关于反爬虫我见到的各种前后端奇葩姿势
以下方式都是比较有意思而非是非常有效的做法,
一:前端高危数据的特殊显示
去哪儿网、猫眼电影、美团,都可喜欢在价格字体上做文章:
1:去哪儿网
网上表明标注的价格在html源码中竟然不一样,
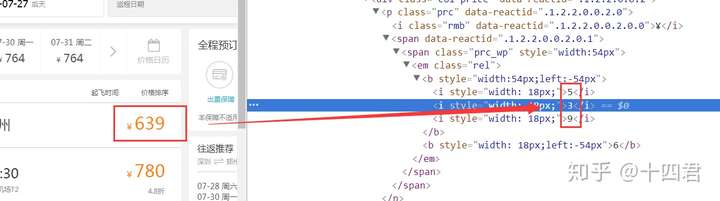
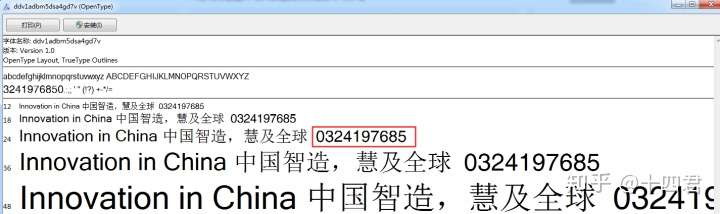
仔细分析他们的CSS就会发现他们用了一个字体,正常字体是0123456789 在官方字体中替换为:(这是他们以前的做法,现在已经更新因此图来自网络)
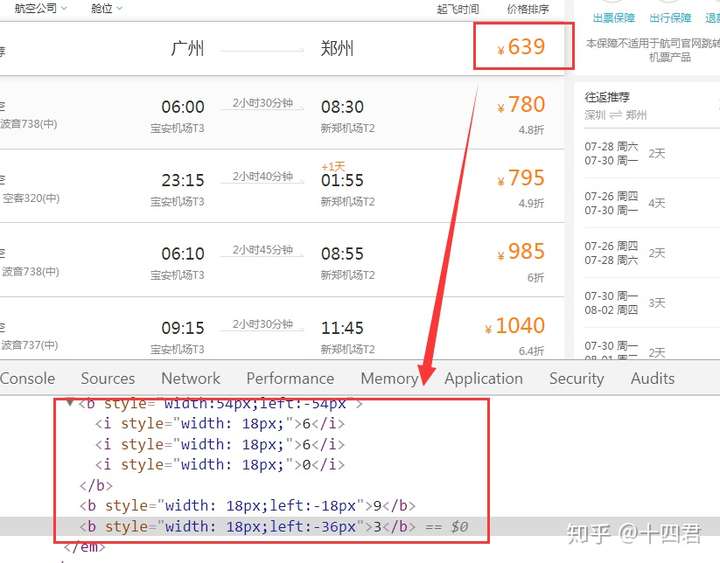
或者价格的显示与html中的顺序不同
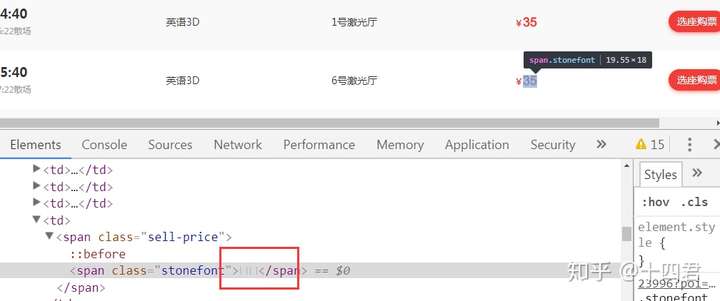
2:猫眼电影
每次都不同的字符集,需要对应采集一起解码。
3:过去美团也采用过font的思路,用backgfround拼接,数字其实是图片,用不同的偏移量显示不同的字符。还个比较狠的,呈现的数值是SVG矢量图。
4:部分微信公众号会穿插各种蜜汁字符,再用样式调整隐藏他们,比如他:叨逼姐说
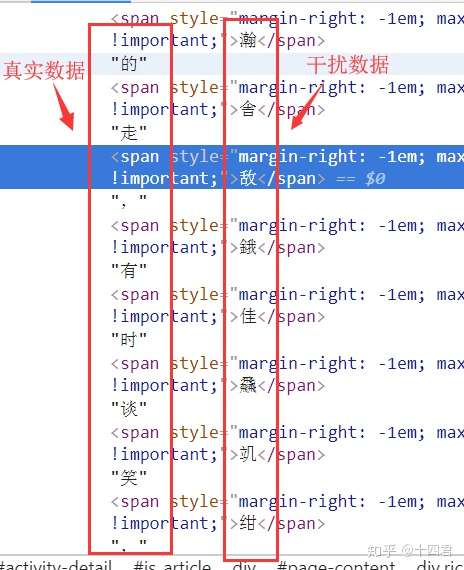
5:用display:none来随机化网页源码,有网站还会随机类和id的名字再加点随机的trtd,更加不好捕捉.比如:全网代理ip
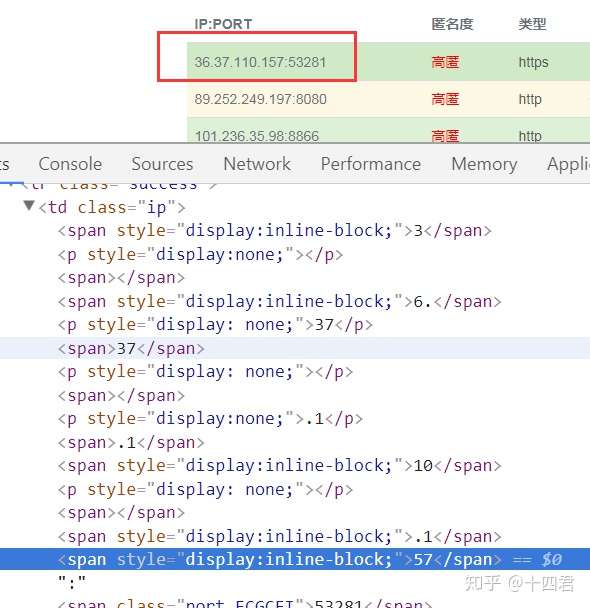
二:各种异步加载反复嵌套
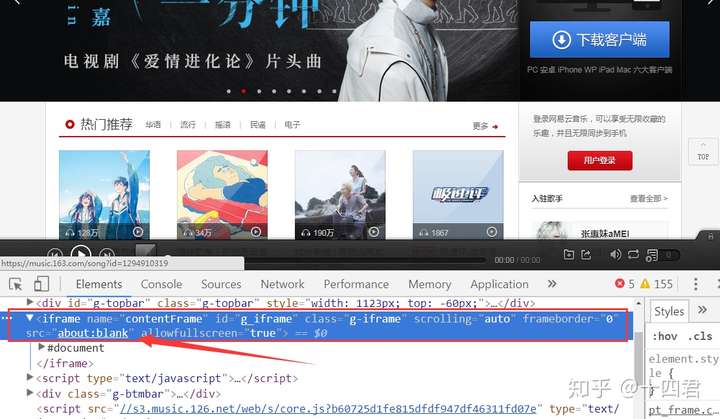
网易云音乐也怕爬什么都是异步加载嵌套在iframe里的,包括他的整个主页,而且src=”about:blank”
三:别以为后端汉子就不花哨
1:还有的网站识别出爬虫后会反骂一句话:
比如IT桔子,会返回Fack you Spider, 还有个麦子金服会返回一个go away,然后一般我就会解开加密后在hreder里加个呵呵,再发给他。
4:还有ip方面的操作
比如新浪知乎的反爬虫机制会对ip异常或者不带cookie的跳转到访客系统中,如果用模拟登陆就会反复出现验证码,这就涉及到是否是白ip,他的判定机制也和其他网站不同,其他主要是看近期常用登陆地ip为白,他是用注册时ip为白,因此只要用服务器去注册一个号,就基本轻松过了(17年实测)。
还有些佛系反爬虫,每个ip的第一次访问秒回数据,但是第二次就必然sleep 12 秒才返回,这招其实很佛系,你爬可以,别让我老板发现数据量太夸张了。一般这种就程序放着慢慢来吧,因为换个可靠ip也得好几秒。对方这么坦诚咱们也不乱来。
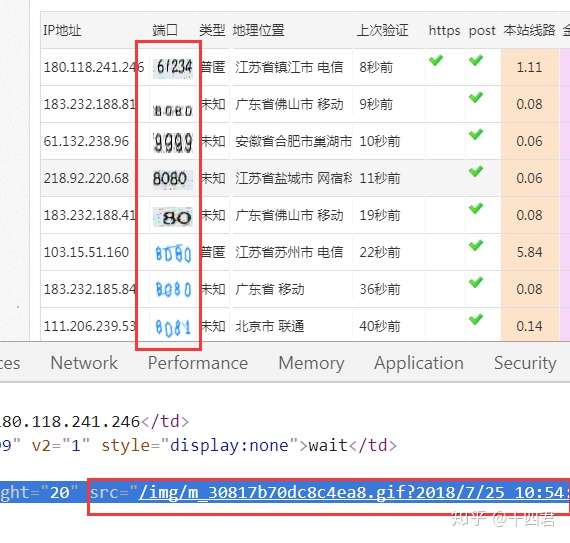
5:网页数据转化为图片的
比如站大爷的免费代理端口数据是扭曲图片构成的数字
还有各种网站用了不同的奇葩手法,用文中没有的类别的,欢迎各位看官放在评论区,回头我搞搞看补充上来。
作者:十四君
更多Python视频、源码、资料加群683380553免费获取
本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16766812.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号