
用python进行列联表卡方检验
转自:https://zhuanlan.zhihu.com/p/42470566
前天在看书的时候第一次看到了列联表卡方检验,觉得这个东西不难又相对容易实现,刚好知乎上有个老哥的文章是用R来实现卡方检验,于是借用他的数据,我在spyder上面实现了。
这是一份手游数据,里面是某手游2013年8-9月的用户登录数据以及用户数据库数据。这是为了查看到底是什么因素使得8-9月的登录次数骤减。为了看到底是什么因素会影响,首先会想到方差分析、相关性矩阵,还有卡方检验。
首先卡方检验是针对自变量和因变量都是分类数据,也就是说带有属性的数据;而单因素方差分析是自变量是分类数据,因变量是连续型的数据。还有一点:方差分析是参数检验,而卡方检验是属于非参数检验。
到底列联表的卡方怎么做呢?
卡方检验是用途非常广的一种 假设检验方法,它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的 相关分析等。
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。注意:卡方检验针对分类变量
当然是要进行假设检验啦:

更多Python视频、源码、资料加群683380553免费获取
根据度娘的图:
1、括号里面是根据观测值的概率来推算出来的理论值,或者叫期望值。
2、最下面和最右面是分别在不同分类数据下的求和,右边那列的和下边的和怎么都等于200
3、概率和理论值怎么算呢:
4、我们把理论值都直接放进去表格里面,卡方的公式: 其中A是实际值,T是理论值。
5、最后根据得出的卡方值查表便可求得结果。
回归本题:
在spyder里面实现
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
os.chdir('./新建文件夹')
user_database = pd.read_csv('./user_database.csv',encoding='utf-8',sep=',')
user_login = pd.read_csv('./user_login.csv',encoding='utf-8',sep=',')
#是否有空值
udba_na = np.sum(user_database.isnull().sum())
ulg_na = np.sum(user_login.isnull().sum())
print(udba_na,'-----\n-----',ulg_na)
if udba_na == 0 and ulg_na == 0:
print('进行下一步')
else:
print('再检查')
以上是 常规操作
#merge
new_df = pd.merge(user_login,user_database,how='left',on='user_id')
new_df.drop(['app_name_x','app_name_y'],axis=1,inplace=True)
new_df.log_date = pd.to_datetime(new_df.log_date)
#merge成功之后,进行探索性分析
#8-9月之间登陆次数是否有异常
logdf = new_df.groupby(['log_date']).count()['user_id']
logdf.plot(figsize=(20,10),legend=True,fontsize=20,
label = '用户数',linewidth =2,colormap = 'BrBG_r',marker='o',
alpha=0.6,linestyle='--',grid=True)
plt.legend(fontsize=20)
plt.title('8-9月登陆用户数趋势图',fontsize=20)
plt.grid(which='y',linestyle='--',color='grey',alpha=0.8)
#明显整体趋势走弱,最大断崖式下跌9月10-11-12日
这里首先进行merge,因为是两个文件,采用的是left join的形式,和SQL一样。然后根据图像进行分析。
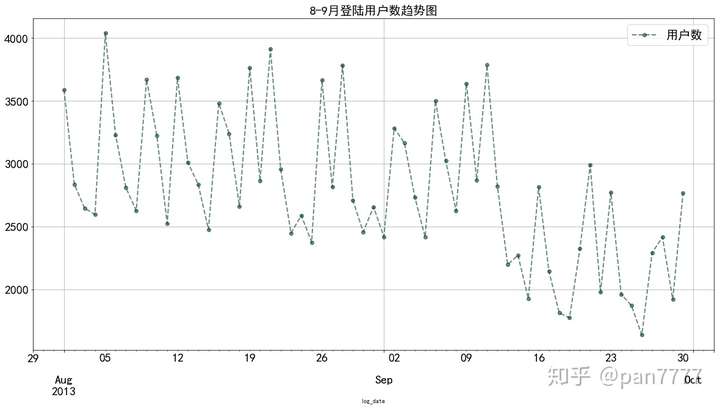
整体趋势向下走,在9月初一下子降得有点严重。
进一步分析为什么会这样
#8-9月月活跃玩家整体下降
new_df.index = new_df.log_date
new_df['log_month'] = new_df.index.month
这里先把月份提取出来,因为做卡方检验需要分类数据
这里我写了3个自定义函数,是为了输出报告
#看哪几个因素有影响
#主因素 月份 其他因素:年龄段,性别,设备
#自定义函数,做卡方检验
def colu(df,col):
uni = df[col].unique().tolist()
return uni
def observe(df,subcol,maincol):
d = []
lst1 = colu(df,subcol)
lst2 = colu(df,maincol)
for l in lst1:
for ls in lst2:
b = len(df[(df[subcol] == l)&(df[maincol]==ls)])
d.append(b)
return d
def split_array(df,subcol,maincol):
result_lst = []
lst = observe(df,subcol,maincol)
for j in range(0,len(lst),len(colu(df,maincol))):
result = lst[j:j+len(colu(df,maincol))]
result_lst.append(result)
result_lst = np.array(result_lst)
return result_lst.T
def chi(array):
#计算理论值
#main = np.sum(array,axis=1)
#sub = np.sum(array,axis=0)
sum_ = np.sum(np.sum(gender_month))
#理论值:
#expectation_value = sum_*(main/np.sum(main))*(sub/np.sum(sub))
#expectation_value1 = sum_*(1-main/np.sum(main))*(sub/np.sum(sub))
if sum_ > 40:
print('样本量大于40')
chi,p,v,exp = stats.chi2_contingency(array,correction=False)
else:
print('样本量小于40')
chi,p,v,exp = stats.chi2_contingency(array,correction=True)
print ('''
====================================================
报告
χ2值:{}
p值:{}
自由度:{}
理论值:
{}
====================================================
'''.format(chi,p,v,exp))
if p > 0.05:
print('不拒绝原假设,无充分证据表明两个因素之间存在关系,即可认为该因素不影响登陆次数')
else:
if p < 0.05:
print('显著性水平α=0.05下,拒绝原假设,充分相关,建议作图分析做进一步判断到底是因子里面哪个因素起作用')
elif p < 0.01:
print('显著性水平α=0.01下,拒绝原假设,显著相关,建议作图详细分析')
return (chi,p,v,exp)
总的思路就是,先把属性提取出来,然后循环遍历把对应的数据总量算出来,最后转换为numpy.array格式,根据scipy的stats里面的chi2_contingency方法做相关性检验,里面有个参数叫correction,是连续性修正,默认True,这是因为理论值全部小于5,且样本量小于40或者样本量大于40有一格或几格的理论值小于5的时候就要用这个修正。
#性别和月份检测:
#返回的是转置后的二维数组,index分别是月份,columns名是M,F
gender_month = split_array(new_df,'gender','log_month')
print('--------------------性别和月份------------------------\n')
chi(gender_month)
print('------------------------------------------------------\n')
#年龄段和月份检测:
generation_month = split_array(new_df,'generation','log_month')
print('--------------------年龄和月份------------------------\n')
chi(generation_month)
print('------------------------------------------------------\n')
#设备和月份检测:
device_month = split_array(new_df,'device_type','log_month')
print('--------------------设备和月份------------------------\n')
chi(device_month)
print('------------------------------------------------------\n')
返回的结果
--------------------性别和月份------------------------
样本量大于40
====================================================
报告
χ2值:2.009573852892115
p值:0.1563092191352709
自由度:1
理论值:
[[46987.45685607 47197.54314393]
[38002.54314393 38172.45685607]]
====================================================
不拒绝原假设,无充分证据表明两个因素之间存在关系,即可认为该因素不影响登陆次数
------------------------------------------------------
--------------------年龄和月份------------------------
样本量大于40
====================================================
报告
χ2值:17.246958670810887
p值:0.0017306236244977753
自由度:4
理论值:
[[33669.09192299 4789.96736323 27807.68449166 9023.75892228
18894.49729984]
[27230.90807701 3874.03263677 22490.31550834 7298.24107772
15281.50270016]]
====================================================
显著性水平α=0.05下,拒绝原假设,充分相关,建议作图分析做进一步判断到底是因子里面哪个因素起作用
------------------------------------------------------
--------------------设备和月份------------------------
样本量大于40
====================================================
报告
χ2值:2042.142383870325
p值:0.0
自由度:1
理论值:
[[51824.41720474 42360.58279526]
[41914.58279526 34260.41720474]]
====================================================
显著性水平α=0.05下,拒绝原假设,充分相关,建议作图分析做进一步判断到底是因子里面哪个因素起作用
------------------------------------------------------
这里两组因子都返回了p值在显著性水平0.05下小于0.05
因此进一步查看相关数据,这里是用到了pandas的交叉表,当然用pivottable也就是透视表也可以。
#研究年龄段是否真的影响
#Python学习交流群:548377875
age_df=pd.crosstab(index=new_df.log_month,
columns=new_df.generation,
values=new_df.user_id,aggfunc='count')
print(age_df)
返回
generation 10 20 30 40 50
log_month
8 18785 33671 28072 8828 4829
9 15391 27229 22226 7494 3835
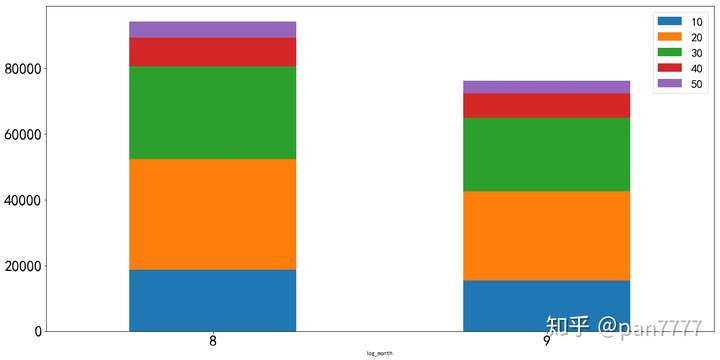
初步看20代、30代的玩家是该手游的主力玩家,这时候要比较8月和9月各个年龄段之间的差值以及每个月内的占比,也就是比较组间差距和组内 差距
#8-9月年龄段同比
Aug_age_df = age_df.loc[8]
Sep_age_df = age_df.loc[9]
diff_age_df = (Sep_age_df - Aug_age_df)/Aug_age_df
print(diff_age_df,'\n40-49年龄段同比下降幅度15%,其他年龄段同比下降20%左右')
print(Aug_age_df/Aug_age_df.sum(),'\n',Sep_age_df/Sep_age_df.sum())
#看整体
age_df.plot(figsize=(20,10),kind='bar',rot=0,fontsize=25,stacked=True)
plt.legend(fontsize=20)
print('20、30代下降得比较严重')
返回
generation
10 -0.180676
20 -0.191322
30 -0.208250
40 -0.151110
50 -0.205840
dtype: float64
40-49年龄段同比下降幅度15%,其他年龄段同比下降20%左右
generation
10 0.199448
20 0.357499
30 0.298052
40 0.093730
50 0.051271
Name: 8, dtype: float64
generation
10 0.202048
20 0.357453
30 0.291776
40 0.098379
50 0.050345
Name: 9, dtype: float64
20、30代下降得比较严重
单单这样比较起来,每个年龄段在每个月内的占比情况其实大同小异,再看组间差距,可以发现除了40代以外,其他都是维持在20%左右的降幅,作为一个异常值,可以去尝试把40代的数据挑出来再做检验
#把40代剔除
newdf = new_df[new_df.generation != 40]
generation_month2 = split_array(newdf,'generation','log_month')
print('--------------------年龄和月份(剔除40代后)------------------------\n')
chi(generation_month2)
返回报告
--------------------年龄和月份(剔除40代后)------------------------
样本量大于40
====================================================
报告
χ2值:6.74676953726528
p值:0.08042237855065465
自由度:3
理论值:
[[33746.48658123 4800.97799244 27871.6056168 18937.92980953]
[27153.51341877 3863.02200756 22426.3943832 15238.07019047]]
====================================================
不拒绝原假设,无充分证据表明两个因素之间存在关系,即可认为该因素不影响登陆次数
p值 大于0.05,个人认为虽然是大于0.05,但是多少还是会存在年龄段的因素,相对于下面这个因素来说影响太弱。
#可以认为年龄段对于登陆次数是有影响,40代剔除后本对整体不影响,但卡方检验p值提升,因此年龄段也需要关注
device_type_df =pd.crosstab(index=new_df.log_month,
columns=new_df.device_type,
values=new_df.user_id,aggfunc='count')
print(device_type_df)
返回
device_type Android iOS
log_month
8 46974 47211
9 29647 46528
可以看到安卓突然崩塌式下坠,而IOS基本保持应有的水平,似乎答案已经出来了。
#很直观,明显9月安卓突然下降,设备上面很可能有问题。
logdf1 = new_df[new_df['device_type']=='iOS'].groupby(['log_date']).count()['user_id']
logdf2 = new_df[new_df['device_type']=='Android'].groupby(['log_date']).count()['user_id']
f,axes = plt.subplots(1,1)
logdf1.plot(figsize=(20,10),legend=True,fontsize=20,
label = 'IOS用户数',linewidth =2,colormap = 'BrBG_r',marker='o',
alpha=0.6,linestyle='--',grid=True)
logdf2.plot(figsize=(20,10),legend=True,fontsize=20,
label = '安卓用户数',linewidth =2,colormap = 'jet_r',marker='*',
alpha=0.6,linestyle='--',grid=True)
plt.legend(fontsize=20)
plt.title('8-9月登陆用户数趋势图',fontsize=20)
plt.grid(which='y',linestyle='--',color='grey',alpha=0.8)
plt.show()
#根据图像,明显安卓用户断崖崩塌,假设:存在安卓系统优化问题
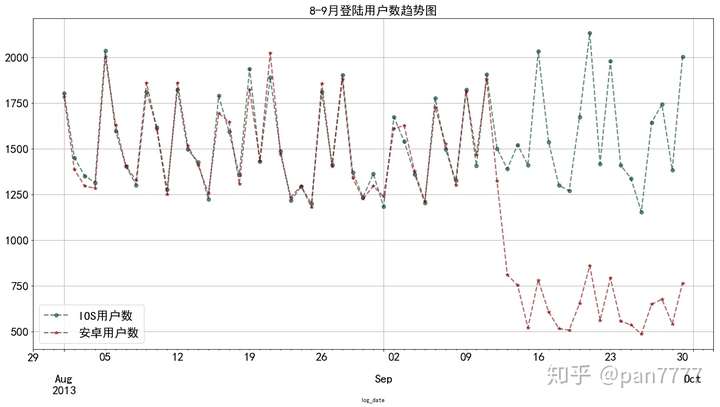
初步判断,安卓用户存在优化问题。
以上就是用 python做卡方检验。也可以考虑用相关矩阵
n = new_df
n.drop('log_date',axis=1,inplace=True)
n['device_type'] = n['device_type'].map({'iOS':1,'Android':0})
n['gender'] = n['gender'].map({'F':0,'M':1})
corr = n.corr()
print(corr)
#相关性矩阵,可以看到设备类型和登陆月份之间的相关性是里面最强的,其余基本都是无相关关系
user_id gender generation device_type log_month
user_id 1.000000 -0.000472 0.012713 0.037740 0.184411
gender -0.000472 1.000000 -0.009061 0.014727 0.003435
generation 0.012713 -0.009061 1.000000 -0.011449 -0.001097
device_type 0.037740 0.014727 -0.011449 1.000000 0.109486
log_month 0.184411 0.003435 -0.001097 0.109486 1.000000本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16766905.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号