Python使用Tabula提取PDF表格数据
今天遇到一个批量读取pdf文件中表格数据的需求,样式大体是以下这样:
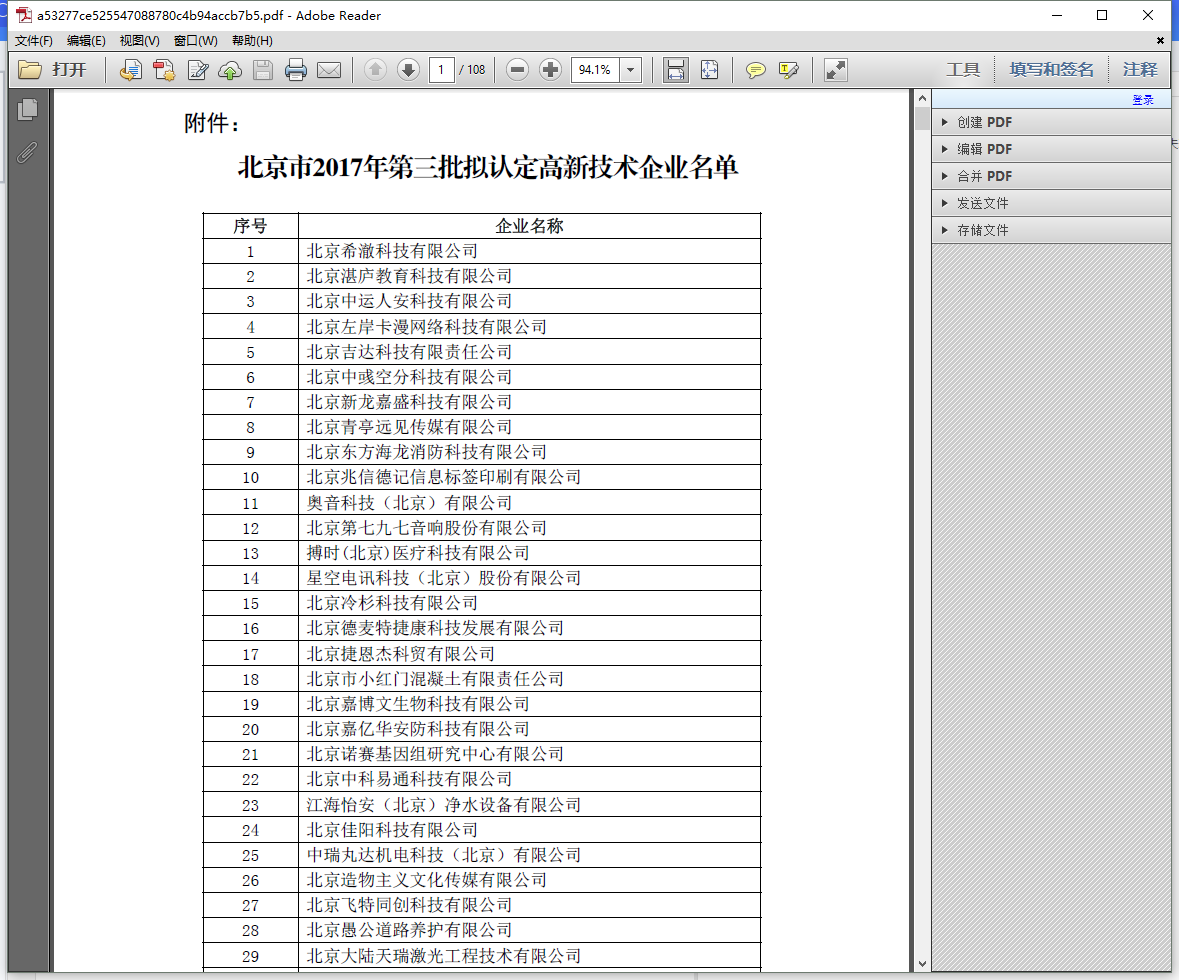
python读取PDF无非就是三种方式(我所了解的),pdfminer、pdf2htmlEX 和 Tabula。综合考虑后,选择了最后一种。下面对三种方式分别介绍:
pdfminer
该方式从网上搜索的结果是,可以提取pdf文本数据,但是提取后表格信息就乱了。所以本人没有亲自实验,就果断放弃了实验该方法。如果只是提取pdf里面的文本内容,该方式可能是比较合适的。
pdf2htmlEX
该方式是通过把pdf格式转换成html格式,然后再提取信息的方法。
Github: https://github.com/coolwanglu/pdf2htmlEX
需先下载pdf2htmlEX可执行程序,下载地址:https://github.com/coolwanglu/pdf2htmlEX/wiki/Download。

执行以上代码,会在指定目录 E:\test\extract\2017gq\out 下生成对应html文件,浏览器中查看效果:
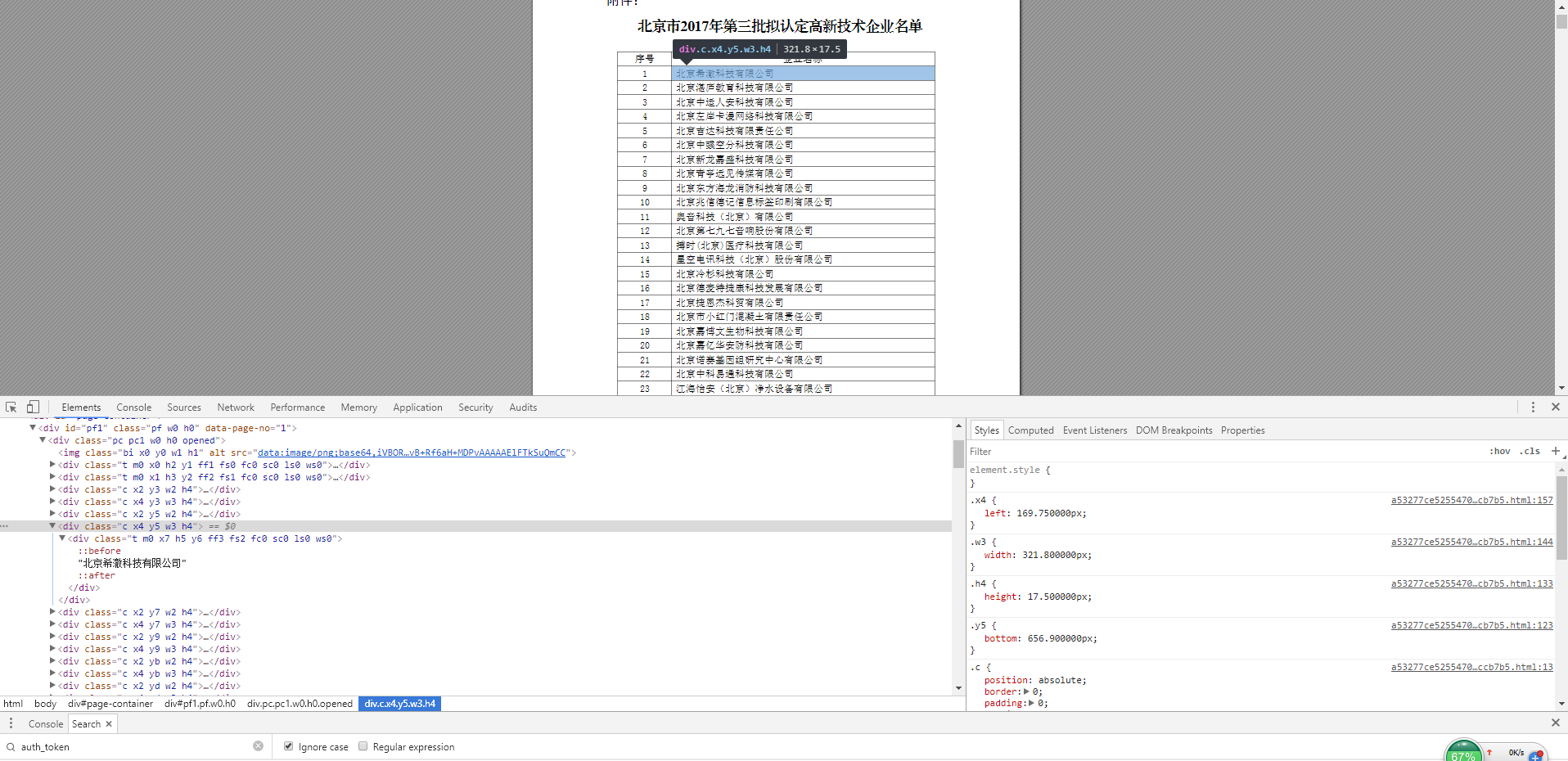
可以看到整体转换的效果非常不错,但是转换后的标签没有特点,使数据的提取变得非常困难。多番尝试后,感觉该方法不够通用,没法解决我的需求。也许对于单纯的pdf转html,该方式可能是最好的选择。
Tabula
Tabula是专门用来提取PDF表格数据的,同时支持PDF导出为CSV、Excel格式。
官网: Tabula: Extract Tables from PDFs
Github: https://github.com/chezou/tabula-py
首先安装tabula-py: pip install tabula-py
tabula-py依赖库包括java、pandas、numpy,所以需保证运行环境中安装了这些库。

执行以上代码,成功打印出表格中的所有企业名称,查看打印的 df 的结构,如下图:

总结
以上三种方式中,最后一种方式完美的解决了我的从PDF表格中提取数据的需求,希望能抛砖引玉,大家在使用时选择最适合自己的方法,如有介绍不当之处,望留言中指正,谢过。
本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16764734.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号