Python敏感地址扫描和爬取工具
为了方便信息安全测评工作,及时收集敏感地址(初衷是爬取api地址),所以写了这么个小工具。两个简单的功能(目录扫描和url地址爬取)。
0×01 说明:
为了方便信息安全测评工作,及时收集敏感地址(初衷是爬取api地址),所以写了这么个小工具。两个简单的功能(目录扫描和url地址爬取)。
0×02 使用参数:
python spider.py -u url -s api -o output.txt -t thread_number #通过爬虫
python spider.py -u url -s dir -f dict.txt -o output.txt #通过目录扫描
0×03 部分函数说明:
防止因末尾斜线、锚点而重复爬取(http://www.example.com、http://www.example.com、http://www.example.com/index.html#xxoo)

爬取规则:
第一个无法爬取页面注释中的地址(<!–http://example.com/index.html–>),第二个无法爬取相对路径和php?id=等类型的地址,古结合两种规则,并排除图片视频类的地址,最后再去重
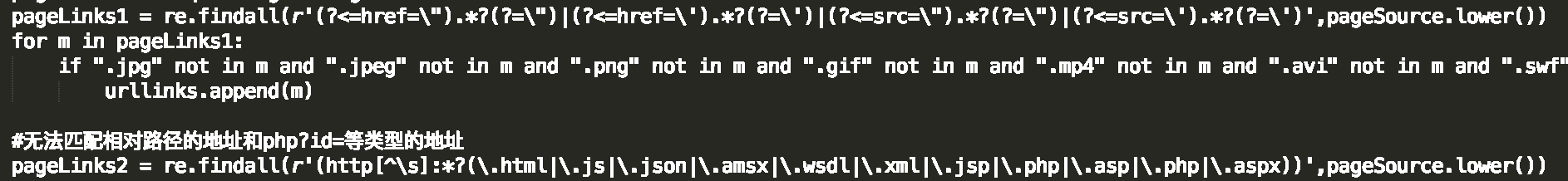
补全相对地址、防止越界(可爬取子域名,其他地址除外),并验证地址是否能正常访问
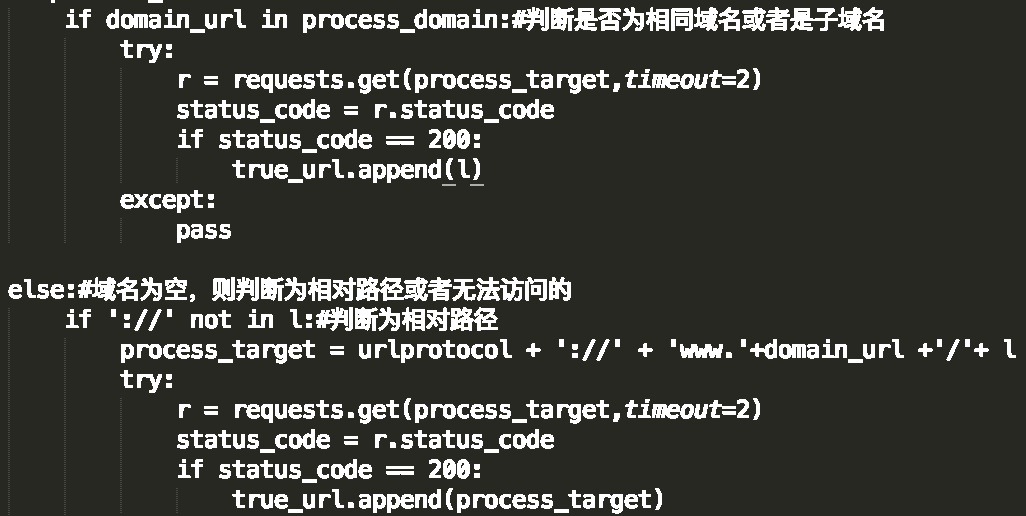
地址池
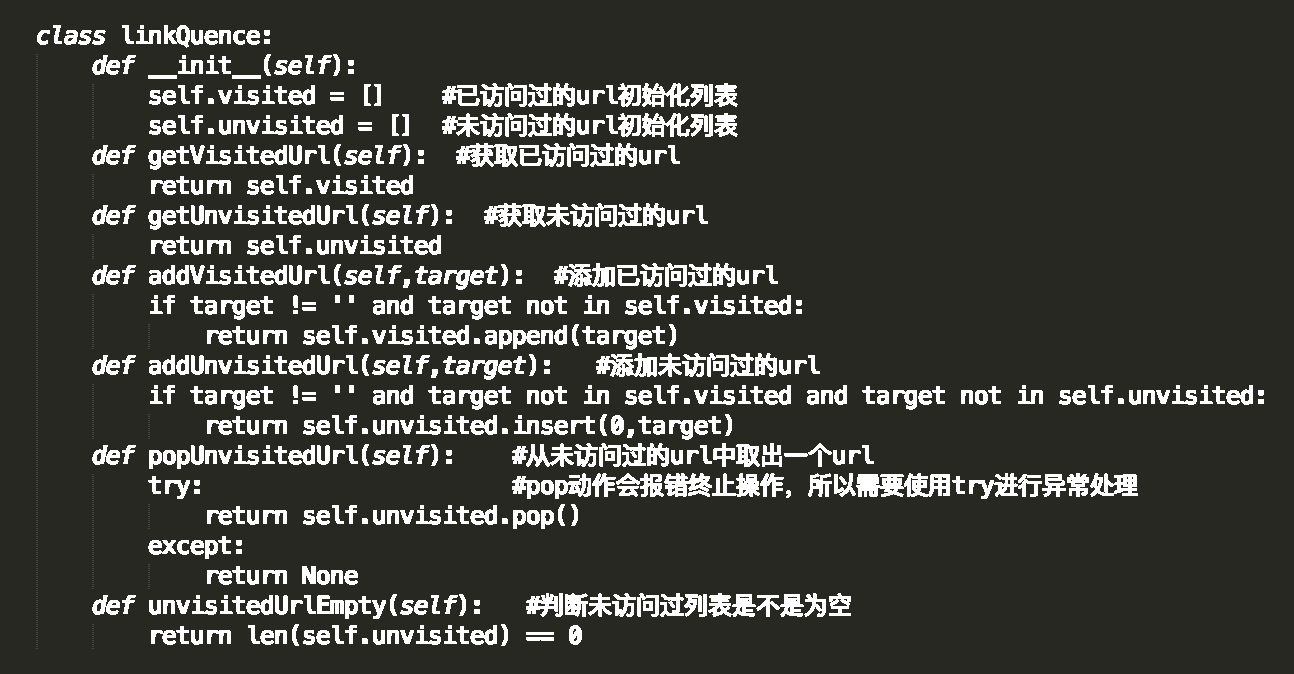
爬取功能,虽然使用了多线程,但还是比较慢,输出结果是爬取完毕的地址

目录扫描和输出到文件

0×04 代码地址:
https://github.com/silience/spider
0×05 参考链接:
#http://blog.csdn.net/foryouslgme/article/details/52242653
更多Python视频、源码、资料加群683380553免费获取
本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16766915.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号