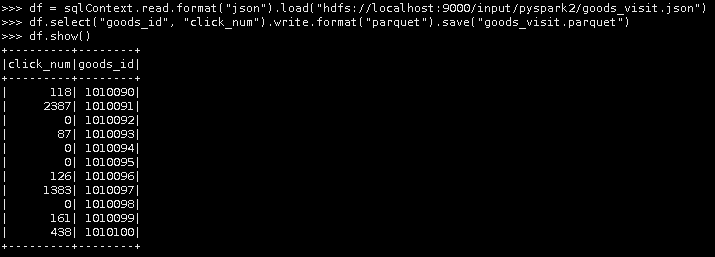
18.读取goods_visit.json文件,保存为parquet格式。
df = sqlContext.read.format("json").load("hdfs://localhost:9000/input/pyspark2/goods_visit.json")
df.select("goods_id", "click_num").write.format("parquet").save("goods_visit.parquet")

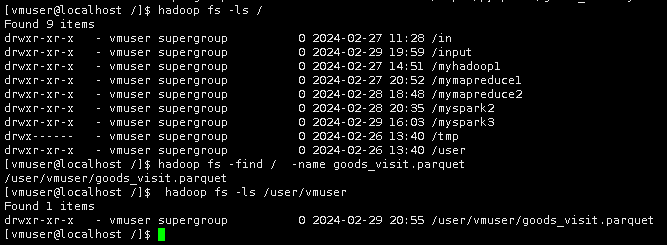
19.另打开一个终端,先转换为devuser用户后再查看保存的goods_visit.parquet文件。
查看文件
hadoop fs -find / -name goods_visit.parquet
hadoop fs -ls /user/vmuser

至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号