容器平台应用搭建
三 容器平台应用搭建
3.1 数据库部分
3.1.1 关系数据库
3.1.1.1 Mysql
MySQL 是最流行的关系型数据库管理系统,在 结构化数据方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件。
(1)Mysql 安装
在第二章Docker 应用容器引擎,2.2.3 节Docker基础用法中介绍了Mysql 安装过程。
(2)Mysql用户授权
MySQL 赋予用户权限命令:grant 权限 on 数据库对象 to 用户
授权test1账户设置密码为123456,操作menagerie数据库。
进入root用户(mysql -u root -p),打开命令符界面
|
CREATE DATABASE menagerie; USE menagerie create user test1@'%' identified by '123456' /* GRANT ALL ON menagerie.* TO 'your_mysql_name'@'your_client_host'; */ GRANT ALL ON menagerie.* TO test1@'%'; mysql -h host -utest1 -pmenagerie SHOW TABLES; CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),species VARCHAR(20), sex CHAR(1), birth DATE, death DATE); SHOW TABLES; DESCRIBE pet; INSERT INTO pet VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL); /*查看test1账户信息*/ use mysql; select host,user,plugin,authentication_string from mysql.user where user='test1'; /*修改test1密码*/ ALTER USER 'test1'@'%' IDENTIFIED WITH mysql_native_password BY '123456' |
(3)根据数据字典形成数据标准表
《中华人民共和国教育行业标准》定义了教育行业数据标准,本部分内容主要解决根据数据标准,生成标准数据表。
- 创建数据项标准表
|
DROP TABLE IF EXISTS `standardmaintable1`; CREATE TABLE `standardmaintable1` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `identifierName` varchar(10) NOT NULL COMMENT '编号', `dataitemname` varchar(255) NOT NULL COMMENT '数据项名称', `chineseshort` varchar(255) NOT NULL COMMENT '中文简称', `dataitemtype` varchar(1) NOT NULL COMMENT '数据项类型', `dataitemlength` varchar(10) DEFAULT NULL COMMENT '长度', `dataitemrestrict` varchar(1) DEFAULT NULL COMMENT '约束', `dataitemarea` varchar(255) DEFAULT NULL COMMENT '值空间', `dataitemexplain` varchar(255) DEFAULT NULL COMMENT '解释说明', `citeNumber` varchar(255) DEFAULT NULL COMMENT '引用编号', `standardtablename` varchar(255) NOT NULL COMMENT '表名', `standardclass` varchar(15) NOT NULL COMMENT '表类别说明', PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8; |
- 插入数据项标准表数据
|
-- ---------------------------- -- Records of standardmaintable1 -- ---------------------------- INSERT INTO `standardmaintable1` VALUES ('1', 'JCXX010101', 'XXDM', '学校代码', 'C', '30', 'M',null, null, null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('2', 'JCXX010102', 'XXMC', '学校名称', 'C', '255', 'M',null, null, null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('3', 'JCXX010103', 'XXYWMC', '学校英文名称', 'C','255', 'O', null, '', null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('4', 'JCXX010104', 'XXDZ', '学校地址', 'C', '255', 'M',null, null, null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('5', 'GXXX030301', 'YXSZBZS', '院系所总编制数', 'N','4', 'O', null, null, null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('6', 'GXXX050223', 'WYYSYQSBZZ', '万元以上仪器设备总值', 'M', null, 'M', null, '单位:元', null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('7', 'GXXS050106', 'WYKSCJ', '外语考试成绩', 'N','5,1', 'O', null, '单位:分 ', null, 'GXXX0101', 'JY/T1006—2012'); INSERT INTO `standardmaintable1` VALUES ('8', 'GXXX050101', 'XKDJJ', '学科点简介', 'T', null, 'M',null, null, null, '', ''); |
数据显示如下图
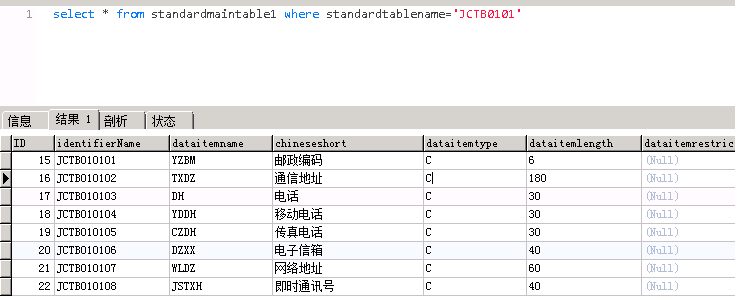
- 构建存储过程,根据数据项标准表生成标准数据表结构
# 构造 SQL,构建 sql 语句,用于生成标准表SQL语句,存储过程名称为proc_create_table0
|
DROP PROCEDURE proc_create_table0; CREATE DEFINER=`root`@`%` PROCEDURE `proc_create_table0`(table_name VARCHAR(255)) BEGIN DECLARE varID INT; # 编号 DECLARE varidentifierName VARCHAR(10); # 编号 DECLARE vardataitemname VARCHAR(10); # 数据项名称 DECLARE varchineseshort VARCHAR(10); # 中文简称 DECLARE vardataitemtype VARCHAR(100); # 数据项类型 DECLARE vardataitemlength VARCHAR(10); # 长度 DECLARE vardataitemrestrict VARCHAR(10); # 约束 DECLARE vardataitemarea VARCHAR(10); # 值空间 外键 DECLARE vardataitemexplain VARCHAR(100); # 解释说明 DECLARE varciteNumber VARCHAR(10); # 引用编号 DECLARE Done INT DEFAULT 0; DECLARE rs CURSOR FOR select ID, identifierName, dataitemname, chineseshort, #dataitemtype, case when dataitemtype='C' then concat('varchar',"(",standardmaintable1.dataitemlength,")") when dataitemtype='N' then concat('decimal',"(",standardmaintable1.dataitemlength,")") when dataitemtype='M' then concat('decimal',"(15,4)") when dataitemtype='T' then 'text' when dataitemtype='B' then 'binary(255) ' END as dataitemtype, dataitemlength, dataitemrestrict, dataitemarea, dataitemexplain, citeNumber from standardmaintable1 where standardtablename=table_name; DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET Done = 1; select table_name; SET @sql1=CONCAT("DROP TABLE IF EXISTS `",table_name,"`;" ); select @sql1; CALL proc_create_table(@sql1); # 前5列不能为空,最后2列不能为空 OPEN rs; FETCH NEXT FROM rs INTO varID,varidentifierName,vardataitemname,varchineseshort,vardataitemtype,vardataitemlength,vardataitemrestrict,vardataitemarea,vardataitemexplain,varciteNumber; SET @sql2=CONCAT("CREATE TABLE `",table_name,"` ("); SET @sql2=CONCAT(@sql2," `ID` int(11) NOT NULL AUTO_INCREMENT,"); REPEAT IF NOT Done THEN #第一次为建表create table ,后面为增加字段 # select varID,varidentifierName,vardataitemname,varchineseshort,vardataitemtype,vardataitemlength,vardataitemrestrict,vardataitemarea,vardataitemexplain,varciteNumber; SET @sql2=CONCAT(@sql2,"`",varidentifierName,"` ",vardataitemtype," NULL COMMENT '",vardataitemname,varchineseshort,"',"); END IF; FETCH NEXT FROM rs INTO varID,varidentifierName,vardataitemname,varchineseshort,vardataitemtype,vardataitemlength,vardataitemrestrict,vardataitemarea,vardataitemexplain,varciteNumber; UNTIL Done END REPEAT; CLOSE rs; SET @sql2=CONCAT(@sql2, " PRIMARY KEY (`ID`)"); SET @sql2=CONCAT(@sql2, " ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;"); select @sql2; CALL proc_create_table(@sql2); END |
# 执行生成的标准表SQL语句,创建标准表,存储过程名称为proc_create_table
|
DROP PROCEDURE proc_create_table; CREATE DEFINER=`root`@`%` PROCEDURE `proc_create_table`(sqlstenence VARCHAR(10000)) BEGIN SET @sql1=sqlstenence; PREPARE STMT from @sql1; EXECUTE STMT; DEALLOCATE PREPARE STMT; END |
- 执行存储过程,生成标准表
|
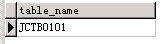
CALL proc_create_table0('JCTB0101'); |
执行结果如下图所示:
结果1
结果1(2)
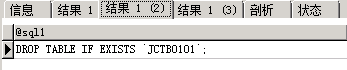
结果1(3)


3.1.1.2 Sqlite
(1)SQLite特征和应用场景
SQLite3只是一个轻型的嵌入式数据库引擎,占用资源非常低,处理速度比Mysql还快,专门用于移动设备上进行适量的数据存取,它只是一个文件,不需要服务器进程。
- SQLite的优点
源代码不受版权限制,真正的自由,开源和免费.
无服务器,不需要一个单独的服务器进程或者操作的系统
一个SQLite 数据库是存储在一个单一的跨平台的磁盘文件
零配置,因为其本身就是一个文件,不需要安装或管理,轻松携带
不需要任何外部的依赖,所有的操作等功能全部都在自身集成.
轻量级,SQLite本身是C写的,体积很小,经常被集成到各种应用程序中.
- SQLite的缺点
缺乏用户管理和安全功能
只能本地嵌入,无法被远程的客户端访问,需要上层应用来处理这些事情;
不适合大数据
适合单线程访问,对多线程高并发的场景不适用;
各种数据库高级特性它都不支持,比如管理工具、分析工具、维护等等;
SQLite3 应用场景:(1)小型网站 (2) 嵌入式设备 (3) 数据库教学 (4) 本地应用程序
(2)SQLite安装
|
docker search sqlite docker pull nouchka/sqlite3 docker run -itd --name sqlite3-test nouchka/sqlite3 /bin/bash docker exec -it sqlite3-test /bin/sh |
(3)SQLite基本操作
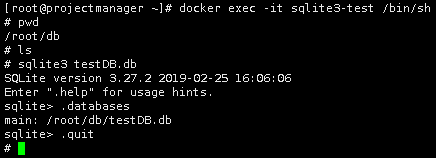
- 创建一个新的数据库 <testDB.db>
# sqlite3 testDB.db
.databases 命令来检查它是否在数据库列表中
sqlite> .databases
SQLite .quit 命令退出 sqlite 提示符
- 基本操作(CRUD操作)
CRUD即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)
|
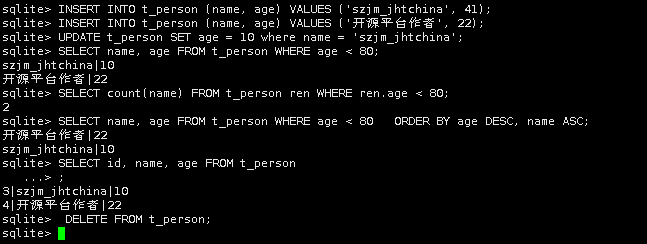
CREATE TABLE IF NOT EXISTS t_person (id integer PRIMARY KEY AUTOINCREMENT, name text NOT NULL, age integer NOT NULL); INSERT INTO t_person (name, age) VALUES ('szjm_jhtchina', 41); INSERT INTO t_person (name, age) VALUES ('开源平台作者', 22); UPDATE t_person SET age = 10 where name = 'szjm_jhtchina'; SELECT name, age FROM t_person WHERE age < 80; SELECT count(name) FROM t_person ren WHERE ren.age < 80; SELECT name, age FROM t_person WHERE age < 80 ORDER BY age DESC, name ASC; // 先按年龄降序,再按名字升序。 SELECT id, name, age FROM t_person ; DELETE FROM t_person; |
3.1.1.3 PostgresSQL
PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。
(1)PostgreSQL安装
|
docker search postgresql /*查找镜像*/ docker pull postgres /*拉取postgresql镜像*/ docker images |grep postgres /*查找postgres 镜像*/ docker run --name postgres2 -e POSTGRES_PASSWORD=password -p 5432:5432 -v pgdata:/var/lib/postgresql/data -d postgres /*初始化镜像*/ /* -p端口映射 -v将数据存到宿主服务器 -e POSTGRES_PASSWORD 密码(默认用户名postgres) -e TZ=PRC时区,中国 -d后台运行 --name容器名称 时区问题 如果在启动容器时不设置时区,默认为UTC,使用now()设置默认值的时候将有时间差。 */ docker inspect postgres2 /*查看容器信息*/ docker exec -it postgres2 /bin/bash /*进入镜像*/ /* 镜像的data目录在 /var/lib/postgresql/data */ /*进入postgresql的工具目录/usr/lib/postgresql/13/bin */ cd /usr/lib/postgresql/13/bin psql –upostgres /*连接数据库*/
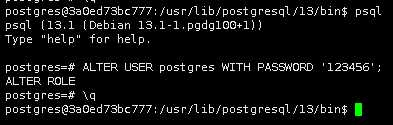
/* docker进入容器,修改postgresql密码*/ su postgres psql ALTER USER postgres WITH PASSWORD '123456'; \q
CREATE DATABASE szjmjhtchina; /*创建数据库*/ SELECT version(); /* 查看数据库版本 PostgreSQL 13.1 (Debian 13.1-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit */ \q /*退出psql*/ psql -s szjmjhtchina /*进入数据库名为szjmjhtchina 的数据库 */ |

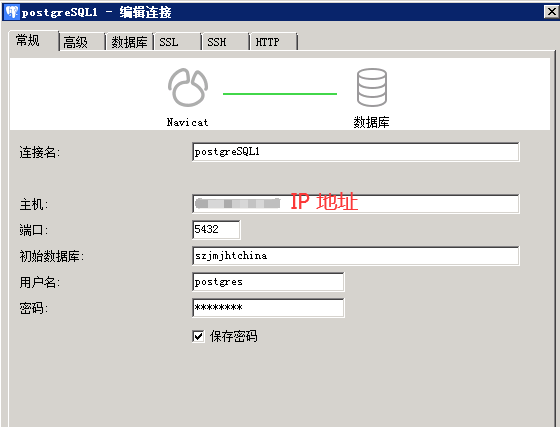
Navicat 12 客户端连接
|
|

(2)PostgreSQL特征和应用场景
PostgreSQL完全免费,而且是BSD协议;
PostgreSQL特征:
函数:通过函数,可以在数据库服务器端执行指令程序;
索引:用户可以自定义索引方法,或使用内置的 B 树,哈希表与 GiST 索引;
触发器:触发器是由SQL语句所触发的事件;
规则:规则(RULE)允许一个查询能被重写,通常用来实现对视图(VIEW)的操作,如插入(INSERT)、更新(UPDATE)、删除(DELETE);
数据类型:包括文本、任意精度的数值数组、JSON 数据、枚举类型、XML 数据;
全文检索:通过 Tsearch2 或 OpenFTS,8.3版本中内嵌 Tsearch2;
NoSQL:JSON,JSONB,XML,HStore 原生支持,至 NoSQL 数据库的外部数据包装器;
数据仓库:能平滑迁移至同属 PostgreSQL 生态的 GreenPlum,DeepGreen,HAWK 等,使用 FDW 进行 ETL。
PostgreSQL应用场景:
根据腾讯云云开发者社区介绍(文档中心 > 云数据仓库 PostgreSQL > 产品简介 > 应用场景),有如下应用场景,经营分析决策;海量日志分析;用户行为实时洞察等;
(3)PostgreSQL基本操作(CRUD操作)
本部分内容参考《PostgreSQL 12.2手册》
- 创建数据表
表名weather
|
CREATE TABLE weather ( city varchar(80), temp_lo int, -- 最低温度 temp_hi int, -- 最高温度 prcp real, -- 湿度 date date ); DROP TABLE weather ; /*删除weather 表*/ |
psql可以识别该命令直到分号才结束。
表名cities
|
CREATE TABLE cities ( name varchar(80), location point ); |
类型point就是一种PostgreSQL特有数据类型的例子。
- 在表中增加数据
|
INSERT INTO weather(city, temp_lo, temp_hi, prcp, date) VALUES ('苏州', 36, -2, 0.25, '2010-11-27'); INSERT INTO weather(city, temp_lo, temp_hi, prcp, date) VALUES ('苏州', 23, -4, 0.25, '2010-12-27'); INSERT INTO weather (city, temp_lo, temp_hi, prcp, date) VALUES ('南京', 43, 57, 0.0, '2014-11-29'); INSERT INTO cities VALUES ('苏州', '(120.62 ,31.32)'); INSERT INTO cities VALUES ('南京', '(118.78,32.04)'); |
- 查询数据
|
SELECT city, temp_lo, temp_hi, prcp, date FROM weather; SELECT * FROM weather WHERE city = '苏州' AND prcp > 0.0; /*表关联*/ SELECT weather.city, weather.temp_lo, weather.temp_hi, weather.prcp, weather.date, cities.location FROM weather, cities WHERE cities.name = weather.city; /*查询最高的温度*/ SELECT max(temp_lo) FROM weather; /*查询温度最高的城市*/ SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather); /*获取每个城市观测到的最低温度的最高值*/ SELECT city, max(temp_lo) FROM weather GROUP BY city; |
- 更新数据
|
/*所有 11 月 28 日以后的温度读数都低了两度*/ UPDATE weather SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2 WHERE date > '1994-11-28'; |
- 删除数据
|
DELETE FROM weather WHERE city = '南京'; |
- 创建视图
|
CREATE VIEW myview AS SELECT city, temp_lo, temp_hi, prcp, date, location FROM weather, cities WHERE city = name; |
3.1.2 非关系型数据库
3.1.2.1 MongoDB
MongoDB 是一个免费的开源跨平台面向文档的 NoSQL 数据库程序。是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
(1)MongoDB安装
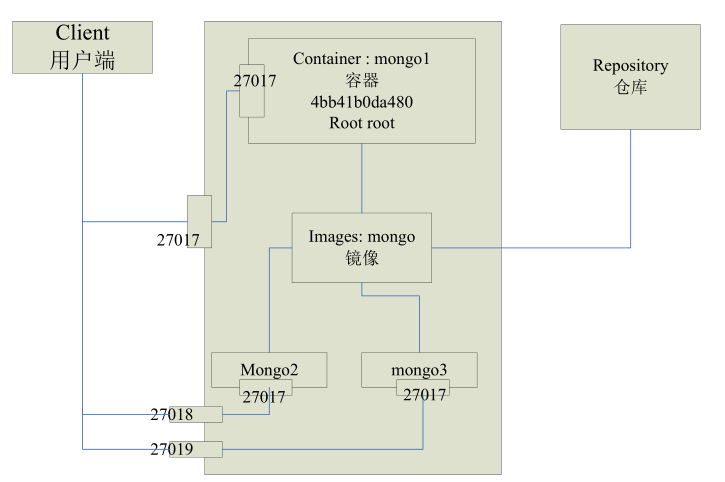
下图为安装MongoDB集群的架构图,本部分讲解独立节点Docker下安装。
|
docker search mongodb /*查看仓库中的mongodb镜像*/ docker pull mongo /*拉取mongodb镜像到本地*/ docker images /*查看本地镜像*/ docker run -itd --name mongo -p 27017:27017 mongo –auth /*运行容器*/ /*参数说明:-p 27017:27017 :映射容器服务的 27017 端口到宿主机的 27017 端口。外部可以直接通过 宿主机 ip:27017 访问到 mongo 的服务。 --auth:需要密码才能访问容器服务。 */ docker ps | grep mongo /*查看mongoDB容器*/ docker exec -it mongo /bin/bash /*进入mongoDB容器Shell命令模式*/ mongo /*进入mongo命令行*/ use admin /*切换到admin库,mongo默认库用来保存操作用户信息*/ db.createUser({user:"root",pwd:"root",roles:[{role:'root',db:'admin'}]}) /*创建用户,此用户创建成功,则后续操作都需要用户认证*/ use szjm_jhtchina /*创建数据库名为szjm_jhtchina的数据库*/ db /*查看当前数据库名*/ |
Navicat 12 客户端与 MongoDB 的连接
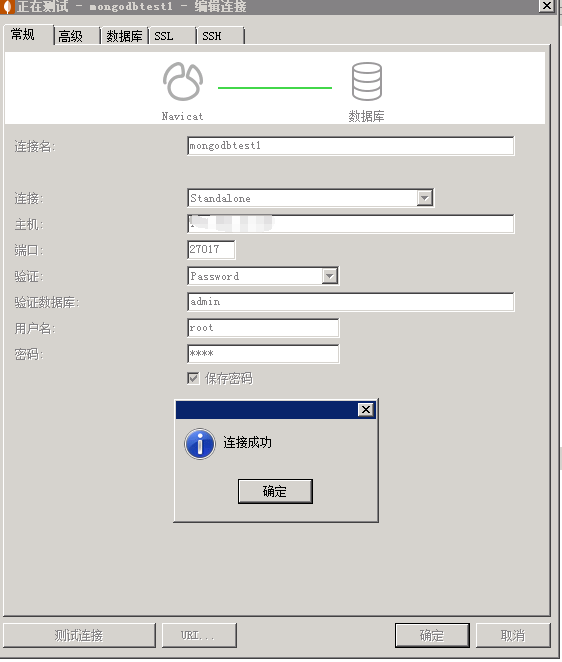
Mongo中的一些概念:
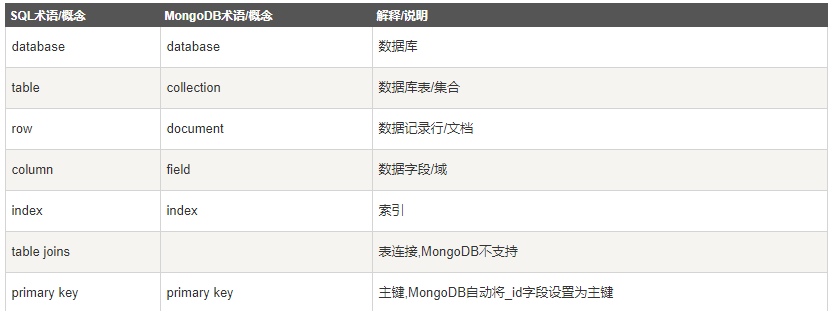
MongoDB 数据逻辑结构分为数据库(database)、集合(collection)、文档(document)三层 。
一个mongod实例中允许创建多个数据库。
一个数据库中允许创建多个集合(集合相当于关系型数据库的表)。
一个集合则是由若干个文档构成(文档相当于关系型数据库的行,是MongoDB中数据的基本单元)。
在MongoDB中有几个内建的数据库:
admin库主要存 放有数据库帐号相关信息;
local数据库永远不会被复制到从节点,可以用来 存储限于本地单台服务器的任意集合;
config数据库 用于分片集群环境,存放了分片相关的元数据信息;
(2)MongoDB特征和应用场景
MongoDB
(3)MongoDB基本操作(CRUD操作)
CRUD基本操作(增加Create、读取查询Retrieve、更新Update和删除Delete)
|
mongo 127.0.0.1/admin -uroot –proot /*mongo容器下进入数据库命令行模式*/ /*127.0.0.1 :数据库地址 admin 数据库名称 -uroot :用户名是root -proot 密码是root*/ db /*查看当前数据库*/ show dbs /*查看所有数据库*/ use test1 /*创建test1数据库*/ db.collection1.insert({'name':'szjm_jhtchina'}) /*向collection1集合插入数据*/ /*删除collection1集合*/ db.collection1.drop() db.collection1.insert({title: 'MongoDB 教程', description: 'MongoDB 在智慧校园中的建设应用', by: 'jhtchina', url: 'http://www.szjm.edu.cn', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }) db.collection1.insert({title: 'Redis 教程', description: 'Redis在智慧校园中的建设应用', by: 'jhtchina', url: 'http://www.szjm.edu.cn', tags: [' Redis', 'database', 'NoSQL'], likes: 200 }) /*向collection1集合插入数据*/ show dbs /*显示数据库*/ show collections /*显示集合*/ db.collection1.find() /*查看集合collection1中的数据*/ db.collection1.find({'title':'Redis 教程'}) /*查看title为Redis 教程的记录*/ db.createCollection("table1") /*创建table1集合*/ db.table1.insert({"name":"test1","Age":20,"role":["baby","doctor","nurse"]}) db.table1.insert({"name":"jhtchina","Age":18,"role":["student","teacher","engineer"]}) db.table1.find({"name":"test1"}) /*查询name为test1的数据*/ db.table1.find({"name":"jhtchina"}) /*查询name为jhtchina的数据*/ db.table1.find({"Age":18}) /*查询Age为18的数据*/ db.table1.find({$or:[{"name":"jhtchina"},{"Age": 20}]}).pretty() /*查询name为jhtchina或者Age为20的数据,并且标准化格式输出*/ db.table1.find({"Age":{$lt:19}}).pretty() /*查询Age小于19的数据*/ /* MongoDB中条件操作符有: (>) 大于 - $gt (<) 小于 - $lt (>=) 大于等于 - $gte (<= ) 小于等于 - $lte */ db.table1.update({'name':'jhtchina'},{$set:{'Age':41}}) /*根据name=jhtchina修改Age为41*/ db.table1.remove({"name":"jhtchina"}) /*删除name为jhtchina 的数据*/ db.table1.renameCollection("table1New") /*修改table1的名字为table1New */ /*备份test1 数据库到home目录*/ mongodump -h 127.0.0.1:27017 -uroot -proot --authenticationDatabase admin -d test1 -o /home /*mongo数据库命令符模式下,删除test1 数据库*/ use test1 show tables db.dropDatabase() /*恢复test1数据库*/ mongorestore -uroot -proot --authenticationDatabase admin -d test1 /home/test1 /*验证数据*/ use test1 db.table1New.findOne() |
在 https://github.com/tmcnab/northwind-mongo 下载测试数据
拷贝宿主机文件到容器相应目录下
|
docker cp /home/dump/. mongo:/home/dump |
mongorestore 恢复数据到数据库
|
mongorestore -uroot -proot --authenticationDatabase admin -d test1 /home/dump/ |
进入mongo数据库查看还原的数据表信息
|
mongo 127.0.0.1/admin -uroot –proot /*进入mongo数据库shell命令模式*/ use test1 show collections /*查看集合信息*/ |
(4)mongoDB复制集机制及其应用
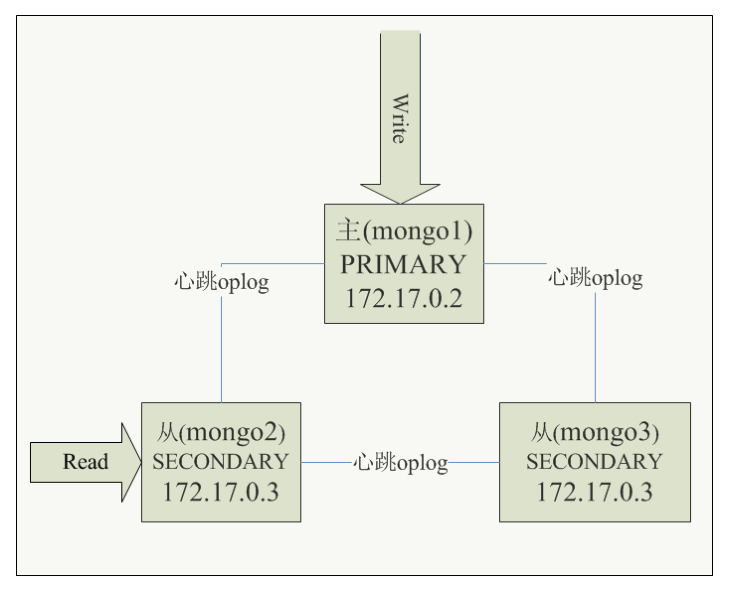
Mongodb复制集,就是mongod进程,这些进程维护同一个数据集合。复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础。
复制集目的:保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险。同时提高读取能力,用户的读取服务和写入服务在不同的地方,而且,由不同的服务为不同的用户提供服务,提高整个系统的负载。
复制集框架图如下图所示:
具体实施过程:
|
/*创建mongo1,mongo2,mongo3容器*/ docker run --name mongo1 -p 27017:27017 -d mongo --replSet "rs0" --bind_ip_all docker run --name mongo2 -p 27018:27017 -d mongo --replSet "rs0" --bind_ip_all docker run --name mongo3 -p 27019:27017 -d mongo --replSet "rs0" --bind_ip_all /*查看容器的IP地址*/ docker inspect mongo1 | grep -i ipaddress docker inspect mongo2 | grep -i ipaddress docker inspect mongo3 | grep -i ipaddress /*查看3个容器的端口*/ docker port mongo1 docker port mongo2 docker port mongo3 docker exec -it mongo1 /bin/bash /*进入mongo命令行模式*/ mongo use test /*初始化复制集*/ rs.initiate( { _id : "rs0", members: [ { _id: 0, host: "172.17.0.8:27017" }, { _id: 1, host: "172.17.0.9:27017" }, { _id: 2, host: "172.17.0.10:27017" } ] }) /*查看节点信息*/ rs.status() exit mongo mongodb://172.17.0.8:27017,172.17.0.9:27017,172.17.0.10:27017/test?replicaSet=rs0 use test db.order.insert({price: 1}) db.order.insert({price: 2}) db.order.insert({price: 3}) db.order.find({}) /*在 mongo2 DB 上查看同步的数据*/ docker exec -it mongo2 /bin/bash mongo use test db.getMongo().setSlaveOk() db.order.find({}) /*通过修改配置文件实现副本节点数据自动同步*/ find / -name .mongorc.js /*查找文件.mongorc.js */ vi /root/.mongorc.js /*在文件内添加一段 rs.slaveOk(); 并保存*/ /*如果容器不能识别vi,需要安装vi apt-get update apt-get install vim*/ /*再次进入mongo命令模式下,可以查看到数据实现自动同步*/ mongo use test db.order.find({}) |
(5)mongoDB 聚合运算
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。聚合是基于数据处理的聚合管道,每个文档通过一个有多个阶段(stage)组成的管道;可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
|
/*limit会接受一个数字n,返回结果集中的前n个文档*/ db.orders.find({}).limit(10).pretty() /*查询 orders 集合, userId 大于 8000,小于 9000, 并且'total' 大于 600 并且('country' ='China' 或者 'status'='fulfilled') ,限制读取 100 表,按照 'userId' 升序排列。*/ db.orders.find({ 'userId': { $lt: 9000, $gt: 8000 }, 'total': { $gt: 600 }, $or: [{ 'country': 'China', 'status': 'fulfilled' }] }).limit(100).sort({ 'userId': 1 }).pretty() |
聚合运算格式:db.集合名称.aggregate({管道: {表达式}})
|
/*获取 orders 数据集的 city 字段和 state 字段*/ db.orders.aggregate({ $project: { city: 1, state: 1 } }) /*查询嵌套在一个数组的 JSON 对象 例如:'orderLines. qty' 为 11 和 100 的文档*/ db.orders.find({ $and: [{ 'orderLines.qty': 100 }, { 'orderLines.qty': 11 }] }).pretty() /*查询'orderLines. qty' 为 11 和 100 的文档,并且 ShippingFee 的值加 1000,然后将结果赋值给一个新的字段:ShippingFeeNew,限制显示前 2 行。*/ db.orders.aggregate( [ { $project: { _id: 1, city: 1, state: 1, ShippingFee: 1, ShippingFeeNew: { $add: ["$shippingFee", 1000] }, orderLines: 1 } }, { "$limit": 2 } ] ); /*获取 orders 集合中shippingFee>=7 并且 shippingFee<=9的数据*/ db.orders.aggregate({ $match: { shippingFee: { $gte: 7, $lte: 9 } } }).pretty() /*获取 orders 集合的 shippingFee>=7 且 shippingFee<=10,然后将符合条件的记录送到下一阶段$group 管道操作符进行处理,类似于在 SQL 中的 group by 语法*/ db.orders.aggregate([ { $match: { shippingFee: { $gte: 7, $lte: 10 } } }, { $group: { _id: 'countNew', count: { $sum: 1 } } } ]);
/*查询 3 条文档记录,标准化输出*/ db.orders.aggregate({$limit:3}).pretty() /*获取 orders 集合中第 99999 条数据之后的数据*/ db.orders.aggregate({ $skip: 99999}).pretty(); /* SQL 语句中的 count(*),统计文档个数*/ db.orders.aggregate([ { $group: { _id: 'countNew', count: { $sum: 1 } } } ]); |
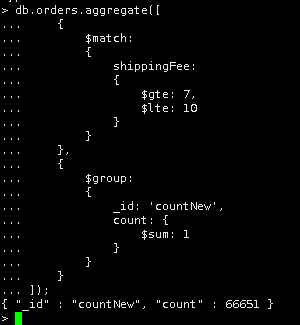
聚合查询(project、match、group、limit、skip、unwind、sort)
3.1.2.2 Redis
Redis 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 的 NoSQL 数据库,并提供多种语言的 API。
(1)Redis 安装
|
docker search redis /*查找redis镜像*/ docker pull redis /*获取redis镜像*/ docker images |grep redis /*查看本地redis镜像*/ docker run -itd --name redis-test -p 6379:6379 redis /*运行容器*/ /* 参数说明:-p 6379:6379:映射容器服务的 6379 端口到宿主机的 6379 端口。外部可以直接通过宿主机ip:6379 访问到 Redis 的服务。 */ docker ps | grep redis /*查看容器的运行信息*/ docker exec -it redis-test /bin/bash /*进入redis容器*/ redis-cli /* redis-cli 连接测试使用 redis 服务*/
|

(2)Redis 命令
- Redis 数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
string 类型
String 是 redis 最基本的类型,一个 key 对应一个 value。string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB,一个键最大能存储 512MB。
实例:
|
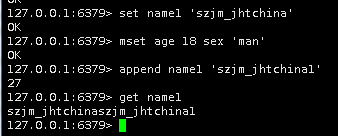
127.0.0.1:6379> set name1 'szjm_jhtchina' OK 127.0.0.1:6379> get name1 "szjm_jhtchina" 127.0.0.1:6379> del name1 (integer) 1 |
Hash(哈希)类型
Redis hash 是一个键值(key=>value)对集合。Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
|
HMSET address1 country "china" province "jiangsu" city "suzhou" college "szjm" department "smart campus center" HGET address1 country HGET address1 city del address1 |
实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。
List(列表)类型
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
|
redis-cli --raw /*redis shell*/ lpush province '江苏' lpush province '河南' lpush province '安徽' lpush province '浙江' lpush province '上海' lrange province 0 10 |
Set(集合) 类型
Redis 的 Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
sadd 命令:添加一个 string 元素到 key 对应的 set 集合中,成功返回 1,如果元素已经在集合中返回 0。
|
sadd databases1 redis sadd databases1 mongodb sadd databases1 mysql sadd databases1 mysql smembers databases1 /*输出结果: mysql redis mongodb */ |
以上实例中 mysql添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
|
ZADD databases1 0 redis ZADD databases1 1 mongodb ZADD databases1 2 mysql ZADD databases1 2 mysql ZADD databases1 3 oracle ZADD databases1 4 mysql ZRANGE databases1 0 10 WITHSCORES /* 运行结果 127.0.0.1:6379> ZRANGE databases1 0 10 WITHSCORES 1) "redis" 2) "0" 3) "mongodb" 4) "1" 5) "oracle" 6) "3" 7) "mysql" 8) "4" */ |
redis 数据类型增删改查(CRUD操作)
|
/*字符串 string set key value # 添加一条 mset key value [key value...] # 添加多条 append key value # 添加到末尾 */
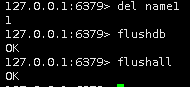
/*列表list*/ del key # 删除key flushdb #删除当前数据库所有key flushall # 删除所有
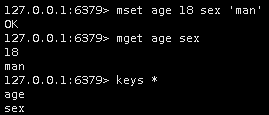
/*修改数据 rename key newkey #改名 set key value # 直接替换 查看数据 get key #查看一条 mget key [key...] # 查看多条 keys * # 查看所有key */
/*列表list 添加数据 lpush key value [value...] # 头部插入 rpush key value [value...] # 尾部插入*/ lpush my_list a b c d e f rpush my_list 1 2 3 4 5 6 LRANGE my_list 0 100 /*删除数据 lpop key # 删除左边第一个 rpop key # 删除右边第一个 lrem key count value # 删除指定数量的值 当count = 0 时 删除所有指定值*/ lrem my_list 1 a /*删除列表中字符为a的数据*/ /*修改数据 lset key index newvalue # 指定索引号修改*/ lset my_list 2 aa /*修改索引号为2的数据*/ /*查看数据 lindex key index # 返回指定索引值 lrange key start stop # 查看索引范围内的值 llen key # 查看长度 */ /*哈希 hash 添加数据 hset key field value # 添加一条 hmset key field value [field value...] */
/*删除数据 hdel key field*/ hdel user age /*查看数据hget key field # 获取value hmget key field [field...] # 获取多个value hvals key # 获取全部value hkeys key # 获取全部field hgetall key # 获取全部field 和 value hlen key # 查看有几个键值对*/ /*集合 set*/ /*新增 sadd key member [member...] #增加元素*/ /* 删除 srem key member [member...] #移除元素 spop key # 随机删除 */ /*查看 scard key # 返回key中元素个数 smemebers key # 获取集合中所有元素*/ sadd set1 a b c 40 80 szjm sgzx smembers set1 /*交集sinter my_set1 my_set2 # 求交集 sinterstore newset my_set1 my_set2 # 交集合并到新集合 并集 sunion key1 key2 # 求并集 sunionstore newkey key1 key2 # 并集合并到新集合*/ sadd set2 a b c 40 80 szjm test sinter set1 set2 sunion set1 set2 /*差集 sdiff key1 key2 # 差集 sdiffstore newkey key1 key2 # 差集合并到新集合 */ sdiff set1 set2 sdiffstore set1 set2 set3 smembers set3 /*有序集合 zset*/ /*新增 zadd key score member[ [score member] ..] 删除 zrem key member [member...] #移除有序集合中的一个或多个元素,若member不存在则忽略; zremrangebyrank min max : # 删除集合中 score 在给定区间的元素 查看 zscore key member # 查看score值 zrange key start stop[withscores] #按索引返回key的成员, withscores表示显示score zrangebyscore key min max #返回集合中 score 在给定区间的元素 */ |

(3)Redis特点和应用场景
做缓存,就要遵循缓存的语义规定:
读:读缓存redis,没有,读mysql,并将mysql的值写入到redis。
写:写mysql,成功后,更新或者失效掉缓存redis中的值。
一般按照下图的流程来进行业务操作。
在web服务端开发的过程中,redis+mysql是最常用的存储解决方案,mysql存储着所有的业务数据,根据业务规模会采用相应的分库分表、读写分离、主备容灾、数据库集群等手段。但是由于mysql是基于磁盘的IO,基于服务响应性能考虑,将业务热数据利用redis缓存,使得高频业务数据可以直接从内存读取,提高系统整体响应速度。
利用redis+mysql进行数据的CRUD时需要考虑的核心问题是数据的一致性。业务数据读操作流程:
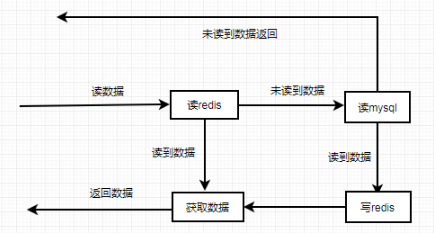
业务数据更新操作流程:
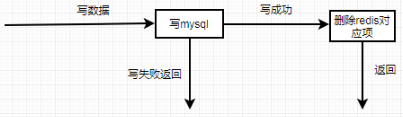
mysql数据更新成功后,直接删除redis中对应项的方式。目的是在保证一致性的过程中以mysql中数据为准,redis中的数据始终保持和mysql的同步。
3.2 应用服务并发分布式架构
3.2.1 tomcat
3.2.1.1 tomcat介绍
Tomcat 服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
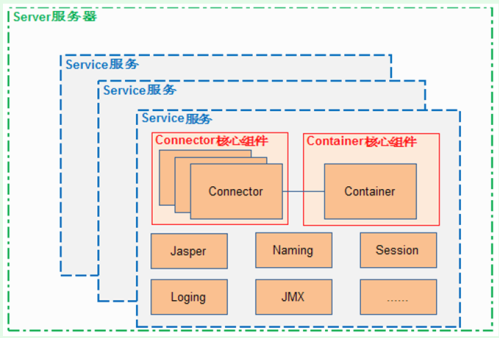
tomcat中包括主要四个元素:Server(总控制)、 Service(服务)、 Connector(专门处理连接) 、Container(处理业务)。浏览器首先会连接Connector,然后放到Container中的Servlet中处理。
3.2.1.2 tomcat 安装与配置
|
docker search tomcat /* docker search tomcat 命令来查看可用版本*/ docker pull tomcat /*拉取官方的镜像*/ docker images|grep tomcat /*在本地镜像列表查找*/ /*命令说明: -p 8080:8080:将主机的 8080 端口映射到容器的 8080 端口。 -v $PWD/test:/usr/local/tomcat/webapps/test:将主机中当前目录下的 test 挂载到容器的 /test。*/ docker run --name tomcat1 -p 8080:8080 -v $PWD/test:/usr/local/tomcat/webapps/test -d tomcat /*查看容器tomcat1 启动情况*/ docker ps |grep tomcat1 docker inspect tomcat1 /*查看容器信息*/ docker exec -it tomcat1 /bin/bash /*进入tomcat1容器*/ cd /usr/local/tomcat/bin /*进入Tomcat下的bin目录*/ ps -ef|grep java /*查看Tomcat状态*/ ./shutdown.sh /*Tomcat关闭命令*/ ./startup.sh /* Tomcat启动命令*/ |
3.2.1.3 tomcat 部署Web应用案例
编写JSP,文件名为test1.jsp 文件保存到容器的 /usr/local/tomcat/webapps/test目录下,并在TOMCAT上运行
|
<%@ page language="java" contentType="text/html; charest=GB18030" pageEncoding="GB18030"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN""http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html;charset=GB18030"> <title>第一个tomcat docker测试</title> </head> <body> <center>HELLO Tomcat Docker!!!</center> </body> </html> |
URL地址: http://IP:8080/test/test1.jsp
Tomcat 的是两个组件:Connector 和 Container, Container 可以选择对应多个 Connector。多个Connector 和一个 Container 就形成了一个 Service,有了 Service 就可以对外提供服务了,Service需要环境支撑。Tomcat中最顶层的容器是Server,代表着整个服务器,一个Server可以包含至少一个Service,用于具体提供服务。所以整个 Tomcat 的生命周期由 Server 控制。Service 对于connector和container的关系:Connector 主要负责对外交流,Container 主要处理 Connector 接受的请求,主要是处理内部事务;Service 将它们连接在一起。Service 只是在 Connector 和 Container 外面多包一层,把它们组装在一起,向外面提供服务,一个 Service 可以设置多个Connector,但是只能有一个 Container 容器。
3.3.2 nginx
3.3.2.1 nginx 介绍
Nginx 是一个高性能的 HTTP 和反向代理 web 服务器,同时也提供了 IMAP/POP3/SMTP 服务 。
3.3.2.2 nginx安装与配置
|
docker search nginx /*查看nginx可用版本*/ docker pull nginx /*拉取官方的最新版本的镜像*/ docker images | grep nginx /*查看本地镜像*/ docker run --name nginx-test -p 8081:80 -d nginx /*运行容器 */ /*参数说明 --name nginx-test:容器名称。 -p 8081:80: 端口进行映射,将本地 8081 端口映射到容器内部的 80 端口。 -d nginx: 设置容器在在后台一直运行。*/ docker inspect nginx-test /*查看nginx-test 容器信息*/ docker stop nginx-test /*停止nginx服务*/ docker start nginx-test /*启动nginx服务*/ docker exec -it nginx-test /bin/bash /*进入nginx容器*/ |
URL地址: http://IP:8081/ 可以打开nginx服务
docker 安装 nginx 并配置反向代理
|
/*将nginx关键目录映射到本机 www: nginx存储网站网页的目录 logs: nginx日志目录 conf: nginx配置文件目录*/ mkdir -p /root/nginx/www /root/nginx/logs /root/nginx/conf /*将nginx-test容器配置文件copy到本地*/ docker cp nginx-test:/etc/nginx/nginx.conf /root/nginx/conf /*创建新nginx容器nginx-web,并将www,logs,conf目录映射到本地*/ docker rm -f nginx-test /*删除nginx-test 容器*/ docker run -d -p 8089:80 --name nginx-web -v /root/nginx/www:/usr/share/nginx/html -v /root/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -v /root/nginx/logs:/var/log/nginx nginx /*创建新nginx容器nginx-web,并将www,logs,conf目录映射到本地*/ docker start nginx-web /*启动nginx */ /*在本机/root/nginx/www目录下创建index.html内容为*/
|
URL地址: http://IP: 8089/ 可以打开nginx服务
3.3.2.3 nginx+tomcat应用案例
Nginx+Tomcat均衡负载,使用Nginx作为Tomcat的负载平衡器。
1安装两个tomcat服务器
2安装Nginx服务器
3配置Nginx实现均衡负载
4测试负载均衡
|
docker rm -f tomcat1 docker rm -f tomcat2 docker rm -f nginx-test rm -rf nginx/ /*创建nginx和tomcat本地目录,稍后将挂载到docker容器上:*/ mkdir -p ~/nginx/www ~/nginx/conf/ ~/nginx/logs mkdir -p ~/tomcat/webapps/ROOT ~/tomcat/conf ~/tomcat/logs /*在tomcat/webapps/ROOT中创建index.html:*/
/*启动tomcat*/ docker run -d --name tomcat1 -v ~/tomcat/webapps:/usr/local/tomcat/webapps tomcat docker run -d --name tomcat2 -v ~/tomcat/webapps:/usr/local/tomcat/webapps tomcat /*获取tomcat容器IP,获取到的IP将配置到nginx的配置文件中*/ docker inspect tomcat1|grep "IPAddress" docker inspect tomcat2|grep "IPAddress" curl http://172.17.0.11:8080 /*在nginx/conf增加配置文件nginx.conf*/
启动nginx docker run -d -p 8090:80 --name nginx1 -v ~/nginx/www:/usr/share/nginx/html -v ~/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -v ~/nginx/logs:/var/log/nginx nginx 使用docker ps查看docker进程: docker ps | grep nginx1 docker ps | grep tomcat1 docker ps | grep tomcat2 /* 访问http://server_ip:8090/index.html: 测试 停止tomcat1 docker stop tomcat1 打开网页,访问正常 部署成功 */ |
3.3.3 ftp
3.3.3.1 ftp介绍
FTP(File Transfer Protocol,文件传输协议) 是 TCP/IP 协议组中的协议之一。FTP协议包括两个组成部分,其一为FTP服务器,其二为FTP客户端。其中FTP服务器用来存储文件,用户可以使用FTP客户端通过FTP协议访问位于FTP服务器上的资源。默认情况下FTP协议使用TCP端口中的 20和21这两个端口,其中20用于传输数据,21用于传输控制信息。
3.3.3.2 ftp安装与配置
|
docker search vsftpd /*查看docker ftp 镜像*/ docker pull vsftpd /*拉取镜像文件到本地*/ ifconfig /*获取本机IP*/ docker run -d -p 21:21 -p 20:20 -p 21100-21110:21100-21110 -v /Ftpfile:/home/vsftpd -e FTP_USER=davion -e FTP_PASS=davion -e PASV_ADDRESS=IP地址 -e PASV_MIN_PORT=21100 -e PASV_MAX_PORT=21110 --name vsftpd --privileged=true --restart=always fauria/vsftpd /*运行FTP镜像 #-p 进行端口绑定映射 #-v 添加容器数据卷 #-e FTP_USER=davion -e FTP_PASS=davion 添加一个初始化用户davion #PASV_MIN_PORT和PASV_MAX_PORT映射的是被动模式下端口使用范围 #-name vsftpd 为容器命名为vsftpd #--restart=always fauria/vsftpd docker重启的时候自动启动这个容器 # --privileged=true docker 应用容器 获取宿主机root权限*/ docker exec -i -t vsftpd bash /*进入container里面*/ vi /etc/vsftpd/virtual_users.txt /*修改并生成虚拟用户模式下的用户db文件,向文件中最后两行写入用户名和密码*/ mkdir /home/vsftpd/user /*假如添加user用户,需要建立对应用户的文件夹*/ chmod -R 777 /home/vsftpd/ user /*设置目录权限可写*/ /usr/bin/db_load -T -t hash -f /etc/vsftpd/virtual_users.txt /etc/vsftpd/virtual_users.db /*把登录的验证信息写入数据库*/ docker restart vsftpd /*重启容器文件*/ |
vsftpd匿名登陆设置
|
docker exec -i -t vsftpd bash vi /etc/vsftpd/vsftpd.conf /*anonymous_enable=YES anon_root=/home/vsftpd/szjm2*/ chown root:root /home/vsftpd/szjm2 /* 此处可能出现错误: 500 OOPS: vsftpd: refusing to run with writable root inside chroot () 需要对文件夹进行设置 */ chmod a-w /home/vsftpd/szjm2 /*去除用户主目录的写权限*/ exit docker restart vsftpd /*重启容器文件,实现Ftp匿名登陆*/ |
3.3.3.3 ftp应用案例
|
/*客户端连接*/
|
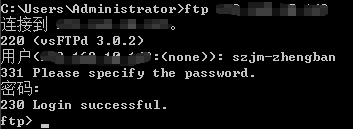
可以采用ftp客户端(CuteFTP Pro)连接ftp服务器
3.3.4 LDAP 轻量级目录访问协议
3.3.4.1 LDAP介绍
LDAP(Light Directory Access Portocol),它是基于X.500标准的轻量级目录访问协议。目录是一个为查询、浏览和搜索而优化的数据库,它成树状结构组织数据,类似文件目录一样。目录数据库和关系数据库不同,它有优异的读性能,但写性能差,并且没有事务处理、回滚等复杂功能,不适于存储修改频繁的数据。所以目录天生是用来查询的,就好象它的名字一样。LDAP目录服务是由目录数据库和一套访问协议组成的系统。
LDAP基本概念
(一)目录树概念
1. 目录树:在一个目录服务系统中,整个目录信息集可以表示为一个目录信息树,树中的每个节点是一个条目。
2. 条目:每个条目就是一条记录,每个条目有唯一可区别的名称(DN)。
3. 对象类:与某个实体类型对应的一组属性,对象类是可以继承的,这样父类的必须属性也会被继承下来。
4. 属性:描述条目的某个方面的信息,一个属性由一个属性类型和一个或多个属性值组成,属性有必须属性和非必须属性。
(二)专有名词DC、UID、OU、CN、SN、DN、RDN
|
关键字 |
英文全称 |
含义 |
|
Dc |
Domain Component |
域名的部分,其格式是将完整的域名分成几部分,如域名为example.com变成dc=example,dc=com(一条记录的所属位置) |
|
Uid |
User Id |
用户ID ht.jia(一条记录的ID) |
|
Ou |
Organization Unit |
组织单位,组织单位可以包含其他各种对象(包括其他组织单元),如“oa组”(一条记录的所属组织) |
|
Cn |
Common Name |
公共名称,如“szjm”(一条记录的名称) |
|
Sn |
Surname |
姓,如“jia” |
|
Dn |
Distinguished Name |
“uid= ht.jia,ou=oa组,dc=example,dc=com”,一条记录的位置(唯一) |
|
rdn |
Relative dn |
相对辨别名,类似于文件系统中的相对路径,它是与目录树结构无关的部分,如“uid= ht.jia”或“cn= szjm” |
(三)基本模型
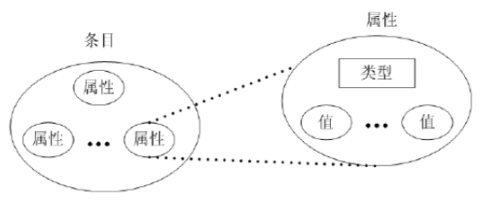
- 信息模型:
在LDAP中信息以树状方式组织,在树状信息中的基本数据单元是条目,而每个条目由属性构成,属性中存储有属性值;
- 命名模型:
LDAP中的命名模型,也即LDAP中的条目定位方式。在LDAP中每个条目均有自己的DN。DN是该条目在这个树中的唯一名称标识,如同文件系统中,带路径的文件名就是DN。
- 功能模型:
LDAP中共有四类10种操作:查询类操作,如搜索、比较;更新类操作,如添加条目、删除条目、修改条目、修改条目名;认证类操作,如绑定、解绑定;其他操作,如放弃和扩展操作。
- 安全模型:
LDAP中的安全模型主要通过身份认证、安全通道和访问控制来实现。
3.3.4.2 LDAP安装与配置
|
docker search ldap docker pull osixia/openldap mkdir -p /usr/local/ldap && cd /usr/local/ldap docker run \ -d \ -p 389:389 \ -p 636:636 \ -v /usr/local/ldap:/usr/local/ldap \ --name ldap \ osixia/openldap /*启动容器 默认配置 dn dc=example,dc=org admin cn=admin,dc=example,dc=org password admin 可以考虑 --privileged=true container内的root拥有真正的root权限*/ docker exec -it ldap /bin/bash /* 进入容器*/ ldapsearch -x -H ldap://localhost:389 -b dc=example,dc=org -D "cn=admin,dc=example,dc=org" -w admin /* 执行查询*/ /*或直接在容器外执行查询*/ docker exec -it ldap ldapsearch -x -H ldap://localhost:389 -b dc=example,dc=org -D "cn=admin,dc=example,dc=org" -w admin /*执行结果如下图所示*/
slapd –VV /*查看LDAP版本信息*/ /* @(#) $OpenLDAP: slapd 2.4.50+dfsg-1~bpo10+1 (May 4 2020 05:25:06) $ Debian OpenLDAP Maintainers <pkg-openldap-devel@lists.alioth.debian.org> */ |
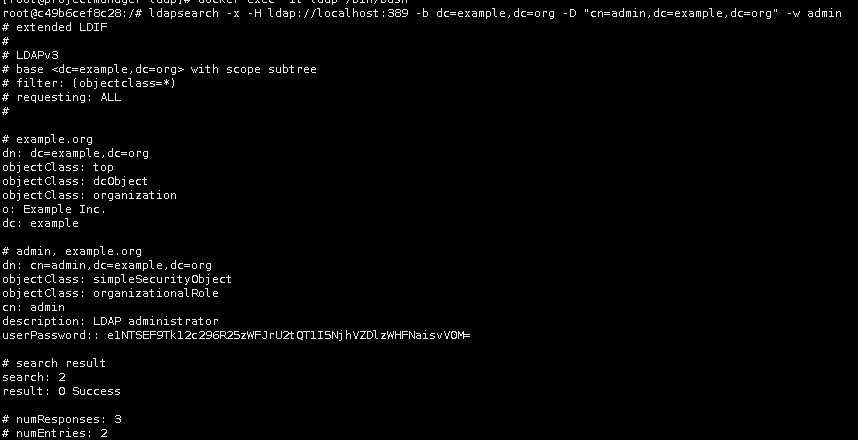
3.3.4.3 LDAP应用案例
openldap目录服务优点
是一个跨平台的标准互联网协议,基于X.500协议
提供静态数据查询搜索,不需要像关系数据库中那样通过SQL语句维护数据库信息
基于推和拉的机制实现节点间数据同步,简称复制(replication)并提供基于TLS/SASL的安全认证机制,实现数据加密传输以及Kerberos密码验证功能。
可以实现用户的集中认证管理,所有关于账号的变更,只需在openldap服务器端直接操作,无需到每个客户端进行操作,影响范围为全局
默认使用TCP/IP协议传输数据
支持各种应用平台:nginx/http/vsftpd/samba/svn/postfix/openstack/hadoop等都可以实现统一用户管理
openldap具有费用低、配置简单、功能强大、管理容易、开源等特点
- Softerra LDAP Browser 使用及配置
(1)New->New Profile并填写Profile:szjmTest1
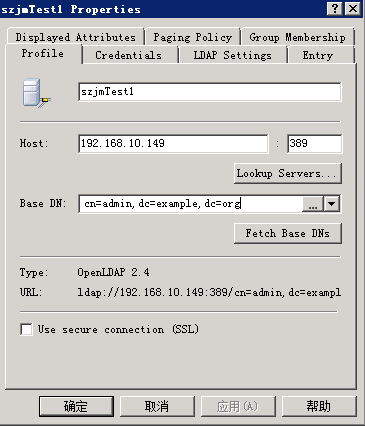
(2)填写Profile General Information
Host:LDAP IP地址;Port :默认端口389;Base DN: cn=admin,dc=example,dc=org
Base DN可以点击Fetch Base DNs 自动带出
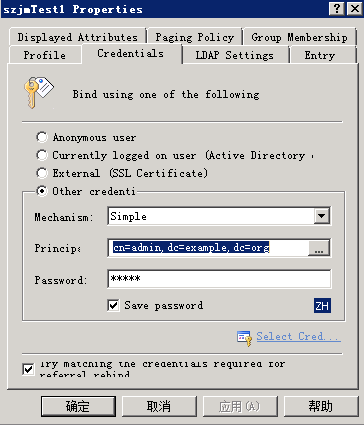
(3)填写域账号和密码
Mechanism:Simple ;Princip: cn=admin,dc=example,dc=org;Password: admin
(4)打开建立好的profile
导入ldif文件(LDIF(LDAP Data Interchanged Format)轻量级目录访问协议交换数据格式的简称,是存储LDAP配置信息及目录内容的标准文本文件格式,通常用来完成openldap数据的导入、导出、修改。)
|
dn: cn=admin456,dc=example,dc=org objectclass: inetOrgPerson objectclass: organizationalPerson objectclass: person objectclass: top cn: szjm1 uid: htjia1 description: htjia1 sn: jia1 givenname: haitian1 displayname: htjia1 mail: jhtchina1@163.com userpassword: 123123 |
保存文件名为: test111.ldif,拷贝文件到容器ldap的home目录下
|
docker cp test111.ldif ldap:/home/ |
在容器home目录下,导入test111.ldif文件
|
ldapadd -D "cn=admin,dc=example,dc=org" -w admin -f test111.ldif |
3.3.5 Git安装与使用
3.3.5.1 Git介绍
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
版本控制是一套系统,系统按照时间顺序记录某一个或一系列文件的变化,让用户可以查看以前特定的版本。
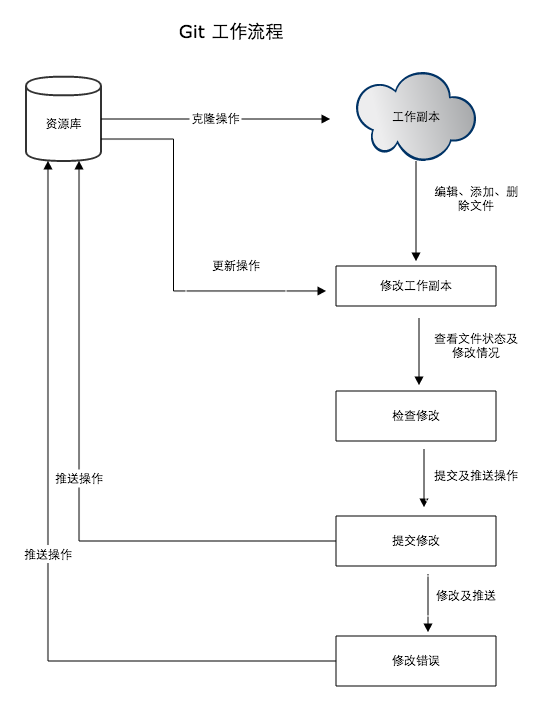
- Git 工作流程
Git工作流程如下:克隆 Git 资源作为工作目录;在克隆的资源上添加或修改文件;’
如果其他人修改了,你可以更新资源;在提交前查看修改;提交修改。
在修改完成后,如果发现错误,可以撤回提交并再次修改并提交。
工作流程如下图所示:
3.3.5.2 Git安装
Git服务端安装参看2.2.3 中的Docker部署gitlab-ce
Git客户端安装,Windows 下安装git客户端。https://gitforwindows.org/。
3.3.5.3 Git应用案例
git bash
查看git版本 : git version
设置用户名:git config --global user.name "jhtchina"
设置用户邮件:git config --global user.email 11804709@qq.com
查看git设置情况:git config –list
创建一个新的文件夹,在git bash中 执行: git init /*内部会生成.git文件夹*/
ls –a /*查看文件夹信息*/
cd .git /*转入.git目录*/
cat config /*查看config文件*/
/*从Git服务器上克隆项目 https://github.com/jhtchina/DataCenterplatform.git */
/*仓库数据下载到本地*/
git clone https://github.com/jhtchina/DataCenterplatform.git
cd DataCenterplatform/
echo 'I love you.'>test1.jsp
git add test1.jsp
git commit -m 'test1.jsp'
git status /*查看git本地仓库状态*/
git remote /*显示远程仓库 ,git remote -v */
/*显示远程仓库的信息 */
git remote show https://github.com/jhtchina/DataCenterplatform.git
/*本地仓库与远端仓库建立一个链接*/
git remote add DataCenterplatform https://github.com/jhtchina/DataCenterplatform.git
git fetch DataCenterplatform /*将远程主机的最新内容拉到本地*/
/* git 身份验证*/
git config --global user.name "jhtchina"
git config --global user.email 11804709@qq.com
git config --system --unset credential.helper
/*控制面板-用户账户-凭证管理器-普通凭证*/
/*数据推送到远程仓库*/
echo 'I love you.'>test1.jsp
git add test1.jsp
git status
git commit -m 'test1.jsp'
git remote
git push origin master /*本地版本库推送到远程服务器*/
/*删除文件到远程仓库*/
git rm test1.jsp
git status
git commit -m 'delete test1.jsp'
git push origin master

3.3.6 python Anaconda3安装与使用
3.3.6.1 python Anaconda3 介绍
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项;Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等;conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
3.3.6.2 python Anaconda3 安装
|
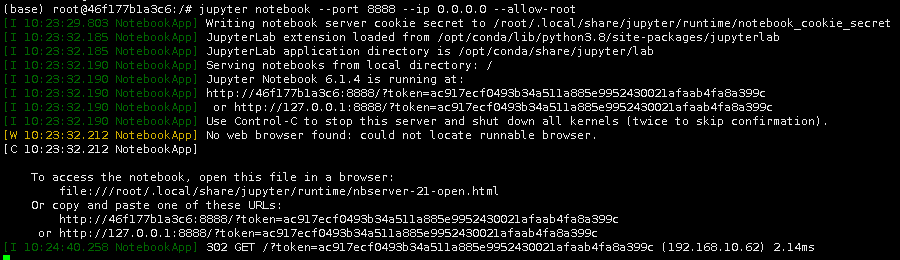
docker search anaconda /*搜索镜像*/ docker pull continuumio/anaconda3 /*拉取镜像*/ /*运行镜像,指定网络端口*/ docker run -i -t -p 1234:8888 continuumio/anaconda3 /bin/bash /*-i: 是 以交互模式运行容器,通常与 -t 同时使用; -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用; -p: 指定端口映射,格式为:主机(宿主)端口:容器端口*/ /*进入容器命令行,检查Python的版本,当前版本为Python 3.8.5*/ python conda list /*查看已经安装的库*/ pip list docker rename cc432d1f6b13 AnacondaEnvironment /*给anaconda镜像改名*/ docker start -i AnacondaEnvironment /*重新运行改名后的镜像*/ /*在该容器中运行jupyter notebook */ /*已经指定了宿主机的端口和容器的端口相互映射,其中: 宿主机的端口是:1234;容器的端口是:8888;在容器中启动 jupyter notebook*/ jupyter notebook --port 8888 --ip 0.0.0.0 --allow-root
/*把前面的127.0.0.1:8888(容器的ip和端口)改为宿主机的ip和8888映射到宿主机的端口1234 ;http://IP:1234/?token= token值; 在本地浏览器中打开*/
docker exec -it AnacondaEnvironment /bin/bash /*进入容器*/ jupyter notebook list /*在docker中查询jupyter notebook 的token*/ |
3.3.6.3 python Anaconda3 应用案例
- 读取文本文件
|
/*拷贝文件到容器*/ docker cp /home/test1.jsp AnacondaEnvironment:/home/ docker exec -it AnacondaEnvironment /bin/bash /*在Anaconda 读取/home/ test1.jsp文件*/ filename=r'/home/test1.jsp' f=open(filename,'r',encoding="gbk") for each_line in f: print(each_line) f.close() /*运行效果如下图所示*/
|

- 基于HyperLPR车牌识别
HyperLPR是一个基于深度学习的高性能中文车牌识别开源项目,地址是 https://github.com/zeusees/HyperLPR,由python语言编写,同时还支持Linux、Android、iOS、Windows等各主流平台。
|
import cv2 cv2.__version__ /*'3.4.8'版本*/ |
|
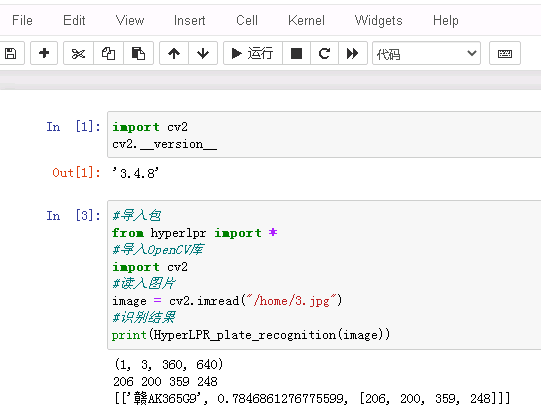
docker cp /home/4.jpg AnacondaEnvironment:/home/ docker exec -it AnacondaEnvironment /bin/bash /*容器里安装*/ pip3 uninstall opencv-contrib-python /*卸载opencv-contrib-python */ pip3 uninstall opencv-python pip3 install opencv-python==3.4.8.29 /*安装指定版本的opencv*/ pip3 install opencv-contrib-python==3.4.8.29 /**/ python -m pip install --upgrade pip pip install hyperlpr /*安装hyperlpr */ apt update apt install libgl1-mesa-glx apt-get update apt-get install -y libgl1-mesa-dev /*在Anaconda 编写代码*/ #导入包 from hyperlpr import * #导入OpenCV库 import cv2 #读入图片 image = cv2.imread("/home/4.jpg") #识别结果 print(HyperLPR_plate_recognition(image))
|

实验案例
3.3.1 mysql和python数据操作
3.3.1.1 安装mysql,python环境
MySQL安装本书第二章2.2.3中的(3)Docker 下安装Mysql数据库已经做描述,python环境搭建在本书3.3.6 python Anaconda3安装与使用已经做了描述。
3.3.1.2 PyMySQL 安装
PyMySQL 是一个纯 Python 实现的 MySQL 客户端库,支持兼容 Python 3,用于代替 MySQLdb。安装如下:
|
pip3 install PyMySQL |
3.3.1.3 数据库连接
连接数据库前,请先确认以下事项:
- Mysql创建了数据库 TESTDB;
- 在TESTDB数据库中您已经创建了表 EMPLOYEE;
EMPLOYEE表字段为 FIRST_NAME, LAST_NAME, AGE, SEX 和 INCOME;
- 连接数据库TESTDB使用的用户名为 "root" ,密码为 "123456";
- python Anaconda3已经安装了 Python MySQLdb 模块;
|
import pymysql # 打开数据库连接 conn = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) cursor = conn.cursor() #使用 cursor() 方法创建一个游标对象 cursor cursor.execute("SELECT VERSION()") # 使用 execute() 方法执行 SQL 查询 data = cursor.fetchone() # 使用 fetchone() 方法获取单条数据. print ("Database version : %s " % data) conn.close() # 关闭数据库连接 |
执行以上脚本输出结果如下:
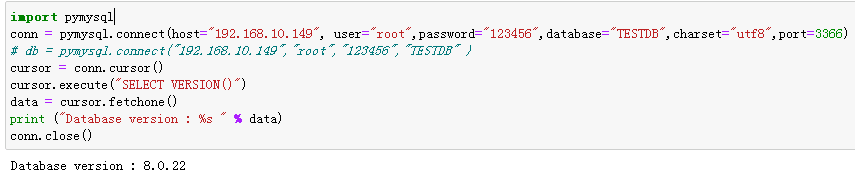
db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366)
/*db = pymysql.connect(host=“数据库地址”, user=“用户名”,password=“密码”,database=“数据库名”,charset=“编码”, port=端口号)/*
3.3.1.4 创建数据库表
execute()方法来为数据库创建表,创建表EMPLOYEE:
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 使用 execute() 方法执行 SQL,如果表存在则删除 cursor.execute("DROP TABLE IF EXISTS EMPLOYEE") # 使用预处理语句创建表 sql = """CREATE TABLE EMPLOYEE ( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT )""" cursor.execute(sql) # 关闭数据库连接 db.close() |
3.3.1.5 数据表插入操作
使用执行 SQL INSERT 语句向表 EMPLOYEE 插入记录:
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 插入语句 sql = """INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES ('Mac', 'Mohan', 20, 'M', 2000)""" try: # 执行sql语句 cursor.execute(sql) # 提交到数据库执行 db.commit() except: # 如果发生错误则回滚 db.rollback() # 关闭数据库连接 db.close() |
也可以写成如下形式(以参数形式传递):
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 插入语句 sql = "INSERT INTO EMPLOYEE(FIRST_NAME, \ LAST_NAME, AGE, SEX, INCOME) \ VALUES ('%s', '%s', %s, '%s', %s)" % \ ('MacNew', 'MohanNew', 200, 'M', 200) try: # 执行sql语句 cursor.execute(sql) # 执行sql语句 db.commit() except: # 发生错误时回滚 db.rollback() # 关闭数据库连接 db.close() |
以下代码使用变量向SQL语句中传递参数:
|
user_id = "test123" password = "password" con.execute('insert into Login values( %s, %s)' % \ (user_id, password)) |
3.3.1.6 数据表查询操作
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用fetchall() 方法获取多条数据。
- fetchone(): 该方法获取下一个查询结果集。结果集是一个对象
- fetchall(): 接收全部的返回结果行.
- rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
查询EMPLOYEE表中salary(工资)字段大于1000的所有数据:
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 查询语句 sql = "SELECT * FROM EMPLOYEE \ WHERE INCOME > %s" % (1000) try: # 执行SQL语句 cursor.execute(sql) # 获取所有记录列表 results = cursor.fetchall() for row in results: fname = row[0] lname = row[1] age = row[2] sex = row[3] income = row[4] # 打印结果 print ("fname=%s,lname=%s,age=%s,sex=%s,income=%s" % \ (fname, lname, age, sex, income )) except: print ("Error: unable to fetch data") # 关闭数据库连接 db.close() |
3.3.1.7 数据表更新操作
更新操作用于更新数据表的的数据,以下实例将 TESTDB 表中 SEX 为 'M' 的 AGE 字段递增 1:
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 更新语句 sql = "UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = '%c'" % ('M') try: # 执行SQL语句 cursor.execute(sql) # 提交到数据库执行 db.commit() except: # 发生错误时回滚 db.rollback() # 关闭数据库连接 db.close() |
3.3.1.8 删除操作
删除操作用于删除数据表中的数据,以下实例演示了删除数据表 EMPLOYEE 中 AGE 大于 20 的所有数据:
|
#!/usr/bin/python3 import pymysql # 打开数据库连接 db = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 使用cursor()方法获取操作游标 cursor = db.cursor() # SQL 删除语句 sql = "DELETE FROM EMPLOYEE WHERE AGE > %s" % (20) try: # 执行SQL语句 cursor.execute(sql) # 提交修改 db.commit() except: # 发生错误时回滚 db.rollback() # 关闭连接 db.close() |
3.3.1.9 执行事务
事务机制可以确保数据一致性。事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
先创建一个交易表,方便测试 pymysql 的功能:
|
DROP TABLE IF EXISTS `trade`; CREATE TABLE `trade` ( `id` int(4) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(6) NOT NULL COMMENT '用户真实姓名', `account` varchar(11) NOT NULL COMMENT '银行储蓄账号', `saving` decimal(8,2) unsigned NOT NULL DEFAULT '0.00' COMMENT '账户储蓄金额', `expend` decimal(8,2) unsigned NOT NULL DEFAULT '0.00' COMMENT '账户支出总计', `income` decimal(8,2) unsigned NOT NULL DEFAULT '0.00' COMMENT '账户收入总计', PRIMARY KEY (`id`), UNIQUE KEY `name_UNIQUE` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; INSERT INTO `trade` VALUES (1,'Jobs','123456456',0.00,0.00,0.00); |
使用Python脚本实现增删改查和事务处理,源码如下:
|
import pymysql.cursors # 连接数据库 connect = pymysql.connect(host="192.168.10.149", user="root",password="123456",database="TESTDB",charset="utf8",port=3366) # 获取游标 cursor = connect.cursor() # 插入数据 sql = "INSERT INTO trade (name, account, saving) VALUES ( '%s', '%s', %.2f )" data = ('张三', '12564963258', 10000) cursor.execute(sql % data) connect.commit() print('成功插入', cursor.rowcount, '条数据') # 修改数据 sql = "UPDATE trade SET saving = %.2f WHERE account = '%s' " data = (8888, '12564963258') cursor.execute(sql % data) connect.commit() print('成功修改', cursor.rowcount, '条数据') # 查询数据 sql = "SELECT name,saving FROM trade WHERE account = '%s' " data = ('12564963258',) cursor.execute(sql % data) for row in cursor.fetchall(): print("Name:%s\tSaving:%.2f" % row) print('共查找出', cursor.rowcount, '条数据') # 删除数据 sql = "DELETE FROM trade WHERE account = '%s' LIMIT %d" data = ('12564963258', 1) cursor.execute(sql % data) connect.commit() print('成功删除', cursor.rowcount, '条数据') # 事务处理 sql_1 = "UPDATE trade SET saving = saving + 1000 WHERE account = '12564963258' " sql_2 = "UPDATE trade SET expend = expend + 1000 WHERE account = '12564963258' " sql_3 = "UPDATE trade SET income = income + 2000 WHERE account = '12564963258' " try: cursor.execute(sql_1) # 储蓄增加1000 cursor.execute(sql_2) # 支出增加1000 cursor.execute(sql_3) # 收入增加2000 except Exception as e: connect.rollback() # 事务回滚 print('事务处理失败', e) else: connect.commit() # 事务提交 print('事务处理成功', cursor.rowcount) # 关闭连接 cursor.close() connect.close() |
3.1.1.10 redis与mysql数据同步
3.4 本章小结
本章主要介绍了智慧校园开发平台架构数据库等技术问题,数据库部分包括关系型数据库和非关系型数据库;应用服务并发分布式架构,其中主要介绍了tomcat、nginx、ftp,LDAP,Git,python 等智慧校园开发中常见的技术。最后的实验案例主要介绍了python操作mysql数据的案例教程。通过本章学习可以加深读者对智慧校园开发平台架构数据库有更一步的了解,为后面章节的学习打下一个更好的技术。
3.5 本章参考
https://dev.mysql.com/doc/refman/8.0/en/database-use.html
https://www.cnblogs.com/rmbteam/archive/2011/10/20/2219368.html
https://www.cnblogs.com/it-tsz/p/10206786.html
https://github.com/nouchka/docker-sqlite3
https://www.cnblogs.com/hankkk/p/5782321.html
https://www.cnblogs.com/mingfan/p/12332506.html
https://www.cnblogs.com/kungfupanda/p/12630198.html
https://blog.csdn.net/weixin_43453386/article/details/85065043
https://blog.csdn.net/Coder_Boy_/article/details/110950347?utm_source=app
https://www.cnblogs.com/duanxz/p/10730096.html
https://www.runoob.com/redis/redis-tutorial.html
https://www.cnblogs.com/gkl123/p/9746246.html
https://www.cnblogs.com/dhjy123/p/13390929.html
https://www.cnblogs.com/alimayun/p/10604532.html
https://blog.csdn.net/weixin_40461281/article/details/92586378
https://www.cnblogs.com/lichmama/p/11366262.html
https://blog.csdn.net/Smile_Sunny521/article/details/89552331
https://www.cnblogs.com/jake-jin/p/12713324.html
https://blog.csdn.net/java_zyq/article/details/90041267
https://www.cnblogs.com/davion2017/p/13172099.html
https://blog.csdn.net/qq_36154886/article/details/108789315
https://blog.csdn.net/zhenliang8/article/details/78330658
https://blog.csdn.net/iw1210/article/details/86549599
https://www.cnblogs.com/hcfan/p/11275174.html
https://www.cnblogs.com/eoalfj/p/11837415.html
https://blog.csdn.net/weixin_38637595/article/details/89817940
https://blog.csdn.net/gray13/article/details/7228737
https://blog.csdn.net/jbgtwang/article/details/38902435
https://blog.csdn.net/z2011415107/article/details/107709285
https://www.runoob.com/git/git-tutorial.html
https://www.cnblogs.com/panwenbin-logs/p/8149772.html
https://blog.csdn.net/weixin_43815140/article/details/106087232
https://blog.csdn.net/qq_27469517/article/details/100928433
https://blog.csdn.net/yang1159/article/details/89492368
https://www.cnblogs.com/prefertea/p/13448414.html
https://huchenyang.net/py/80.html
https://www.runoob.com/python3/python3-mysql.html
https://www.cnblogs.com/xfxing/p/9322199.html
https://www.cnblogs.com/woider/p/5926744.html
https://www.cnblogs.com/yblackd/p/12242005.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号