一、概述
Kubernetes 作为容器集群系统,通过健康检查+重启策略实现了 Pod 故障自我修复能力, 通过调度算法实现将 Pod 分布式部署,监控其预期副本数,并根据 Node 失效状态自动在正常 Node 启动 Pod,实现了应用层的高可用性。
针对 Kubernetes 集群,高可用性还应包含以下两个层面的考虑:Etcd 数据库的高可用性和 Kubernetes Master 组件的高可用性。 而 Etcd 我们已经采用 3 个节点组建集群实现高可用,本节将对 Master 节点高可用进行说明和实施。
Master 节点扮演着总控中心的角色,通过不断与工作节点上的 Kubelet 和 kube-proxy 进行通信来维护整个集群的健康工作状态。如果 Master 节点故障,将无法使用 kubectl 工具或者 API 任何集群管理。
Master 节点主要有三个服务 kube-apiserver、kube-controller-mansger 和 kube-scheduler,其中 kube-controller-mansger 和 kube-scheduler 组件自身通过选择机制已经实现了高可用,所以 Master 高可用主要针对 kube-apiserver 组件,而该组件是以 HTTP API 提供服务,因此对他高可用与 Web 服务器类似,增加负载均衡器对其负载均衡即可, 并且可水平扩容。
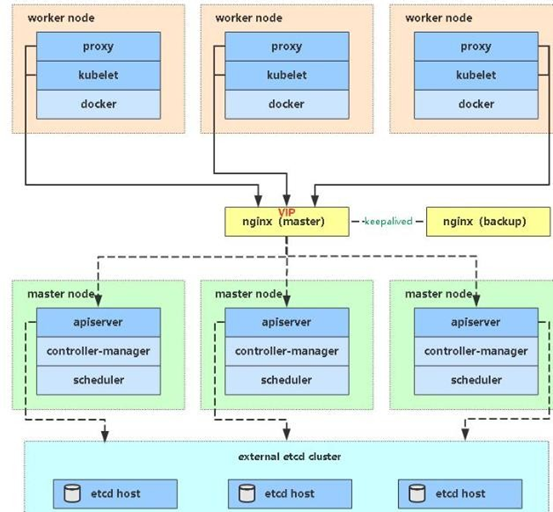
二、多Master架构图
三、安装要求
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master节点的IP和端口 >
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
- 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
- 禁止swap分区
四、环境准备
| 角色 |
IP |
| master1 |
192.168.44.155 |
| master2 |
192.168.44.156 |
| node1 |
192.168.44.157 |
| VIP(虚拟ip) |
192.168.44.158 |
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.44.158 master.k8s.io k8s-vip
192.168.44.155 master01.k8s.io master1
192.168.44.156 master02.k8s.io master2
192.168.44.157 node01.k8s.io node1
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
五、Master节点部署keepalived
1.安装相关包和keepalived
yum install -y conntrack-tools libseccomp libtool-ltdl
yum install -y keepalived
2.配置master节点
#1.master1节点配置
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 250
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.44.158
}
track_script {
check_haproxy
}
}
EOF
#2.master2节点配置
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.44.158
}
track_script {
check_haproxy
}
}
EOF
3.启动和检查
在两台master节点都执行
# 启动keepalived
$ systemctl start keepalived.service
设置开机启动
$ systemctl enable keepalived.service
# 查看启动状态
$ systemctl status keepalived.service
启动后查看master1的网卡信息
ip a s ens33
六、部署haproxy
1.安装
yum install -y haproxy
2.配置
两台master节点的配置均相同,配置中声明了后端代理的两个master节点服务器,指定了haproxy运行的端口为16443等,因此16443端口为集群的入口
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master01.k8s.io 192.168.44.155:6443 check
server master02.k8s.io 192.168.44.156:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
3. 启动和检查
两台master都启动
# 设置开机启动
$ systemctl enable haproxy
# 开启haproxy
$ systemctl start haproxy
# 查看启动状态
$ systemctl status haproxy
检查端口
netstat -lntup|grep haproxy
七、所有节点安装Docker/kubeadm/kubelet
Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker。
1.安装Docker
$ wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
$ yum -y install docker-ce-18.06.1.ce-3.el7
$ systemctl enable docker && systemctl start docker
$ docker --version
Docker version 18.06.1-ce, build e68fc7a
$ cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
2.添加阿里云YUM软件源
$ cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署,不指定默认安装最新版本:
$ yum install -y kubelet-1.16.3 kubeadm-1.16.3 kubectl-1.16.3
$ systemctl enable kubelet
八、部署Kubernetes Master
1. 创建kubeadm配置文件
在具有vip的master上操作,这里为master1
$ mkdir /usr/local/kubernetes/manifests -p
$ cd /usr/local/kubernetes/manifests/
$ vi kubeadm-config.yaml
apiServer:
certSANs:
- master1
- master2
- master.k8s.io
- 192.168.44.158
- 192.168.44.155
- 192.168.44.156
- 127.0.0.1
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "master.k8s.io:16443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.16.3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.1.0.0/16
scheduler: {}
2. 在master1节点执行
$ kubeadm init --config kubeadm-config.yaml
3.按照提示配置环境变量,使用kubectl工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl get nodes
$ kubectl get pods -n kube-system
4.按照提示保存以下内容,一会要使用:
kubeadm join master.k8s.io:16443 --token jv5z7n.3y1zi95p952y9p65 \
--discovery-token-ca-cert-hash sha256:403bca185c2f3a4791685013499e7ce58f9848e2213e27194b75a2e3293d8812 \
--control-plane
5.查看集群状态
kubectl get cs
kubectl get pods -n kube-system
九、安装集群网络
从官方地址获取到flannel的yaml,在master1上执行
mkdir flannel
cd flannel
wget -c https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
1.安装flannel网络
kubectl apply -f kube-flannel.yml
2.检查
kubectl get pods -n kube-system
十、Master2节点加入集群
1.复制密钥及相关文件
从master1复制密钥及相关文件到master2
# ssh root@192.168.44.156 mkdir -p /etc/kubernetes/pki/etcd
# scp /etc/kubernetes/admin.conf root@192.168.44.156:/etc/kubernetes
# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.44.156:/etc/kubernetes/pki
# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.44.156:/etc/kubernetes/pki/etcd
2.Master2加入集群
执行在master1上init后输出的join命令,需要带上参数`--control-plane`表示把master控制节点加入集群
kubeadm join master.k8s.io:16443 --token ckf7bs.30576l0okocepg8b --discovery-token-ca-cert-hash sha256:19afac8b11182f61073e254fb57b9f19ab4d798b70501036fc69ebef46094aba --control-plane
3.检查状态
kubectl get node
kubectl get pods --all-namespaces
十一、加入Kubernetes Node
在node1上执行
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
kubeadm join master.k8s.io:16443 --token ckf7bs.30576l0okocepg8b --discovery-token-ca-cert-hash sha256:19afac8b11182f61073e254fb57b9f19ab4d798b70501036fc69ebef46094aba
1.集群网络重新安装,因为添加了新的node节点
kubectl delete -f kube-flannel.yml
kubectl apply -f kube-flannel.yml
2.检查状态
kubectl get node
kubectl get pods --all-namespaces
十二、测试kubernetes集群
#1.在Kubernetes集群中创建一个pod,验证是否正常运行:
$ kubectl create deployment nginx --image=nginx
$ kubectl expose deployment nginx --port=80 --type=NodePort
$ kubectl get pod,svc
#2.访问地址:http://NodeIP:Port

 浙公网安备 33010602011771号
浙公网安备 33010602011771号