1.1Hadoop 伪分布模式安装(Hadoop3.0)
1.1Hadoop 伪分布模式安装(Hadoop3.0)
【实验目的】
1、了解Hadoop的3种运行模式
2、熟练掌握Hadoop伪分布模式安装流程
3、培养独立完成Hadoop伪分布安装的能力
【实验原理】
Hadoop由Apache基金会开发的分布式系统基础架构,是利用集群对大量数据进行分布式处理和存储的软件框架。用户可以轻松地在Hadoop集群上开发和运行处理海量数据的应用程序。Hadoop有高可靠,高扩展,高效性,高容错等优点。Hadoop 框架最核心的设计就是HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。此外,Hadoop还包括了Hive,Hbase,ZooKeeper,Pig,Avro,Sqoop,Flume,Mahout等项目。
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,完全分布运行模式。
(1)本地模式(local mode):这种运行模式在一台单机上运行,没有HDFS分布式文件系统,而是直接读写本地操作系统中的文件系统。在本地运行模式(local mode)中不存在守护进程,所有进程都运行在一个JVM上。单机模式适用于开发阶段运行MapReduce程序,这也是最少使用的一个模式。
(2)伪分布模式:这种运行模式是在单台服务器上模拟Hadoop的完全分布模式,单机上的分布式并不是真正的分布式,而是使用线程模拟的分布式。在这个模式中,所有守护进程(NameNode,DataNode,ResourceManager,NodeManager,SecondaryNameNode)都在同一台机器上运行。因为伪分布运行模式的Hadoop集群只有一个节点,所以HDFS中的块复制将限制为单个副本,其secondary-master和slave也都将运行于本地主机。此种模式除了并非真正意义的分布式之外,其程序执行逻辑完全类似于完全分布式,因此,常用于开发人员测试程序的执行。本次实验就是在一台服务器上进行伪分布运行模式的搭建。
(3)完全分布模式:这种模式通常被用于生产环境,使用N台主机组成一个Hadoop集群,Hadoop守护进程运行在每台主机之上。这里会存在Namenode运行的主机,Datanode运行的主机,以及SecondaryNameNode运行的主机。在完全分布式环境下,主节点和从节点会分开。
【实验环境】
Anolis OS 8.8
【实验内容】
安装Hadoop3.0.0伪分布模式。
【实验步骤】
From
https://blog.csdn.net/weixin_42609366/article/details/127880660
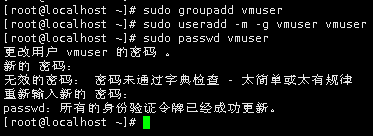
0 创建用户vmuser和
用户组 vmuser 密码 vm123456
用户 vmuser
sudo groupadd vmuser
sudo useradd -m -g vmuser vmuser
sudo passwd vmuser
查看一个用户组里有哪些用户
cat /etc/group|grep 组名
cat /etc/group|grep vmuser

1点击实验机右下角的三角形,点击【切换】,进入高级模式,打开终端。
2 2.配置SSH免密码登陆
SSH免密码登陆需要在服务器执行以下命令,生成公钥和私钥对:
cd
ssh-keygen -t rsa
此时会有多处提醒输入在冒号后输入文本,这里主要是要求输入ssh密码以及密码的放置位置。在这里,只需要使用默认值,按回车即可。
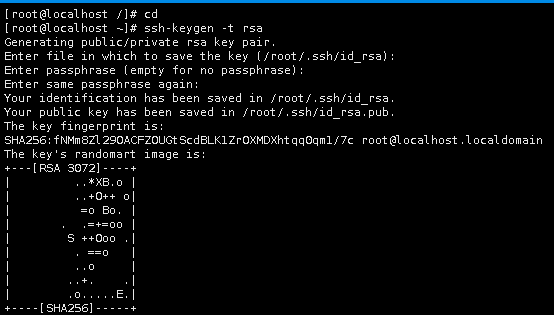
此时ssh公钥和私钥已经生成完毕,且放置在~/.ssh目录下。
切换到~/.ssh目录下:
cd ~/.ssh
执行ll命令,可以看到~/.ssh目录下的文件:
ll
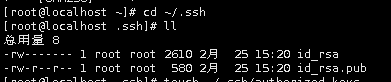
下面在~/.ssh目录下,创建一个空文本,名为authorized_keys
touch ~/.ssh/authorized_keys
将存储公钥文件的id_rsa.pub里的内容,追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
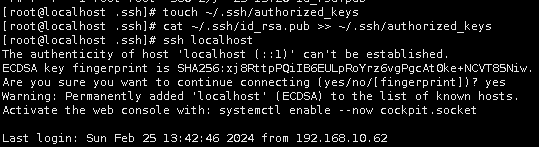
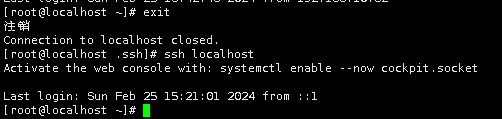
下面执行ssh localhost测试ssh配置是否正确
ssh localhost
第一次使用ssh访问,会提醒是否继续连接,输入“yes"继续进行
修改vmuser权限为最高权限,方便安装
root用户 sudo visudo

3.下面首先来创建两个目录,用于存放安装程序及数据。(sudo命令密码:vm123456)
并为/apps目录切换所属的用户为vmuser及用户组为vmuser:
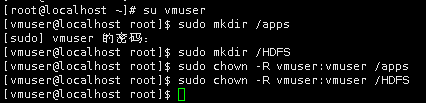
两个目录的作用分别为:/apps目录用来存放安装的框架,/HDFS目录用来存放临时数据、HDFS数据、程序代码或脚本。
切换到根目录下,执行 ls -l 命令查看
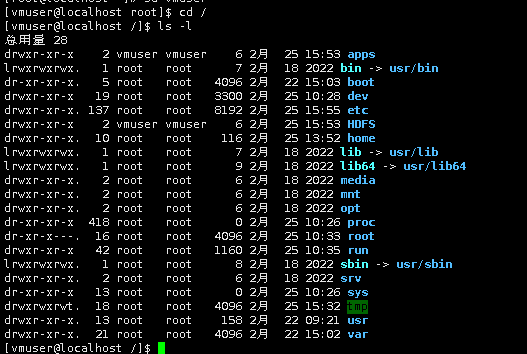
可以看到根目录下/apps和/HDFS目录所属用户及用户组已切换为vmuser:vmuser
4.配置HDFS。
创建/HDFS/hadoop1目录,用来存放相关安装工具。
mkdir -p /HDFS/hadoop1
切换目录到/HDFS/hadoop1目录,使用wget命令,下载所需的JDK安装包和Hadoop安装包。
https://archive.apache.org/dist/hadoop/core/hadoop-3.0.0/
cd /HDFS/hadoop1
wget http://hadoop3/jdk-8u191-linux-x64.tar.gz
wget http://hadoop3/hadoop-3.0.0.tar.gz
5.安装JDK。
将/HDFS/hadoop1目录下jdk-8u191-linux-x64.tar.gz解压缩到/apps目录下。
tar -xzvf /HDFS/hadoop1/jdk-8u191-linux-x64.tar.gz -C /apps
其中,tar -xzvf 对文件进行解压缩,-C 指定解压后,将文件放到/apps目录下。
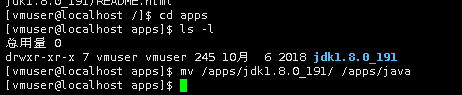
切换到/apps目录下,可以看到目录下内容如下:
cd /apps/
ls -l
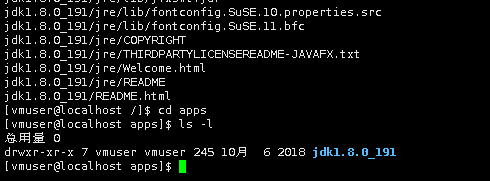
下面将jdk1.8.0_191目录重命名为java:
mv /apps/jdk1.8.0_191/ /apps/java
6.修改环境变量。
可以修改系统环境变量或用户环境变量。在这里我们修改用户环境变量。(sudo命令密码:vm123456)
sudo vim ~/.bashrc
输入上面的命令,打开存储环境变量的文件。
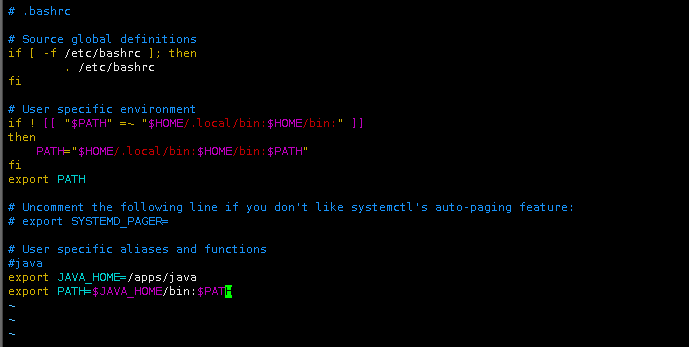
按“i”键进入输入模式,将Java的环境变量,追加进用户环境变量中。
#java
export JAVA_HOME=/apps/java
export PATH=$JAVA_HOME/bin:$PATH
按下ESC,进入Vim命令模式,输入“:wq”后回车进行保存。
执行source命令,让Java环境变量生效。
source ~/.bashrc
执行完毕后,可以输入java,来测试环境变量是否配置正确。
java
如果出现下面界面,则正常运行。

7.安装Hadoop。
切换到/HDFS/hadoop1目录下,将hadoop-3.0.0.tar.gz解压缩到/apps目录下。
cd /HDFS/hadoop1
tar -xzvf /HDFS/hadoop1/hadoop-3.0.0.tar.gz -C /apps/
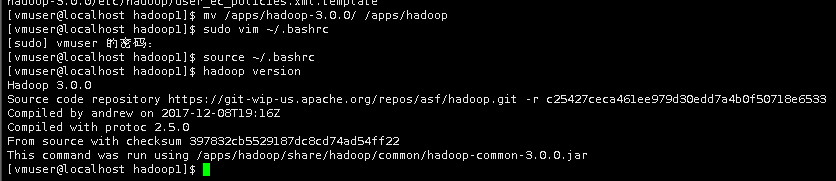
为了便于操作,这里也将hadoop-3.0.0重命名为hadoop。
mv /apps/hadoop-3.0.0/ /apps/Hadoop

8.修改用户环境变量,将Hadoop的路径添加到path中。
先打开用户环境变量文件。
sudo vim ~/.bashrc
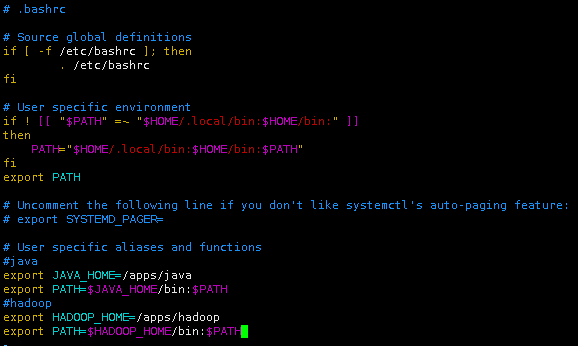
将以下内容追加到环境变量~/.bashrc文件中。
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
让环境变量生效。
source ~/.bashrc
验证hadoop环境变量配置是否正常
hadoop version
9.修改hadoop本身相关的配置。
首先切换到hadoop配置目录下。
cd /apps/hadoop/etc/Hadoop

10.打开hadoop-env.sh配置文件。
vim /apps/hadoop/etc/hadoop/hadoop-env.sh
将下面JAVA_HOME追加到hadoop-env.sh文件中。
export JAVA_HOME=/apps/java
11.打开core-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/core-site.xml
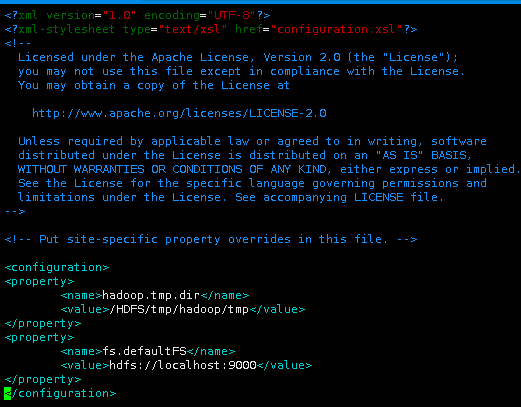
添加下面配置到<configuration>与</configuration>标签之间。
<property>
<name>hadoop.tmp.dir</name>
<value>/HDFS/tmp/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
这里有两项配置:
一项是hadoop.tmp.dir,用于配置在Hadoop处理过程中,临时文件的存储位置。这里的/HDFS/tmp/hadoop/tmp目录需要提前创建:
mkdir -p /HDFS/tmp/hadoop/tmp
另一项是fs.defaultFS,用于配置Hadoop HDFS文件系统的地址。
12.打开hdfs-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/hdfs-site.xml
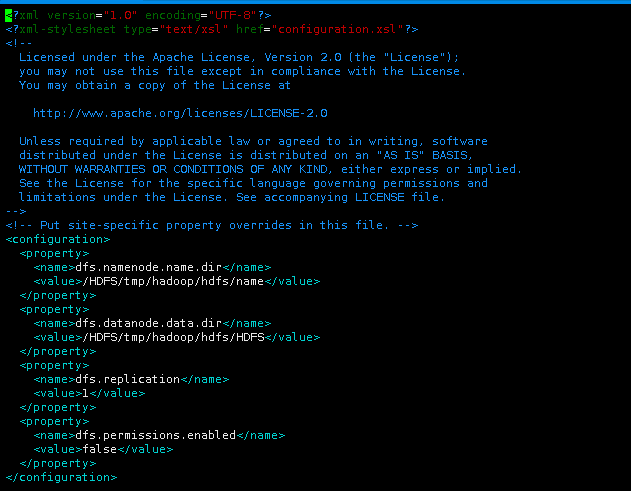
添加下面配置到<configuration>与</configuration>标签之间。
<property>
<name>dfs.namenode.name.dir</name>
<value>/HDFS/tmp/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/HDFS/tmp/hadoop/hdfs/HDFS</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
:%!xmllint --format –
配置项说明:
dfs.namenode.name.dir,配置元数据信息存储位置;
dfs.datanode.data.dir,配置具体数据存储位置;
dfs.replication,配置每个数据库备份数,由于目前我们使用1台节点,所以,设置为1,如果设置为2的话,运行会报错。
dfs.permissions.enabled,配置hdfs是否启用权限认证
另外/HDFS/tmp/hadoop/hdfs路径,需要提前创建:
mkdir -p /HDFS/tmp/hadoop/hdfs
13 打开slaves配置文件。
vim /apps/hadoop/etc/hadoop/slaves
将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,所以slaves文件内容为:
localhost

去除警告及无用的信息
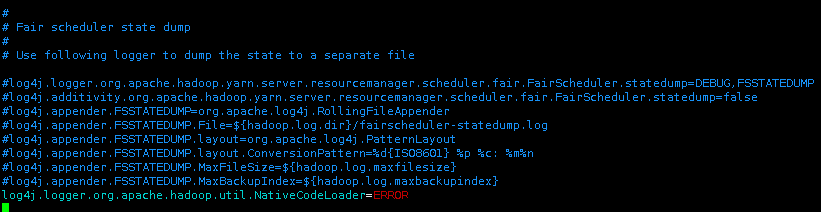
进入/apps/hadoop/etc/hadoop/log4j.properties文件中
vim /apps/hadoop/etc/hadoop/log4j.properties
在文件的开头,将INFO改为ERROR

在文件末尾添加
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
14.下面格式化HDFS文件系统。执行:
hadoop namenode -format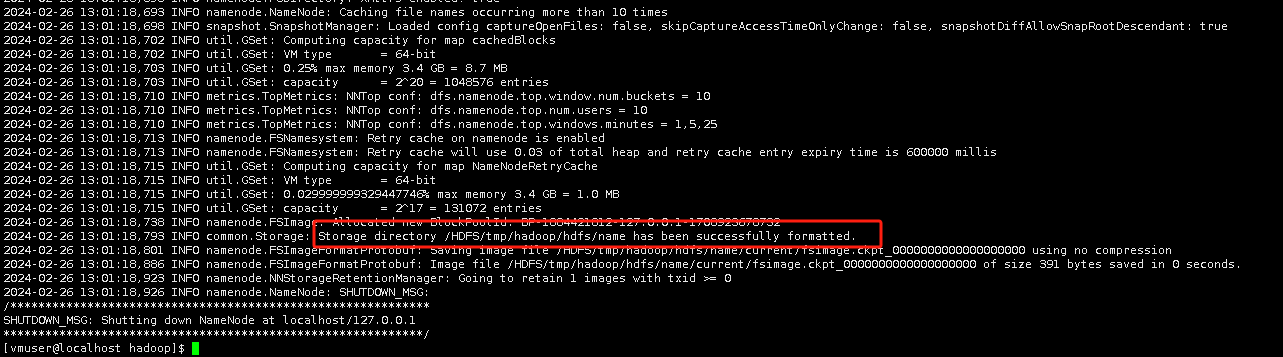
在输出的内容中显示successfully formatted,则格式化成功。
15.切换目录到/apps/hadoop/sbin目录下。
cd /apps/hadoop/sbin/
16.启动Hadoop的HDFS相关进程。
./start-dfs.sh
这里只会启动HDFS相关进程。

https://blog.csdn.net/m0_52735414/article/details/124695587


17.输入jps查看HDFS相关进程是否已经启动。
jps
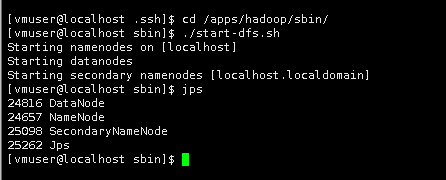
可以看到相关进程都已经启动。
18.下面可以再进一步验证HDFS运行状态。
先在HDFS上创建一个目录。
hadoop fs -mkdir /myhadoop1
19.执行下面命令,查看目录是否创建成功。
hadoop fs -ls -R /

以上,便是HDFS安装过程。
20.下面来配置MapReduce相关配置。
再次切换到hadoop配置文件目录
cd /apps/hadoop/etc/Hadoop
21.打开mapred-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/mapred-site.xml
将mapreduce相关配置,添加到<configuration>标签之间。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/apps/hadoop/etc/hadoop:/apps/hadoop/share/hadoop/common/lib/*:/apps/hadoop/share/hadoop/common/*:/apps/hadoop/share/hadoop/hdfs:/apps/hadoop/share/hadoop/hdfs/lib/*:/apps/hadoop/share/hadoop/hdfs/*:/apps/hadoop/share/hadoop/mapreduce/*:/apps/hadoop/share/hadoop/yarn:/apps/hadoop/share/hadoop/yarn/lib/*:/apps/hadoop/share/hadoop/yarn/*</value>
</property>
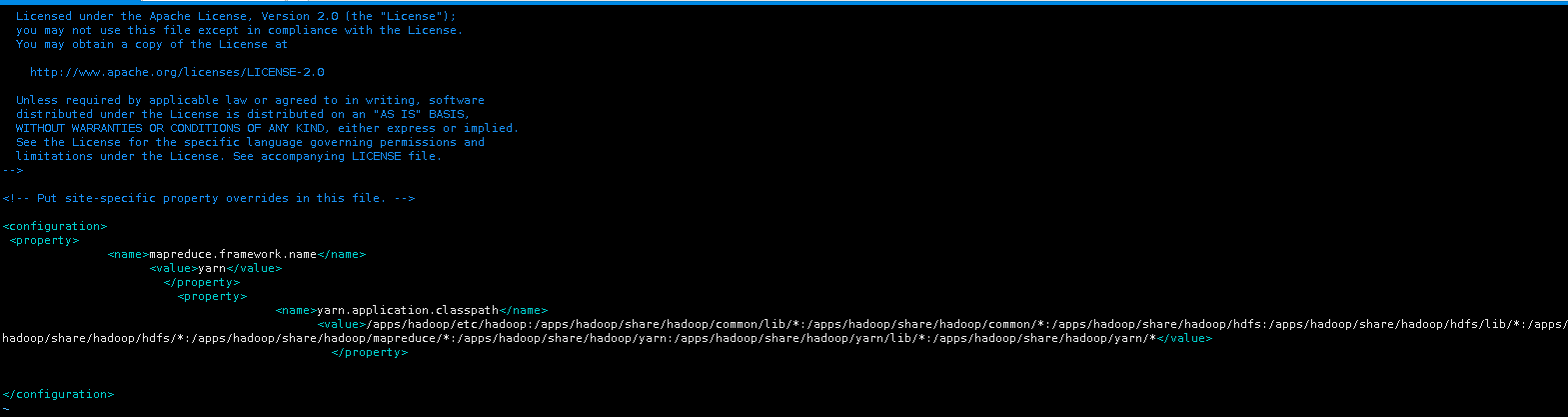
这里指定mapreduce任务处理所使用的框架。
22.打开yarn-site.xml配置文件。
vim /apps/hadoop/etc/hadoop/yarn-site.xml
将yarn相关配置,添加到<configuration>标签之间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

这里的配置是指定所用服务,默认为空。
23.下面来启动计算层面相关进程。
切换到hadoop启动目录。
cd /apps/hadoop/sbin/
24.执行命令,启动yarn。
./start-yarn.sh
25.输入jps,查看当前运行的进程。
jps
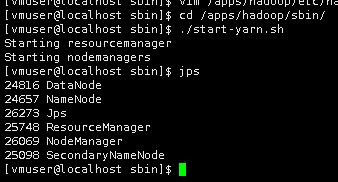
26.执行测试。
切换到/apps/hadoop/share/hadoop/mapreduce目录下。
cd /apps/hadoop/share/hadoop/mapreduce
然后,在该目录下跑一个mapreduce程序,来检测一下hadoop是否能正常运行。
hadoop jar hadoop-mapreduce-examples-3.0.0.jar pi 2 2
这个程序是计算数学中的pi值。当然暂时先不用考虑数据的准确性。当你看到下面流程的时候,表示程序已正常运行,hadoop环境也是没问题的。
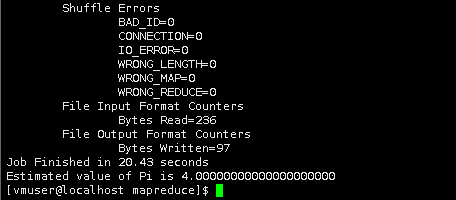
至此,Hadoop 伪分布模式已经安装完成!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号