深入学习页面优化之页面渲染原理
拾人牙慧理解并整理之
直奔主题,要考虑到页面性能优化,必须得理解浏览器的渲染机制才行。
1、原理
渲染引擎在这里就不展开了,可自行搜索解决。下面说说渲染流程,大致是这样的:
浏览器在接收到服务器返回的html页面后,
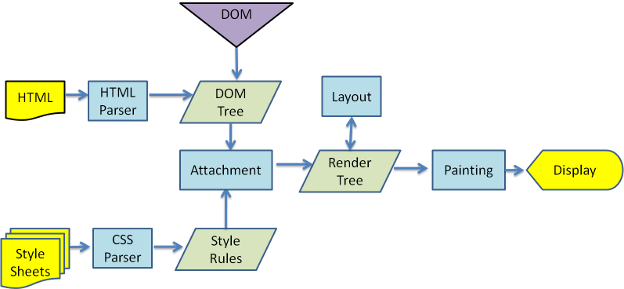
浏览器开始构建DOM TREE,遇到CSS样式会构建CSS RULER TREE,
遇到javascript会通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree,解析完成后,
浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree(渲染树),
最后,渲染树构建完成后就是” 布局“处理,也就是确定每个节点在屏幕上的确切显示位置。 下一个步骤是 绘制 —— 遍历渲染树并用UI后端层将每一个节点绘制出来。
用一张图来表示
另外,在构建相应的树形结构时,会发生阻碍:
在构建DOM树时,
- HTML的响应流被阻塞在了网络中
- 有未加载完的脚本
- 遇到了script节点,但是此时还有未加载完的样式文件
例子:
1 <html> 2 <body> 3 <link rel="stylesheet" href="example.css"> 4 <div>Hi there!</div> 5 <script> 6 document.write('<script src="other.js"></scr' + 'ipt>'); 7 </script> 8 <div>Hi again!</div> 9 <script src="last.js"></script> 10 </body> 11 </html> |
首先,解析器遇到了example.css,并将它从网络中下载下来。下载样式表的过程是耗时的,但是解析器并没有被阻塞,继续往下解析。接下来,解析器遇到script标签,但是由于样式文件没有加载下来,阻塞了该脚本的执行(上面已指出)。解析器(构建DOM TREE和 CSS RULER TREE)被阻塞住,不能继续往下解析。
同样的,因为渲染树是DOM Tree 和 CSS Rule Tree 来构造,所以此时,渲染树的构建也被阻塞,同时Hi there!也就 不能被绘制(painting->display)到页面中,
绘制的条件是,渲染树构建完成并遇到阻塞就会触发绘制。
接下来,一旦example.css文件加载完成,内联的脚本执行完之后,解析器就会立即被other.js阻塞住。一旦解析器被阻塞,浏览器就会收到绘制请求,"Hi there!"也就显示在了页面上。同理,当other.js加载完成之后,解析器继续向下解析,解析器遇到last.js之后会被阻塞,然后浏览器收到了另一个绘制请求,"Hi again!"就显示在了页面上。最后last.js会被加载,并且会被执行。
另外,CSS在页面的渲染上是从上到下,从右到左的机制,
例如,div#username p span.red{color:red;},浏 览器的查找顺序如下:先查找html中所有class=’red’的span元素,找到后,再查找其父辈元素中是否有p元素,再判断p的父元素中是否有id为 username的div元素,如果都存在则CSS匹配上。
例如如下代码:

1 <!DOCTYPE html> 2 <html> 3 <head> 4 <title></title> 5 <meta charset="utf-8"> 6 <style type="text/css"> 7 .red{ color:red; } 8 .blue{ color:blue; } 9 </style> 10 </head> 11 <body> 12 <p class="red blue">这是一段文字</p> 13 </body> 14 </html>
字体还是会显示为蓝色,

浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素。firefox称这种查 找方式为keyselector(关键字查询),所谓的关键字就是样式规则中最后(最右边)的规则,上面的key就是span.red。
所以在我们命名class类名的时候,尽量重用样式。
以上参考的资料有:浏览器的渲染原理简介
2、页面性能优化的方法:
把原理理解的差不多了再来看看常见的优化方法,
1、DOM结构不要复杂,不必要的标签坚决不要,例如:<div class="clearfix"></div>这样一个清除浮动的标签,虽然很好用,但是会增加浏览器的渲染,我们可以用别的方法代替啊,例如增加伪元素after,为了兼容IE67也是可以利用IE67的一些特有的属性来清除浮动的,比如zoom:1;是不是?
2、少引用css,js文件,少增加图片的请求次数,很常见的css sprites。
3、少用滤镜,少用hack,少用position:absolute;。
在这里我想问,为什么要少用绝对定位?为什么?请点这里详解
4、使用简写样式,如background,margin,padding等。
5、不要在ID选择器和class选择器前 使用标签名 例如:div.box { color: #f00; }; 直接 可以 用类名, .box { color:#f00;} 这样浏览器找到这个class后 就不用再匹配是否存在div标签.从而提高了渲染效率。当然同一级的 有不同的样式可以这样写,但是不建议这样。
6、css的层级关系不要太深 用class直接代替多余的层级元素。例如 .box .box-con .box-list li { line-height: 24px; } 这么长。。。增加代码量减小开发效率。刚也说了,css渲染是从上到下,从右到左的。所以直接这样写就可以了.box-list li { line-height: 24px; };
7、平铺背景图片不要过小,影响渲染速率。
8、float使用要谨慎。为什么这么说?这就得深入float了解了,自己接下来多了解了解吧。
最后,第一次比较认真的写文章,有点乱,无头无尾的,希望自己越写越好。
我想用这个来结束这篇文章,我觉得很生动的描述浏览器在接收到html后解析渲染出来的过程,此处引用。。。
1.用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件;
2.浏览器开始载入html代码,发现<head>标签内有一个<link>标签引用外部CSS文件;
3.浏览器又发出CSS文件的请求,服务器返回这个CSS文件;
4.浏览器继续载入html中<body>部分的代码,并且CSS文件已经拿到手了,可以开始渲染页面了;
5.浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码;
6.服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
7.浏览器发现了一个包含一行Javascript代码的<script>标签,赶快运行它;
8.Javascript脚本执行了这条语句,它命令浏览器隐藏掉代码中的某个<div> (style.display=”none”)。突然少了这么一个元素,浏览器不得不重新渲染这部分代码;
9.终于等到了</html>的到来,浏览器泪流满面……
10.等等,还没完,用户点了一下界面中的“换肤”按钮,Javascript让浏览器换了一下<link>标签的CSS路径;
11.浏览器召集了在座的各位<div><span><ul><li>们,“大伙儿收拾收拾行李,咱得重新来过……”,浏览器向服务器请求了新的CSS文件,重新渲染页面。
此处参考:
 声明:码字不易,请注重别人的劳动果实,转载请注明该文章来源:http://www.cnblogs.com/jhmydear/
声明:码字不易,请注重别人的劳动果实,转载请注明该文章来源:http://www.cnblogs.com/jhmydear/
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步