Python破解-图形验证码
前言
写爬虫有一个绕不过去的问题,那就是验证码,比如像某乎,如果不先登陆,连里面的内容数据都爬不到,而验证码就是网站进行发爬虫的一种措施,随着技术的发展,验证码越来越复杂,爬虫的工作越来越艰苦,所以这次就来讲解,怎么来识别验证码;(听上去口气很大的感觉)

先来看看,目前遇到的验证码种类有哪些?
1)图形验证码
图形验证码应该是最简单的一种验证码,这种验证码是最早出现,也是目前最常见的,一般组成规则是4个字母或数字或混合组成;

2)滑动验证码
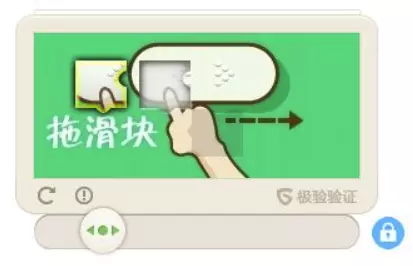
3)点触验证码


Ok,上面这3种验证码方式,应该是目前PC上比较常见的验证码种类的,当然手机app上还会有手势验证,宫格验证,语音验证等等,这里就不介绍,主要针对上面常见的3种介绍;
1 图形验证码
某乎的验证码有2种,一种是图形验证码,一种是点触验证码,经过测试发现,一开始是显示图形验证码,但当登陆退出次数逐渐增多,就会变成点触验证码,这种验证码的切换机制,也算是防爬虫的一种手段,闲话不多说,先喵喵:
某乎链接:知乎 - 有问题,就会有答案
打开后默认是在注册页面,点击下登陆按钮,如果还是没有验证码,刷新几次网页就行了;
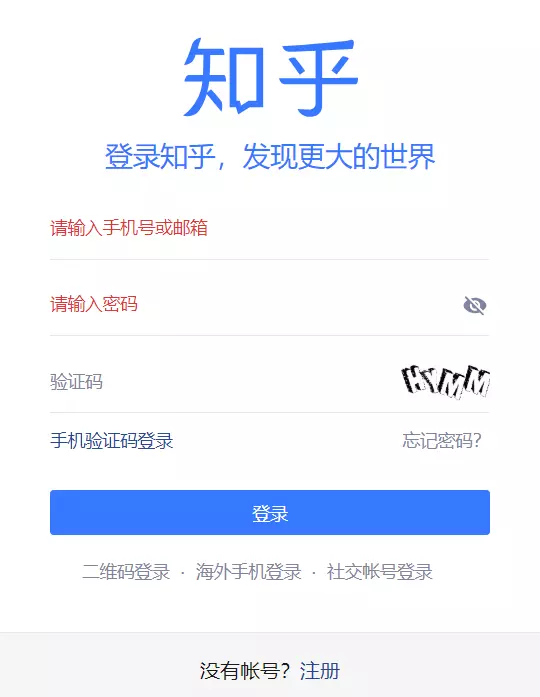
下面这种,下2篇文章会介绍;
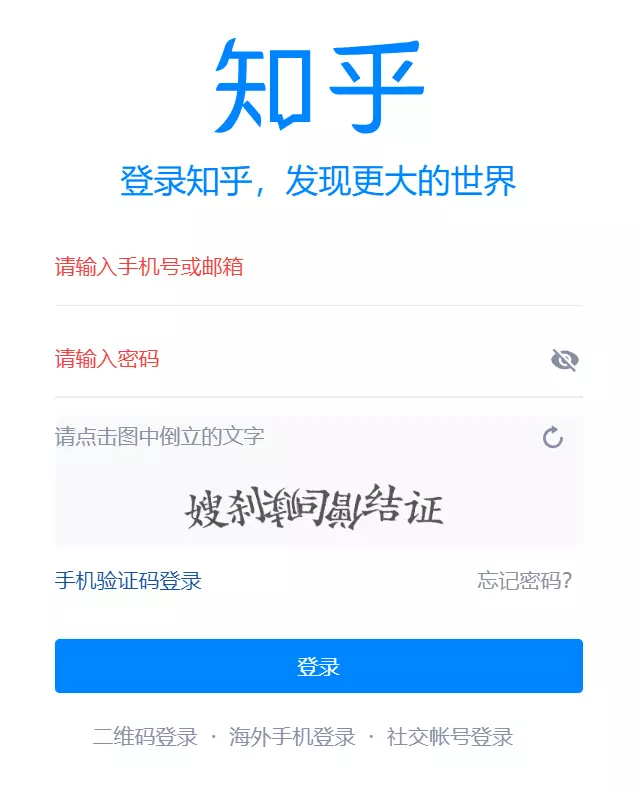
2 信息介绍
识别图形验证码需要安装tesserocr这个库,下面介绍下tesserocr;
tesserocr是Python的一个OCR识别库,但其实是对tesseract做了一层Python Api的封装,
核心还是tesseract,所以在安装tesserocr之前,需要先安装tesseract;
等下,懵逼中,tesserocr这个能看明白,是一个库,但OCR是什么?tesseract又是什么?
OCR
OCR,全称叫 Optical Character Recognition,中文翻译叫光学字符识别,是指通过扫描字符,通过其形状将其翻译成电子文本的过程;
举例:
当有一个图形验证码,先使用OCR技术将其转化成电子文本,然后爬虫将识别的结果提交到服务器,便达到自动识别验证码的过程;
tesseract
tesseract是google开源的OCR
OK,貌似对概念有所理解了,还有个疑问,之前有在图形识别领域,还有个opencv的玩意,那这两者有什么区别?
opencv专注机器视觉
tesseract专注字符识别
所以从领域来说,opencv更广,而图形验证码,opencv也可以做,但杀鸡焉用牛刀~
3 环境准备
windows下的安装
在Windows下,要先下载tesseract,它为tesserocr提供了支持;
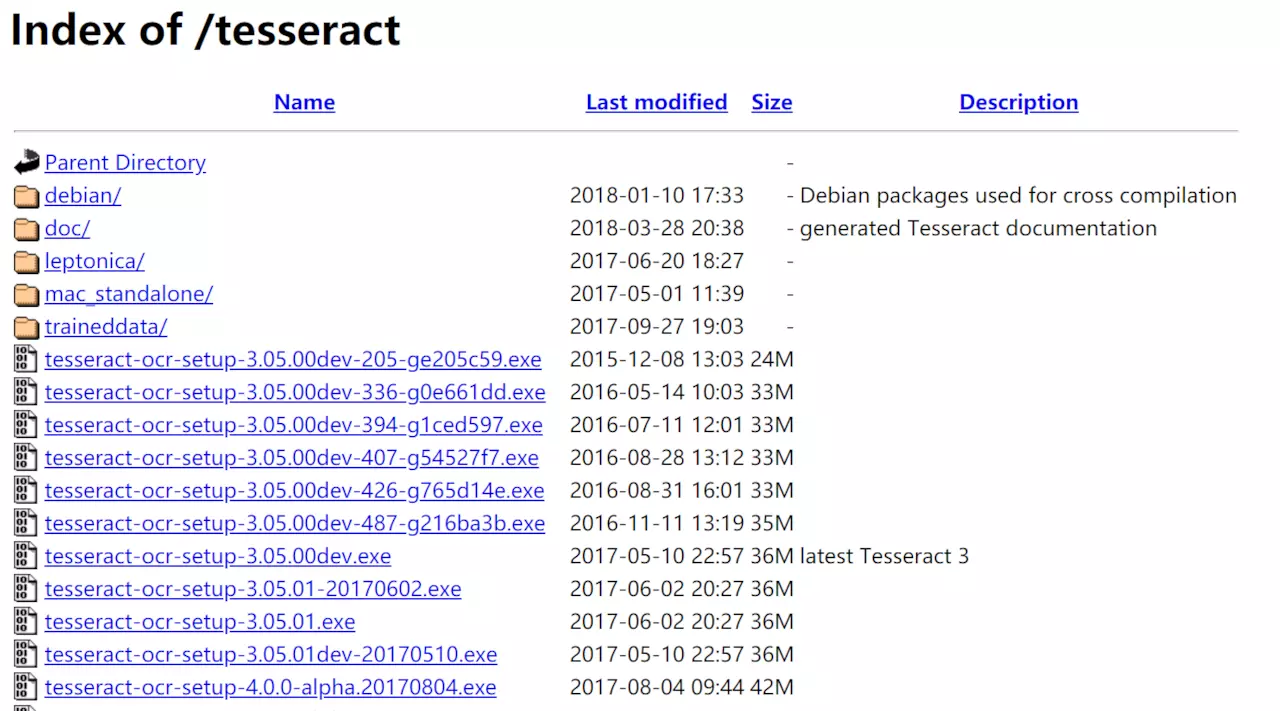
tesseract下载地址:Index of /tesseract
打开后,可以看到各种exe的列表,可以随便挑选;
其中文件名中带有dev的为开发版本,不带dev则为稳定版本,例如jb是下载 tesseract-ocr-setup-3.05.01.exe;
下载后双击,一路点击,直到出现下面这个页面
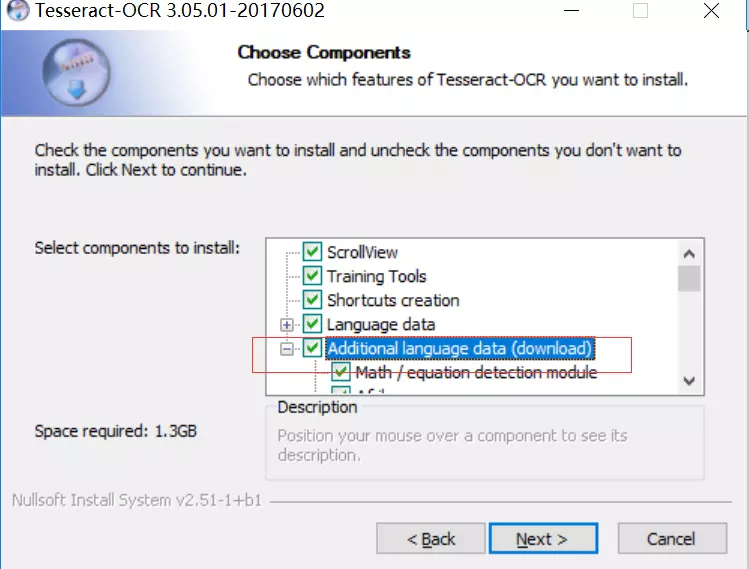
这里需要勾选红框里的Additional language data(download),这个选项是安装OCR识别支持的语言包,这样OCR就可以识别多国语言,然后再一路点击NEXT即可,因为要下载语言包,所以需要点时间,大概10-20分钟左右,跟网速有关,如果不需要支持多国语言的话,也可以不勾选,自由选择
需要说明:默认包含英文字库
如果,觉得一次下载那么多语言占空间,又或者觉得网速慢,也可以选择单独安装中文字库;
字库下载地址:https://github.com/tesseract-ocr/tessdata
打开后,直接搜索chi_sim.traineddata,这个代表的就是中文,下载下来;
然后找到刚刚tesseract安装目录,里面会有一个叫tessdata的目录,直接把刚下载的语言包放到这个目录下即可;
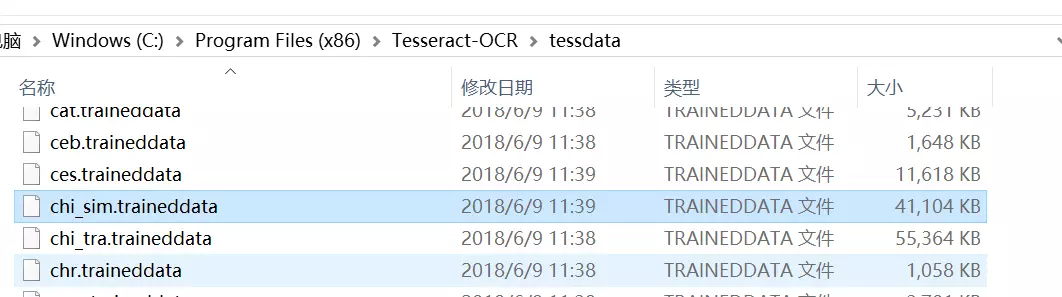
如何验证tesseract是否安装成功?直接cmd下输入tesseract即可;
成功会直接显示信息;
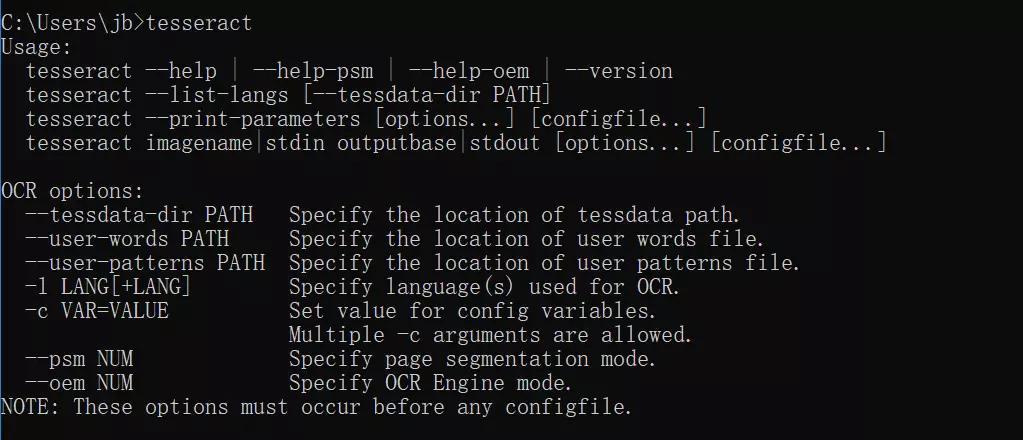
如果提示'tesseract' 不是内部或外部命令,则是因为没有配置环境变量,手动把tesseract根目录配置到path参数下即可,这块不详细说明;
到此为止,tesseract安装成功啦~
接下来就安装tesserocr,直接pip命令即可:
pip3 install tesserocr install
但jb在安装的时候,直接报错:

试过很多种方式,就算使用conda install tesserocr,也一样报错。
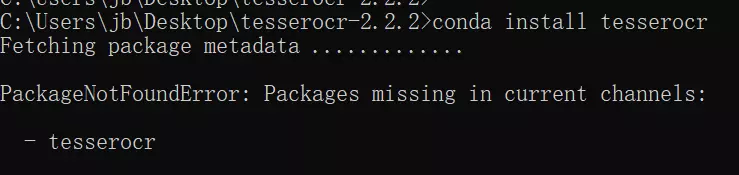
经历千辛万苦,终于找到一条可行的命令:
conda install -c simonflueckiger tesserocr
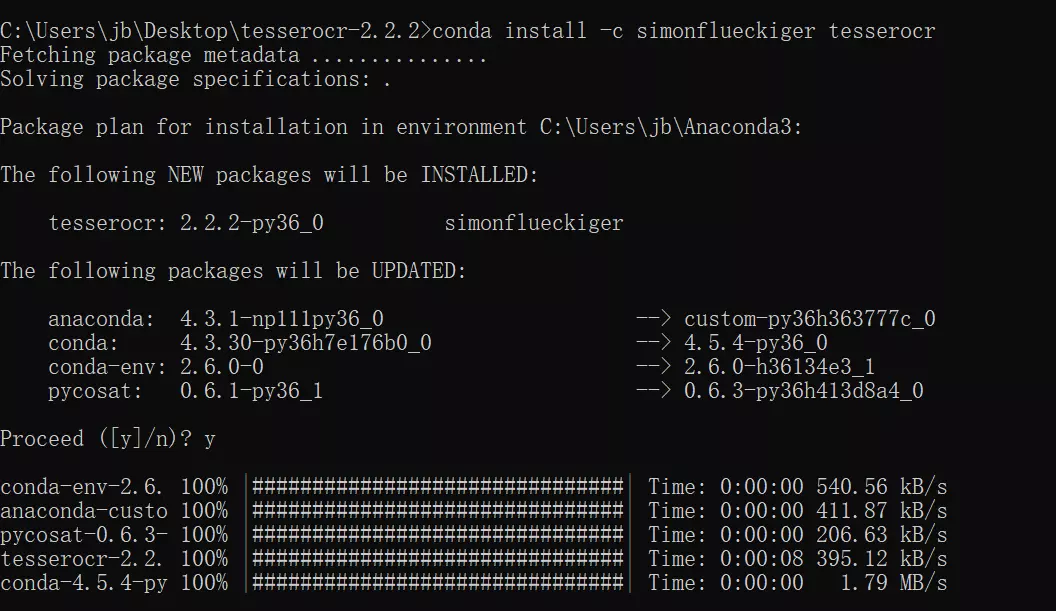
最终就安装上tesserocr啦~
如何验证是否真的安装了?很简单,直接import tesserocr,不报错就说明安装好了;

对了,如果有同学不知道conda这条命令的话,请访问下面的链接,直接搜索scrapy安装,会有介绍conda:
https://juejin.im/post/5afcb91251882565bd257097|
OK,windows下的tesserocr跟tesseract的环境已经安装好了;
别着急,顺便介绍下Linux跟Mac,但以下方式均未经过jb验证,信息来源于网上,仅供参考:
Linux下的安装
对于Liunx来说,不同系统已经有了不同的发行包了,它可能叫做tesseract-ocr或者tesseract,直接用对应的命令安装即可;
-
Ubuntu、Debian和Deepin
在Ubuntu、Debian和Deepin系统下,安装命令如下:sudo apt-get install-y tesseract-ocr libtesseract-dev libleptioica-dev -
CentOS、Red Hat 在CentOS和Red Hat系统下,安装命令如下:
yum install -y tesseract
在不同发行版本运行如上命令,即可完成tesseract的安装;
安装完成后,便可以调用tesseract命令;
默认也是指安装英文语言,如果需要安装其他语言,请看下上面Windows的介绍,一样的处理方案,这里不重复说明;
接下来就是安装tesserocr,直接使用pip安装:
pip3 install tesserocr pillow
Mac下的安装
在Mac下,首先使用Homebrew 安装ImageMagick 和tesseract库:
brew install imagemagick
brew install tesseract --all-languages
接下来再安装tesserocr即可:
brew install tesserocr pillow
4 识别测试
为了方便测试,需要把验证码的图片保存到本地;
打开weibo.com,随便输入账号密码,会提示输入验证码,打开开发者工具,找到验证码元素,它的src属性就是一个链接,copy出来直接打开,会看到一个验证码,而且刷新的验证码会变化,由此推断这是个验证码的接口,右键保存验证码即可,就得到一张验证码;
验证码链接:
https://login.sina.com.cn/cgi/pin.php?r=9967937&s=0&p=gz-d0dc363f6a4523cbd602a5a10f00c59b4784

ok,完事具备,那就开始吧,新建项目,把验证码放到项目根目录下;
用tesserocr库来识别验证码:
import tesserocr
from PIL import Image
#新建Image对象
image = Image.open("3.jpg")
#调用tesserocr的image_to_text()方法,传入image对象完成识别
result = tesserocr.image_to_text(image)
print(result)
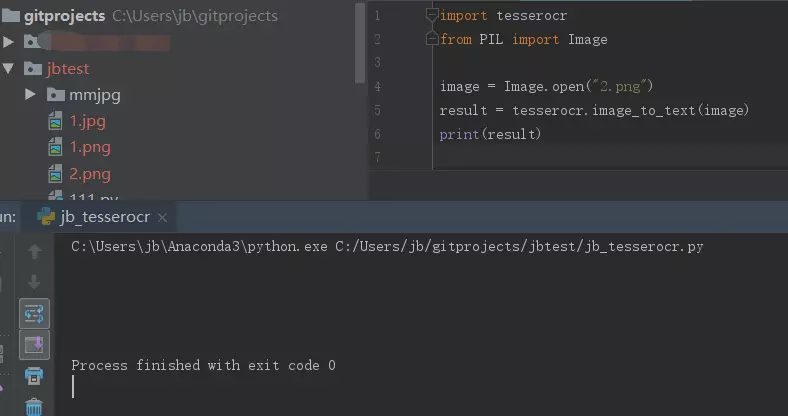
结果,运行后,啥都没有???
接下来jb陷入了困扰,包括调试,找各种文档,最终,把上面调试的验证码换了一个:

替换下图片,再执行一次代码:
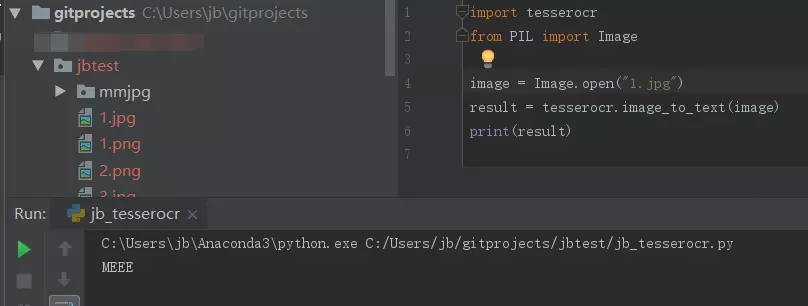
OK,看到是有数据了,不过输出的是MEEE,跟验证码的ME8E还是有点不一样;
目前两个问题:
1)微博的验证码识别失败,输出空
2)第二章验证码部分词识别有误
心想,这库是网上都推荐用的,是Google开源的,理论上没问题,而且人家也都这么用,为什么这里就有问题?难道还需要额外的处理?
怀着疑问跟梦想,继续学习;
题外话: tesserocr还有一个更加简单的方法,这个方法可直接将图片文件转换成字符串,代码如下:
import tesserocr
print(tesserocr.file_to_text("1.jpg"))
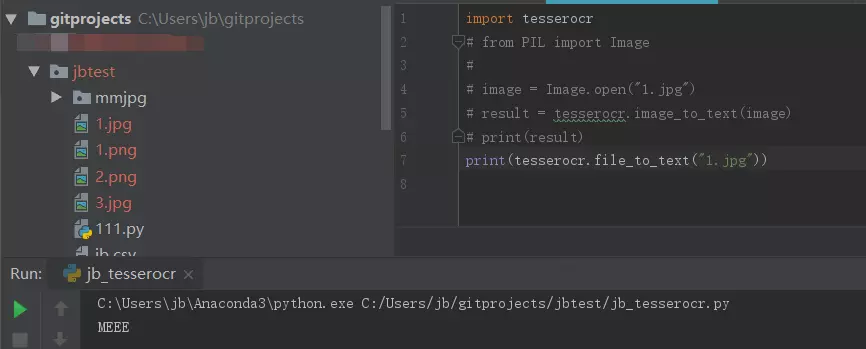
结果也跟上面的一样,但网上不建议这么用,原因是据说这种识别效果不如上一种的好;
关于微博验证码为空,使用tesseract输出下原因:
tesseract 图片路径 output

leptonica 在解析时没有检测到任何dpi;
5 验证码处理
网上找了下信息,比如这张验证码:

可能是验证码内的多余线条干扰了图片的识别;
又比如微博这张:

可能是字体位置,跟图案等因素干扰了图标的识别;
解决方案还是有的,需要对图片进行额外的处理,如转灰度,二值化等操作;
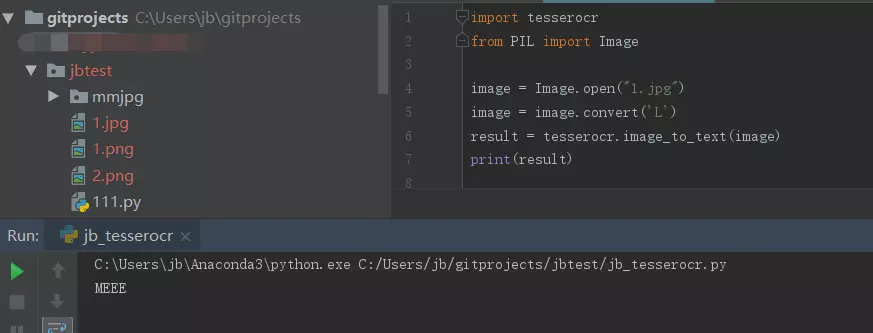
转灰度处理: 利用Image对象的convert()方法参数传入L,即可将图片转成为灰度图像:
from PIL import Image
image = Image.open("1.jpg")
image = image.convert('L')
image.show()

图片成功转灰了;此时我们再校验一下,发现校验还是MEEE,失败;
传入1的后,即可将图片进行二值化处理:
(二值化是指将图像上的像素点的灰度值设置为0或255,也就是将整个图片呈现出明显的只有黑和百的视觉效果)
import tesserocr
from PIL import Image
image = Image.open("1.jpg")
image = image.convert('1')
image.show()

这个一看,比上面更模糊了,理所当然的,校验结果会错的更加离谱:

二值化的阈值是可以指定的,上面的方法采用的是默认阈值127;但一般很少直接转换原图,原因如上可看到,错误的更加离谱了;
一般是先将原图转为灰度图像,然后再指定二值化的阈值,代码如下:
import tesserocr
from PIL import Image
#新建Image对象
image = Image.open("1.jpg")
#进行置灰处理
image = image.convert('L')
#这个是二值化阈值
threshold = 150
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
#通过表格转换成二进制图片,1的作用是白色,不然就全部黑色了
image = image.point(table,"1")
image.show()
result = tesserocr.image_to_text(image)
print(result)
这里说明下,可能有同学对256不明白,这是什么?
首先,我们是把图片置灰处理,灰度图像是一种具有从黑到白256级灰度色阶或等级的单色图像;
对于灰度图像利用阈值得到二值化的图像, 也就是说,我们设定了一个阈值,从0到256,如果灰度图像少于阈值则设置0,大于阈值则设置1,0是黑色,1是白色,这样做,就可以把一个灰度图完全转换二值化图;
可能还是懵逼,直接贴图:
原图

灰度图:

二值图:

在灰度图上,部分色彩是介于白色跟黑色之间,所以通过设置阈值的方法,把这些中间色彩全部转换成黑色跟白色;
ok,扯远了,上面把验证码二值图后是长这样的:

而校验结果:
good,有所变化, 至少不是MEEE了,那我们继续调,调到一个合适的值;
调了半天,jb放弃了,原因是这个8,不管怎么调都调不到一个合适的值,一直在S、R、B之间徘徊;
JB换了个验证码:

上面同样的代码,无修改,二值图如下:

校验结果:

oh year,这个能校验出来了~
还记得我们一开始那个微博验证码吗?我们也来试试,处理后的验证码是这样的~

结果校验的时候,基本上都空,只有在138的时候会有一点点识别效果,但是压根不搭边;
对比了下,微博验证码跟上面能识别的验证码:


能别识别的,是实心,而不能被识别的,是空心;
实心的好处在于,图像处理后,黑白分明,但是空心在图像处理后,由于线条本来就很细,处理后可能都识别不出来了;
6 小结
本章学习了tesserocr及tesseract的环境搭建,以及如何对图形验证码进行噪音处理,并且讲解灰色图跟二值图的概念;
7 疑难杂症
实际发现,tesserocr仅能解决实心的验证码,对于空心的验证码,依然束手无策,那怎么办呢?
既然图像识别存在误差,那我们就放弃这条路,而是通过其他的方式来获取这个验证码;
比如直接找到生成这验证码的代码二次转化获取验证码,深度学习训练机器识别;
更多Python视频、源码、资料加群531509025免费获取
作者:jb
转载至:掘金
结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!
Python基础入门教程推荐:更多Python视频教程-关注B站:Python学习者
【Python教程】全网最容易听懂的1000集python系统学习教程(答疑在最后四期,满满干货)
Python爬虫案例教程推荐:更多Python视频教程-关注B站:Python学习者
2021年Python最新最全100个爬虫完整案例教程,数据分析,数据可视化,记得收藏哦
本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16766970.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号