1.7MapReduce 实例:求平均值(Hadoop3.0)
1.7MapReduce 实例:求平均值(Hadoop3.0)
【实验目的】
1.准确理解Mapreduce求平均值的设计原理
2.熟练掌握Mapreduce求平均值程序的编写
3.学会编写Mapreduce求平均值程序代码解决问题
【实验原理】
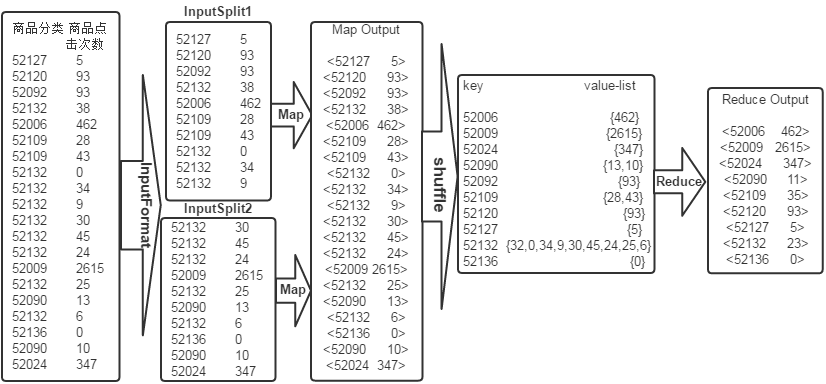
求平均数是MapReduce比较常见的算法,求平均数的算法也比较简单,一种思路是Map端读取数据,在数据输入到Reduce之前先经过shuffle,将map函数输出的key值相同的所有的value值形成一个集合value-list,然后将输入到Reduce端,Reduce端汇总并且统计记录数,然后作商即可。具体原理如下图所示:
【实验环境】
Anolis8.8
Java 1.8.0
Hadoop-3.0.0
Eclipse-JEE 2022.03
【实验内容】
现有某电商关于商品点击情况的数据文件,表名为goods_click,包含两个字段(商品分类,商品点击次数),分隔符“\t”,由于数据很大,所以为了方便统计我们只截取它的一部分数据,内容如下:
|
商品分类 商品点击次数 52127 5 52120 93 52092 93 52132 38 52006 462 52109 28 52109 43 52132 0 52132 34 52132 9 52132 30 52132 45 52132 24 52009 2615 52132 25 52090 13 52132 6 52136 0 52090 10 52024 347 |
要求使用mapreduce统计出每类商品的平均点击次数。
结果数据如下:
|
商品分类 商品平均点击次数 52006 462 52009 2615 52024 347 52090 11 52092 93 52109 35 52120 93 52127 5 52132 23 52136 0 |
【实验步骤】
打开终端模拟器,切换到vmuser用户(密码:vm123456)
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
使用jps查看启动的进程
2.在Linux本地新建/data/mapreduce4目录。
mkdir -p /data/mapreduce4
3.在Linux中切换到/data/mapreduce4目录下,用wget命令下载文本文件goods_click。
cd /data/mapreduce4
wget http://goods_click
然后在当前目录下用wget命令下载项目用到的依赖包。
将hadoop2lib.tar.gz解压到当前目录下。
tar zxvf hadoop2lib.tar.gz
4.首先在HDFS上新建/mymapreduce4/in目录,然后将Linux本地/data/mapreduce4目录下的goods_click文件导入到HDFS的/mymapreduce4/in目录中。
hadoop fs -mkdir -p /mymapreduce4/in
hadoop fs -put /data/mapreduce4/goods_click /mymapreduce4/in

5.双击Eclipse,默认/data2/路径,点击【Launch】,点击【File】---->【New】---->【Project】
选择【Java Project】,点击【Next】
项目名为mapreduce4,JRE选择【JavaSE-1.8】,点击【Finish】
在项目下新建包,点击【File】---->【New】---->【Package】包名为mapreduce。
在mapreduce包下新建类,右击,【New】---->【Class】
类名为MyAverage。
6.添加项目所需依赖的jar包,右键项目,新建一个文件夹,点击项目名mapreduce4,右击,点击【New】--->【Folder】
命名为hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce4目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce4项目的hadoop2lib目录下。
选中hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写Java代码并描述其设计思路。
Mapper代码
|
public static class Map extends Mapper<Object , Text , Text , IntWritable>{ private static Text newKey=new Text(); //实现map函数 public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ // 将输入的纯文本文件的数据转化成String String line=value.toString(); System.out.println(line); String arr[]=line.split("\t"); newKey.set(arr[0]); int click=Integer.parseInt(arr[1]); context.write(newKey, new IntWritable(click)); } } |
map端在采用Hadoop的默认输入方式之后,将输入的value值通过split()方法截取出来,我们把截取的商品点击次数字段转化为IntWritable类型并将其设置为value,把商品分类字段设置为key,然后直接输出key/value的值。
Reducer代码
|
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{ //实现reduce函数 public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{ int num=0; int count=0; for(IntWritable val:values){ num+=val.get(); //每个元素求和num count++; //统计元素的次数count } int avg=num/count; //计算平均数 context.write(key,new IntWritable(avg)); } } |
map的输出<key,value>经过shuffle过程集成<key,values>键值对,然后将<key,values>键值对交给reduce。reduce端接收到values之后,将输入的key直接复制给输出的key,将values通过for循环把里面的每个元素求和num并统计元素的次数count,然后用num除以count 得到平均值avg,将avg设置为value,最后直接输出<key,value>就可以了。
完整代码
|
package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class MyAverage { public static class Map extends Mapper<Object, Text, Text, IntWritable> { private static Text newKey = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); System.out.println(line); String arr[] = line.split("\t"); newKey.set(arr[0]); int click = Integer.parseInt(arr[1]); context.write(newKey, new IntWritable(click)); } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int num = 0; int count = 0; for (IntWritable val : values) { num += val.get(); count++; } int avg = num / count; context.write(key, new IntWritable(avg)); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); System.out.println("start"); Job job = new Job(conf, "MyAverage"); job.setJarByClass(MyAverage.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in = new Path("hdfs://localhost:9000/mymapreduce4/in/goods_click"); Path out = new Path("hdfs://localhost:9000/mymapreduce4/out"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
8.在MyAverage类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
9.待执行完毕后,进入命令模式下,在HDFS上/mymapreduce4/out中查看实验结果。
hadoop fs -ls /mymapreduce4/out
hadoop fs -cat /mymapreduce4/out/part-r-00000
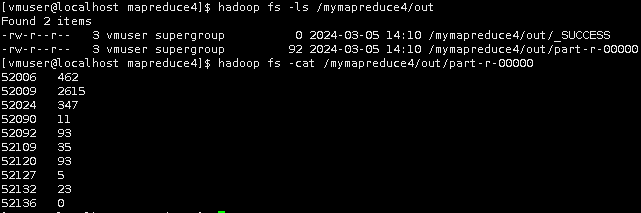
将HDFS上的输出结果下载到本地
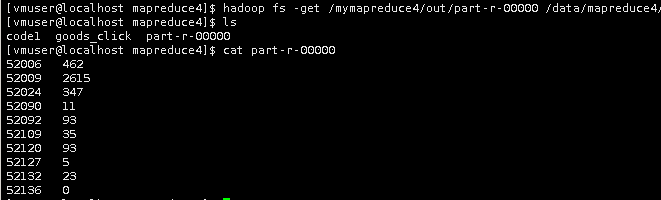
hadoop fs -get /mymapreduce4/out/part-r-00000 /data/mapreduce4/
ls
cat part-r-00000
至此,本实验结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号