一、Sentinel介绍
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
#必须在redis主从已经做好的前提下
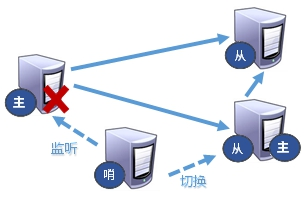
二、Sentinel的构造
Sentinel 是一个监视器,它可以根据被监视实例的身份和状态来判断应该执行何种动作。
三、Sentinel的功能
1.监控(Monitoring):
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
四、Sentinel的具体工作
1.Sentinel通过用户给定的配置文件来发现主服务器
2.Sentinel会与被监视的主服务器创建两个网络连接:
1)命令连接用于向主服务器发送命令。
2)订阅连接用于订阅指定的频道,从而发现监视同一主服务器的其他Sentinel。
3.Sentinel通过向主服务器发送INFO命令来自动获得所有从服务器的地址。
4.发现其他sentinel
Sentinel 会通过命令连接向被监视的主从服务器发送 “HELLO” 信息,该消息包含 Sentinel 的 IP、端口号、ID 等内容,以此来向其他 Sentinel 宣告自己的存在。与此同时Sentinel 会通过订阅连接接收其他 Sentinel 的“HELLO” 信息,以此来发现监视同一个主服务器的其他 Sentinel 。
5.多个Sentinel之间只会互相创建命令连接,用于进行通信。因为已经有主从服务器作为发送和接收HELLO信息的中介,所以Sentinel之间不会创建订阅连接。
6.检测实例的状态:
Sentinel使用PING命令来检测实例的状态:如果实例在指定的时间内没有返回回复,或者返回错误的回复,那么该实例会被 Sentinel 判断为下线。
Redis的Sentinel中关于下线(down)有两个不同的概念:
1)主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
2)客观下线(Objectively Down,简称 ODOWN)指的是多个Sentinel实例在对同一个服务器做出SDOWN判断,并且通过SENTINEL is-master-down-by-addr命令互相交流之后,得出的服务器下线判断。(一个 Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
五、故障转移流程
一次故障转移操作由以下步骤组成:
1.发现主服务器已经进入客观下线状态。
2.基于Raft leader election协议,进行投票选举
3.如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选。如果当选成功,那么执行以下步骤。
1)选出一个从服务器,并将它升级为主服务器。
2)向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
3)通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新。
4)向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器。
5)当所有从服务器都已经开始复制新的主服务器时, leader Sentinel 终止这次故障迁移操作。
六、Sentinel选择主库的规则
1.在失效主服务器属下的从服务器当中,那些被标记为主观下线、已断线、或者最后一次回复PING命令的时间大于五秒钟的从服务器都会被淘汰。
2.在失效主服务器属下的从服务器当中,那些与失效主服务器连接断开的时长超过down-after选项指定的时长十倍的从服务器都会被淘汰。
3.在经历了以上两轮淘汰之后剩下来的从服务器中,我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行ID的那个从服务器成为新的主服务器。
七、Sentinel特性
1.Sentinel自动故障迁移使用Raft算法来选举领头(leader)Sentinel ,从而确保在一个给定的周期(epoch)里,只有一个领头产生。
2.这表示在同一个周期中,不会有两个 Sentinel 同时被选中为领头,并且各个 Sentinel 在同一个节点中只会对一个领头进行投票。
3.更高的配置节点总是优于较低的节点,因此每个 Sentinel 都会主动使用更新的节点来代替自己的配置。
#简单来说,我们可以将Sentinel配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他Sentinel。
八、Sentinel实战
1.环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
db01 |
172.16.1.51 |
6379 |
| 从库 |
db02 |
172.16.1.52 |
6379 |
| 从库 |
db03 |
172.16.1.53 |
6379 |
2.恢复主从状态
#修复坏掉的主库
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-cli -h 172.16.1.51
172.16.1.51:6379> info replication
172.16.1.51:6379> SLAVEOF 172.16.1.52 6379
OK
172.16.1.51:6379> info replication
#主库查看
172.16.1.52:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=4229,lag=1
slave1:ip=172.16.1.51,port=6379,state=online,offset=4229,lag=1
master_repl_offset:4229
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:4228
3.配置sentinel哨兵
#创建目录(随便创建)
[root@db01 ~]# mkdir /service/redis/26379
#编辑sentinel配置文件
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile /service/redis/26379/sentinel.pid
logfile /service/redis/26379/sentinel.log
dir /service/redis/26379
bind 172.16.1.51 127.0.0.1
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
4.启动sentinel
[root@db01 ~]# redis-sentinel /service/redis/26379/sentinel.conf
#启动之后配置文件会发生改变
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile "/service/redis/26379/sentinel.pid"
logfile "/service/redis/26379/sentinel.log"
dir "/service/redis/26379"
bind 172.16.1.51 127.0.0.1
sentinel myid 7d430385a1269307819e5300ecf09dfbf92b46f5
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel config-epoch mymaster 0
# Generated by CONFIG REWRITE
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 172.16.1.51 6379
sentinel known-slave mymaster 172.16.1.53 6379
sentinel current-epoch 0
5.停止sentinel
[root@db01 ~]# redis-cli -p 26379 shutdown
6.测试sentinel
#关闭主库的redis
[root@db02 ~]# redis-cli shutdown
#查看其它从库主从状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.16.1.53,port=6379,state=online,offset=586,lag=1
master_repl_offset:723
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:722
7.恢复故障节点
#修复故障节点
[root@db02 ~]# redis-server /service/redis/6379/redis.conf
#查看主库状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=5077,lag=1
slave1:ip=172.16.1.52,port=6379,state=online,offset=5077,lag=1
master_repl_offset:5077
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:5076
8.sentinel管理命令(不常用)
#连接sentinel管理端口
[root@db01 ~]# redis-cli -p 26379
#检测状态,返回PONG
127.0.0.1:26379> ping
PONG
#列出所有被监视的主服务器
127.0.0.1:26380> SENTINEL masters
#列出所有被监视的从服务器
127.0.0.1:26380> SENTINEL slaves mymaster
#返回给定名字的主服务器的IP地址和端口号
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
1) "172.16.1.51"
2) "6379
#重置所有名字和给定模式
127.0.0.1:26380> SENTINEL reset mymaster
#当主服务器失效时,在不询问其他Sentinel意见的情况下,强制开始一次自动故障迁移。
127.0.0.1:26380> SENTINEL failover mymaster
9.设置权重,指定主库的优先级
#查看db02的权重
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "100"
#修改db02的权重值为0
172.16.1.52:6379> CONFIG set slave-priority 0
OK
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "0"
#权重值越低越不会优先切换为主库
#强制开始一次自动故障迁移
127.0.0.1:26380> SENTINEL failover mymaster
#再次查看,主库为db03
172.16.1.53:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.52,port=6379,state=online,offset=71377,lag=0
slave1:ip=172.16.1.51,port=6379,state=online,offset=71377,lag=0
master_repl_offset:71514
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:70496
repl_backlog_histlen:1019
10.哨兵架构

11. 哨兵集群设置
| 主机名 |
IP地址 |
Redis版本和角色 |
| redis-master |
10.0.0.71 |
Redis 6.0.9 (master) |
| redis-slave01 |
10.0.0.72 |
Redis 6.0.9 (slave) |
| redis-slave02 |
10.0.0.73 |
Redis 6.0.9 (slave) |
| redis-master |
10.0.0.74 |
Redis 6.0.9 (Sentinel01) |
| redis-slave01 |
10.0.0.75 |
Redis 6.0.9 (Sentinel01) |
| redis-slave02 |
10.0.0.76 |
Redis 6.0.9 (Sentinel01) |
12. 哨兵配置
1.sentinel.conf配置文件主要参数解析
# 端口
port 26379
# 是否后台启动
daemonize yes
# pid文件路径
pidfile /var/run/redis-sentinel.pid
# 日志文件路径
logfile "/var/log/sentinel.log"
# 定义工作目录
dir /tmp
# 定义Redis主的别名, IP, 端口,这里的2指的是需要至少2个Sentinel认为主Redis挂了才最终会采取下一步行为
# sentinel monitor [集群名称] [集群主节点IP] [端口] []
sentinel monitor mymaster 127.0.0.1 6379 2
# 如果mymaster 30秒内没有响应,则认为其主观失效
sentinel down-after-milliseconds mymaster 30000
# 如果master重新选出来后,其它slave节点能同时并行从新master同步数据的台数有多少个,显然该值越大,所有slave节点完成同步切换的整体速度越快,但如果此时正好有人在访问这些slave,可能造成读取失败,影响面会更广。最保守的设置为1,同一时间,只能有一台干这件事,这样其它slave还能继续服务,但是所有slave全部完成缓存更新同步的进程将变慢。
sentinel parallel-syncs mymaster 1
# 该参数指定一个时间段,在该时间段内没有实现故障转移成功,则会再一次发起故障转移的操作,单位毫秒
sentinel failover-timeout mymaster 180000
# 当集群配置密码的时候,哨兵需要知道节点密码才能进行监控
# sentinel auth-pass [节点名称] [密码]
sentinel auth-pass mymaster abc123
# 不允许使用SENTINEL SET设置notification-script和client-reconfig-script。
sentinel deny-scripts-reconfig yes
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel.pid"
logfile "/var/log/sentinel.log"
dir "/tmp"
sentinel monitor mymaster 192.168.56.11 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
#修改三台Sentinel配置文件
[root@alvin-test-os sentinel]# grep -Ev "^$|#" sentinel26379.conf
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel79.pid"
logfile "/var/log/sentinel79.log"
dir "/tmp"
sentinel monitor mymaster 192.168.12.60 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@alvin-test-os sentinel]# grep -Ev "^$|#" sentinel26380.conf
port 26380
daemonize yes
pidfile "/var/run/redis-sentinel80.pid"
logfile "/var/log/sentinel80.log"
dir "/tmp"
sentinel monitor mymaster 192.168.12.60 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@alvin-test-os sentinel]# grep -Ev "^$|#" sentinel26381.conf
port 26381
daemonize yes
pidfile "/var/run/redis-sentinel81.pid"
logfile "/var/log/sentinel81.log"
dir "/tmp"
sentinel monitor mymaster 192.168.12.60 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
# 部署
[root@alvin-test-os sentinel]# ps -ef | grep redis
root 6406 1 0 15:08 ? 00:00:26 ./bin/redis-server 127.0.0.1:6379
root 6492 1 0 15:08 ? 00:00:27 ./bin/redis-server 127.0.0.1:6380
root 6566 1 0 15:08 ? 00:00:24 ./bin/redis-server 127.0.0.1:6381
root 12128 1 0 18:55 ? 00:00:01 redis-sentinel *:26379 [sentinel]
root 12202 1 0 18:55 ? 00:00:01 redis-sentinel *:26380 [sentinel]
root 12248 1 0 18:55 ? 00:00:02 redis-sentinel *:26381 [sentinel]
# 查看集群主节点监控
127.0.0.1:26379> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "192.168.12.60"
5) "port"
6) "6379"
7) "runid"
8) "c3cfe939ddae7c73e8dce06588e88b4eda5c0112"
9) "flags"

