2.2 Spark Shell 操作(Hadoop3.0)
2.2 Spark Shell 操作(Hadoop3.0)
【实验目的】
1.了解Scala语言的基本语法
2.了解Spark Shell数据处理的原理
3.了解Spark算子的使用
4.了解Spark Shell和MapReduce对数据处理的不同点
【实验原理】
Spark shell是一个特别适合快速开发Spark程序的工具。即使你对Scala不熟悉,仍然可以使用这个工具快速应用Scala操作Spark。
Spark shell使得用户可以和Spark集群交互,提交查询,这便于调试,也便于初学者使用Spark。
Spark shell是非常方便的,因为它很大程度上基于Scala REPL(Scala交互式shell,即Scala解释器),并继承了Scala REPL(读取-求值-打印-循环)(Read-Evaluate-Print-Loop)的所有功能。运行spark-shell,则会运行spark-submit,spark-shell其实是对spark-submit的一层封装。
下面是Spark shell的运行原理图:

RDD有两种类型的操作 ,分别是Transformation(返回一个新的RDD)和Action(返回values)。
1.Transformation:根据已有RDD创建新的RDD数据集build
(1)map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集。
(2)filter(func) :对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD。
(3)flatMap(func):和map很像,但是flatMap生成的是多个结果。
(4)mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition。
(5)mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index。
(6)sample(withReplacement,faction,seed):抽样。
(7)union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合。
(8)distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element。
(9)groupByKey(numTasks):返回(K,Seq[V]),也就是Hadoop中reduce函数接受的key-valuelist。
(10)reduceByKey(func,[numTasks]):就是用一个给定的reduce func再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数。
(11)sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型。
2.Action:在RDD数据集运行计算后,返回一个值或者将结果写入外部存储
(1)reduce(func):就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的。
(2)collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组。
(3)count():返回的是dataset中的element的个数。
(4)first():返回的是dataset中的第一个元素。
(5)take(n):返回前n个elements。
(6)takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed。
(7)saveAsTextFile(path):把dataset写到一个textfile中,或者HDFS,或者HDFS支持的文件系统中,Spark把每条记录都转换为一行记录,然后写到file中。
(8)saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者Hadoop文件系统。
(9)countByKey():返回的是key对应的个数的一个map,作用于一个RDD。
(10)foreach(func):对dataset中的每个元素都使用func。
【实验环境】
Anolis 8.8
Java 1.8.0
Hadoop-3.0.0
Pycharm
Eclipse-JEE 2022.03
spark 3.5.0
【实验内容】
使用Spark Shell对数据进行WordCount统计、去重、排序、求平均值以及Join操作。
【实验步骤】
WordCount统计:某电商网站记录了大量的用户对商品的收藏数据,并将数据存储在名为buyer_favorite的文本文件中。文本数据格式如下:
用户id(buyer_id),商品id(goods_id),收藏日期(dt)
|
用户id 商品id 收藏日期 10181 1000481 2010-04-04 16:54:31 20001 1001597 2010-04-07 15:07:52 20001 1001560 2010-04-07 15:08:27 20042 1001368 2010-04-08 08:20:30 20067 1002061 2010-04-08 16:45:33 20056 1003289 2010-04-12 10:50:55 20056 1003290 2010-04-12 11:57:35 20056 1003292 2010-04-12 12:05:29 20054 1002420 2010-04-14 15:24:12 20055 1001679 2010-04-14 19:46:04 20054 1010675 2010-04-14 15:23:53 20054 1002429 2010-04-14 17:52:45 20076 1002427 2010-04-14 19:35:39 20054 1003326 2010-04-20 12:54:44 20056 1002420 2010-04-15 11:24:49 20064 1002422 2010-04-15 11:35:54 20056 1003066 2010-04-15 11:43:01 20056 1003055 2010-04-15 11:43:06 20056 1010183 2010-04-15 11:45:24 20056 1002422 2010-04-15 11:45:49 20056 1003100 2010-04-15 11:45:54 20056 1003094 2010-04-15 11:45:57 20056 1003064 2010-04-15 11:46:04 20056 1010178 2010-04-15 16:15:20 20076 1003101 2010-04-15 16:37:27 20076 1003103 2010-04-15 16:37:05 20076 1003100 2010-04-15 16:37:18 20076 1003066 2010-04-15 16:37:31 20054 1003103 2010-04-15 16:40:14 20054 1003100 2010-04-15 16:40:16 |
现要求统计用户收藏数据中,每个用户收藏商品数量。
1切换用户vmuser(密码:vm123456)
su – vmuser
在Linux上,创建/data/spark3/wordcount目录,用于存储实验所需的数据。
sudo mkdir -p /data/spark3/wordcount

目录授权
sudo chown -R vmuser:vmuser /data/spark3
切换目录到/data/spark3/wordcount下,并下载实验所需数据。
cd /data/spark3/wordcount
wget http://wordcount/buyer_favorite

2.启动Hadoop以及Spark的相关进程
/apps/hadoop/sbin/start-all.sh
/apps/spark/sbin/start-all.sh
使用jps查看启动的进程
jps
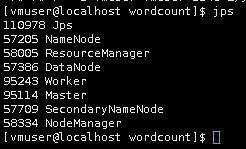
将Linux本地/data/spark3/wordcount/buyer_favorite文件,上传到HDFS上的/myspark3/wordcount目录下。若HDFS上/myspark3目录不存在则需提前创建。
hadoop fs -mkdir -p /myspark3/wordcount
hadoop fs -put /data/spark3/wordcount/buyer_favorite /myspark3/wordcount
(注意:此文档格式不要错)

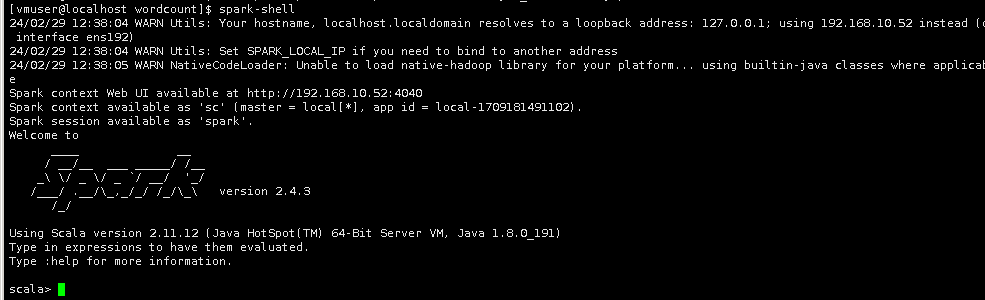
3.启动spark-shell
spark-shell
4.编写Scala语句,统计用户收藏数据中,每个用户收藏商品数量。
先在spark-shell中,加载数据。
val rdd = sc.textFile("hdfs://localhost:9000/myspark3/wordcount/buyer_favorite");

执行统计并输出。
rdd.map(line=> (line.split('\t')(0),1)).reduceByKey(_+_).collect

去重:使用spark-shell,对上述实验中,用户收藏数据文件进行统计。根据商品ID进行去重,统计用户收藏数据中都有哪些商品被收藏。
1新开一个终端
su vmuser
密码:vm123456
在Linux上,创建/data/spark3/distinct,用于存储实验数据。
sudo mkdir -p /data/spark3/distinct
切换到/data/spark3/distinct目录下,并下载实验所需数据。
cd /data/spark3/distinct
wget http://spark3/distinct/buyer_favorite
2.将/data/spark3/distinct/buyer_favorite文件,上传到HDFS上的/myspark3/distinct目录下。若HDFS目录不存在则创建。
hadoop fs -mkdir -p /myspark3/distinct
hadoop fs -put /data/spark3/distinct/buyer_favorite /myspark3/distinct
3.在Spark窗口,编写Scala语句,统计用户收藏数据中,都有哪些商品被收藏。
先加载数据,创建RDD。
val rdd = sc.textFile("hdfs://localhost:9000/myspark3/distinct/buyer_favorite");

对RDD进行统计并将结果打印输出。

排序:电商网站都会对商品的访问情况进行统计,现有一个goods_visit文件,存储了电商网站中的各种商品以及此各个商品的点击次数。
商品id(goods_id) 点击次数(click_num)
|
商品ID 点击次数 1010037 100 1010102 100 1010152 97 1010178 96 1010280 104 1010320 103 1010510 104 1010603 96 1010637 97 |
现根据商品的点击次数进行排序,并输出所有商品。
输出结果样式:
|
点击次数 商品ID 96 1010603 96 1010178 97 1010637 97 1010152 100 1010102 100 1010037 103 1010320 104 1010510 104 1010280 |
1在Linux上,创建/data/spark3/sort,用于存储实验数据。
sudo mkdir -p /data/spark3/sort
切换到/data/spark3/sort目录下,并下载实验所需数据。
cd /data/spark3/sort
wget http://spark3/sort/goods_visit
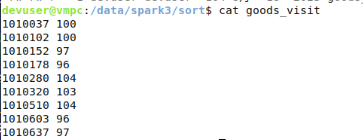
sudo chown -R vmuser:vmuser /data/spark3/sort/
2.将/data/spark3/sort/goods_visit文件,上传到HDFS上的/spark3/sort/目录下。若HDFS目录不存在则需提前创建。
hadoop fs -mkdir -p /myspark3/sort
hadoop fs -put /data/spark3/sort/goods_visit /myspark3/sort
3.在Spark窗口,加载数据,将数据转变为RDD。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/sort/goods_visit");
对RDD进行统计并将结果打印输出。
rdd1.map(line => ( line.split('\t')(1).toInt, line.split('\t')(0) ) ).sortByKey(true).collect
4.输出结果为:

Join:现有某电商在2011年12月15日的部分交易数据。数据有订单表orders和订单明细表order_items,表结构及数据分别为:
orders表:(订单id order_id, 订单号 order_number, 买家ID buyer_id, 下单日期 create_dt)
|
订单ID 订单号 用户ID 下单日期 52304 111215052630 176474 2011-12-15 04:58:21 52303 111215052629 178350 2011-12-15 04:45:31 52302 111215052628 172296 2011-12-15 03:12:23 52301 111215052627 178348 2011-12-15 02:37:32 52300 111215052626 174893 2011-12-15 02:18:56 52299 111215052625 169471 2011-12-15 01:33:46 52298 111215052624 178345 2011-12-15 01:04:41 52297 111215052623 176369 2011-12-15 01:02:20 52296 111215052622 178343 2011-12-15 00:38:02 52295 111215052621 178342 2011-12-15 00:18:43 52294 111215052620 178341 2011-12-15 00:14:37 52293 111215052619 178338 2011-12-15 00:13:07 |
order_items表:(明细ID item_id, 订单ID order_id, 商品ID goods_id )
|
明细ID 订单ID 商品ID 252578 52293 1016840 252579 52293 1014040 252580 52294 1014200 252581 52294 1001012 252582 52294 1022245 252583 52294 1014724 252584 52294 1010731 252586 52295 1023399 252587 52295 1016840 252592 52296 1021134 252593 52296 1021133 252585 52295 1021840 252588 52295 1014040 252589 52296 1014040 252590 52296 1019043 |
orders表和order_items表,通过订单id进行关联,是一对多的关系。
下面在spark-shell,查询在当天该电商网站,都有哪些用户购买了什么商品。
1在Linux上,创建/data/spark3/join,用于存储实验数据。
mkdir -p /data/spark3/join
切换目录到/data/spark3/join目录下,并下载实验所需数据。
cd /data/spark3/join
wget http://spark3/join/order_items
wget http://spark3/join/orders

2.在HDFS上创建/myspark3/join目录,并将Linux上/data/spark3/join目录下的数据,上传到HDFS。
hadoop fs -mkdir -p /myspark3/join
hadoop fs -put /data/spark3/join/orders /myspark3/join
hadoop fs -put /data/spark3/join/order_items /myspark3/join
3.在Spark窗口创建两个RDD,分别加载orders文件以及order_items文件中的数据。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/join/orders");
val rdd2 = sc.textFile("hdfs://localhost:9000/myspark3/join/order_items");
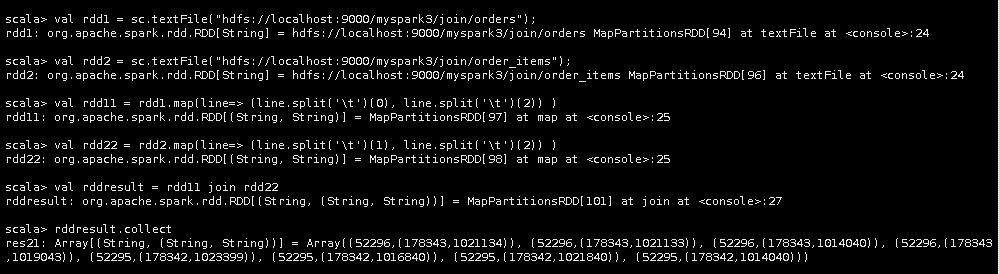
4.我们的目的是查询每个用户购买了什么商品。所以对rdd1和rdd2进行map映射,得出关键的两个列的数据。
val rdd11 = rdd1.map(line=> (line.split('\t')(0), line.split('\t')(2)) )
val rdd22 = rdd2.map(line=> (line.split('\t')(1), line.split('\t')(2)) )
5.将rdd11以及rdd22中的数据,根据Key值,进行Join关联,得到最终结果。
val rddresult = rdd11 join rdd22
6.最后将结果输出。
rddresult.collect
7.将输出数据进行格式化:
|
(52294,(178341,1014200)), (52294,(178341,1001012)), (52294,(178341,1022245)), (52294,(178341,1014724)), (52294,(178341,1010731)), (52296,(178343,1021134)), (52296,(178343,1021133)), (52296,(178343,1014040)), (52296,(178343,1019043)), (52295,(178342,1023399)), (52295,(178342,1016840)), (52295,(178342,1021840)), (52295,(178342,1014040)), (52293,(178338,1016840)), (52293,(178338,1014040)) |
可以看到上面数据关联后一共有3列,分别为订单ID,用户ID,商品ID。
求平均值:电商网站都会对商品的访问情况进行统计。现有一个goods_visit文件,存储了全部商品及各商品的点击次数。还有一个文件goods,记录了商品的基本信息。两张表的数据结构如下:
goods表:商品ID(goods_id),商品状态(goods_status),商品分类id(cat_id),评分(goods_score)
goods_visit表:商品ID(goods_id),商品点击次数(click_num)
商品表(goods)及商品访问情况表(goods_visit)可以根据商品id进行关联。现在统计每个分类下,商品的平均点击次数是多少?
1 在Linux上,创建目录/data/spark3/avg,用于存储实验数据。
mkdir -p /data/spark3/avg
切换到/data/spark3/avg目录下,并下载实验所需数据。
cd /data/spark3/avg
wget http://192.168.1.150:60000/allfiles/spark3/avg/goods
wget http://192.168.1.150:60000/allfiles/spark3/avg/goods_visit
2.在HDFS上创建目录/myspark3/avg,并将Linux/data/spark3/avg目录下的数据,上传到HDFS的/myspark3/avg。
hadoop fs -mkdir -p /myspark3/avg
hadoop fs -put /data/spark3/avg/goods /myspark3/avg
hadoop fs -put /data/spark3/avg/goods_visit /myspark3/avg
3.在Spark窗口创建两个RDD,分别加载goods文件以及goods_visit文件中的数据。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/avg/goods")
val rdd2 = sc.textFile("hdfs://localhost:9000/myspark3/avg/goods_visit")

4.我们的目的是统计每个分类下,商品的平均点击次数,我们可以分三步来做。
首先,对rdd1和rdd2进行map映射,得出关键的两个列的数据。
val rdd11 = rdd1.map(line=> (line.split('\t')(0), line.split('\t')(2)) )
val rdd22 = rdd2.map(line=> (line.split('\t')(0), line.split('\t')(1)) )

用collect()方法启动程序。
rdd11.collect

用collect()方法启动程序。
rdd22.collect

然后,将rdd11以及rdd22中的数据根据商品ID,也就是key值进行关联,得到一张大表。
表结构变为:(商品id,(商品分类,商品点击次数))
val rddjoin = rdd11 join rdd22

用collect()方法启动程序。

最后,在大表的基础上,进行统计。得到每个分类,商品的平均点击次数。
rddjoin.map(x=>{(x._2._1, (x._2._2.toLong, 1))}).reduceByKey((x,y)=>{(x._1+y._1, x._2+y._2)}).map(x=>{(x._1, x._2._1*1.0/x._2._2)}).collect

至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号