第二十一章 函数递归
一、函数递归调用介绍
函数不仅可以嵌套定义,还可以嵌套调用,即在调用一个函数的过程中,函数内部又调用另一个函数,而函数的递归调用指的是在调用一个函数的过程中又直接或间接地调用该函数本身。
例如
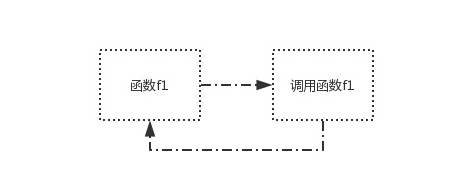
在调用f1的过程中,又调用f1,这就是直接调用函数f1本身
def f1():
print('from f1')
f1()
f1()
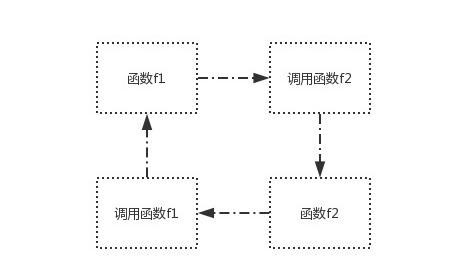
# 在调用f1的过程中,又调用f2,而在调用f2的过程中又调用f1,这就是间接调用函数f1本身
def f1():
print('from f1')
f2()
def f2():
print('from f2')
f1()
f1()
从上图可以看出,两种情况下的递归调用都是一个无限循环的过程,但在python对函数的递归调用的深度做了限制,因而并不会像大家所想的那样进入无限循环,会抛出异常,要避免出现这种情况,就必须让递归调用在满足某个特定条件下终止。
ps:
#1. 可以使用sys.getrecursionlimit()去查看递归深度,默认值为1000,虽然可以使用
import sys
sys.getrecursionlimit()查看递归深度,默认值为1000
sys.setrecursionlimit()去设定该值,但仍受限于主机操作系统栈大小的限制
#2. python不是一门函数式编程语言,无法对递归进行尾递归优化。
二、回溯与递推
下面我们用一个浅显的例子,阐释递归的原理和使用:
某公司四个员工坐在一起,问第四个人薪水,他说比第三个人多1000,问第三个人薪水,第他说比第二个人多1000,问第二个人薪水,他说比第一个人多1000,最后第一人说自己每月5000,请问第四个人的薪水是多少?
思路解析:
要知道第四个人的月薪,就必须知道第三个人的,第三个人的又取决于第二个人的,第二个人的又取决于第一个人的,而且每一个员工都比前一个多一千,数学表达式即:
salary(4)=salary(3)+1000
salary(3)=salary(2)+1000
salary(2)=salary(1)+1000
salary(1)=5000
总结为:
salary(n)=salary(n-1)+1000 (n>1)
salary(1)=5000 (n=1)
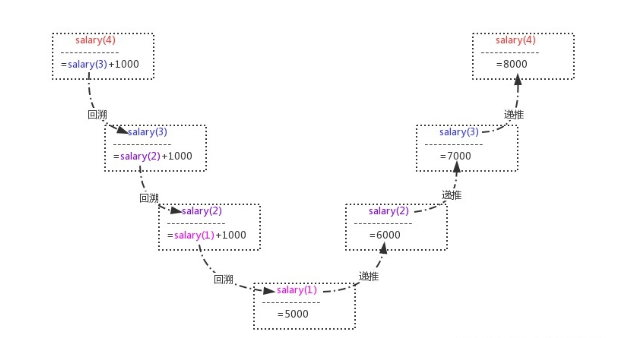
很明显这是一个递归的过程,可以将该过程分为两个阶段:回溯和递推。
在回溯阶段,要求第n个员工的薪水,需要回溯得到(n-1)个员工的薪水,以此类推,直到得到第一个员工的薪水,此时,salary(1)已知,因而不必再向前回溯了。
然后进入递推阶段:从第一个员工的薪水可以推算出第二个员工的薪水(6000),从第二个员工的薪水可以推算出第三个员工的薪水(7000),以此类推,一直推算出第第四个员工的薪水(8000)为止,递归结束。需要注意的一点是,递归一定要有一个结束条件,这里n=1就是结束条件。
# 代码实现:
def salary(n):
if n==1:
return 5000
return salary(n-1)+1000
s=salary(4)
print(s)
# 执行结果:
8000
# 程序分析:
在未满足n\=\=1的条件时,一直进行递归调用,即一直回溯,见图左半部分。而在满足n\=\=1的条件时,终止递归调用,即结束回溯,从而进入递推阶段,依次推导直到得到最终的结果。
递归本质就是在做重复的事情,所以理论上递归可以解决的问题循环也都可以解决,只不过在某些情况下,使用递归会更容易实现,比如有一个嵌套多层的列表,要求打印出所有的元素,代码实现如下
items=[[1,2],3,[4,[5,[6,7]]]]
def foo(items):
for i in items:
if isinstance(i,list): #满足未遍历完items以及if判断成立的条件时,一直进行递归调用
foo(i)
else:
print(i,end=' ')
foo(items) #打印结果1 2 3 4 5 6 7
使用递归,我们只需要分析出要重复执行的代码逻辑,然后提取进入下一次递归调用的条件或者说递归结束的条件即可,代码实现起来简洁清晰
三、python中的递归效率低且没有尾递归优化
#python中的递归
python中的递归效率低,需要在进入下一次递归时保留当前的状态,在其他语言中可以有解决方法:尾递归优化,即在函数的最后一步(而非最后一行)调用自己。
但是python又没有尾递归,且对递归层级做了限制
#总结递归的使用:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
四、二分法
想从一个按照从小到大排列的数字列表中找到指定的数字,遍历的效率太低,用二分法(算法的一种,算法是解决问题的方法)可以极大低缩小问题规模
l=[1,2,10,30,33,99,101,200,301,311,402,403,500,900,1000] #从小到大排列的数字列表
def search(n,l):
print(l)
if len(l) == 0:
print('not exists')
return
mid_index=len(l) // 2
if n > l[mid_index]:
#in the right
l=l[mid_index+1:]
search(n,l)
elif n < l[mid_index]:
#in the left
l=l[:mid_index]
search(n,l)
else:
print('find it')
search(3,l)
l=[1,2,10,30,33,99,101,200,301,402]
def search(num,l,start=0,stop=len(l)-1):
if start <= stop:
mid=start+(stop-start)//2
print('start:[%s] stop:[%s] mid:[%s] mid_val:[%s]' %(start,stop,mid,l[mid]))
if num > l[mid]:
start=mid+1
elif num < l[mid]:
stop=mid-1
else:
print('find it',mid)
return
search(num,l,start,stop)
else: #如果stop > start则意味着列表实际上已经全部切完,即切为空
print('not exists')
return
search(301,l)

