一、Hadoop环境准备
1.集群规划
| 主机名 |
IP |
HDFS |
YARN |
| hadoop102 |
10.0.0.102 |
NameNode、DataNode |
NodeManager |
| hadoop103 |
10.0.0.103 |
DataNode、SecondaryNameNode |
NodeManager、ResourceManager |
| hadoop104 |
10.0.0.104 |
DataNode |
NodeManager |
#1.注意事项:
ps:
1)NameNode和SecondaryNameNode不要安装在同一台服务器
2)ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
#2.配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
1)默认配置文件:
要获取的默认文件 文件存放在Hadoop的jar包中的位置
[core-default.xml] hadoop-common-3.1.3.jar/core-default.xml
[hdfs-default.xml] hadoop-hdfs-3.1.3.jar/hdfs-default.xml
[yarn-default.xml] hadoop-yarn-common-3.1.3.jar/yarn-default.xml
[mapred-default.xml] hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml
2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
2.修改主机名称
#1.修改hadoop102的hosts文件
[root@hadoop102 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.102 hadoop102
10.0.0.103 hadoop103
10.0.0.104 hadoop104
#2.将hadoop102的hosts文件拷贝到hadoop103
[root@hadoop102 ~]# scp /etc/hosts root@hadoop103:/etc/hosts
root@hadoop103's password:
hosts 100% 222 1.5KB/s 00:00
#2.将hadoop102的hosts文件拷贝到hadoop104
[root@hadoop102 ~]# scp /etc/hosts root@hadoop104:/etc/hosts
root@hadoop104's password:
hosts 100% 222 108.8KB/s 00:00
3.创建部署用户
#1.创建用户
[root@hadoop102 ~]# useradd delopy
[root@hadoop103 ~]# useradd delopy
[root@hadoop104 ~]# useradd delopy
#2.sudo提权
[root@hadoop102 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
delopy ALL=(ALL) ALL
#3.复制sudo文件到hadoop103
[root@hadoop102 ~]# scp /etc/sudoers root@hadoop103:/etc/sudoers
root@hadoop103's password:
sudoers 100% 4356 1.0MB/s 00:00
#4.复制sudo文件到hadoop104
[root@hadoop102 ~]# scp /etc/sudoers root@hadoop104:/etc/sudoers
root@hadoop104's password:
sudoers 100% 4356 769.0KB/s 00:00
#5.创建程序和数据目录
[root@hadoop102 ~]# mkdir /data/
[root@hadoop102 ~]# mkdir /opt/module
[root@hadoop102 ~]# chown -R delopy.delopy /data/
[root@hadoop102 ~]# chown -R delopy.delopy /opt/module/
二、SSH免密登录
1.生成密钥对(所有机器)
#1.切换delopy用户
[root@hadoop102 ~]# su delopy
#2.设置用户密码
[root@hadoop102 ~]# passwd delopy
Changing password for user delopy.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
#3.生成密钥对,一直回车即可
[delopy@hadoop102 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/delopy/.ssh/id_rsa):
Created directory '/home/delopy/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/delopy/.ssh/id_rsa.
Your public key has been saved in /home/delopy/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:8gV808AJIHCQTE8uEkUPuCn16A8IuSQrMfQSf2CBBEc delopy@hadoop102
The key's randomart image is:
+---[RSA 2048]----+
|=OE== ...o.. |
|.*+X . . oo |
|o=*o= o o . |
|X+.+.. o . |
|=B. . . S . |
|= o o . |
|. o . |
| . |
| |
+----[SHA256]-----+
2.查看密钥(所有机器)
#1.查看生成的密钥对
[delopy@hadoop102 ~]$ cd ~/.ssh
[delopy@hadoop102 ~/.ssh]$ ll
total 8
-rw------- 1 delopy delopy 1679 2021-08-31 14:59 id_rsa
-rw-r--r-- 1 delopy delopy 398 2021-08-31 14:59 id_rsa.pub
#3.查看公钥
[root@hadoop102 ~/.ssh]# cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCebmCdoFk9XrT5AVoNJFlhwoYArJY80BU9JyNwwXziR6NjuTrS4pzENBwx/Lbq0/qMI/PdZMMdiBYhpZTL/DkZyDoRf+2zRzPNQUMvTrK3bjIH4CAs3L7qSrkGICeaWQ9PIJwaRqF2yPS16qFTnq8aAimz08UiGzLfhGUHiEA+QF8usoe3titLXQ9fguRxyCfigdCEeq+xhPVuDpXCNoi6Woh4mnegGoVtJWgguFG0DU1gfUGckl0oKHM4ZbVBaQWTmQjHUKgvwwlXAO4gZ3qkVcGzMxfcc0P/OMqojYEbD5n/RFiMbN8ylCJt6QjOj23NzTG/LTNFFRbDfbLRhhm1 root@hadoop102
[delopy@hadoop102 ~/.ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC7WKwWyb3lliFTQ1HPxZS63NvFLPYYiLovVhspMCWkiRKrgIGXB++tBRi2vJvLpLyMOpJVRc0hIUD2ycBgHuWLtWYNqma/1xzeIu67OrsK+v8+CeTCzqZ97DPp881Uu+4SoVQOkla7evpH40DOibvKd7SN8L7Mk+PEsVCeIrNyA/g2iZ9+M+XWaZIIYJb15QRPZLcgj1GHcR0cf6DtuTt26pCVimSYJ8DOYNNfHfwWKyJfBKKaQUX3ByYDbKIIH+yw3VbLgyU3v9oseYCA5psqeuD0YLuERrr45rydNRL7/oeoW2NicHSG2V1H6KBQBq861HcdbmcE2nbZtWrAsKpv delopy@hadoop102
[delopy@hadoop103 ~/.ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDLlKkbKYyIpUpwYLRBIqLhhU2YYb9o1dafpNwR8IkIj6rDBc2OzD1fqdzSQSpHX8LXShDTv2nr4R++SG1MabwqJ4q7JKwmZRSjuy/flQK0uhtSW6rPNqZX3P8Tl8rSqUMInOwwna9qCZTI8gajPrXRHAJ+oKRWWtGQ3M6t6larC4tXSoFQ4nBkPEgXUFnYphX1mYJiD0QduUXZwK7IMzFXPP/SkW+PddepFlsV2gTf2xCsLh7RHhsh0zWThkJGqLb6nPbIjOydQ84C3Z5DusAxOqlvuQk2FKpOQrB0dAgtHog7Oc/1vJqAMRe6MPdzaExl+OIEW2Xh8jJf9JWSkcs3 delopy@hadoop103
[delopy@hadoop104 ~/.ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2EXMXB9V4f86vRhD2cHhZEd+gqatotEy9HkwKfajelPgH1KcD4jepM7h+RmutGj+QfCSE/fj56GuebjHFJmB8eB1X5wZ0B3lBbz+KV/bNB7IAHvEWn7KG6nkdkzT47zLJrWVY6zxS0BMW86WF4wNGeyHq4R3XZnRxEW/LJ/ZjENpJkh7X2Om2H6d+tq8WjBSCvlidSB8WlG+OAnLxk/rVUaUdRmBTXqBUhcWqIsD+vMaa/rESxvXbrn/0pl83ZVguRpbNPHbpEPvUujBn/FPSvwv0DN9JEB+v+AzOQADJvT+2mDI/FDzCPpashoeSN31p1vdgXJUQEsBaIlxrm94H delopy@hadoop104
3.配置SSH免密(所有机器)
#1.编辑新文件authorized_keys,将所有公钥添加进去
[delopy@hadoop102 ~/.ssh]$ vim authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCebmCdoFk9XrT5AVoNJFlhwoYArJY80BU9JyNwwXziR6NjuTrS4pzENBwx/Lbq0/qMI/PdZMMdiBYhpZTL/DkZyDoRf+2zRzPNQUMvTrK3bjIH4CAs3L7qSrkGICeaWQ9PIJwaRqF2yPS16qFTnq8aAimz08UiGzLfhGUHiEA+QF8usoe3titLXQ9fguRxyCfigdCEeq+xhPVuDpXCNoi6Woh4mnegGoVtJWgguFG0DU1gfUGckl0oKHM4ZbVBaQWTmQjHUKgvwwlXAO4gZ3qkVcGzMxfcc0P/OMqojYEbD5n/RFiMbN8ylCJt6QjOj23NzTG/LTNFFRbDfbLRhhm1 root@hadoop102
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC7WKwWyb3lliFTQ1HPxZS63NvFLPYYiLovVhspMCWkiRKrgIGXB++tBRi2vJvLpLyMOpJVRc0hIUD2ycBgHuWLtWYNqma/1xzeIu67OrsK+v8+CeTCzqZ97DPp881Uu+4SoVQOkla7evpH40DOibvKd7SN8L7Mk+PEsVCeIrNyA/g2iZ9+M+XWaZIIYJb15QRPZLcgj1GHcR0cf6DtuTt26pCVimSYJ8DOYNNfHfwWKyJfBKKaQUX3ByYDbKIIH+yw3VbLgyU3v9oseYCA5psqeuD0YLuERrr45rydNRL7/oeoW2NicHSG2V1H6KBQBq861HcdbmcE2nbZtWrAsKpv delopy@hadoop102
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDLlKkbKYyIpUpwYLRBIqLhhU2YYb9o1dafpNwR8IkIj6rDBc2OzD1fqdzSQSpHX8LXShDTv2nr4R++SG1MabwqJ4q7JKwmZRSjuy/flQK0uhtSW6rPNqZX3P8Tl8rSqUMInOwwna9qCZTI8gajPrXRHAJ+oKRWWtGQ3M6t6larC4tXSoFQ4nBkPEgXUFnYphX1mYJiD0QduUXZwK7IMzFXPP/SkW+PddepFlsV2gTf2xCsLh7RHhsh0zWThkJGqLb6nPbIjOydQ84C3Z5DusAxOqlvuQk2FKpOQrB0dAgtHog7Oc/1vJqAMRe6MPdzaExl+OIEW2Xh8jJf9JWSkcs3 delopy@hadoop103
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2EXMXB9V4f86vRhD2cHhZEd+gqatotEy9HkwKfajelPgH1KcD4jepM7h+RmutGj+QfCSE/fj56GuebjHFJmB8eB1X5wZ0B3lBbz+KV/bNB7IAHvEWn7KG6nkdkzT47zLJrWVY6zxS0BMW86WF4wNGeyHq4R3XZnRxEW/LJ/ZjENpJkh7X2Om2H6d+tq8WjBSCvlidSB8WlG+OAnLxk/rVUaUdRmBTXqBUhcWqIsD+vMaa/rESxvXbrn/0pl83ZVguRpbNPHbpEPvUujBn/FPSvwv0DN9JEB+v+AzOQADJvT+2mDI/FDzCPpashoeSN31p1vdgXJUQEsBaIlxrm94H delopy@hadoop104
#2.修改文件权限为600
[delopy@hadoop102 ~/.ssh]$ chmod 600 authorized_keys
#3.ssh文件夹下(~/.ssh)的文件功能解释
known_hosts 记录ssh访问过计算机的公钥(public key)
id_rsa 生成的私钥
id_rsa.pub 生成的公钥
authorized_keys 存放授权过的无密登录服务器公钥
4.测试SSH免密登录(所有机器)
#1.ssh免密登录hadoop102
[delopy@hadoop102 ~/.ssh]$ ssh hadoop102
The authenticity of host 'hadoop102 (10.0.0.102)' can't be established.
ECDSA key fingerprint is SHA256:g6buQ4QMSFl+5MMAh8dTCmLtkIfdT8sgRFYc6uCzV3c.
ECDSA key fingerprint is MD5:5f:d7:ad:07:e8:fe:d2:49:ec:79:2f:d4:91:59:c5:03.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop102,10.0.0.102' (ECDSA) to the list of known hosts.
Last login: Tue Aug 31 15:21:35 2021
[delopy@hadoop102 ~]$ logout
Connection to hadoop102 closed.
#2.ssh免密登录hadoop103
[delopy@hadoop102 ~/.ssh]$ ssh hadoop103
The authenticity of host 'hadoop103 (10.0.0.103)' can't be established.
ECDSA key fingerprint is SHA256:g6buQ4QMSFl+5MMAh8dTCmLtkIfdT8sgRFYc6uCzV3c.
ECDSA key fingerprint is MD5:5f:d7:ad:07:e8:fe:d2:49:ec:79:2f:d4:91:59:c5:03.
Are you sure you want to continue connecting (yes/no)? yes
There were 16 failed login attempts since the last successful login.
Last login: Tue Aug 31 14:58:54 2021
[delopy@hadoop103 ~]$ logout
Connection to hadoop103 closed.
#3.ssh免密登录hadoop104
[delopy@hadoop102 ~/.ssh]$ ssh hadoop104
The authenticity of host 'hadoop104 (10.0.0.104)' can't be established.
ECDSA key fingerprint is SHA256:g6buQ4QMSFl+5MMAh8dTCmLtkIfdT8sgRFYc6uCzV3c.
ECDSA key fingerprint is MD5:5f:d7:ad:07:e8:fe:d2:49:ec:79:2f:d4:91:59:c5:03.
Are you sure you want to continue connecting (yes/no)? yes
Last failed login: Tue Aug 31 15:12:11 CST 2021 from 10.0.0.102 on ssh:notty
There were 4 failed login attempts since the last successful login.
Last login: Tue Aug 31 15:01:13 2021
[delopy@hadoop104 ~]$ logout
Connection to hadoop103 closed.
三、编写集群分发脚本xsync
1.scp(secure copy)安全拷贝
#1.scp定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
#2.基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
2.rsync远程同步工具
#1.rsync定义
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
#2.基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明:
-a 归档拷贝
-v 显示复制过程
3.需求分析
#1.需求:循环复制文件到所有节点的相同目录下
#2.需求分析:
1)rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt/
2)期望脚本:
xsync要同步的文件名称
3)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[delopy@hadoop102 ~]$ echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
4.编写xsync集群分发脚本
#1.在/home/deploy/bin目录下创建xsync文件
[delopy@hadoop102 ~]$ mkdir bin
[delopy@hadoop102 ~]$ cd bin/
[delopy@hadoop102 ~/bin]$ vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
#2.修改脚本 xsync 具有执行权限
[delopy@hadoop102 ~/bin]$ chmod +x xsync
#3.测试脚本
[delopy@hadoop102 ~/bin]$ ./xsync /home/delopy/bin
#4.配置环境变量
[delopy@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
# RSYNC_HOME
export PATH=/home/delopy/bin:$PATH
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
#5.同步环境变量配置(root所有者)
[delopy@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效
#5.所有机器刷新环境变量并查看
[atguigu@hadoop103 bin]$ source /etc/profile
[delopy@hadoop102 ~]$ echo $PATH
/opt/hadoop/bin:/opt/hadoop/sbin:/home/delopy/bin:/home/delopy/bin:/home/delopy/bin/xsync:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin:/opt/jdk/bin
四、JDK安装
JDK官网下载:https://www.oracle.com
1.创建软件存放目录
[delopy@hadoop102 ~]$ mkdir /data/software/
[delopy@hadoop102 ~]$ cd /data/software/
2.上传JDK安装包
[delopy@hadoop102 /data/software]$ rz
[delopy@hadoop102 /data/software]$ ll
total 181192
-rw-r--r-- 1 delopy delopy 185540433 2021-06-16 14:21 jdk-8u131-linux-x64.tar.gz
3.解压安装包
[delopy@hadoop102 /data/software]$ tar xf jdk-8u131-linux-x64.tar.gz -C /opt/module/
[delopy@hadoop102 /data/software]$ cd /opt/module/
[delopy@hadoop102 /opt/module]$ ll
total 0
drwxr-xr-x 8 delopy delopy 255 2017-03-15 16:35 jdk1.8.0_131
4.做软连接
[delopy@hadoop102 /data/software]$ cd /opt/module/
[delopy@hadoop102 /opt/module]$ ll
total 0
drwxr-xr-x 8 delopy delopy 255 2017-03-15 16:35 jdk1.8.0_131
5.推送JDK到其他机器
[delopy@hadoop102 /opt/module]$ xsync /opt/module/
6.验证JDK版本(所有机器)
[delopy@hadoop102 /opt/module]$ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
五、Hadoop安装
Hadoop官网下载地址:https://hadoop.apache.org/releases.html
1.下载安装包
[delopy@hadoop102 ~]$ cd /data/software/
[delopy@hadoop102 /data/software]$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
[delopy@hadoop102 /data/software]$ ll
total 772196
-rw-r--r-- 1 delopy delopy 605187279 2021-06-15 17:55 hadoop-3.3.1.tar.gz
2.解压安装包
[delopy@hadoop102 /data/software]$ tar xf hadoop-3.3.1.tar.gz -C /opt/module/
[delopy@hadoop102 /data/software]$ cd /opt/module/
[delopy@hadoop102 /opt/module]$ ll
total 0
drwxr-xr-x 10 delopy delopy 215 2021-06-15 13:52 hadoop-3.3.1
3.做软连接
[delopy@hadoop102 /opt/module]$ ln -s hadoop-3.3.1 hadoop
[delopy@hadoop102 /opt/module]$ ll
total 0
lrwxrwxrwx 1 delopy delopy 12 2021-09-01 11:43 hadoop -> hadoop-3.3.1
drwxr-xr-x 10 delopy delopy 215 2021-06-15 13:52 hadoop-3.3.1
4.同步Hadoop程序到其他机器
[delopy@hadoop102 /opt/module]$ xsync /opt/module/
5.验证hadoop(所有机器)
[delopy@hadoop102 /opt/module]$ hadoop version
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /opt/module/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar
六、Hadoop集群配置
1.核心配置文件
[delopy@hadoop102 ~]$ cd /opt/module/hadoop/etc/hadoop/
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim core-site.xml
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
<description>指定NameNode的地址</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/data</value>
<description>指定hadoop数据的存储目录</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>delopy</value>
<description>配置HDFS网页登录使用的静态用户为delopy</description>
</property>
</configuration>
2.HDFS配置文件
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim hdfs-site.xml
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
<description>nn web端访问地址</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
<description>2nn web端访问地址</description>
</property>
</configuration>
3.YARN配置文件
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>指定MR走shuffle</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
<description>指定ResourceManager的地址</description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description>环境变量的继承</description>
</property>
</configuration>
4.MapReduce配置文件
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MapReduce程序运行在Yarn上</description>
</property>
</configuration>
5.配置workers
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim workers
hadoop102
hadoop103
hadoop104
ps: 该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
6.分发配置好的Hadoop配置文件
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ xsync /opt/module/
七、启动Hadoop集群
1.格式化HDFS
#1.如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[delopy@hadoop102 ~]$ hdfs namenode -format
... ...
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop102/10.0.0.102
************************************************************/
2.启动HDFS
#1.hadoop102启动HDFS
[delopy@hadoop102 ~]$ start-dfs.sh
Starting namenodes on [hadoop102]
Starting datanodes
hadoop103: WARNING: /opt/module/hadoop/logs does not exist. Creating.
hadoop104: WARNING: /opt/module/hadoop/logs does not exist. Creating.
Starting secondary namenodes [hadoop104]
#2.查看集群HDFS启动状态
[delopy@hadoop102 ~]$ jps
18016 Jps
17653 NameNode
17756 DataNode
[delopy@hadoop103 ~]$ jps
16681 DataNode
16748 Jps
[delopy@hadoop104 ~]$ jps
31880 DataNode
31976 SecondaryNameNode
32024 Jps
3.启动YARN
#1.hadoop103启动YARN
[delopy@hadoop103 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
#2.查看集群YARN启动状态
[delopy@hadoop103 ~]$ jps
16968 NodeManager
16681 DataNode
17052 Jps
16862 ResourceManager
[delopy@hadoop102 ~]$ jps
18800 NameNode
18905 DataNode
19323 Jps
19229 NodeManager
[delopy@hadoop104 ~]$ jps
32197 Jps
31880 DataNode
31976 SecondaryNameNode
32090 NodeManager
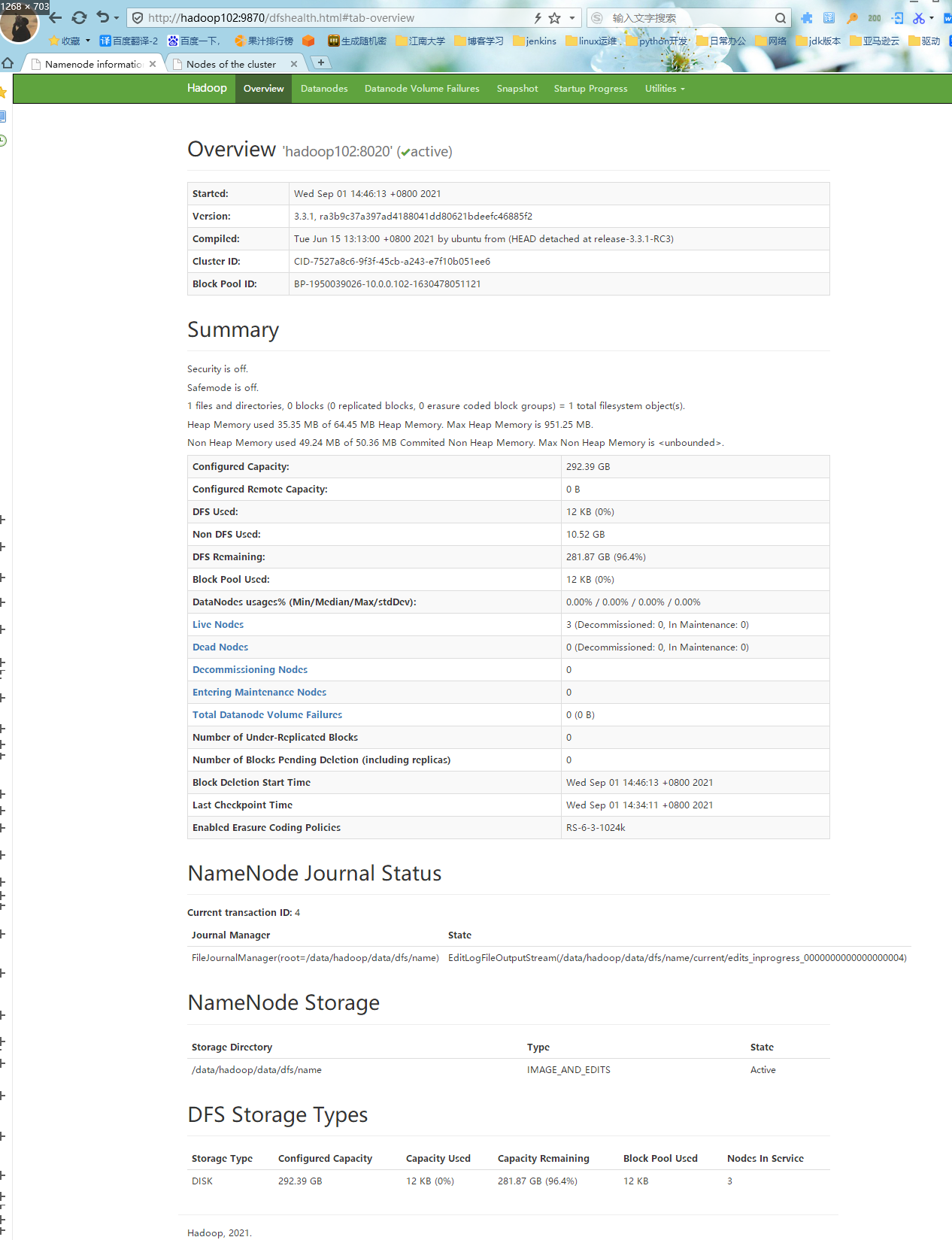
4.Web端查看HDFS的NameNode
#1.浏览器中输入:http://hadoop102:9870,下图可以看到Live Nodes:3,Disk:300G.
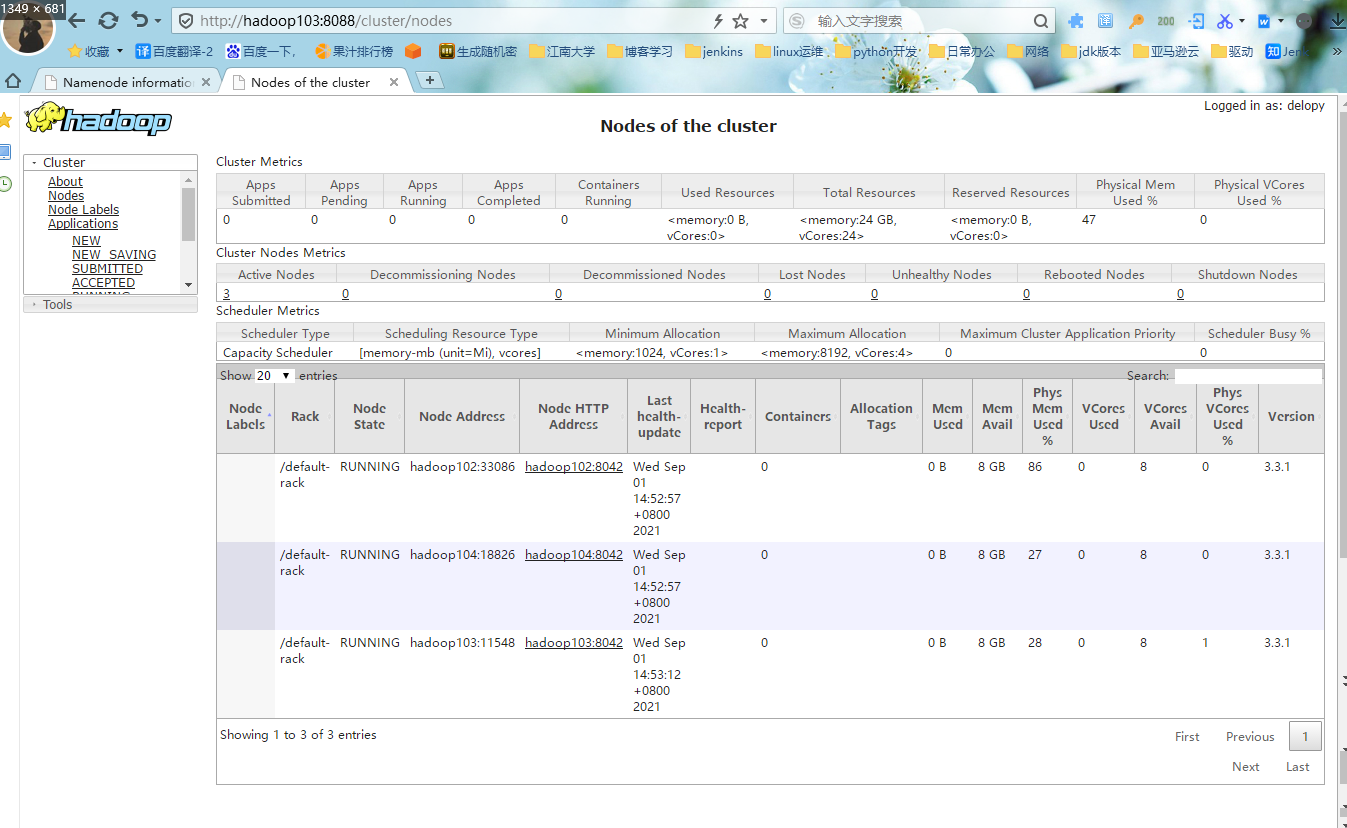
5.Web端查看YARN的ResourceManager
#1.浏览器中输入:http://hadoop103:8088,
八、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1.配置mapred-site.xml
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MapReduce程序运行在Yarn上</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
<description>历史服务器端地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
<description>历史服务器web端地址</description>
</property>
</configuration>
2.分发配置
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ xsync /opt/module/
3.启动历史服务器
#1.hadoop102启动历史服务器
[delopy@hadoop102 ~]$ mapred --daemon start historyserver
#2.查看历史服务器是否启动
[delopy@hadoop102 ~]$ jps
18800 NameNode
20133 Jps
18905 DataNode
19229 NodeManager
20077 JobHistoryServer
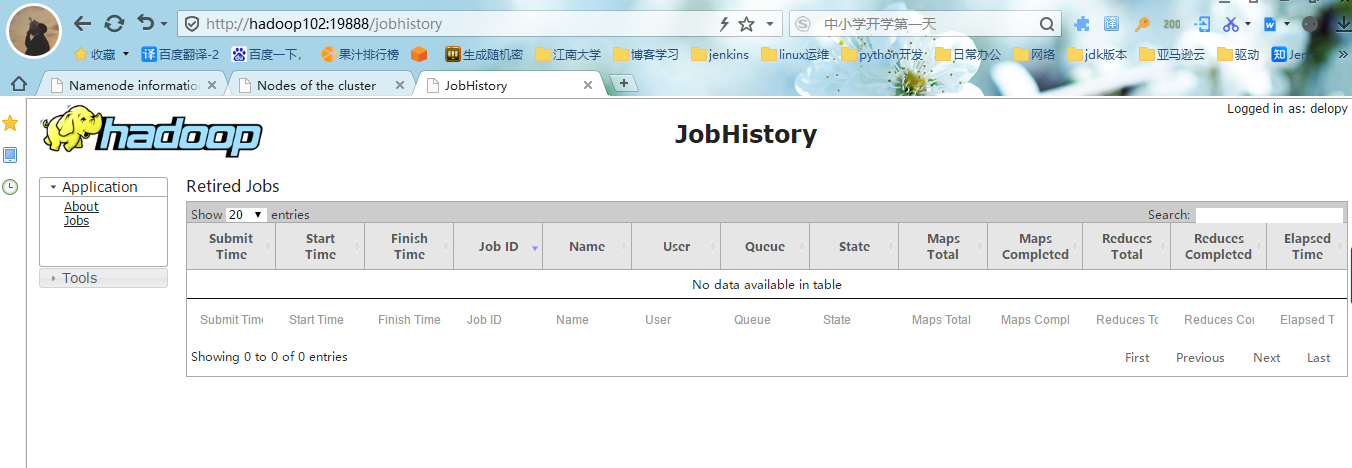
4.查看JobHistory
#1.浏览器输入:http://hadoop102:19888/jobhistory
九、配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
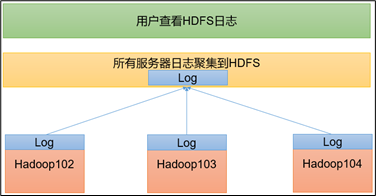
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
ps:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1.配置yarn-site.xml
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>指定MR走shuffle</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
<description>指定ResourceManager的地址</description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description>环境变量的继承</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚集功能</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
<description>设置日志聚集服务器地址</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<description>设置日志保留时间为7天</description>
</property>
</configuration>
2.分发配置
[delopy@hadoop102 /opt/module/hadoop/etc/hadoop]$ xsync /opt/module/
3.关闭NodeManager 、ResourceManager和HistoryServer
#1.在hadoop103执行操作
[delopy@hadoop103 ~]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
#2.在hadoop102执行操作
[delopy@hadoop102 ~]$ mapred --daemon stop historyserver
#3.查看hadoop启动状态
[delopy@hadoop103 ~]$ jps
16681 DataNode
21466 Jps
4.启动NodeManager 、ResourceManager和HistoryServer
#1.在hadoop103执行操作.关闭NodeManager、ResourceManager和HistoryServer
[delopy@hadoop103 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
#2.在hadoop102执行操作
[delopy@hadoop102 ~]$ mapred --daemon start historyserver
#3.查看hadoop启动状态
[delopy@hadoop103 ~]$ jps
21584 ResourceManager
16681 DataNode
21849 JobHistoryServer
21692 NodeManager
21903 Jps
十、集群功能测试
1.新建小文件
[delopy@hadoop102 ~]$ vim /data/software/1.txt
c 是世界上最好的语言!
java 是世界上最好的语言!
python 是世界上最好的语言!
go 是世界上最好的语言!
2.上传文件到Hadoop
[delopy@hadoop102 ~]$ hadoop fs -mkdir /input
[delopy@hadoop102 ~]$ hadoop fs -put /data/software/1.txt /input
3.执行wordcount程序
[delopy@hadoop102 ~]$ hadoop jar /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
2021-09-02 11:20:50,127 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop103/10.0.0.103:8032
2021-09-02 11:20:51,862 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/delopy/.staging/job_1630552034170_0001
2021-09-02 11:20:53,199 INFO input.FileInputFormat: Total input files to process : 1
2021-09-02 11:20:53,675 INFO mapreduce.JobSubmitter: number of splits:1
2021-09-02 11:20:54,787 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1630552034170_0001
2021-09-02 11:20:54,788 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-09-02 11:20:56,510 INFO conf.Configuration: resource-types.xml not found
2021-09-02 11:20:56,510 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-09-02 11:20:57,688 INFO impl.YarnClientImpl: Submitted application application_1630552034170_0001
2021-09-02 11:20:57,969 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1630552034170_0001/
2021-09-02 11:20:57,970 INFO mapreduce.Job: Running job: job_1630552034170_0001
2021-09-02 11:21:47,852 INFO mapreduce.Job: Job job_1630552034170_0001 running in uber mode : false
2021-09-02 11:21:47,854 INFO mapreduce.Job: map 0% reduce 0%
2021-09-02 11:22:12,655 INFO mapreduce.Job: map 100% reduce 0%
2021-09-02 11:22:54,276 INFO mapreduce.Job: map 100% reduce 100%
2021-09-02 11:22:56,374 INFO mapreduce.Job: Job job_1630552034170_0001 completed successfully
2021-09-02 11:22:56,735 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=545011
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=239
HDFS: Number of bytes written=58
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=19108
Total time spent by all reduces in occupied slots (ms)=39504
Total time spent by all map tasks (ms)=19108
Total time spent by all reduce tasks (ms)=39504
Total vcore-milliseconds taken by all map tasks=19108
Total vcore-milliseconds taken by all reduce tasks=39504
Total megabyte-milliseconds taken by all map tasks=19566592
Total megabyte-milliseconds taken by all reduce tasks=40452096
Map-Reduce Framework
Map input records=4
Map output records=8
Map output bytes=173
Map output materialized bytes=84
Input split bytes=98
Combine input records=8
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=84
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1328
CPU time spent (ms)=4710
Physical memory (bytes) snapshot=347209728
Virtual memory (bytes) snapshot=5058207744
Total committed heap usage (bytes)=230821888
Peak Map Physical memory (bytes)=223215616
Peak Map Virtual memory (bytes)=2524590080
Peak Reduce Physical memory (bytes)=123994112
Peak Reduce Virtual memory (bytes)=2533617664
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=141
File Output Format Counters
Bytes Written=58
[delopy@hadoop102 ~]$
4.web端查看测试结果
#1.进入HDFS的web界面,进入HDFS文件系统,
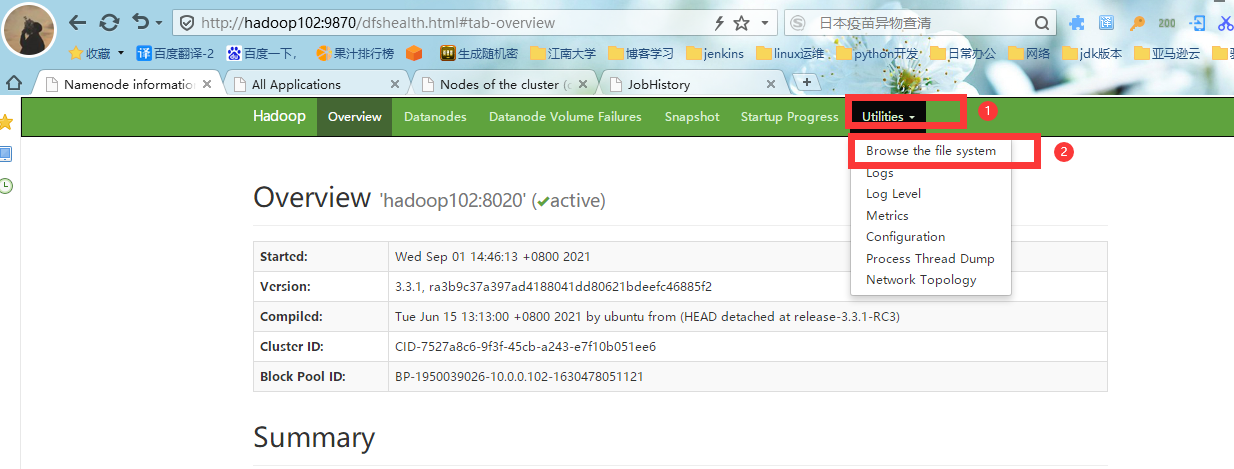
#2. 进入HDFS文件系统后,选择文件目录为/,可以看到我们三个目录:
input 为我们创建的目录
ouput 为我们导出执行结果的目录,执行程序会自动生成
tmp 为我们的临时目录

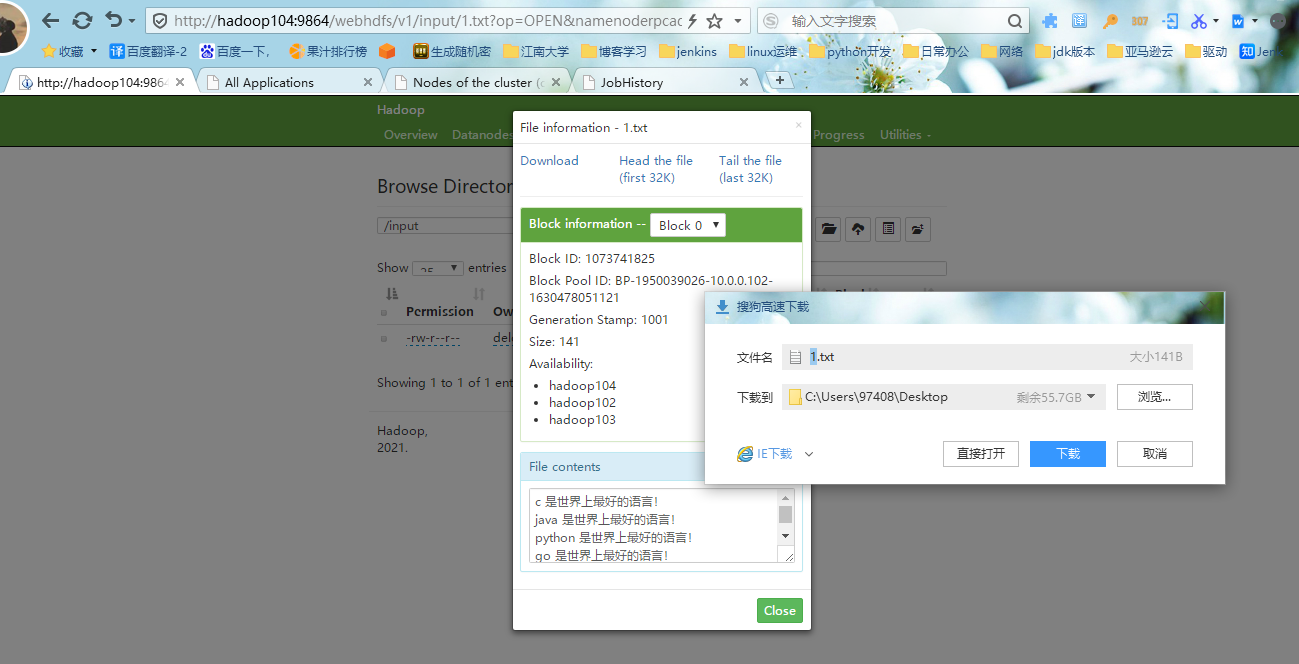
#3.首先点击input,进入我们的input目录,看到所在目录有我们推送的1.txt文件,点击这个文件可以下载和查看我们的文件信息

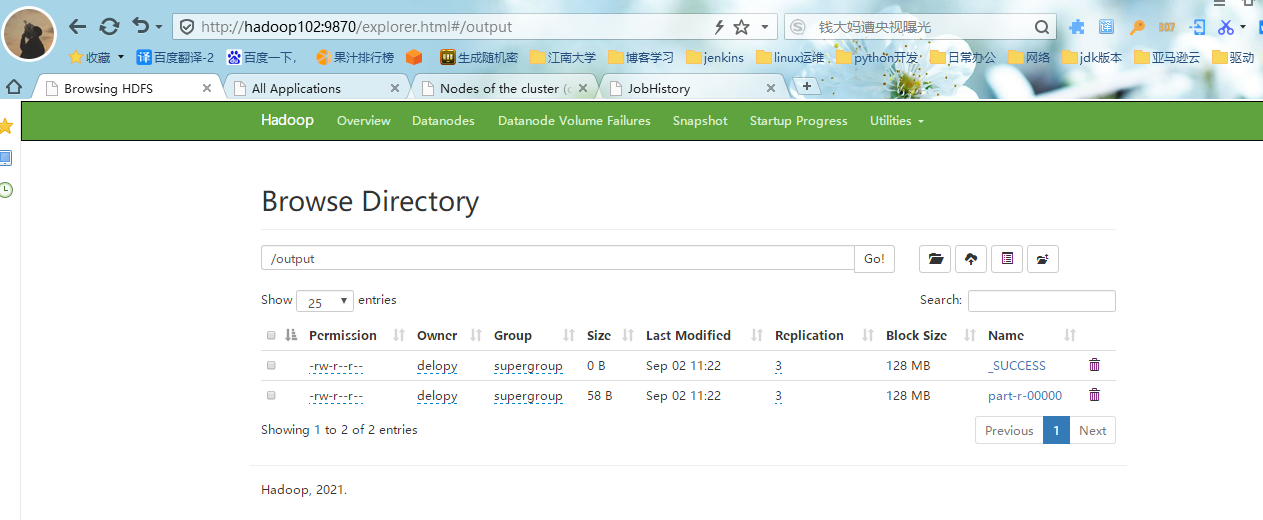
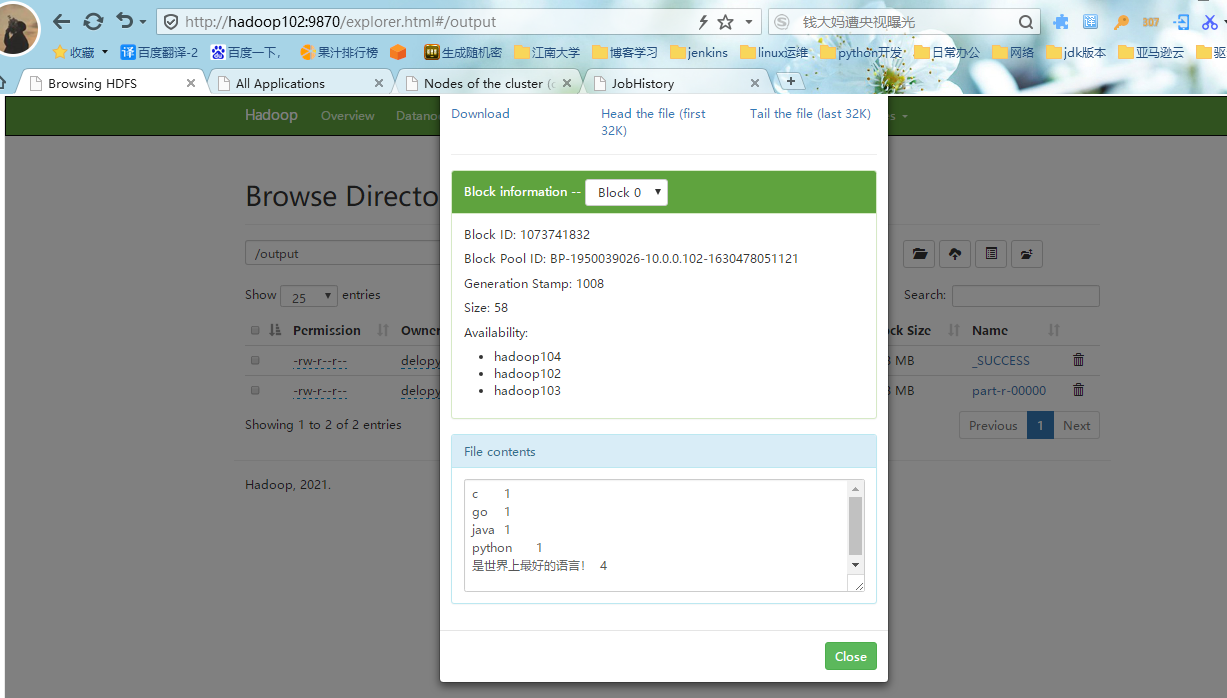
#4.退回到我们的/目录,点击output目录,可以看到以下两个文件,点击第二个文件,查看文件信息,可以看到每个词的出现的次数。
#5.进入yarn的web界面,点击Applications可以看到我们正在执行的job,最右边可以看到这个Job的执行进程是否结束。
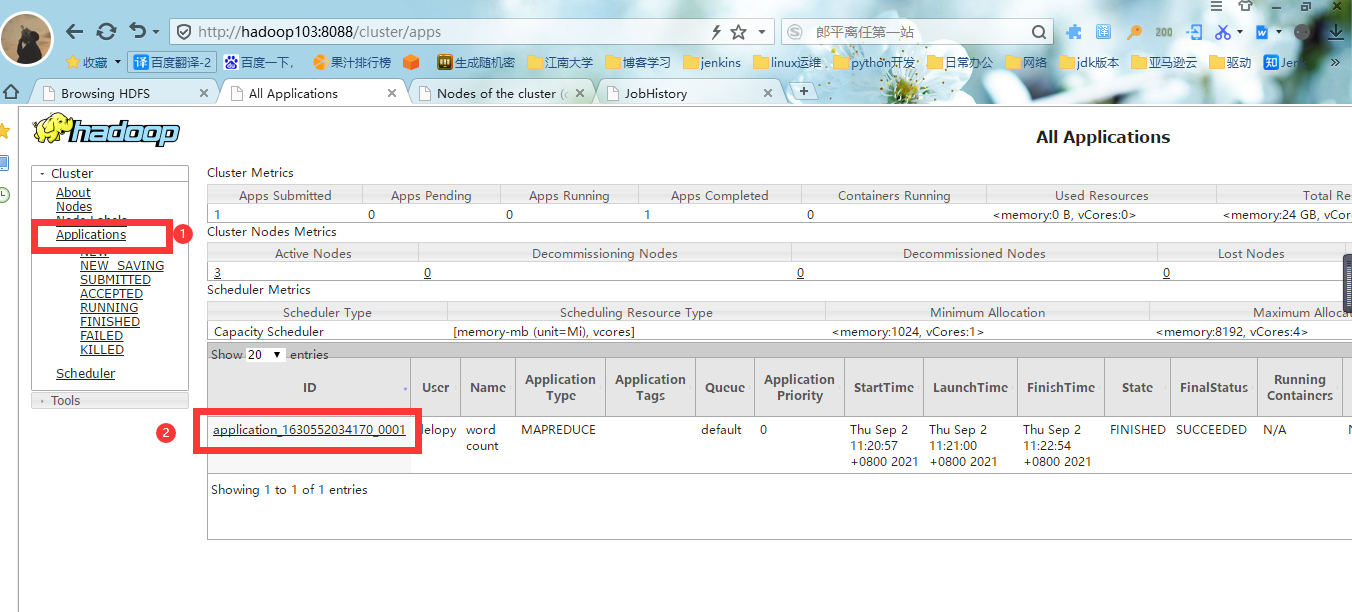
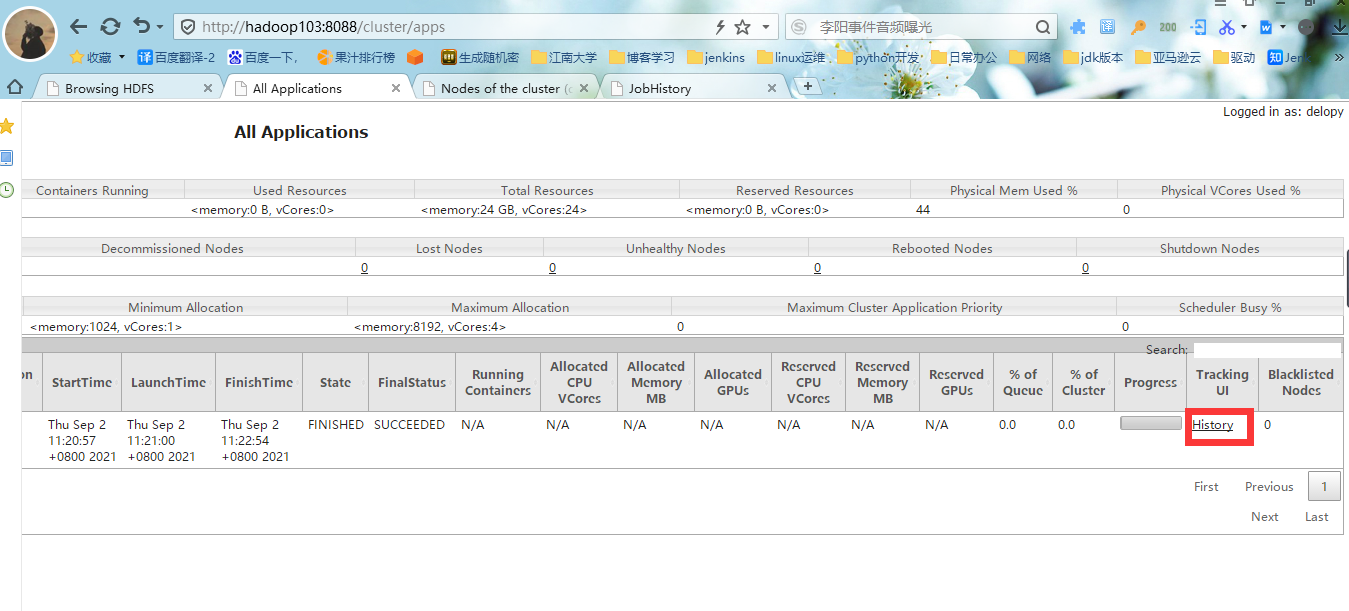
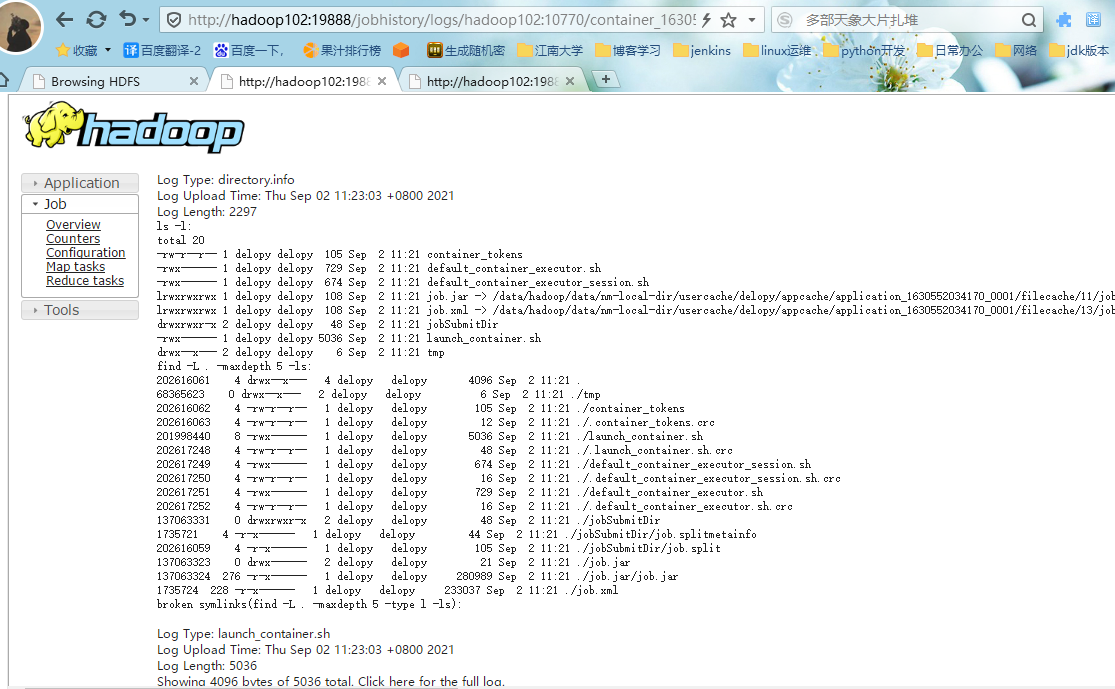
#6.点击yarn的job界面的history,进入历史服务器的web界面,点击logs查看任务运行日志

#7.查看运行日志详情,至此hadoop分布式安装基本完毕。
十一、集群启动/停止方式总结
1.各个模块分开启动/停止(配置ssh是前提)常用
#1.整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
#2.整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2.各个服务组件逐一启动/停止
#1.分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
#2.启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager

