容器技术
二 容器技术
2.1 基础设施层选型
智慧校园基础设施层提供基础设施保障,异构通信网络、广泛的物联和海量的数据汇集存储,为智慧校园的各种应用提供基础支持,为大数据挖掘、分析提供数据支撑。基础设施层主要包括信息化基础设施、数据库与服务器等。本章主要介绍基础设施和服务器。
2.1.1 基于软件定义基础层的平台概述
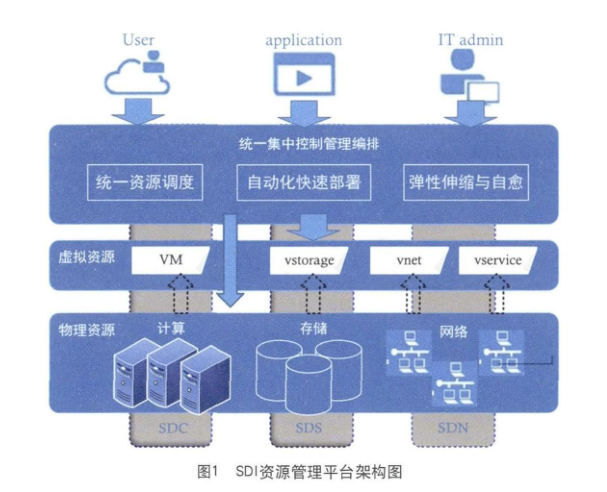
软件定义基础设施(Software Defined Infrastructure,SDI)包含四个方面的内容,即计算、存储、网络和安全;软件定义基础设施构建的数据中心是动态、高度自动化和软件定义的。学校可以根据应用需求分配一个合适的、灵活的系统,可以更快地进行部署,更好地进行管理,满足扩展的需要。基于软件定义基础设施的数据中心平台融合了云计算、软件定义网络等技术,将离散异构资源变为统一的资源池,集中管理所有软硬件资源、异构虚拟化基础设施,将传统以硬件为核心的数据中心的基础设施与服务解耦,能够对这些资源自动发现、自动配置、统一调度和快速部署,快速响应学校的变化需求。同时,该平台提供相关开放接口,以便响应来自服务的请求,对基础设施业务流程和服务进行实时编排调整。其基础架构图如图1所示。
SDI 软件定义基础设施实现统一资源调度,资源调度实现软硬件资源统一管理、精确量化、共享利用,充分发挥资源效率;可实现多中心融合统一集约化管理,降低运营成本;其次实现自动化快速部署,简化各种复杂的人工操作,避免各种低级的配置错误,提升业务效率,缩短学校新增业务上线的时间周期,而且随着运行效率的显著提高,成本也不断降低;另外软件定义基础设施资源管理平台支持资源的弹性扩展、收缩和自愈。通过持续监控各种资源的当前状态,并对这些海量数据进行存储、智能化分析、推断、感知、预测,做出正确的决策,合理优化资源配置。
2.1.2 基础设施层基本建设目标
基础设施层建设目标是满足智慧校园需求对外提供云主机、云存储、虚拟网络、大数据、人工智能、高性能计算、安全防护等云计算服务的需求。主要内容包括平台门户、支撑系统、云计算服务、高性能服务、大数据服务、人工智能服务、安全服务、开发测试云等。
2.1.3 云平台系统
开源云平台系统主要有Openstack 、Docker、Kubernetes 。
OpenStack作为一个开源的云计算平台,利用虚拟化技术和底层存储服务,提供了可扩展,灵活,适应性强的云计算服务。Openstack核心功能有计算组件、对象存储组件、身份认证组件、块存储组件、网络组件、镜像服务组件、仪表盘组件组成。
Docker 是一个开源的应用容器引擎,Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
Kubernetes是容器管理编排引擎,那么底层实现自然是容器技术。容器是一种轻量级、可移植、自包含的软件打包技术,打包的应用程序可以在几乎任何地方以相同的方式运行。
OpenStack和Docker比较
|
类别 |
Docker |
OpenStack |
|
应用平台 |
Paas |
Iaas |
|
部署难度 |
简单 |
复杂 |
|
执行性能 |
和物理性能几乎一致 |
KVM虚拟机会占用资源 |
|
镜像体积 |
MB |
GB |
|
管理效率 |
简单 |
复杂 |
|
隔离性能 |
较高 |
彻底隔离 |
|
可管理性 |
单进程 |
较弱 |
|
网络连接 |
较弱 |
Neutron灵活组件网络 |
|
启动速度 |
极快 |
稍慢 |
OpenStack 采用的是虚拟机虚拟化技术,Docker采用的是容器化技术。
容器时在linux上本机运行,并与其他容器共享主机的内核,它运行的一个独立的进程,不占用其他任何可执行文件的内存,非常轻量。
虚拟机运行的是一个完成的操作系统,通过虚拟机管理程序对主机资源进行虚拟访问,相比之下需要的资源更多。

Kubernetes和Docker比较
建于Docker之上的Kubernetes可以构建一个容器的调度服务,其目的是让用户透过Kubernetes集群来进行云端容器集群的管理,而无需用户进行复杂的设置工作。系统会自动选取合适的工作节点来执行具体的容器集群调度处理工作。
2.1.4 云平台架构分析
云平台架构方面包括底层集群架构、存储架构、网络架构三个方面。
底层集群架构应该具有支持管理集群(含多个管理节点)和资源池集群(含计算、存储、网络节点)分离部署,云平台管理软件单独部署于管理集群中,保证整体安全性和运行稳定性;支持分离部署,资源池集群中计算节点、网络节点、存储节点支持分离部署于每台物理服务器上。支持通过 X86 服务器本地硬盘构建分布式存储系统;支持定义多个资源池集群,每个资源池集群可以拥有独立的服务器、存储、网络配置和虚拟化类型,形成一个独立的资源池,池内所有服务器对等,可以启用集群高可用及资源调度。
存储架构基本要求包括虚拟化平台使用存储设备时,须采用和计算节点分离部署的分布式存储设备。通过服务器本地硬盘构建分布式存储系统。支持这些存储资源的添加、删除、查询、扫描;通过 X86 服务器本地硬盘构建分布式存储系统,支持通过增加物理服务器节点的方式扩展存储资源池。比较著名的存储架构有Ceph分布式文件系统。
网络架构要求包括云平台支持将网络按云平台系统内部管理、业务、存储、安全(审计)划分为不同网络平面;支持通过 SDN 软件定义技术创建虚拟私有二层网络,虚拟私有二层网络间在必须在二层 100%隔离;支持 NFV 网络功能虚拟化,包括但不限于虚拟防火墙、虚拟路由器等网络功能。支持分布式网络控制器,确保任意管理控制节点出现故障,网络完全可以照常工作。OpenvSwitch 是一个高质量的、多层虚拟交换机技术。
本章主要介绍Docker和Kubernetes。Docker是一个开源的应用容器引擎,开发者可以打包他们的应用及依赖到一个可移植的容器中,发布到流行的Linux机器上,也可实现虚拟化。k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
2.2 Docker 应用容器引擎
2.2.1容器化的支撑平台层建设
容器技术是一种轻量级的虚拟化技术。容器有效地将独立的操作系统管理的资源划分到指定的区域,更好的在孤立区域之间平衡有冲突的资源使用需求。
支撑平台具有特性一:轻量级。容器的思想就是把单独的进程进行封装。这样做就使得容器内的进程所运行的环境与其他任何操作系统相独立。
容器特性二:独立性。容器技术通过独立的命名空间,保证了其运行的独立性。实现了对内存、CPU、网络 IO、存储空间、文件系统等的相互隔离,所以通过容器运行应用软件,能够使得应用程序与操作系统实现极低的耦合,其使用内核是通过封装的接口,实现了与操作系统的解耦合。
容器特性三:虚拟化。通过容器技术来构建应用虚拟化,容器启动都在本地,是同构本地应用虚拟化。
容器技术在开发部署运维方面的优势,容器本身的开发、发布和运行应用程序的开放平台属性使得它能够将应用程序与基础设施分离,以便能够快速交付软件。
2.2.2 docker容器技术基础
Docker容器技术包含三个主要的概念。(1)镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 centos 就包含了完整的一套 centos 最小系统的 root 文件系统。(2) 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。(3) 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
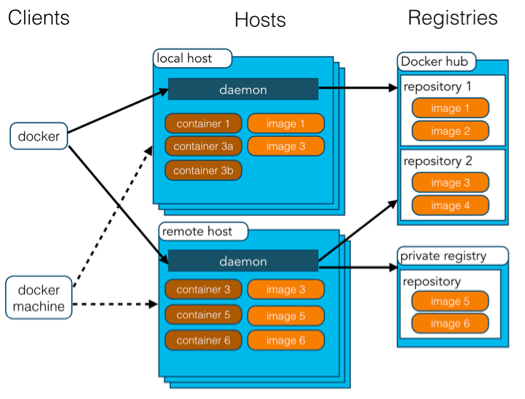
Docker主要概念
- Docker 镜像(Images) : Docker 镜像是用于创建 Docker 容器的模板,比如 Centos 系统。
- Docker 容器(Container): 容器是独立运行的一个或一组应用,是镜像运行时的实体。
- Docker 主机(Host): 一个物理或者虚拟的机器用于执行 Docker 守护进程和容器,也可以称为Docker宿主机。
- Docker Registry: Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。
- Docker Machine: Docker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker。
Centos7下的Docker 安装
- 通过 uname -r 命令查看你当前的内核版本
uname –r
- 使用 root 权限登录 Centos。确保 yum 包更新到最新。
sudo yum update
- 卸载旧版本(如果安装过旧版本的话)
sudo yum remove docker docker-common docker-selinux docker-engine
- 安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
- 设置yum源(阿里源)
sudo yum-config-manager --add-repo
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 可以查看所有仓库中所有docker版本,并选择特定版本安装
yum list docker-ce --showduplicates | sort –r
- 安装docker
sudo yum install docker-ce
- 启动并加入开机启动
sudo systemctl start docker
sudo systemctl enable docker
- ntp同步时间
yum install -y ntpdate
ntpdate time.windows.com
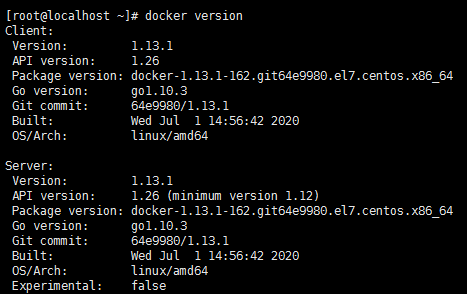
- 安装成功,查看Docker版本
docker version
阿里云的镜像仓库https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
[root@VM_0_13_centos ~]# cat /etc/docker/daemon.json

Docker版本查看
1.启动docker,命令:systemctl start docker
2.验证docker是否启动成功,命令:dockers version
3.重启docker,命令:systemctl restart docker
4.关闭docker,命令:systemctl stop docker END
2.2.3 Docker基础用法
本书所有实例为Centos7下的Docker容器运行。
(1) Docker Hello World
docker search hello-world /*查看仓库是否有hello-world 镜像*/
docker pull hello-world /*从仓库获取hello-world镜像到本地*/
docker images /*查看docker 镜像*/
docker inspect hello-world /*获取镜像 hello-world 的元数据*/
docker run hello-world /*运行hello-world镜像为容器*/

docker rm -f <CONTAINER ID> /*删除容器*/
docker rmi docker.io/hello-world /*删除hello-world镜像*/
(2) Docker 下安装Centos
docker search centos /*查看仓库中Centos镜像*/
docker pull centos /*从镜像仓库中拉取Centos镜像*/
docker run -itd --name centostest1 centos /*运行镜像为centos的容器,容器名称为centostest1 -i: 以交互模式运行容器,通常与 -t 同时使用;-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;-d: 后台运行容器,并返回容器ID;*/
docker ps /*查看容器的运行信息*/
docker exec -it centostest1 /bin/bash /*进入centostest1容器*/
exit /*退出centostest1 容器*/
docker inspect centostest1 /*获取容器centostest1 的元数据*/
docker export centostest1 >centostest1.tar /*导出容器快照到本地文件*/
docker rm -f centostest1 /*删除容器centostest1 */
cat centostest1.tar | docker import - centostest1 /*从容器快照文件中再导入为镜像*/
docker images /*查看镜像centostest1 是否存在*/
docker run -itd --name centostest1-test centostest1 /bin/bash /*运行centostest1 镜像为容器centostest1-test */
docker exec -it centostest1-test /bin/bash /*进入*/
exit /*退出centostest1-test容器*/
docker inspect centostest1-test /*获取容器centostest1-test的元数据*/
docker rm -f centostest1-test /*删除容器centostest1-test */
(3) Docker 下安装Mysql数据库
[root@VM_0_13_centos ~]# docker search mysql /*查看仓库中Mysql镜像*/
[root@VM_0_13_centos ~]# docker pull mysql /*拉去Mysql镜像文件到本地*/
[root@VM_0_13_centos ~]# docker images /*查看本地镜像*/
[root@VM_0_13_centos ~]# docker run -itd --name mysql-jhtchina -p 3366:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
/*参数说明:-p 3366:3306:映射容器服务的 3306 端口到宿主机的 3366 端口,外部主机可以直接通过宿主机3366端口访问Mysql数据库。
MYSQL_ROOT_PASSWORD=123456:设置 MySQL 服务 root 用户的密码。
*/
[root@VM_0_13_centos ~]# docker exec -it mysql- jhtchina /bin/bash
root@d39df678a276:/# mysql -uroot –p
Enter password: /*输入密码123456*/
mysql> GRANT ALL ON *.* TO 'root'@'%'; /*授权*/
mysql> flush privileges; /*刷新授权*/
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; /*更新加密规则*/
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456'; /*更新root用户密码*/
(4) Docker 下安装Oracle数据库
阿里云容器服务,搜索用户公开镜像,可以找到helowin/oracle_11g服务
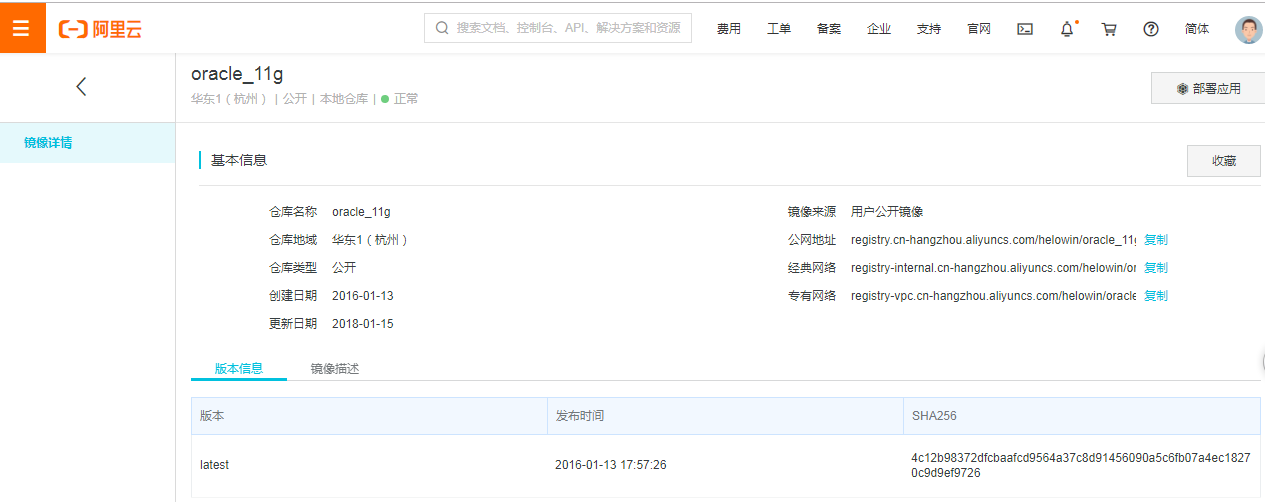
[root@VM_0_13_centos ~]# docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
/*拉取Oracle11g镜像,镜像文件大小为6.85GB*/
[root@VM_0_13_centos ~]# docker inspect 3fa112fd3642 /*查看镜像信息*/
[root@VM_0_13_centos ~]# docker run -d -p 1555:1521 --name oracle11g registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
/*创建容器,容器名称为oracle11g,宿主机端口为1555映射容器1521端口
docker start oracle11g 启动容器*/
[root@VM_0_13_centos ~]# docker exec -it oracle11g bash /*进入容器*/
[oracle@522e3a5ff104 /]$ su root/*切换到root用户,用户名:root 密码:helowin*/
[root@522e3a5ff104 /]# vi /etc/profile /修改profile文件/
在文件末未添加
export ORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_2
export ORACLE_SID=helowin
export PATH=$ORACLE_HOME/bin:$PATH
[root@522e3a5ff104 /]# ln -s $ORACLE_HOME/bin/sqlplus /usr/bin /*创建软链接*/
[root@522e3a5ff104 /]# su – oracle /*切换到oracle用户,密码oracle*/
[oracle@522e3a5ff104 ~]$ sqlplus /nolog /*连接数据库*/
执行一下命令
SQL> conn / as sysdba
SQL> alter user system identified by system;
SQL> alter user sys identified by sys;
SQL> create user jhtchina_oracle identified by jhtchina_oracle ;
SQL> grant connect,resource,dba to jhtchina_oracle ;
/*Oracle数据库启动与停止*/
su – oracle
sqlplus /nolog
SQL> conn / as sysdba
SQL> select instance_name from v$instance; /*查看实例名称*/
SQL> shutdown immediate /*立即关闭数据库*/
SQL> startup /*启动数据库实例*/
SQL> conn jhtchina_oracle/jhtchina_oracle /*用户连接数据库*/
完成数据库创建,与用户权限分配
Oracle监听状态查看:
查看状态命令:lsnrctl status
启动监听:lsnrctl start
关闭监听:lsnrctl stop
配置本地tnsnames.ora文件
|
TEST1= (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = IP地址)(PORT = 1555)) ) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = helowin) ) ) |
完成Oracle数据库安装与配置。
若是修改服务名为orcl,则需要以下脚本
https://blog.csdn.net/weixin_30652879/article/details/95628534
1检查当前oracle的数据库实例名:
su - oracle
echo $ORACLE_SID
sqlplus / as sysdba
select instance from v$thread;
2 关闭数据库
shutdown immediate
3 修改oracle用户的环境变量
vi /home/oracle/.bash_profile
export ORACLE_SID=orcl
4 修改/etc/oratab文件,修改sid
orcl:/u01/app/oracle/11.2/db_1:Y
5 进入$ORACLE_HOME目录,将所有文件名中含有旧sid的部分修改为新的sid
cd $ORACLE_HOME/dbs
mv hc_helowin.dat hc_orcl.dat
mv lkHELOWIN lkorcl
mv orapwhelowin orapworcl
mv spfilehelowin.ora spfileorcl.ora
6 重建口令文件
orapwd file=$ORACLE_HOME/dbs/orapw$ORACLE_SID password=jhtchina_oracle entries=5 force=y
7 重启服务器及数据库
8修改服务名
查看当前服务名:SQL> show parameter service_name
修改服务名:SQL> alter system set service_names=’orcl’ scope=both;
重启服务,生效
9 连接Oracle_SID数据库测试
conn jhtchina_oracle/jhtchina_oracle@localhost:1521/orcl
(5) Docker 下安装Sql Server数据库
[root@projectmanager ~]# sudo docker pull mcr.microsoft.com/mssql/server
/*拉取镜像*/
[root@projectmanager ~]# docker images /*查看镜像*/

[root@projectmanager /]# docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Szjm@123" -p 1433:1433 --name sql1 -h sql1 -d 5ced205176bc
/*其中ACCEPT_EULA=Y的意思是同意许可协议,必选;MSSQL_SA_PASSWORD为密码,要求是最少8位的强密码,要有大写字母,小写字母,数字以及特殊符号*/

/*连接到 SQL Server*/
[root@projectmanager /]# docker exec -it sql1 "bash"
/*在容器内部使用 sqlcmd 进行本地连接*/
mssql@sql1:/$ /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P "Szjm@123"
/*如果成功,应会显示 sqlcmd 命令提示符:1>。*/
/*创建和查询数据*/
/*
使用 sqlcmd 和 Transact-SQL 完成新建数据库、添加数据并运行查询的整个过程。
新建数据库、新建数据表、插入数据
在 sqlcmd 命令提示符中,粘贴以下 Transact-SQL 命令以创建测试数据库:
*/
|
1> CREATE DATABASE TestDB 2> go 1> SELECT Name from sys.Databases 2> go Name ------------------------------------- master tempdb model msdb TestDB (5 rows affected) 1> use TestDB 2> go |
|
1> use TestDB 2> go Changed database context to 'TestDB'. 1> CREATE TABLE Inventory (id INT, name NVARCHAR(50), quantity INT) 2> go 1> INSERT INTO Inventory VALUES (1, 'banana', 150); INSERT INTO Inventory VALUES (2, 'orange', 154); 2> go (1 rows affected) (1 rows affected) 1> SELECT * FROM Inventory WHERE quantity > 152; 2> go id name quantity ----------- -------------------------------------------------- ----------- 2 orange 154 (1 rows affected) 1> SELECT * FROM Inventory 2> go id name quantity ----------- -------------------------------------------------- ----------- 1 banana 150 2 orange 154 (2 rows affected) |
退出 sqlcmd 命令提示符,/*要结束 sqlcmd 会话, QUIT*/
|
1> quit |
Navicat Premium客户端连接
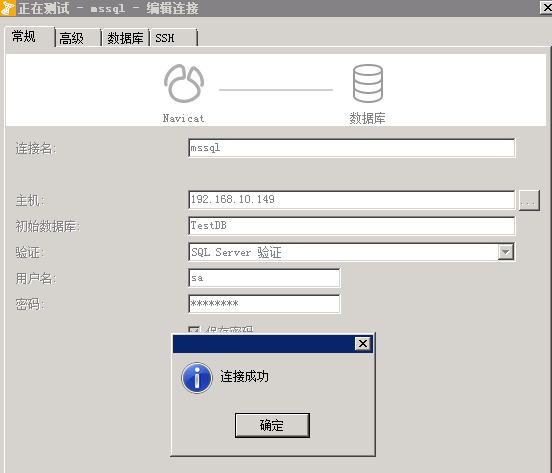
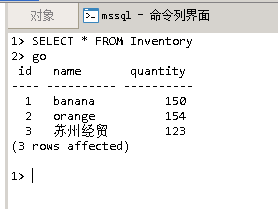
/*MsSQL数据库备份*/
|
BACKUP DATABASE [TestDB] TO DISK = N'/var/opt/mssql/data\TestDB.bak' WITH NAME = N'TestDB - Backup', NOFORMAT, NOINIT, SKIP, STATS = 5 |

微软官方网站给出<快速入门:使用 Docker 运行 SQL Server 容器映像>介绍
(6) Docker部署gitlab-ce
/*获取镜像*/
[root@projectmanager ~]# docker pull gitlab/gitlab-ce
/*
创建gitlab数据目录,在运行的时候需要把docker 容器当中的目录挂载到虚拟机当中*/
[root@projectmanager ~]# mkdir -p /docker/gitlab/config
[root@projectmanager ~]# mkdir -p /docker/gitlab/logs
[root@projectmanager ~]# mkdir -p /docker/gitlab/data
/*运行容器*/
docker run -d -p 8082:443 -p 8083:80 -p 8084:22 --name gitlab --restart always -v /docker/gitlab/config:/etc/gitlab -v /docker/gitlab/logs/var/log/gitlab -v /docker/gitlab/data:/var/opt/gitlab bddfecaf63e1
/* 参数说明
-p 容器内容的端口映射到虚拟机对应的端口
-d 后台运行
--name 容器名字--privileged=true 容器拥有root权限
-v 把虚拟机的目录挂载到镜像里
*/
/*配置gitlab*/
vi /docker/gitlab/config/gitlab.rb
|
#新增部分 配置http协议所使用的访问地址,不加端口号默认为80 external_url 'http://192.168.10.149' # 新增部分 配置ssh协议所使用的访问地址和端口 gitlab_rails['gitlab_ssh_host'] = '192.168.10.149' gitlab_rails['gitlab_shell_ssh_port'] = 8084 # 此端口是run时22端口映射的222端口 |
# 重启gitlab容器
docker restart gitlab
/*完成安装
第一次进入要输入新的root用户密码,设置好之后确定就行*/
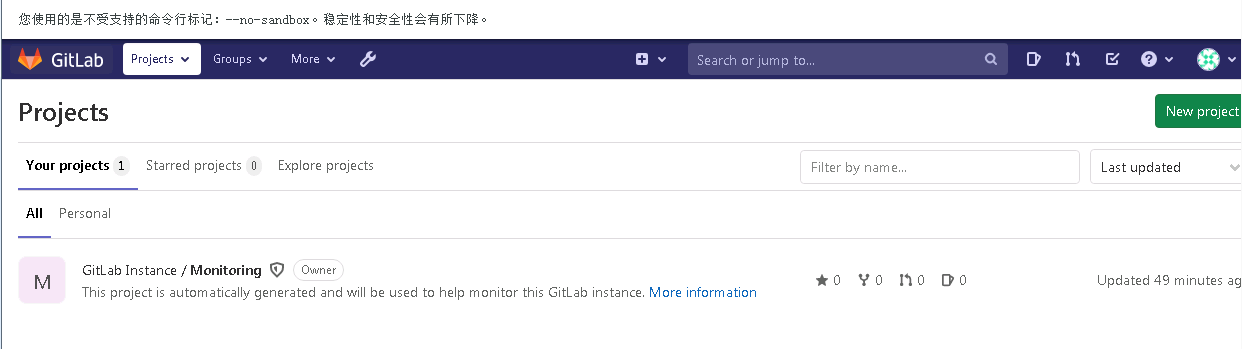
2.2.4 Docker镜像管理基础
当运行容器时,使用的镜像如果在本地中不存在,docker 就会自动从 docker 镜像仓库中下载,默认是从 Docker Hub 公共镜像源下载。
(1)使用 docker images 来列出本地主机上的镜像。
各个选项说明:
|
REPOSITORY |
TAG |
IMAGE ID |
CREATED |
SIZE |
|
镜像的仓库源 |
镜像的标签 |
镜像ID |
镜像创建时间 |
镜像大小 |
(2)查找镜像: docker search <镜像名称>

|
NAME |
DESCRIPTION |
OFFICIAL |
stars |
AUTOMATED |
|
镜像仓库源的名称 |
镜像的描述 |
是否 docker 官方发布 |
星级数量 |
自动构建 |
(3)获取一个新的镜像: docker pull <镜像名称或ID>
(4) 获取镜像元数据:docker inspect <镜像名称或ID>
(5)删除镜像: docker rmi <镜像名称或ID>
(6) 创建镜像
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。Dockerfile的基本指令有十三个,分别是:FROM、MAINTAINER、RUN、CMD、EXPOSE、ENV、ADD、COPY、ENTRYPOINT、VOLUME、WORKDIR等。
FROM:指明构建的新镜像是来自于哪个基础镜像;
MAINTAINER:指明镜像维护者及其联系方式;
RUN:执行什么命令;
CMD:指定一个容器启动时要运行的命令,Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,CMD 会被 docker run 之后的参数替换;
EXPOSE:声明容器运行的服务端口;
ENV:构建镜像过程中设置环境变量;
ADD:将宿主机上的目录或者文件拷贝到镜像中(会帮你自动解压,无需额外操作);
COPY:作用与ADD类似,但是不支持自动下载和解压;
ENTRYPOINT:指定一个容器启动时要运行的命令,用法类似于CMD,只是有由ENTRYPOINT启动的程序不会被docker run命令行指定的参数所覆盖,而且,这些命令行参数会被当作参数传递给ENTRYPOINT指定的程序;
VOLUME:容器数据卷,指定容器挂载点到宿主机自动生成的目录或者其他容器(数据保存和持久化工作,但是一般不会在 Dockerfile 中用到,更常见的还是命令 docker run 的时候指定 -v 数据卷。);
WORKDIR:相当于cd命令,切换目录路径;
构建Tomcat镜像实例:
mkdir docker_file /*创建docker_file目录*/
/*
复制一下2份文件到当前目录
jdk-8u91-linux-x64.tar.gz
apache-tomcat-8.5.16.tar.gz
*/
cd docker_file /*进入docker_file 目录*/
touch Dockerfile /*创建Dockerfile 文件*/
vi Dockerfile /*编辑并保存Dockerfile 文件*/
|
FROM centos:7 MAINTAINER this is tomcat ADD jdk-8u91-linux-x64.tar.gz /usr/local WORKDIR /usr/local RUN mv jdk1.8.0_91 /usr/local/java ENV JAVA_HOME /usr/local/java ##设置环境变量 ENV JAVA_BIN /usr/local/java/bin ENV JRE_HOME /usr/local/java/jre ENV PATH $PATH:/usr/local/java/bin:/usr/local/java/jre/bin ENV CLASSPATH /usr/local/java/jre/bin:/usr/local/java/lib:/usr/local/java/jre/lib/charsets.jar ADD apache-tomcat-8.5.16.tar.gz /usr/local WORKDIR /usr/local RUN mv apache-tomcat-8.5.16 /usr/local/tomcat8 EXPOSE 8080 ENTRYPOINT ["/usr/local/tomcat8/bin/catalina.sh","run"] |
docker build -t tomcatnew:centos . ##创建镜像
docker run --name tomcat1 -p 1234:8080 -it tomcatnew:centos /bin/bash #创建容器
2.2.5 Docker容器网络
Docker的本地网络实现其实就是利用了Linux上的网络命名空间和虚拟网络设备。Docker中的网络接口默认都是虚拟的接口。虚拟接口的优势是转发效率高。这是因为Linux通过在内核中进行数据复制来实现虚拟接口之间的数据转发,即发送接口的发送缓存中的数据包将被直接复制到接收接口的接收缓存中,而无需通过外部物理网络设备进行交换。Docker容器网络就利用了Linux虚拟网络技术,在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通。
docker网络模式在安装Docker时,会存在三个网络,bridge(容器创建时的默认网络)、 none 、host。还有以后一种自定义模式,自定义模式有三种:bridge、overlay、macvlan。
- host:容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
- None:该模式关闭了容器的网络功能。
- Bridge:此模式会为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及Iptables nat表配置与宿主机通信。
- Container:创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围。
通过docker network ls可以查看docker网络:

按照网桥bridge用法创建容器的时候,容器网络会执行操作如下:
- 创建一对虚拟接口,分别放到本地主机和新容器的命名空间中;
- 本地主机一端的虚拟接口连接到默认的docker0网桥或指定网桥上;
- 容器一端的虚拟接口将放到新创建的容器中,并修改名字作为eth0。这个接口只在容器的命名空间可见;
- 从网桥可用地址段中获取一个空闲地址分配给容器的eth0;
完成这些之后,容器就可以使用它所能看到的eth0虚拟网卡来连接其他容器和访问外部网络。用户也可以通过docker network命令来手动管理网络。物理主机为宿主机。
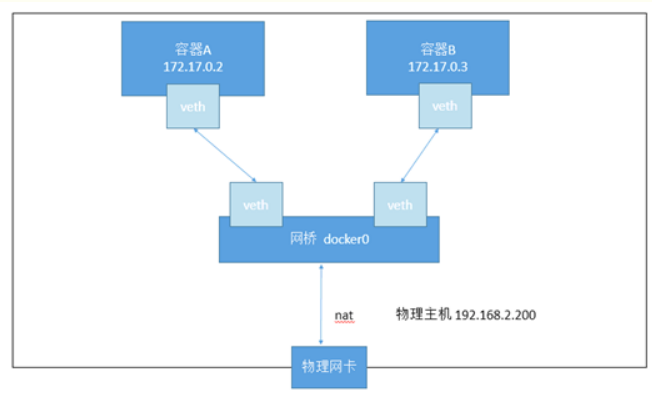
自定义bridge模式(https://www.cnblogs.com/whych/p/9595671.html)
- 创建network。
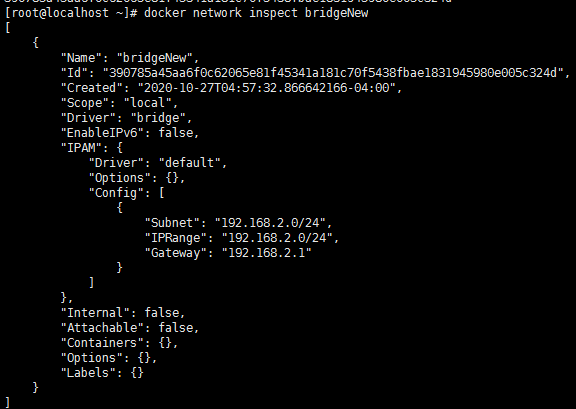
docker network create -d bridge --ip-range=192.168.2.0/24 --gateway=192.168.2.1 --subnet=192.168.2.0/24 bridgeNew
(2)查看bridgeNew网桥信息
(3)创建两个容器指定ip并指定network
docker run -itd --name b1 --network=bridgeNew --ip=192.168.2.3 --dns 114.114.114.114 busybox
docker run -itd --name b2 --network=bridgeNew --ip=192.168.2.4 --dns 114.114.114.114 busybox
docker run -itd --name b5 --network=bridgeNew --ip=192.168.2.5 --dns 114.114.114.114 busybox
--network=user_defined_network:用户用network相关命令创建一个网络,通过这种方式将容器连接到指定的已创建网络上去。
user_defined_network={ --net=bridge 、--net=none 、--net=containe 、--net=host }
容器b1,b2,b5和宿主机之间是互通的。
docker exec -it b1 /bin/sh /*进入容器b1*/
(4) 不同网段容器之间通信
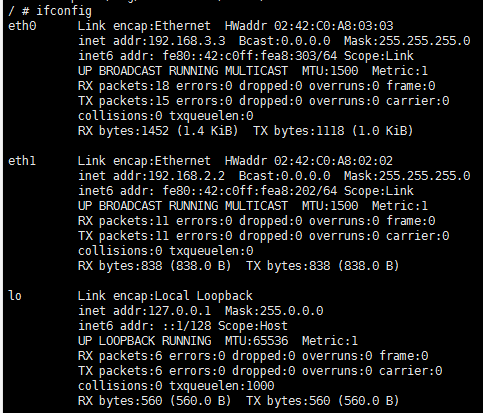
docker network create -d bridge --ip-range=192.168.3.0/24 --gateway=192.168.3.1 --subnet=192.168.3.0/24 bridgeNew1 /*创建新的网络bridgeNew1 */
docker run -itd --name b33 --network=bridgeNew1 --ip=192.168.3.3 --dns 114.114.114.114 busybox /*创建容器b33*/
容器b33和b3之间不能直接通信。
要让它们能够通信,可以执行如下代码为 b33 也添加一个 bridgeNew 网络。
docker network connect bridgeNew b33 /*连接网络*/
docker network disconnect bridgeNew b33 /*断开网络*/
再次查看下 b33 的网络配置,可以发现它除了 bridgeNew1 网络分配的 ip 外,还拥有 bridgeNew 网络的 ip。再次去 ping 第一个容器 b1 的地址会发现可以 ping 通了,说明两个容器可以 IP 通信了。
(5)通过 joined 容器通信
joined 容器特别,它可以使两个或多个容器共享一个网络栈,共享网卡和配置信息,joined 容器之间可以通过 127.0.0.1 直接通信。
joined 容器适合以下场景:
不同容器中的程序希望通过 loopback 高效快速地通信,比如 Web Server 与 App Server,希望监控其他容器的网络流量,比如运行在独立容器中的网络监控程序。
希望监控其它容器的网络流量,比如运行在独立容器中的网络监控程序。
例如:创建一个 busybox 容器并通过 --network=container:b5 指定 joined 容器为 b41:
docker run -itd --name b41 --network=container:b5 busybox
docker exec -it b41 /bin/sh /*进入容器b41*/
查看 b41 容器中的网络配置信息,可以发现它的 mac 地址和 IP 与web1 的完全一样。
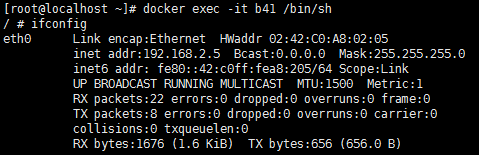
由于共享了相同的网络栈。b41可以直接用 127.0.0.1 访问 b5 的 http 服务。
(6)外部访问容器的实现
docker run --name jhtchinaNew -p 8099:80 -it busybox /bin/sh
/*创建容器jhtchinaNew ,容器端口80映射到宿主机端口8099*/
/ # ls /tmp /*查看tmp目录*/
/ # netstat –tnl /*显示网络监听*/
/ # echo 'hello world!'> /tmp/index.html /*写文件*/
/ # httpd -h /tmp/ /*启动httpd服务*/
/ # netstat -anlp | grep 80 /*检测开放80端口*/
tcp 0 0 :::80 :::* LISTEN 9/httpd
返回宿主机
curl http://172.17.0.2 /*宿主机访问容器 hello world! */
iptables -t nat -vnL|grep :8099
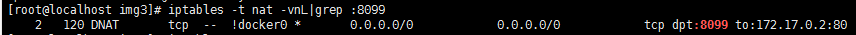
2.2.6 Docker存储卷
Docker关闭并重启容器,其数据不受影响;但删除Docker容器,则其更改将会全部丢失。由此存在如下问题:
- 存储在容器中的文件不易被宿主机访问;
- 容器件数据共享不方便;
- 删除容器会丢失数据;
如果容器中进程所生成的数据,都保存在存储卷上,从而脱离容器文件系统自身后,当容器被关闭甚至被删除时,都不用担心数据被丢失,实现数据可以脱离容器生命周期而持久,当再次重建容器时,如果可以让它使用到或者关联到同一个存储卷上时,再创建容器,虽然不是之前的容器,但是数据还是那个数据,特别类似于进程的运行逻辑,进程本身不保存任何的数据,数据都在进程之外的文件系统上,或者是专业的存储服务之上,所以进程每次停止,只是保存程序文件,对于容器也是一样;容器就是一个有生命周期的动态对象来使用,容器关闭就是容器删除的时候,但是它底层的镜像文件还是存在的,可以基于镜像再重新启动容器。
建立应用状态象限,第一象限中是那些有状态需要存储的,像mysql,redis等服务;有些有有状态但是无需进行存储的,像tomcat把会话保存在内存中时;无状态也无需要存储的数据,如各种反向代理服务器nginx,lvs请求连接都是当作一个独立的容器来调度,本地也不需要保存数据;第四象限是无状态,但是需要存储数据是比较少见。
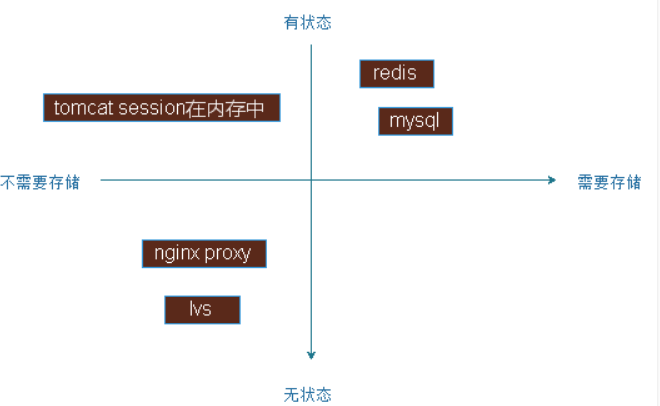
对于有状态的应用的数据,不使用存储卷,只能放在容器本地,效率比较低,而导致一个很严重问题就是无法迁移使用,而且随着容器生命周期的停止,还不能把它删除,只能等待下次再启动状态才可以,如果删除了数据就可能没了,因为它的可写层是随着容器的生命周期而存在的,所以只要持久存储数据,存储卷就是必需的。
Docker存储卷(Volume)目的是独立于容器生命周期实现数据持久化。
卷为docker提供了独立于容器的数据管理机制。
- 可以把“镜像”想像成静态文件,例如“程序”,把卷类比为动态内容,例如“数据”,于是,镜像可以重用,而卷可以共享。
- 卷实现了“程序(镜像)"和”数据(卷)“分离,以及”程序(镜像)“和"制作镜像的主机”分离,用记制作镜像时无须考虑镜像运行在容器所在的主机的环境。
Docker有两种类型的卷,每种类型都在容器中存在一个挂载点,但其在宿主机上位置有所不同。
- Bind mount volume(绑定挂载卷):在宿主机上的路径要人工的指定一个特定的路径,在容器中也需要指定一个特定的路径,两个已知的路径建立关联关系;
- Docker-managed volume(docker管理卷): 只需要在容器内指定容器的挂载点是什么,而被绑定宿主机下的那个目录,是由容器引擎daemon自行创建一个空的目录,或者使用一个已经存在的目录,与存储卷建立存储关系,这种方式解脱用户在使用卷时的耦合关系,缺陷是用户无法指定那些使用目录,临时存储比较适合;
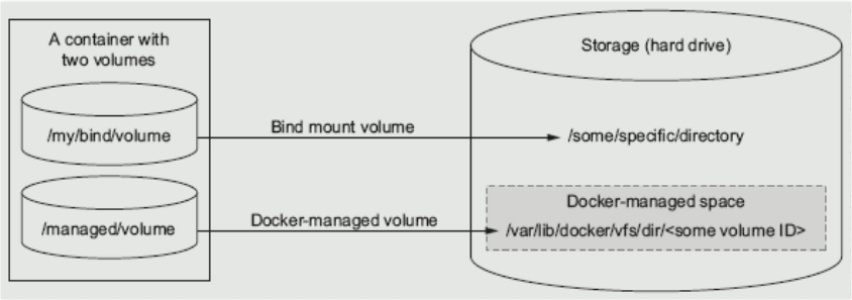
Docker使用存储卷
为docker run 命令使用-v 选项即可使用volume
- docker-managed volume
docker run -it -name rbox1 -v /data busybox /*data指定docker的目录*/
docker inspect -f {{.Mounts}} rbox1 /*查看rbox1容器的卷,卷标识符及挂载的主机目录*/
- bind-mount volume
docker run -it -v HOSTDIR:VOLUMEDIR --name rbox2 busybox
/*宿主机目录:容器目录*/
docker inspect -f {{.Mounts}} rbox2
(1)使用 docker-managed volume
- 创建容器VTest1
docker run --name VTest1 -it -v /data --rm busybox
注意:不要关闭此终端,另起一个终端进行一下操作;因为--rm 选项:一旦容器关闭,立即删除容器。
- 查询存储卷信息
docker inspect VTest1
- 因为inspect查询的结果是列表的形式、所以可以精确查询结果
docker inspect -f {{.Mounts}} VTest1

- 在宿主机的存储卷目录更新文件

- 在容器VTest1中查看,并在容器中更新存储卷中文件
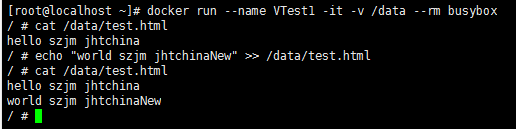
- 在宿主机上查看认证

(2)使用 docker mount volume
- 创建容器b2New
docker run --name b2New -it -v /data/volumes/b2:/data --privileged=true --rm busybox

注:如果设置存储卷的目录不存在,会自动创建
- 查询容器b2New存储卷信息
docker inspect -f {{.Mounts}} b2New

- 在宿主机的存储卷上进行简单操作
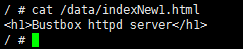
[root@localhost b2]# cd /data/volumes/b2/
[root@localhost b2]# echo "<h1>Bustbox httpd server</h1>" > indexNew1.html

- 在容器b2New中验证
/ # cat /data/indexNew1.html
<h1>Bustbox httpd server</h1>
- 删除容器b2New,再新创建容器b3New,修改存储卷路径,存储卷也不会改变,证明持久功能
docker run --name b3New -it -v /data/volumes/b2:/data/web/html --privileged=true --rm busybox

- 多个docker容器同时关联到同一个宿主机的目录中
实现共享使用同一个存储卷,容器之间的数据共享
(3) volumes-from 基于已有容器的存储器,创建容器
- 创建一个 volume1New容器
docker run --name volume1New -it --privileged=true -v /data/volume1New/:/data/web/html busybox
宿主机的存储卷可以查询
/ # cat /data/web/html/index.html
<h1>Bustbox httpd server</h1>
- 基基于volume1New的存储器,启动一个 nginx容器,两个容器指定IP地址和共享存储地址完全相同
docker run --name nginx --network container:volume1New --volumes-from volume1New -it --rm busybox:latest
/ # cat /data/web/html/index.html
<h1>Bustbox httpd server</h1> 
对nginx 这个容器来说,volume 的本质没变,它只是将volume1New容器的/data/web/html 目录映射的主机上的目录映射到自身的/data/web/html 目录。

2.2.7 OpenvSwitch(OVS)概述
Openvswitch是一款优秀的开源软件交换机,支持主流的交换机功能,比如二层交换、网络隔离、QoS、流量监控等,而其最大的特点就是支持openflow,openflow定义了灵活的数据包处理规范。
Openvswitch支持以下功能:
1. 支持标准802.1Q VLAN模块的Trunk和access端口模式;
2. QoS(Quality of Service)配置,及管理;
3. 支持OpenFlow协议;
4. 支持GRE它是点到点的隧道协议、VXLAN、STT和LISP隧道;
5. 具有C和Python接口配置数据库;
6. 支持内核态和用户态的转发引擎设置;
7. 支持流量控制及监控。
首先查看OpenvSwitch版本:ovs-vsctl show

Docker+openvswitch 可以实现在多台上的容器的互通。
2.3 kubernetes 容器管理平台
2.3.1 kubernetes架构概述
Kubernetes容器管理平台将底层的计算资源连接在一起对外体现为一个高可用的计算机集群。Kubernetes将资源高度抽象化,允许将容器化的应用程序部署到集群中。为了使用这种新的部署模型,需要将应用程序和使用环境一起打包成容器。容器化的应用程序更加灵活和可用,在新的部署模型中,应用程序被直接安装到特定的机器上,Kubernetes能够以更高效的方式在集群中实现容器的分发和调度运行。
k8s的集群至少有两个主机组成:master + node ,即为master/node架构,master为集群的控制面板,master主机需要做冗余,一般建议为3台,而node主机不需要,因为node的主要作用是运行pod,贡献计算能力和存储能力,而pod控制器会自动管控pod资源,如果资源少,pod控制器会自动创建pod,即pod控制器会严格按照用户指定的副本来管理pod的数量。客户端的请求下发给master,即把创建和启动容器的请求发给master,master中的调度器分析各node现有的资源状态,把请求调用到对应的node启动容器。
本书侧重与智慧校园技术框架搭建,主要介绍利用Kubernetes容器管理平台来实现智慧校园框架建设。
2.3.2 kubernetes基础概念
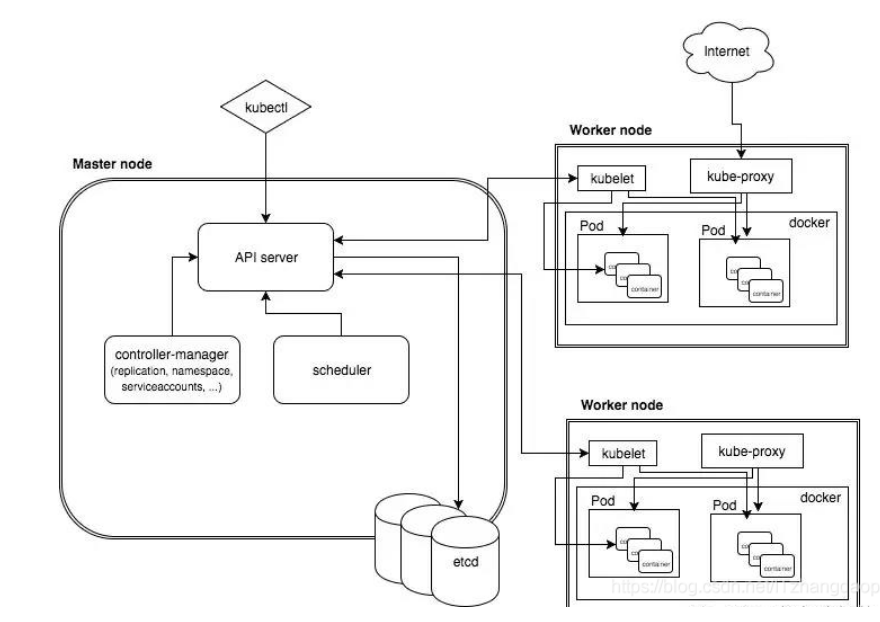
Kubernetes主要由以下几个核心组件组成:
etcd保存了整个集群的状态;
apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的Add-ons:
kube-dns负责为整个集群提供DNS服务
Ingress Controller为服务提供外网入口
Heapster提供资源监控
Dashboard提供GUI
Federation提供跨可用区的集群
Fluentd-elasticsearch提供集群日志采集、存储与查询;
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示
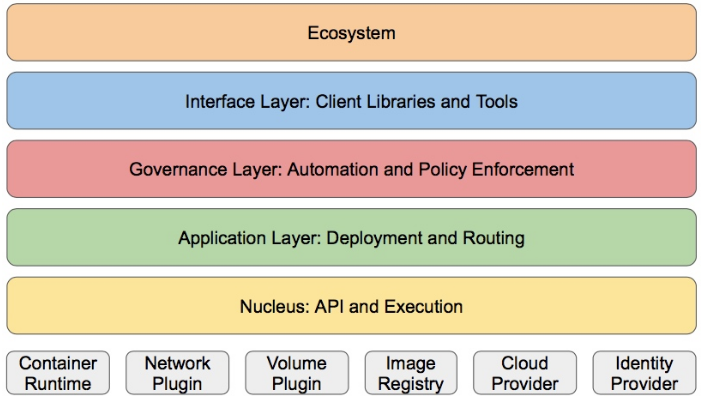
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
(1)Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
(2)Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
2.3.3 KubeSphere 产品介绍
由于Kubernetes安装维护比较复杂,为了更好的理解Kubernetes容器管理平台,本书将从KubeSphere入手,带你更好的理解容器管理架构。KubeSphere 是在 Kubernetes 之上构建的以应用为中心的企业级分布式容器平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大减轻开发、测试、运维的日常工作的复杂度,旨在解决 Kubernetes 本身存在的存储、网络、安全和易用性等痛点。除此之外,平台已经整合并优化了多个适用于容器场景的功能模块,以完整的解决方案帮助企业轻松应对敏捷开发与自动化运维、DevOps、微服务治理、灰度发布、多租户管理、工作负载和集群管理、监控告警、日志查询与收集、服务与网络、应用商店、镜像构建与镜像仓库管理和存储管理等多种业务场景。KubeSphere 从项目初始阶段就采用开源的方式来进行项目的良性发展,相关的项目源代码和文档都在 GitHub 可见。
(1)KubeSphere三节点安装
Master:主节点通常控制和管理整个KubeSphere平台。
Worker:工作节点通常运行部署在它们上的实际应用程序。
KubeKey:由于安装Kubernetes集群具有比较高的复杂性,从3.0.0版本开始,Kube Sphere使用了一个名为KubeKey的全新安装程序。 KubeKey使用Go语言开发,允许用户快速部署多节点架构。对于没有现有Kubernetes集群的用户,他们只需要创建一个配置文件,较少的命令,并添加节点信息(例如:IP地址和节点规则)。 在KubeKey下载后,IP地址和节点角色在其中。 使用一个命令,安装将开始,不需要额外的操作就可以完成KubeSphere集群的安装。本书安装KubeSphere3.0.0版本。
Step 1: 准备Linux主机
针对多集群安装,需要准备下图要求的硬件和操作系统,需要的最低配置如下图所示:
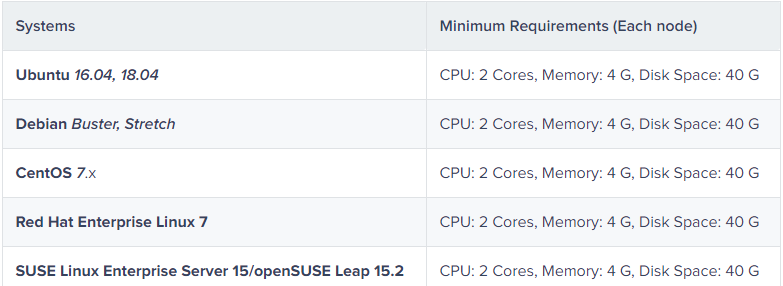
本书中3节点采用Centos7 操作系统,70G硬盘,2核4G内存。此示例包括三个主机,如下所示。
|
主机IP |
主机名 |
角色 |
|
192.168.10.141 |
master |
master, etcd |
|
192.168.10.142 |
Node1 |
worker |
|
192.168.10.143 |
Node2 |
worker |
永久关闭以上3个节点的防火墙。
systemctl status firewalld.service /*查看防火墙状态*/
systemctl stop firewalld.service /*关闭运行的防火墙*/
systemctl disable firewalld.service /*节点重启以后禁止防火墙服务器*/
设置DNS
vi /etc/resolv.conf
[root@master ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
Step 2: 3台主机实现ssh免密码登陆
[root@master ~]# ssh-keygen
生成之后会在用户的根目录生成一个 “.ssh”的文件夹,进入“.ssh”会生成以下几个文件
|
authorized_keys, id_rsa, id_rsa.pub, known_hosts |
authorized_keys:存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文件
know_hosts : 已知的主机公钥清单
远程免密登录原理:
- 客户端向服务器端发出连接请求
- 服务器端向客户端发出自己的公钥
- 客户端使用服务器端的公钥加密通讯密钥然后发给服务器端
- 如果通讯过程被截获,由于窃听者即使获知公钥和经过公钥加密的内容,但不拥有私 钥依然无法解密(RSA算法)
- 服务器端接收到密文后,用私钥解密,获知通讯密钥
通过ssh-copy-id的方式拷贝证书到node1和node2节点
|
[root@master ~]# ssh-copy-id -i root@192.168.10.142 [root@master ~]# ssh-copy-id -i root@192.168.10.143 |
验证:
|
[root@master ~]# ssh root@192.168.10.142 [root@master ~]# ssh root@192.168.10.143 |
Step 3:下载 KubeKey
|
wget https://github.com/kubesphere/kubekey/releases/download/v1.0.0/kubekey-v1.0.0-linux-amd64.tar.gz -O - | tar -xz |
Make kk executable:
|
chmod +x kk |
Step 4:创建一个集群
多节点安装,需要创建一个集群集群配置文件。在master节点下执行如下命令:
|
./kk create config --with-kubesphere v3.0.0 |
编辑配置文件config-sample.yaml
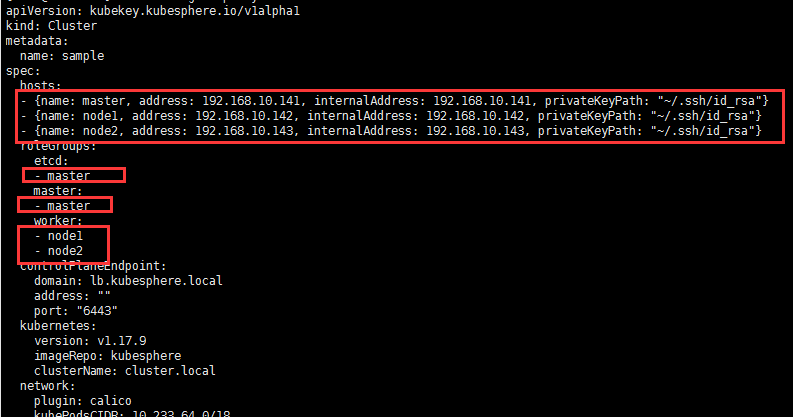
Hosts:集群中的主机列表,以及SSH免密码登录;
规则组:
etcd: etcd node names
master: Master node names
worker: Worker node names
用配置文件创建集群
|
./kk create cluster -f config-sample.yaml |
本条命令需要执行20-30分钟,主要依赖于你的机器和网络;
验证安装,当安装完成以后出现下图所示:
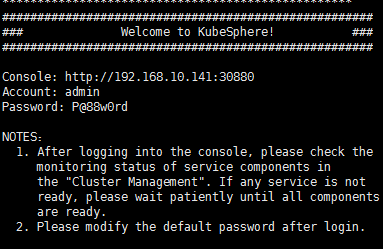
完成Web访问KubeSphere管理界面,http://{IP}:30880 ,账号和密码是admin/P@88w0rd
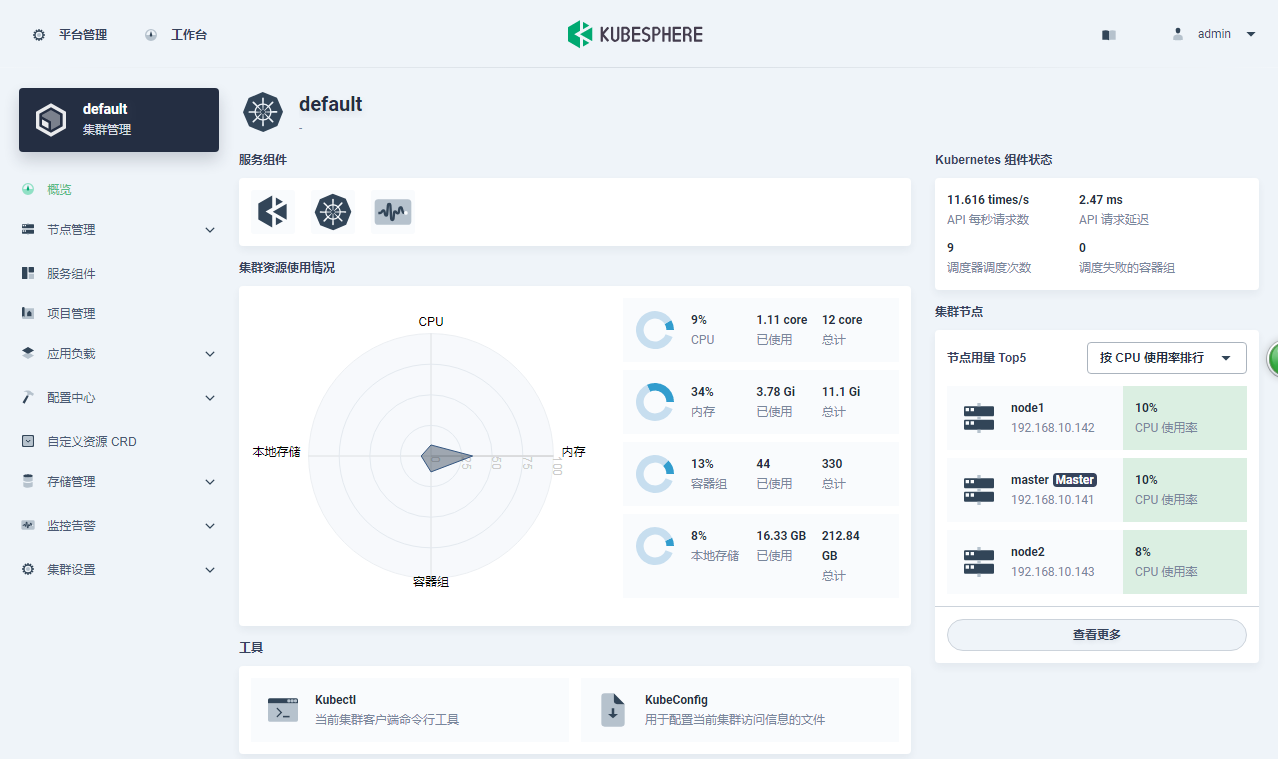
查看安装日志:
|
[root@master ~]# kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f |
Step 5:设置kubectl开机自启动
|
# Install bash-completion apt-get install bash-completion # Source the completion script in your ~/.bashrc file echo 'source <(kubectl completion bash)' >>~/.bashrc # Add the completion script to the /etc/bash_completion.d directory kubectl completion bash >/etc/bash_completion.d/kubectl |
kubectl是Kubernetes集群的命令行工具,通过kubectl能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。
2.3.4 KubeSphere应用快速入门
Kubernetes是容器管理平台, KubeSphere 是在 Kubernetes 之上构建的以应用为中心的企业级分布式容器平台,提供了丰富的界面操作功能。首先通过3个实例介绍KubeSphere下的管理操作,然后本书再深入介绍Kubernetes容器平台的相关概念,方便理解。
(1)KuberSphere多租户管理
目的:用户创建企业空间、创建新的角色和账户,然后邀请新用户进入企业空间后,创建项目和 DevOps 工程,帮助用户熟悉多租户下的用户和角色管理,快速上手 KubeSphere。
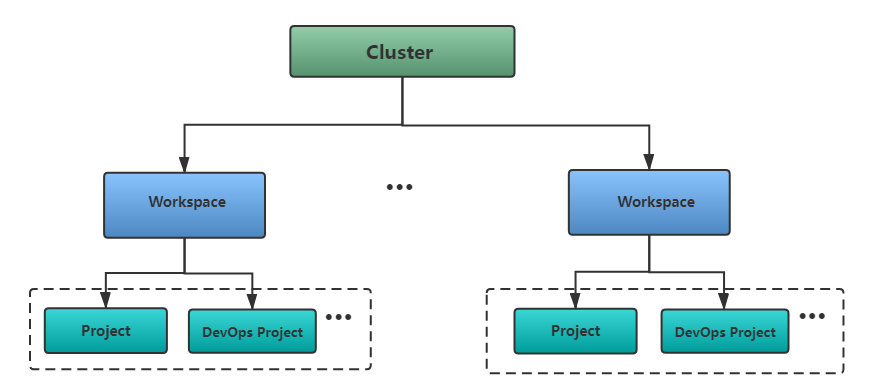
平台的资源一共有三个层级,包括集群 (Cluster)、 企业空间 (Workspace)、 项目 (Project) 和 DevOps Project (DevOps 工程),层级关系如下图所示,在每个层级中,每个组织中都有多个不同的内置角色。
平台中的 cluster-admin角色可以为其他用户创建账号并分配平台角色,平台内置了集群层级的以下三个常用的角色,同时支持自定义新的角色。
|
内置角色 |
描述 |
|
workspaces-manager |
平台企业空间管理员,管理平台所有企业空间。 |
|
users-manager |
平台用户管理员,管理平台所有用户。 |
|
platform-regular |
平台普通用户,在被邀请加入企业空间或集群之前没有任何资源操作权限。 |
|
platform-admin |
平台管理员,可以管理平台内的所有资源。 |
内置角色由KubeSphere自动创建,无法编辑或删除。
(2)KuberSphere部署 MySQL
- 前提条件:集群管理-项目管理-创建项目testproject,
- 创建秘钥
MySQL 的环境变量 MYSQL_ROOT_PASSWORD 即 root 用户的密码属于敏感信息,不适合以明文的方式表现在步骤中,因此以创建密钥的方式来代替该环境变量。创建的密钥将在创建 MySQL 的容器组设置时作为环境变量写入。
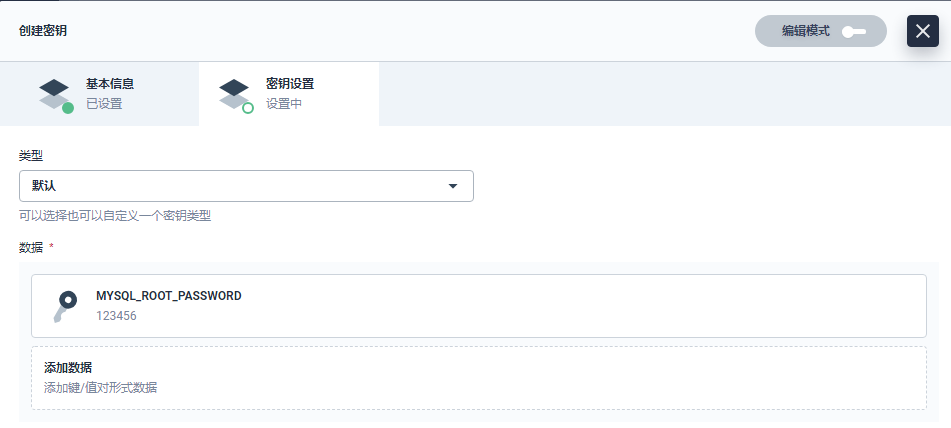
在当前项目下左侧菜单栏的 配置中心 选择 密钥,点击 创建。填写密钥的基本信息,完成后点击 下一步。
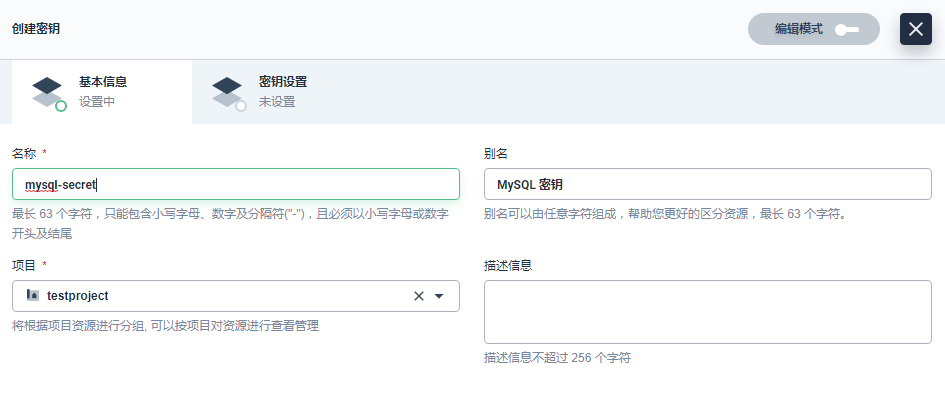
密钥设置页,填写如下信息,完成后点击 创建。(类型:选择 默认 (Opaque);Data:Data 键值对填写 MYSQL_ROOT_PASSWORD 和 123456)
- 创建有状态副本集
在左侧菜单栏选择 工作负载 → 有状态副本集,然后点击 创建有状态副本集。
- 填写基本信息
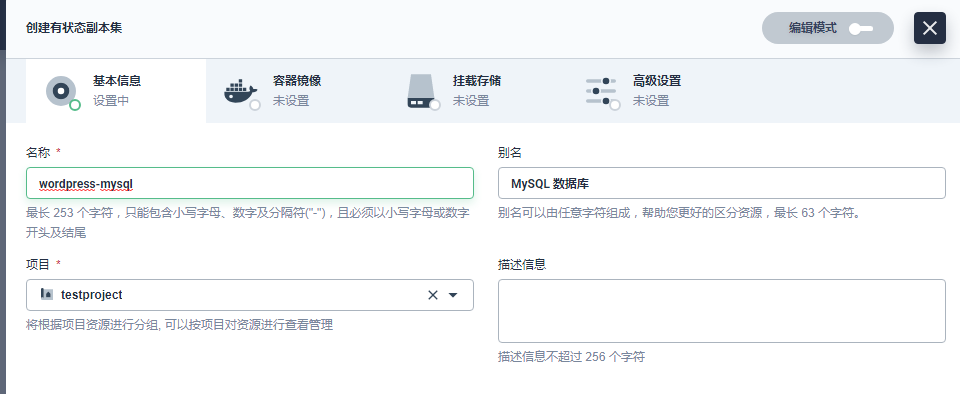
基本信息中,参考如下填写,完成后点击 下一步。
(名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,例如填写 wordpress-mysql;别名:可选,支持中文帮助更好的区分资源,例如填写 MySQL 数据库;描述信息:简单介绍该工作负载,方便用户进一步了解)
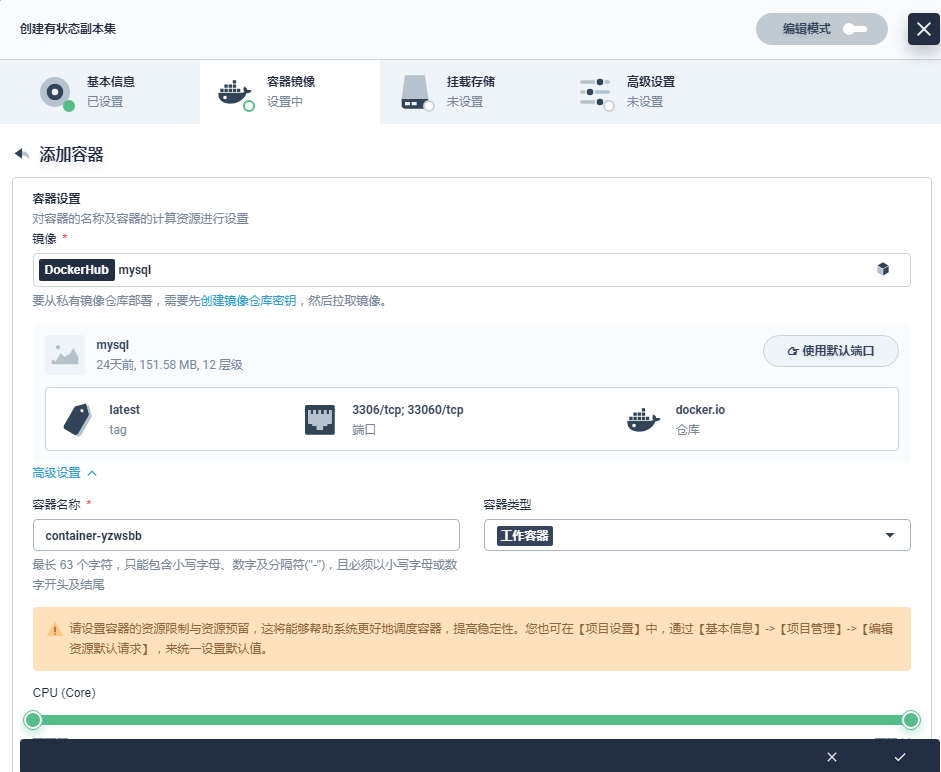
- 容器组模板
点击 添加容器,填写容器组设置,名称可由用户自定义,镜像填写 mysql,CPU 和内存此处暂不作限定,将使用在创建项目时指定的默认请求值。
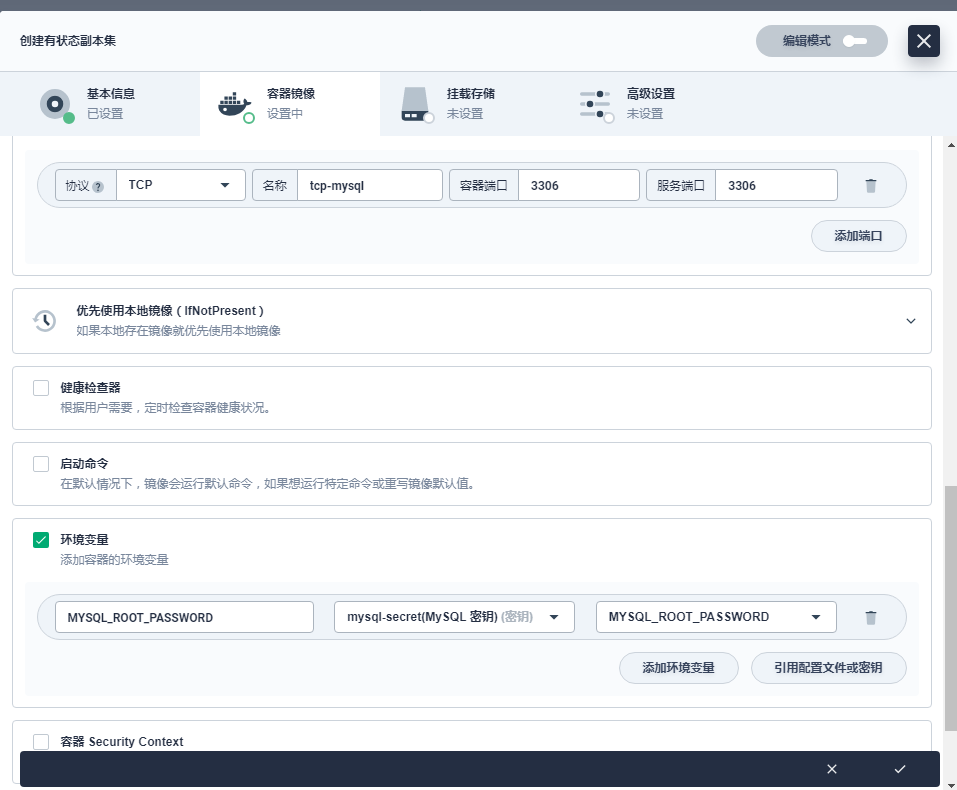
对 服务设置 和 环境变量 进行设置,其它项暂不作设置,完成后点击 保存。
(端口:名称可自定义如 port,选择 TCP 协议,填写 MySQL 在容器内的端口 3306;环境变量:勾选环境变量,点击 引用配置中心,名称填写 MYSQL_ROOT_PASSWORD,选择在第一步创建的密钥 mysql-secret (MySQL 密钥) 和 MYSQL_ROOT_PASSWORD)
点击 保存,然后点击 下一步。
- 添加存储卷模板
容器组模板完成后点击 下一步,在存储卷模板中点击 添加存储卷模板。有状态应用的数据需要存储在持久化存储卷 (PVC) 中,因此需要添加存储卷来实现数据持久化。参考下图填写存储卷信息。
(存储卷名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,此处填写 mysql-pvc
存储类型:选择集群已有的存储类型,如 Local
容量和访问模式:容量默认 10 Gi,访问模式默认 ReadWriteOnce (单个节点读写)
挂载路径:存储卷在容器内的挂载路径,选择 读写,路径填写 /var/lib/mysql)
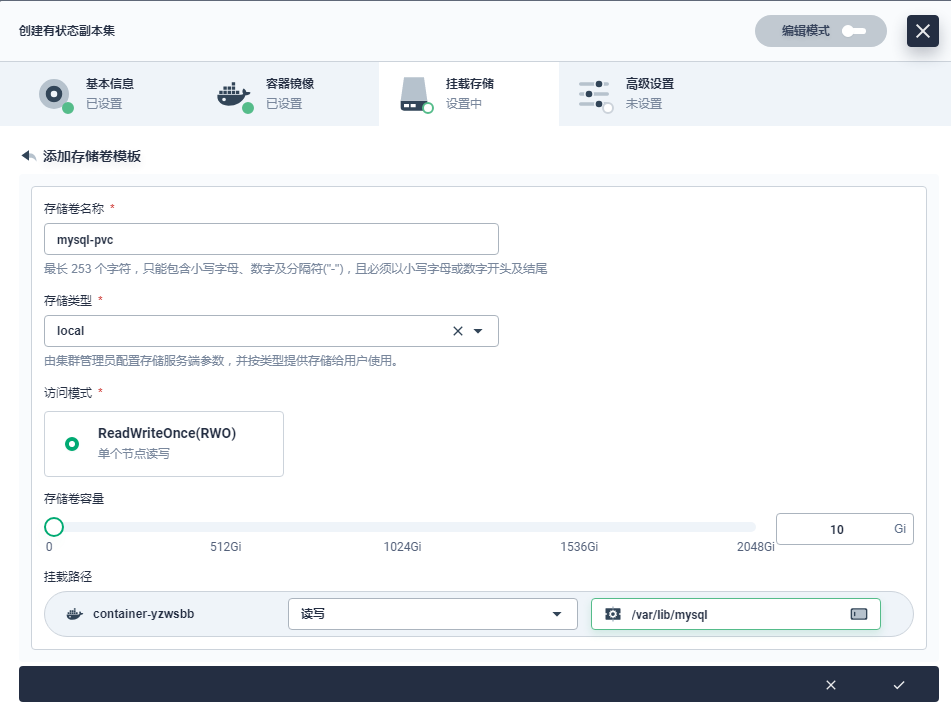
完成后点击 保存,然后点击 下一步。点击 创建 完成有状态副本集。
- 服务配置
要将 MySQL 应用暴露给其他应用或服务访问,需要创建服务,参考以下截图完成参数设置,完成后点击 下一步。
(服务名称:此处填写 mysql-service,注意,这里定义的服务名称将关联 Wordpress,因此在创建 Wordpress 添加环境变量时应填此服务名
会话亲和性:默认 None
端口:名称可自定义,选择 TCP 协议,MySQL 服务的端口和目标端口都填写 3306,其中第一个端口是需要暴露出去的服务端口,第二个端口(目标端口)是容器端口
说明: 若有实现基于客户端 IP 的会话亲和性的需求,可以在会话亲和性下拉框选择 “ClientIP” 或在代码模式将 service.spec.sessionAffinity 的值设置为 “ClientIP”(默认值为 “None”),该设置可将来自同一个 IP 地址的访问请求都转发到同一个后端 Pod。)
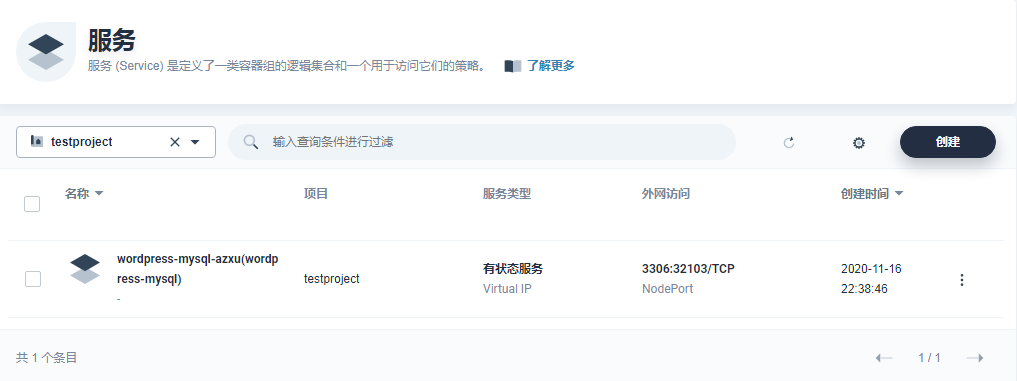
Mysql 外网映射出的端口为32103。
进入Mysql容器远程终端
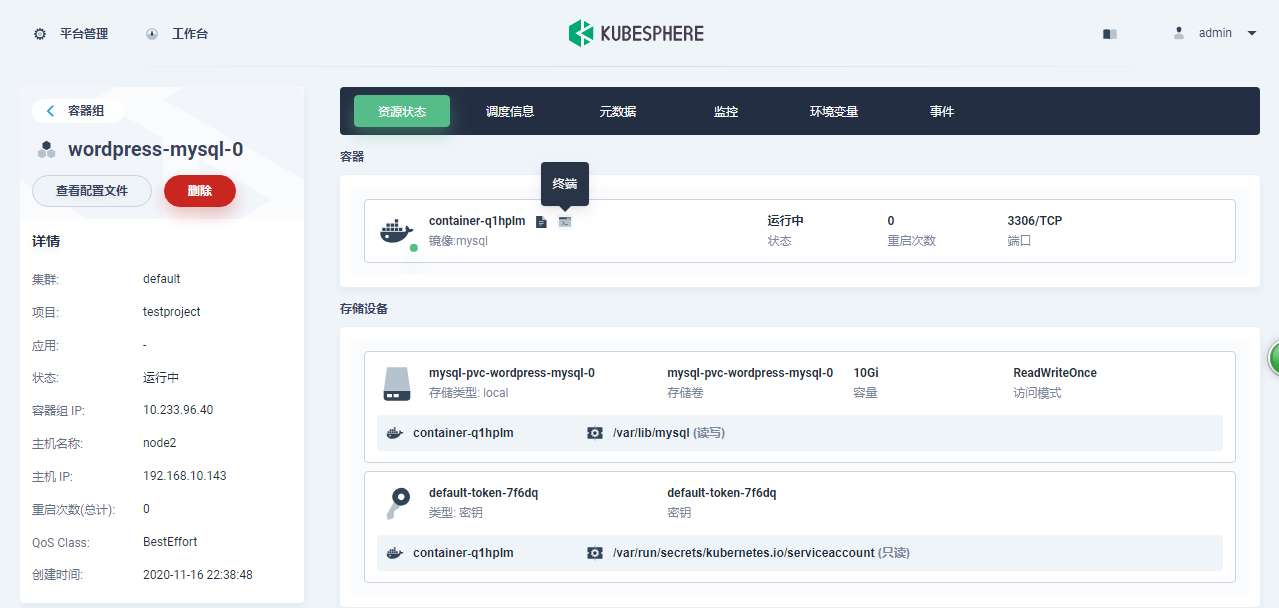
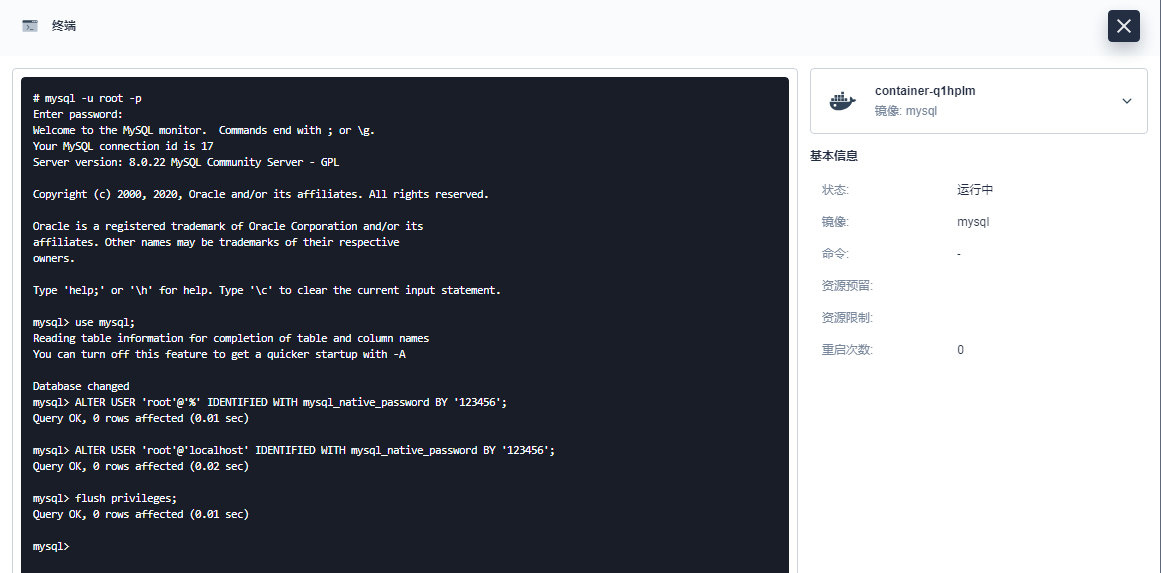
|
mysql -u root -p use mysql; ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456'; ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456'; flush privileges; |
实现Mysql数据库远程连接访问。
- MySQL 有状态应用
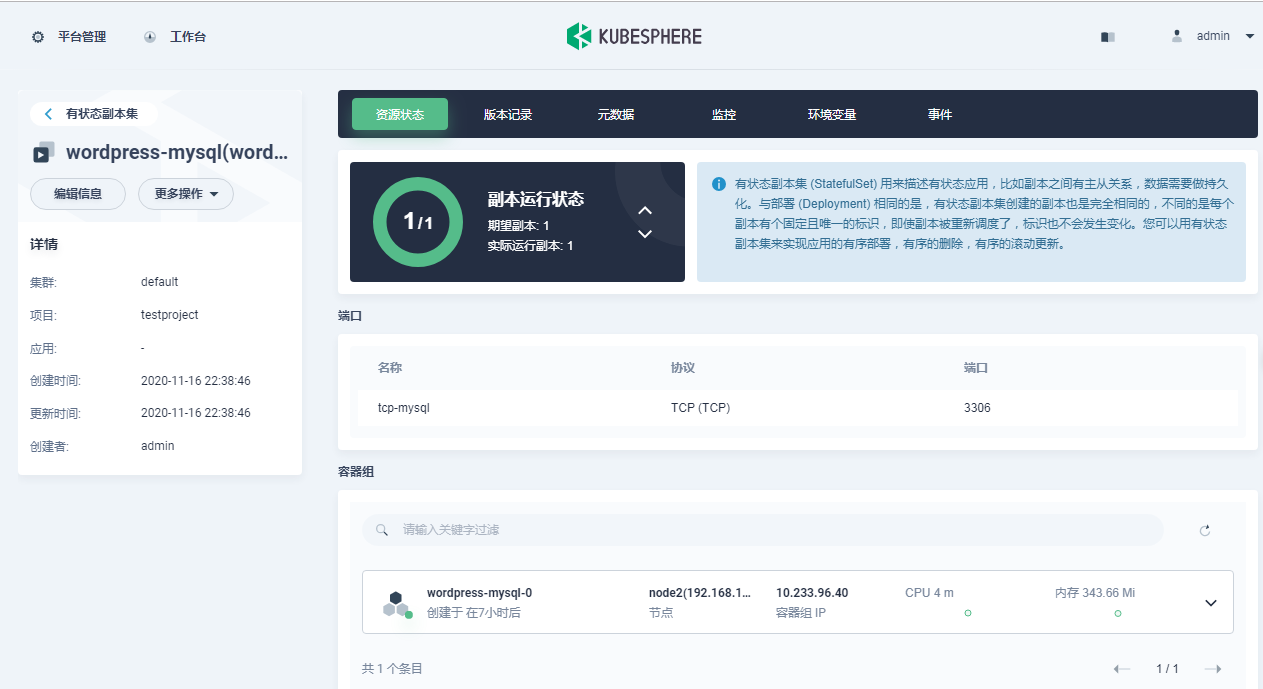
在列表页可以看到有状态副本集 “wordpress-mysql” 的状态为 “更新中”,该过程需要拉取镜像仓库中指定 tag 的 Docker 镜像、创建容器和初始化数据库等一系列操作,状态显示 ContainerCreating。正常情况下在一分钟左右状态将变为 “运行中”,点击该项即可进入有状态副本集的详情页,包括资源状态、版本控制、监控、环境变量、事件等信息。
(3)部署 Wordpress
基于MySQL 应用最终部署一个外网可访问的 Wordpress 网站。Wordpress 连接 MySQL 数据库的密码将以 配置 (ConfigMap) 的方式进行创建和保存。
前提条件,完成Mysql部署
- 创建配置
Wordpress 的环境变量 WORDPRESS_DB_PASSWORD 即 Wordpress 连接数据库的密码,以创建配置 (ConfigMap) 的方式来代替该环境变量。创建的配置将在创建 Wordpress 的容器组设置时作为环境变量写入。
填写配置的基本信息,完成后点击 下一步。
(名称:作为 Wordpress 容器中环境变量的名称,填写 wordpress-configmap
别名:支持中文,帮助您更好的区分资源,比如 连接 MySQL 密码
描述信息:简单介绍该 ConfigMap,如 MySQL password)
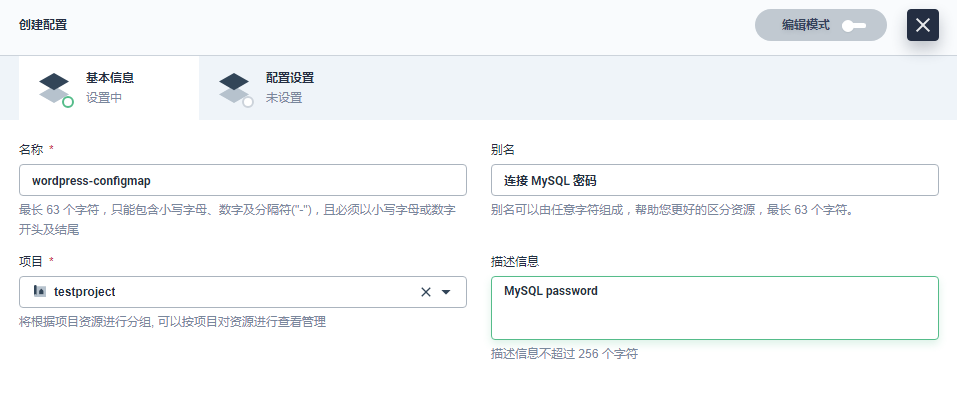
ConfigMap 是以键值对的形式存在,此处键值对设置为 WORDPRESS_DB_PASSWORD 和 123456,完成后点击 创建。
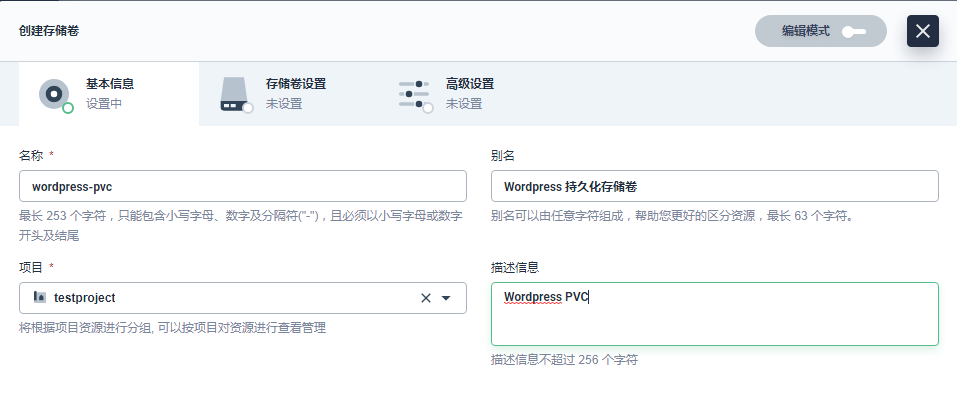
- 创建存储卷
在当前项目下左侧菜单栏的 存储卷,点击创建,基本信息如下。
(名称:wordpress-pvc
别名:Wordpress 持久化存储卷
描述信息:Wordpress PVC)
完成后点击 下一步,存储卷设置中,参考如下填写:
(存储类型:选择集群中已创建的存储类型,例如 Local
访问模式:选择单节点读写 (RWO)
存储卷容量:默认 10 Gi)
标签默认为 app: wordpress-pvc,点击 「创建」。
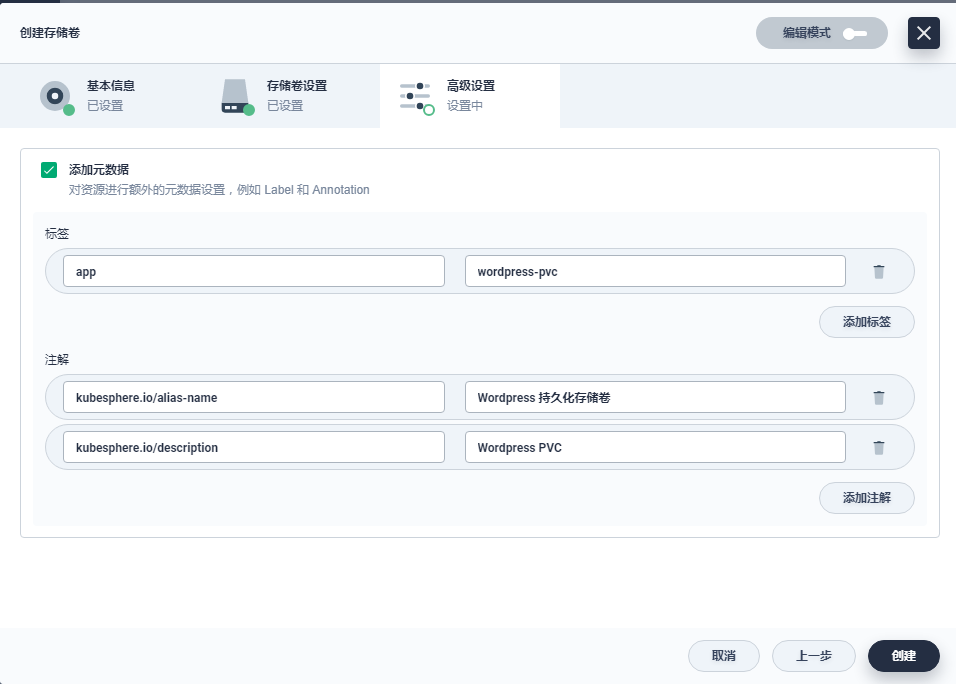
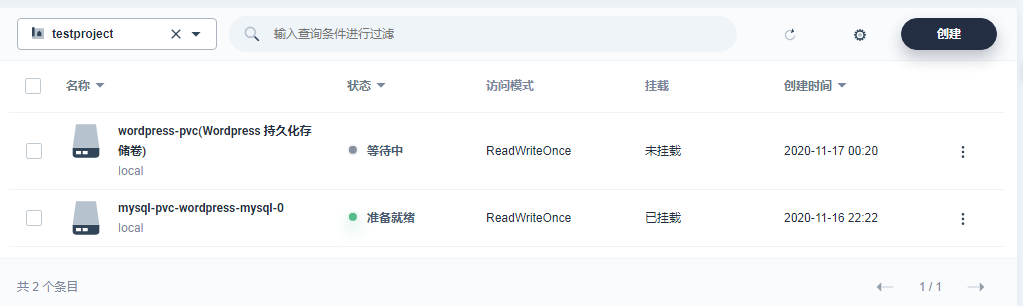
点击左侧菜单中的 存储卷,查看存储卷列表,可以看到存储卷 wordpress-pvc 已经创建成功,状态是 “准备就绪”,可挂载至工作负载。
(若存储类型为 Local,那么该存储卷在被挂载至工作负载之前都将显示创建中,这种情况是正常的,因为 Local 目前还不支持存储卷动态配置 (Dynamic Volume Provisioning) ,挂载后状态将显示 “准备就绪”。)
- 创建部署
在左侧菜单栏选择 工作负载 → 部署,进入列表页,点击 创建部署。
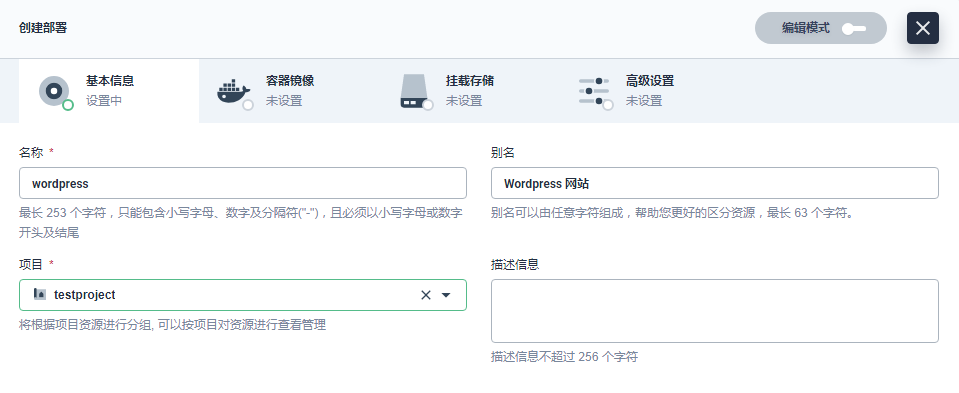
- 填写基本信息
基本信息中,参考如下填写,完成后点击 下一步。
(名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,比如 wordpress
别名:可选,支持中文帮助更好的区分资源,如 Wordpress 网站
描述信息:简单介绍该工作负载,方便用户进一步了解)
- 容器组模板
点击 添加容器。容器组模板中,名称可自定义,镜像填写 wordpress,CPU 和内存此处暂不作限定,将使用在创建项目时指定的默认值。
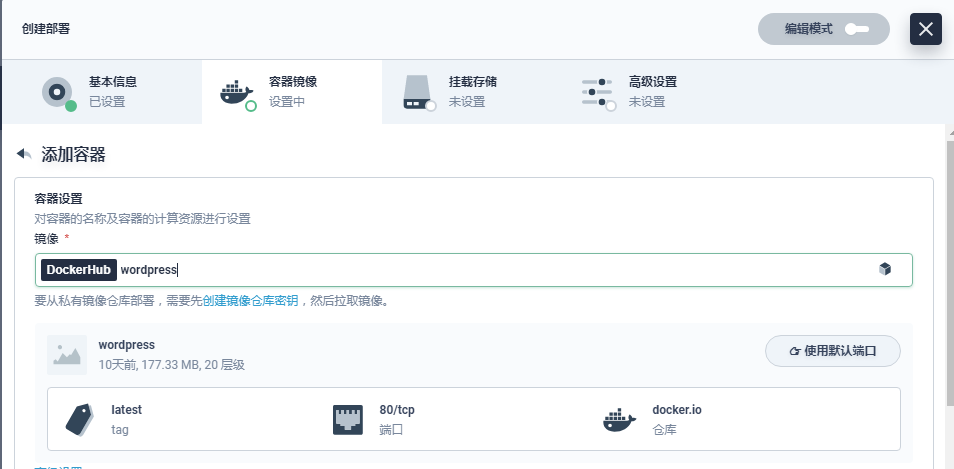
下滑至服务设置,对 端口 和 环境变量 进行设置,其它项暂不作设置。参考如下填写。
(端口:名称可自定义如 port,选择 TCP 协议,填写 Wordpress 在容器内的端口 80。
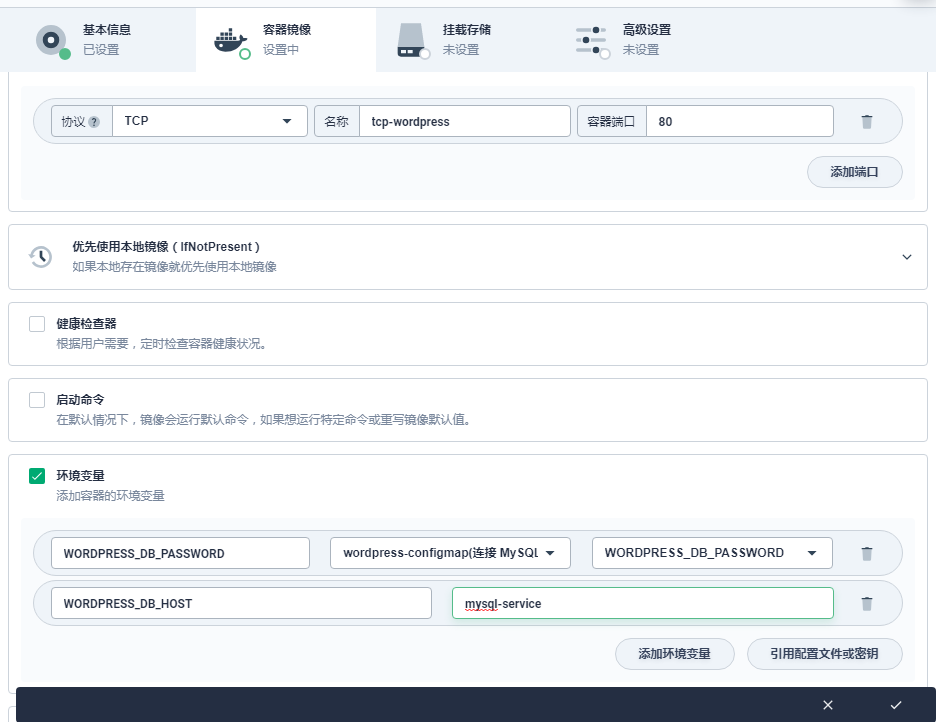
环境变量:这里需要添加两个环境变量
A 点击 引用配置中心,名称填写 WORDPRESS_DB_PASSWORD,选择在第一步创建的配置 (ConfigMap) wordpress-configmap 和 WORDPRESS_DB_PASSWORD。
B 点击 添加环境变量,名称填写 WORDPRESS_DB_HOST,值填写 mysql-service,对应的是 )
完成后点击 保存,点击 下一步。
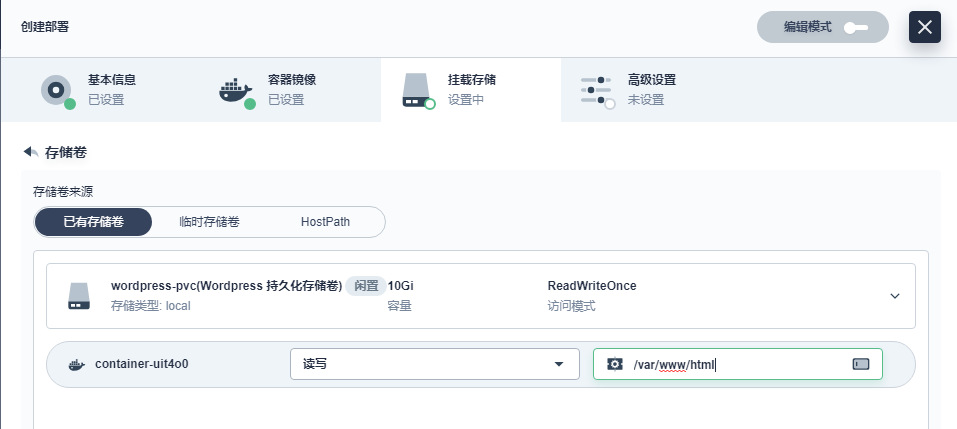
- 存储卷设置
此处选择 添加已有存储卷,选择第二步创建的存储卷 wordpress-pvc。
设置存储卷的挂载路径,其中挂载选项选择 读写,挂载路径为 /var/www/html,保存后点击 下一步。
- 查看部署
标签保留默认值,节点选择器此处暂不作设置,点击 创建,部署创建完成。
创建完成后,部署的状态为 “更新中” 是由于创建后需要拉取 wordpress 镜像并创建容器 (大概一分钟左右),可以看到容器组的状态是 “ContainerCreating”,待部署创建完成后,状态会显示 “运行中”。
查看创建的部署 Wordpress,可以看到其状态显示运行中,下一步则需要为 Wordpress 创建服务,最终暴露给外网访问。
- 创建服务
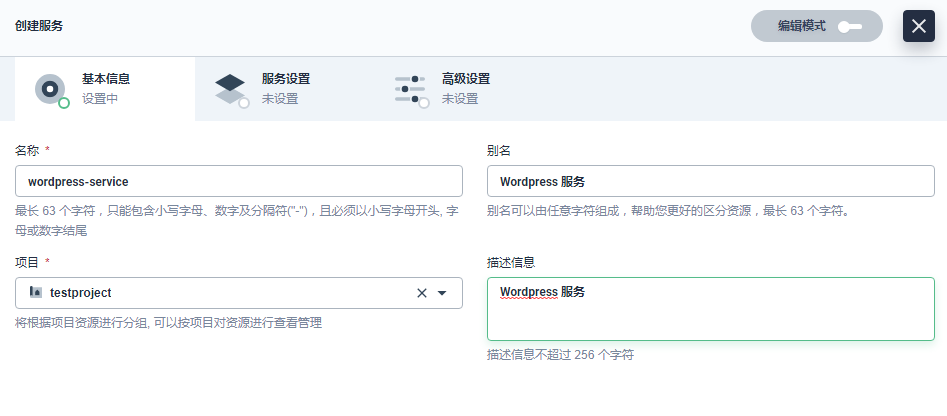
在当前项目中,左侧菜单栏选择 网路与服务 → 服务,点击 创建。
基本信息中,信息填写如下,完成后点击 下一步:
(名称:必填,起简洁明了的名称,便于用户浏览和搜索,比如 wordpress-service
别名和描述信息:如 Wordpress 服务)
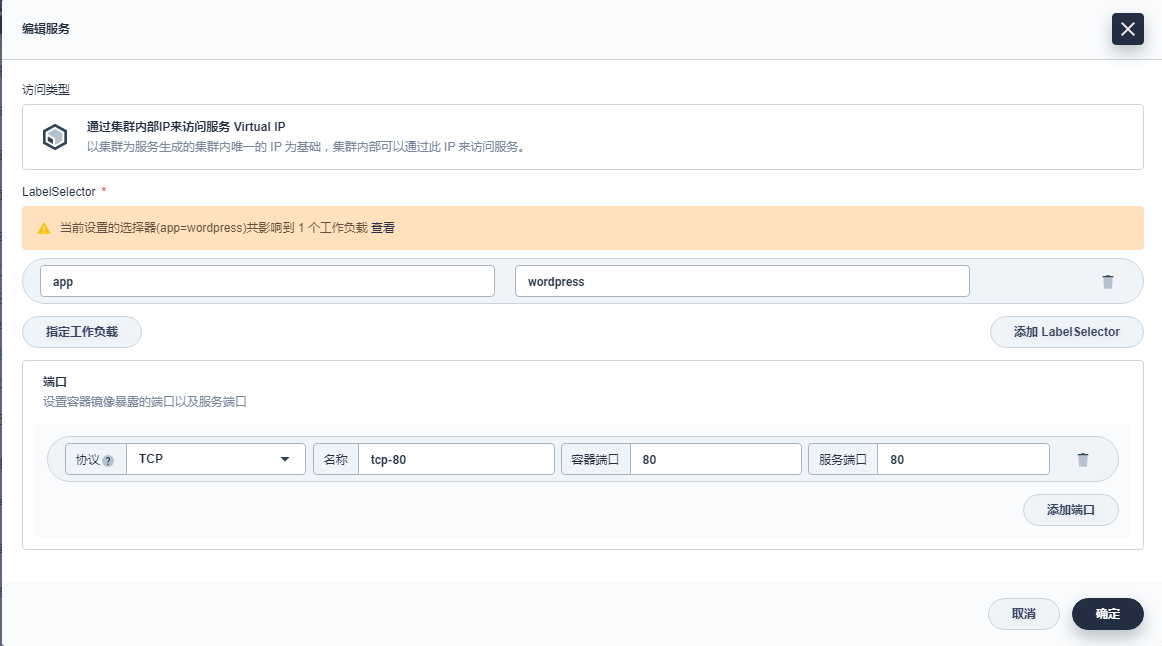
服务设置参考如下填写,完成后点击 下一步:
服务类型:选择第一项 通过集群内部IP来访问服务 Virtual IP
选择器:点击 指定工作负载 可以指定上一步创建的部署 Wordpress,指定后点击 保存
端口:端口名称可自定义如 port,服务的端口和目标端口都填写 TCP 协议的 80 端口
本示例标签保留默认值,选择 下一步。
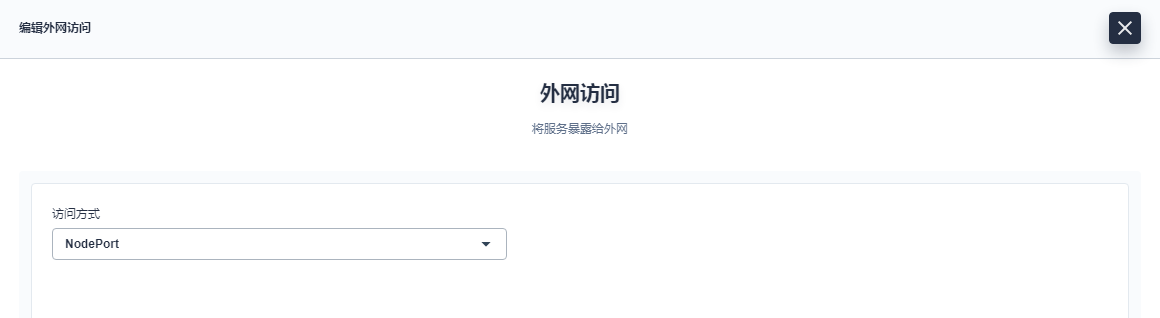
服务暴露给外网访问支持 NodePort 和 LoadBalancer,这里服务的访问方式选择 NodePort。
- 访问 Wordpress
点击 创建,wordpress-service 服务可创建成功。注意,wordpress-service 服务生成了一个节点端口 32412。
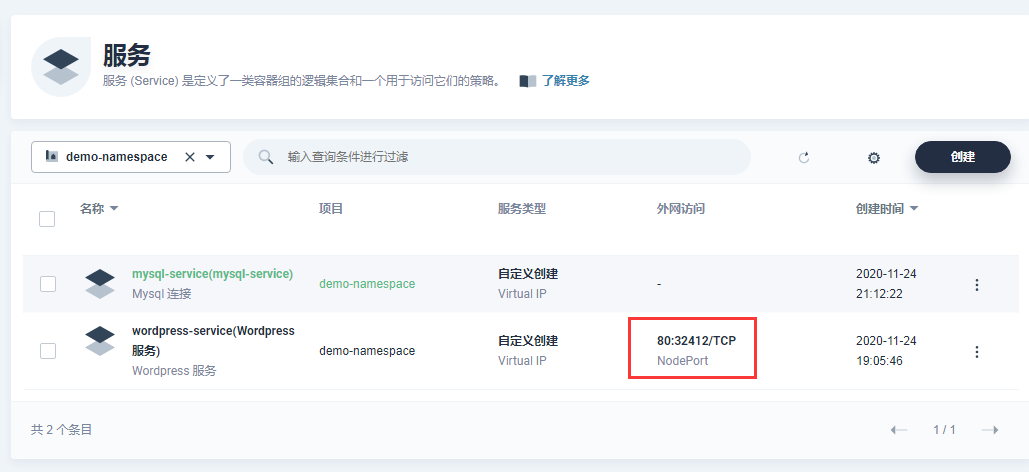
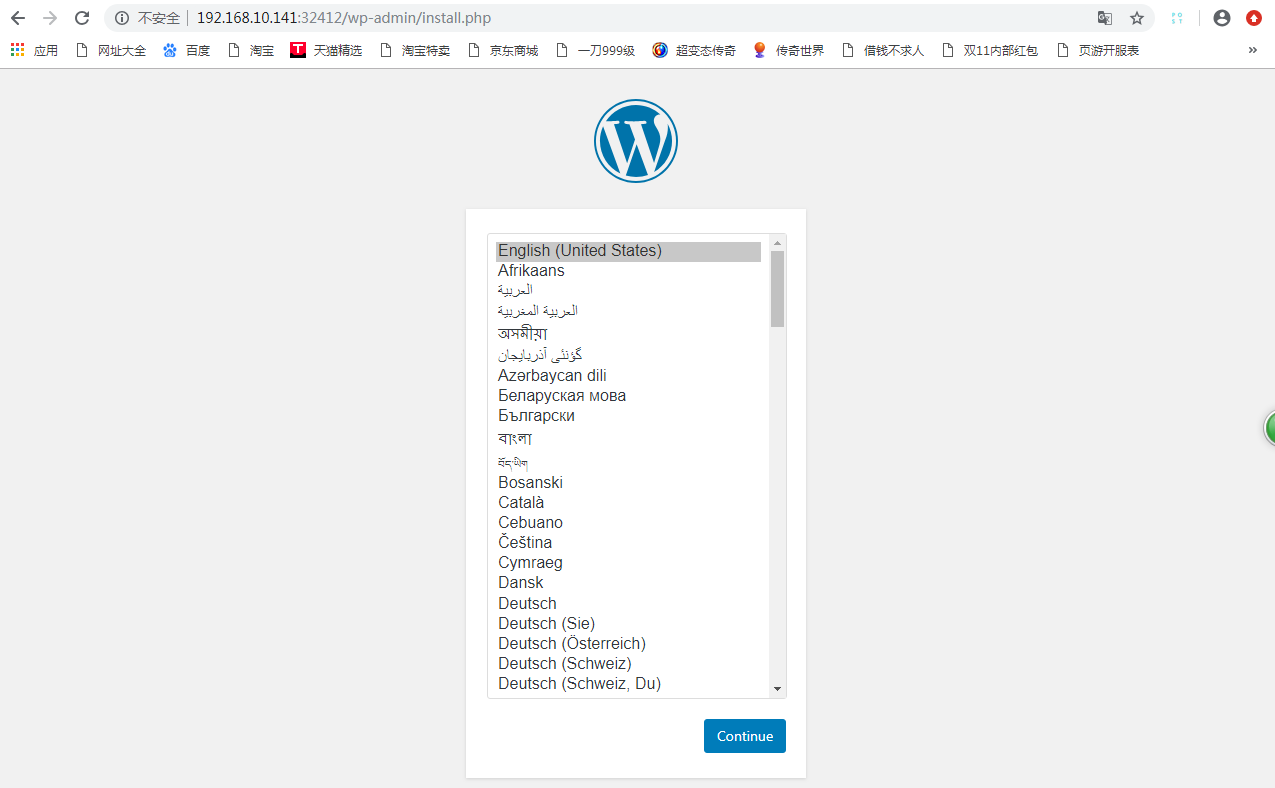
设置完成后,WordPress 就以服务的方式通过 NodePort 暴露到集群外部,可以通过 http://{$ IP}:{$节点端口 NodePort} 访问 WordPress 博客网站。
2.3.5 Kubernetes 框架分析
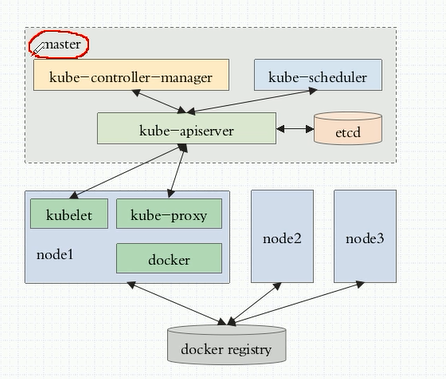
kubernetes由以下组件组成: kubernetes master;kubernetes nodes;etcd; kubernetes network。Kubernetes 框架图如下图所示。
(1)kubernetes master
kubernetes主要有以下几个功能:认证和授权;RESTful API entry point;对kubernetes nodes容器部署的调度;扩容和复制容器;读取配置去创建群集。
- API server (kube-apiserver):
API server提供基于HTTP或者HTTPS的RESTful API,它是kubernetes 组件中心,比如kubectl, the scheduler, the replication controller, 和etcd 数据存储,及运行在kubernetes nodes上的kubelet 和kube-proxy.
- Scheduler (kube-scheduler)
调度器帮助选择哪个容器运行在哪个节点上,针对派送和绑定容器到节点,
- Controller manager( kube-controller-manager)
该控制管理执行群集的操作。比如:管理kubernetes nodes;创建和更新kubernetes内部信息;尝试改变当前的状态到满意的状态。
- Command-line interface (kubectl)
安装完kubernetes master后,可以使用kubernetes 命令行接口,kuberctl,去管理kubernetes群集,比如使用kubectl get cs返回每个组件的状态,kubectl get nodes返回kubernetes节点的列表。
//see the Component Statuses

//see the nodes
- Etcd
etcd是分布式的键值数据存储,可以通过RESTful API去执行CRUD的操作,kubernetes使用etcd作为主要数据存储。
(2)kubernetes Node节点
kubernetes node在kubernetes群集中是slave node, 它是由kubernetes master控制的,使用docker支撑应用。Node节点除了Docker容器以外还有两个守护进程,kubelet和kube-proxy。
- proxy(kube-proxy)
proxy处理网络代理和每个容器的负载均衡,它通过改变linux iptables rules来控制在容器上的TCP和UDP包。
- kubelet
在kubernetes集群中,每个Node节点都会启动kubelet进程,用来处理Master节点下发到本节点的任务,管理Pod和其中的容器。
(3)kubernetes network
Kubernetes网络实现本书主要介绍一些概念,Kubernetes 网络模型设计的一个基础原则是:每个 Pod 都拥有一个独立的 IP 地址,而且假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否允许在同一个 Node(宿主机)中,都要求它可以直接通过对方的 IP 进行访问。
Kubernetes的网络通信主要分为以下几种情况:Pod内容器之间的通信;Pod到Pod之间的通信;Pod到Service之间的通信;集群外部与内部组件之间的通信
2.4 实验案例
|
实验题目 |
Docker平台安装,Docker平台安装Mysql |
|
|
实验目的 :熟悉Docker平台安装与使用 |
||
|
实验内容及过程 Docker平台安装 1 安装centos7 操作系统 2卸载Docker旧版本 3使用 Docker 仓库进行安装 Docker Engine-Community 4运行 hello-world 映像来验证是否正确安装 Docker平台安装Mysql 1 查看镜像 2 拉取 MySQL 镜像 3查看本地镜像 4运行容器(采用共享存储模式) 5 MySQL安装测试 |
||
|
实验完成情况小结 |
||
|
成绩 |
||
2.5 本章小结
本章主要介绍了智慧校园支撑平台Paas层部分,包括基础设施层选型,Docker 应用容器引擎,kubernetes 容器管理平台。通过本章学习可以完成Docker 安装与使用,kubeshpere安装与使用问题。加深对基础设施层的理解,为智慧校园支撑平台提供技术保障。
2.6 本章参考
http://docs.kubernetes.org.cn/249.html#Pod
https://docs.microsoft.com/zh-cn/sql/linux/quickstart-install-connect-docker
https://www.cnblogs.com/zhengyazhao/p/11690189.html
https://www.jianshu.com/p/080a962c35b6
http://dockone.io/article/932
https://blog.csdn.net/ITzhangdaopin/article/details/88896574
https://blog.csdn.net/csdn877425287/article/details/108552412
https://kubesphere.io/docs/quick-start/
https://v2-1.docs.kubesphere.io/docs/zh-CN/quick-start/ingress-demo/
https://www.bookstack.cn/read/kubesphere-v2.0-zh/quick-start-admin-quick-start.md
https://kubesphere.io/docs/quick-start/
https://www.cnblogs.com/liujunjun/p/12191822.html
https://www.cnblogs.com/double-dong/p/11483670.html
https://www.cnblogs.com/zangxueyuan/p/9203180.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号