2.1 Spark Standalone 伪分布模式安装(Hadoop3.0)
2.1 Spark Standalone 伪分布模式安装(Hadoop3.0)
【实验目的】
1.熟练掌握Spark Standalone伪分布模式的安装流程
2.准确理解Spark Standalone伪分布模式的运行原理
3.学会独立进行SparkStandalone伪分布模式安装
【实验原理】
Local cluster伪分布式模式,实际是在SparkContext初始化的过程中,在本地启动一个所有服务都在单机上运行的伪分布Spark集群,所以从部署的角度来说无须做任何准备工作。以SparkPi为例,伪分布式模式下的应用程序的启动命令的示例如下:
./bin/run-example org.apache.spark.examples.SparkPi local-cluster[2,2,1024]
上面的伪分布式模式启动两个Worker,每个Worker管理两个CPU和1024MB的内存。
Local cluster伪分布式模式是基于Standalone模式来实现的,所以也叫Standalone伪分布模式,除了启动Master和Worker的位置不同,在集群启动完毕后,后续应用程序的工作流程及资源的调度流程与Standalone集群模式完全相同。
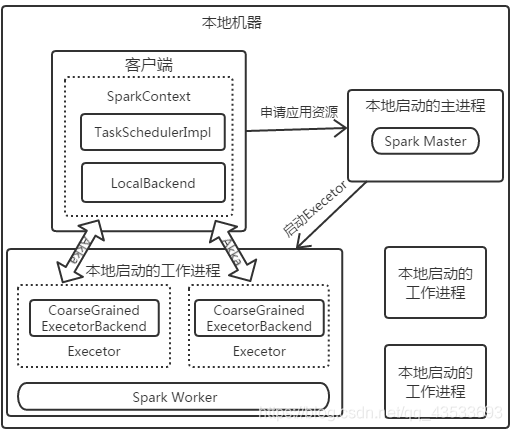
Standalone伪分布模式内部逻辑结构如下图所示:
【实验环境】
Anolis8.8
OpenJDK 1.8.0_352
hadoop-3.0.0
【实验内容】
在已经安装好的Hadoop伪分布模式下,安装Spark Standalone模式。
【实验步骤】
1Spark的运行依赖jdk,Hadoop,Scala。在这里默认已安装jdk以及Hadoop伪分布模式。
2在Linux上,创建目录/data/spark2,用于存储spark安装所需的文件。
sudo mkdir -p /data
sudo mkdir -p /data/spark2
并为/spark2目录切换所属的用户为vmuser及用户组为vmuser(密码:vm123456):
sudo chown -R vmuser:vmuser /data/spark2
sudo chown -R vmuser:vmuser /data
切换目录到/data/spark2下,使用wget命令,下载所需的Spark的安装包spark-2.4.3-bin-hadoop2.7.tgz及scala安装包scala-2.12.8.tgz。
cd /data/spark2/
wget http://hadoop3/scala-2.12.8.tgz
wget http://hadoop3/spark-2.4.3-bin-hadoop2.7.tgz
此处Scala使用scala-2.12.8版本。官网中指出,Scala 2.11和2.12主要是源兼容的,但它们不是二进制兼容的,而Scala 2.12已经过彻底改造,以利用Java 8中提供的新VM功能。
关于spark版本,我们使用spark-2.4.3版本。
3.安装Scala。切换目录到/data/spark2下,将目录下的scala-2.12.8.tgz解压缩到/apps目录下,并将解压后的目录名改为/apps/scala。
cd /data/spark2/
tar -xzvf /data/spark2/scala-2.12.8.tgz -C /apps/
cd /apps
mv /apps/scala-2.12.8/ /apps/scala
使用vim打开用户环境变量~/.bashrc。
vim ~/.bashrc
将scala的bin目录,追加的用户环境变量中。
|
#scala export SCALA_HOME=/apps/scala export PATH=$SCALA_HOME/bin:$PATH |
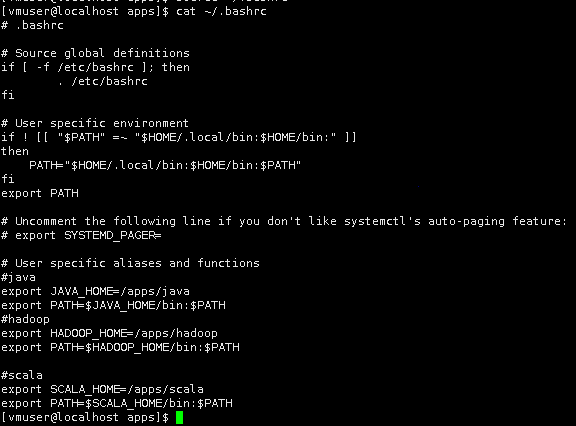
执行source命令,使系统环境变量生效。
source ~/.bashrc
4.切换目录到/data/spark2下,将Spark的安装包spark-2.4.3-bin-hadoop2.7.tgz,解压缩到/apps目录下,并将解压后的目录名,重命名为spark。(密码:vm123456)
cd /data/spark2
tar -xzvf /data/spark2/spark-2.4.3-bin-hadoop2.7.tgz -C /apps/
cd /apps/
mv /apps/spark-2.4.3-bin-hadoop2.7/ /apps/spark
使用vim打开用户环境变量~/.bashrc。
vim ~/.bashrc
将spark的bin目录,追加到用户环境变量中。
#spark
export SPARK_HOME=/apps/spark
export PATH=$SPARK_HOME/bin:$PATH
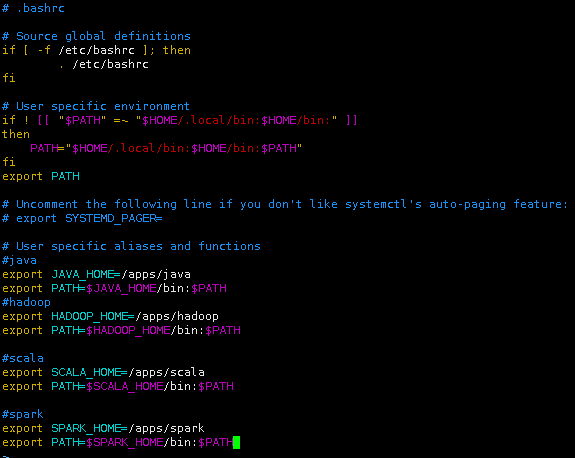
执行source命令,使用户环境变量生效。
source ~/.bashrc
5.切换目录到/apps/spark/conf下,将conf目录下的配置文件slaves.template重命名为slaves。
cd /apps/spark/conf
mv slaves.template slaves
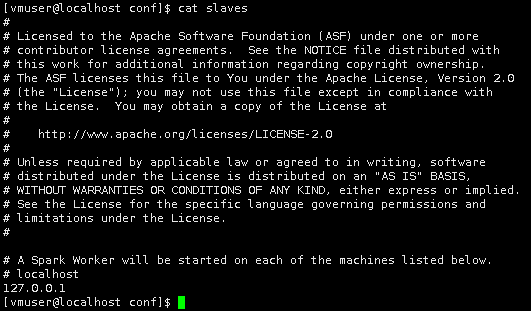
在slaves中,存储了所有worker节点的的ip或主机名。使用文本编辑器vim打开slaves文件。
vim slaves
将所有worker节点的ip添加进去。由于目前只有一台节点,所以是。
127.0.0.1
6.将/apps/spark/conf/spark-env.sh.template文件,重命名为/apps/spark/conf/spark-env.sh。
mv /apps/spark/conf/spark-env.sh.template /apps/spark/conf/spark-env.sh
使用vim,打开/apps/spark/conf/spark-env.sh文件。
vim /apps/spark/conf/spark-env.sh
添加如下配置:
|
HADOOP_CONF_DIR=/apps/hadoop/etc/hadoop JAVA_HOME=/apps/java SPARK_MASTER_IP=127.0.0.1 SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_EXECUTOR_INSTANCES=1 |
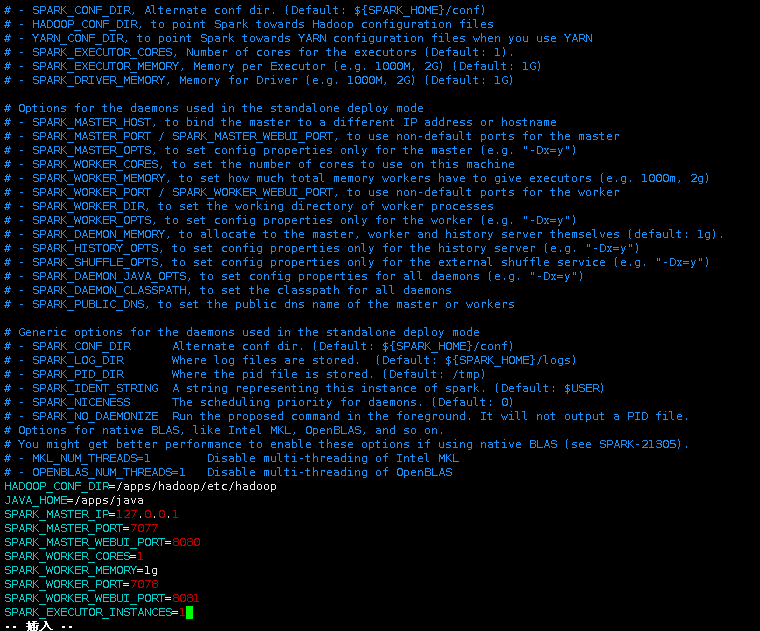
此处需要配置JAVA_HOME以及HADOOP配置文件所在的目录HADOOP_CONF_DIR。
SPARK_MASTER_IP、SPARK_MASTER_PORT、SPARK_MASTER_WEBUI_PORT,分别指spark集群中,master节点的ip地址、端口号、提供的web接口的端口。
SPARK_WORKER_CORES、SPARK_WORKER_MEMORY:worker节点的内核数、内存大小。
此处可用根据自己机器情况调整配置项参数。
7.启动Hadoop,首先需要保证Hadoop相关进程为启动状态。
cd /apps/hadoop/sbin
./start-all.sh
切换目录到/apps/spark/sbin目录下,启动Spark。
cd /apps/spark/sbin
./start-all.sh

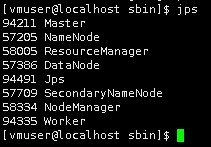
8.执行测试
在HDFS上,创建/myspark2目录,并将Linux上/apps/spark/README.md文件,上传到HDFS。
hadoop fs -mkdir /myspark2
hadoop fs -put /apps/spark/README.md /myspark2/
切换目录到/apps/spark/bin目录下,使用Spark Shell客户端,访问服务端,验证安装完的Spark是否可用,进入命令行模式。
cd /apps/spark/bin
./spark-shell
在Spark Shell中,使用scala加载HDFS上的README.md文件,并转变为rdd。
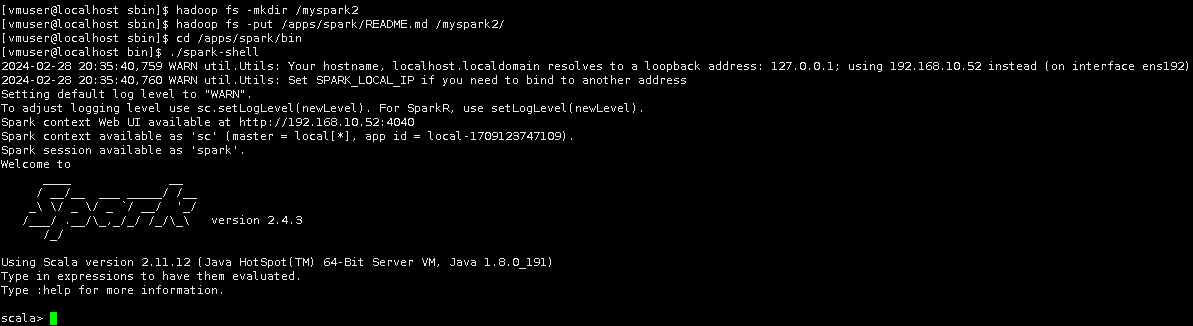
var mytxt = sc.textFile("hdfs://localhost:9000/myspark2/README.md");
统计文件的行数。
mytxt.count();

可用看到输出为:
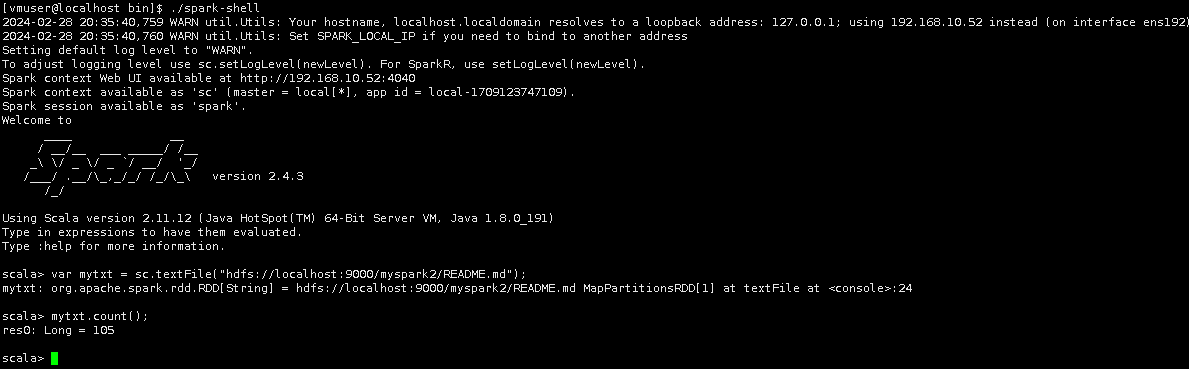
表明安装正确。
9.在刚才执行统计过程中,由于Log4j的日志输出级别为info级别,所以会在屏幕上输出很多的log,很难定位程序的输出结果。
输入:quit,退出spark-shell,并切换目录到/apps/spark/sbin目录下,停止Spark。
:quit
cd /apps/spark/sbin
./stop-all.sh
再切换目录到/apps/spark/conf目录下,将目录下log4j.properties.template重命名为log4j.properties。
cd /apps/spark/conf
mv /apps/spark/conf/log4j.properties.template /apps/spark/conf/log4j.properties
使用vim打开log4j.properties文件。
vim log4j.properties
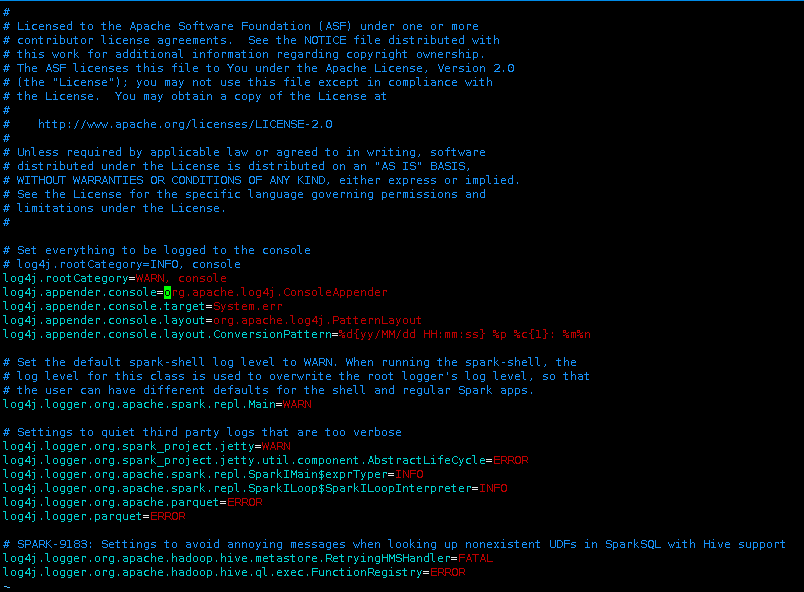
更改log4j的日志级别为WARN级别,修改log4j.rootCategory内容为:
log4j.rootCategory=WARN, console
再次启动Spark。
cd /apps/spark/sbin
./start-all.sh
进入Spark-Shell。
cd /apps/spark/bin
spark-shell
执行Spark-Shell命令。
val mytxt = sc.textFile("hdfs://localhost:9000/myspark2/README.md");
mytxt.count();
完整效果。
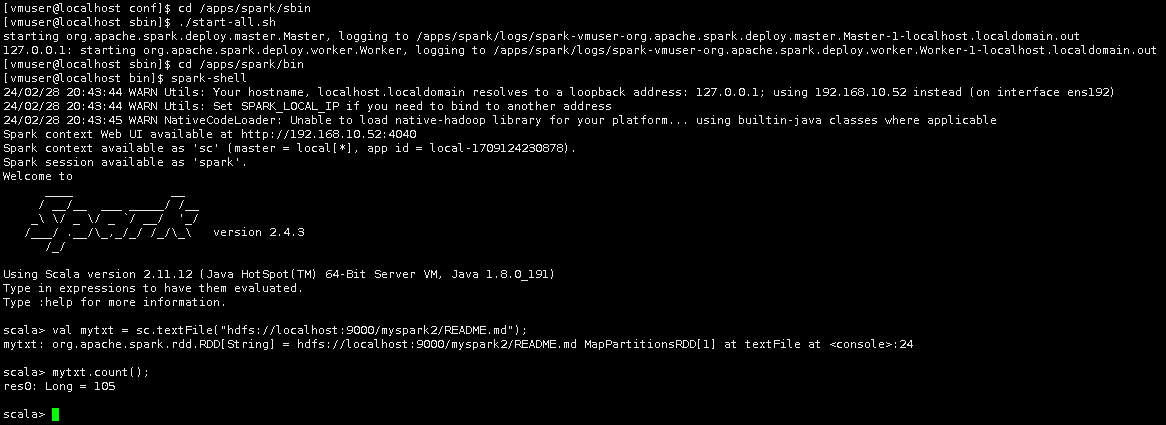
可以看到输出的内容相对于调整log4j日志级别前,更加精简了。
至此,实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号