Python计算大文件行数方法及性能比较
如何使用Python快速高效地统计出大文件的总行数, 下面是一些实现方法和性能的比较。
1.readline读所有行
使用readlines方法读取所有行:
def readline_count(file_name):
return len(open(file_name).readlines())
2.依次读取每行
依次读取文件每行内容进行计数:
def simple_count(file_name):
lines = 0
for _ in open(file_name):
lines += 1
return lines
3.sum计数
使用sum函数计数:
def sum_count(file_name):
return sum(1 for _ in open(file_name))
4.enumerate枚举计数:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def enumerate_count(file_name):
with open(file_name) as f:
for count, _ in enumerate(f, 1):
pass
return count
5.buff count
每次读取固定大小,然后统计行数:
def buff_count(file_name):
with open(file_name, 'rb') as f:
count = 0
buf_size = 1024 * 1024
buf = f.read(buf_size)
while buf:
count += buf.count(b'\n')
buf = f.read(buf_size)
return count
6.wc count
调用使用wc命令计算行:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def wc_count(file_name):
import subprocess
out = subprocess.getoutput("wc -l %s" % file_name)
return int(out.split()[0])
7.partial count
在buff_count基础上引入partial:
def partial_count(file_name):
from functools import partial
buffer = 1024 * 1024
with open(file_name) as f:
return sum(x.count('\n') for x in iter(partial(f.read, buffer), ''))
8.iter count
在buff_count基础上引入itertools模块 :
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def iter_count(file_name):
from itertools import (takewhile, repeat)
buffer = 1024 * 1024
with open(file_name) as f:
buf_gen = takewhile(lambda x: x, (f.read(buffer) for _ in repeat(None)))
return sum(buf.count('\n') for buf in buf_gen)
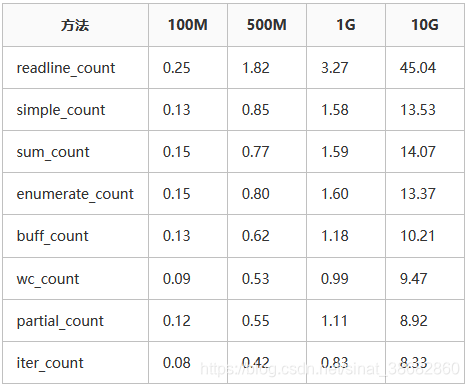
下面是在我本机 4c8g python3.6的环境下,分别测试100m、500m、1g、10g大小文件运行的时间,单位秒:
本文来自博客园,作者:I'm_江河湖海,转载请注明原文链接:https://www.cnblogs.com/jhhh/p/16761297.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号