Java Stream(流)基本使用
将多个Long类型用逗号拼接的字符串转换成List<Long>
String orderDetailIds = "1593507066795622400,1593507066795622401,1593507066795622402";
List<Long> orderDetailIdList = Arrays.stream(orderDetailIds.split(",")).map(Long::parseLong).collect(Collectors.toList());


String orderDetailIds = "1593507066795622400,1593507066795622401,1593507066795622402"; //拆分成数组 String[] strArr = orderDetailIds.split(","); //数组转换成流 Stream<String> stream = Arrays.stream(strArr); //通过Long::parseLong方法将每个元素从String转换成Long //stream.map:它把一个Stream转换为另一个Stream(Stream<String>转换成Stream<Long>) Stream<Long> longStream = stream.map(Long::parseLong); //Collectors.toList():将流中的所有元素导出到一个列表(List)中 //longStream.collect:收集 Stream 流中的数据到集合中 List<Long> longList = longStream.collect(Collectors.toList());
将List<Object>转换成Map<String,Object>
List<ProductRmRateDetailModel> productRmRateDetailModels = new ArrayList<>(); Map<String, ProductRmRateDetailModel> rmRateDetailMap = productRmRateDetailModels.stream().collect(Collectors.toMap(o -> simpleDateFormat.format(o.getPriceDate()), o -> o));
List<ProductRmRateDetailModel> productRmRateDetailModels = new ArrayList<>(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); //将集合转换成流 Stream<ProductRmRateDetailModel> stream = productRmRateDetailModels.stream(); //stream.collect:收集 Stream 流中的数据到集合中 //o -> simpleDateFormat.format(o.getPriceDate()):每个对象是o,根据getPriceDate获取游玩日期,将其转换成字符串,并作为Map的KEY //o -> o,元素对象作为VALUE //toMap(Function, Function) 返回一个 Collector,它将元素累积到一个 Map中,其键和值是将提供的映射函数应用于输入元素的结果 Map<String, ProductRmRateDetailModel> rmRateDetailMap = stream.collect( Collectors.toMap(o -> simpleDateFormat.format(o.getPriceDate()), o -> o) );
将List<Object>转换成Map<String,List<Object>>
List<OrderTicketsModel> subOrderProductDetail = new ArrayList<>(); Map<String,List<OrderTicketsModel>> ticketGroupByProductTypeMap = subOrderProductDetail.stream().collect(Collectors.groupingBy(OrderTicketsModel::getProductType));
List<OrderTicketsModel> subOrderProductDetail = new ArrayList<>(); /** * Collectors.groupingBy 分组的使用方法 * * 键类型、容器类型、值类型都可以进行自定义,键值类型都可以根据需要自定义,而容器类型则只能设置为Map(M extends Map<K, D>)的子类。 * * 容器类型可以根据Map实现类的不同特性选择合适的容器:Hashmap LinkedHashMap ConcurrentHashMap WeakHashMap TreeMap Hashtable等等。 * * 如需要保证students分组后的有序性的话,那么可以自定义容器类型为LinkedHashMap。 * * 1、Collectors.groupingBy:基础分组功能,分组并返回Map容器。将用户自定义的元素作为键,同时将键相同的元素存放在List中作为值 * 写法1、写法2,两种写法是一样的 */ Map<String,List<OrderTicketsModel>> map1 = subOrderProductDetail.stream().collect(Collectors.groupingBy(OrderTicketsModel::getProductType)); //写法2 Map<String,List<OrderTicketsModel>> map2 = subOrderProductDetail.stream().collect(Collectors.groupingBy(OrderTicketsModel::getProductType,Collectors.toList())); /** * 对一批Java对象进行分组,根据需求我们可能会选择其中的一个或多个字段,也可能会根据一些字段格式化操作,以此生成键。 * 2、Collectors.groupingBy:自定义键——字段映射 * 字段映射 分组显示每个课程的学生信息 */ Map<String, List<Student>> filedKey = students.stream().collect(Collectors.groupingBy(Student::getCourse)); // 组合字段 分组现实每个班不同课程的学生信息 Map<String, List<Student>> combineFiledKey = students.stream().collect(Collectors.groupingBy(student -> student.getClazz() + "#" + student.getCourse())); /** * 需要根据对不同区间内的数据设置不同的键,区别于字段,这种范围类型的键多数情况下都是通过比较来生成的 * 3、Collectors.groupingBy:自定义键——范围 */ // 根据两级范围 将学生划分及格不及格两类 Map<Boolean, List<Student>> customRangeKey = students.stream().collect(Collectors.groupingBy(student -> student.getScore() > 60)); // 根据多级范围 根据学生成绩来评分 Map<String, List<Student>> customMultiRangeKey = students.stream().collect(Collectors.groupingBy(student -> { if (student.getScore() < 60) { return "C"; } else if (student.getScore() < 80) { return "B"; } return "A"; })); /** * 后文剩下的三个功能点都基于第三个参数:Collector<? super T, A, D> downstream。它们都是通过实现Collector接口来实现各种downstream操作。 * * 分组统计功能 * 1、Collectors.counting:计数 * 分组后,对同一分组内的元素进行计算:计数、平均值、求和、最大最小值、范围内数据统计。 */ Map<String, Long> groupCount = students.stream().collect(Collectors.groupingBy(Student::getCourse, Collectors.counting())); /** * 2、Collectors.summingInt:求和 * 求和针对流中元素类型的不同,分别提供了三种计算方式:Int、Double、Long。计算方式与计算结果必须与元素类型匹配 */ Map<String, Integer> groupSum = students.stream().collect(Collectors.groupingBy(Student::getCourse, Collectors.summingInt(Student::getScore))); /** * 3、Collectors.averagingInt:平均值 */ // 增加平均值计算 Map<String, Double> groupAverage = students.stream().collect(Collectors.groupingBy(Student::getCourse, Collectors.averagingInt(Student::getScore))); /** * 4、Collectors.minBy:最大最小值 */ // 同组最小值 Map<String, Optional<Student>> groupMin = students.stream() .collect(Collectors.groupingBy(Student::getCourse,Collectors.minBy(Comparator.comparing(Student::getCourse)))); // 使用Collectors.collectingAndThen方法,处理Optional类型的数据 Map<String, Student> groupMin2 = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.collectingAndThen(Collectors.minBy(Comparator.comparing(Student::getCourse)), op ->op.orElse(null)))); // 同组最大值 Map<String, Optional<Student>> groupMax = students.stream() .collect(Collectors.groupingBy(Student::getCourse,Collectors.maxBy(Comparator.comparing(Student::getCourse)))); /** * 5、Collectors.summarizingInt:完整统计(同时获取以上的全部统计结果) */ // 统计方法同时统计同组的最大值、最小值、计数、求和、平均数信息 HashMap<String, IntSummaryStatistics> groupStat = students.stream() .collect(Collectors.groupingBy(Student::getCourse, HashMap::new,Collectors.summarizingInt(Student::getScore))); groupStat.forEach((k, v) -> { // 返回结果取决于用的哪种计算方式 v.getAverage(); v.getCount(); v.getMax(); v.getMin(); v.getSum(); }); /** * 6、Collectors.partitioningBy:范围统计 * 上面的统计都是基于某个指标项的。如果我们需要统计范围,比如:得分大于、小于60分的人的信息,那么我们可以通过Collectors.partitioningBy方法对映射结果进一步切分 */ // 切分结果,同时统计大于60和小于60分的人的信息 Map<String, Map<Boolean, List<Student>>> groupPartition = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60))); // 同样的,我们还可以对上面两个分组的人数数据进行统计 Map<String, Map<Boolean, Long>> groupPartitionCount = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60, Collectors.counting()))); //Collectors.partitioningBy仅支持将数据划分为两个范围进行统计,如果需要划分多个,可以嵌套Collectors.partitioningBy执行,不过需要在执行完后,手动处理不需要的数据。也可以在第一次Collectors.partitioningBy获取结果后,再分别对该结果进行范围统计。 Map<String, Map<Boolean, Map<Boolean, List<Student>>>> groupAngPartitionCount = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.partitioningBy(s -> s.getScore() > 60, Collectors.partitioningBy(s -> s.getScore() > 90)))); /** * 分组合并功能 * 将同一个键下的值,通过不同的方法最后合并为一条数据。 * 1、Collectors.reducing:合并分组结果 */ // 合并结果,计算每科总分 Map<String, Integer> groupCalcSum = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.reducing(0, Student::getScore, Integer::sum))); // 合并结果,获取每科最高分的学生信息 Map<String, Optional<Student>> groupCourseMax = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.reducing(BinaryOperator.maxBy(Comparator.comparing(Student::getScore))))); /** * 2、Collectors.joining:合并字符串 * Collectors.joining只能对字符进行操作,因此一般会与其它downstream方法组合使用 */ // 统计各科的学生姓名 Map<String, String> groupCourseSelectSimpleStudent = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.mapping(Student::getName, Collectors.joining(",")))); /** * 分组自定义映射功能 * 1、Collectors.toXXX:映射结果为Collection对象 */ Map<String, Map<String, Integer>> courseWithStudentScore = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.toMap(Student::getName, Student::getScore))); Map<String, LinkedHashMap<String, Integer>> courseWithStudentScore2 = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.toMap(Student::getName, Student::getScore, (k1, k2) -> k2, LinkedHashMap::new))); /** * 2、Collectors.mapping:自定义映射结果 * Collectors.mapping的功能比较丰富,除了可以将分组结果映射为自己想要的值外,还能组合上面提到的所有downstream方法。 */ //将结果映射为指定字段 Map<String, List<String>> groupMapping = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.mapping(Student::getName, Collectors.toList()))); //转换bean对象 Map<String, List<OutstandingStudent>> groupMapping2 = students.stream() .filter(s -> s.getScore() > 60) .collect(Collectors.groupingBy(Student::getCourse, Collectors.mapping(s -> BeanUtil.copyProperties(s, OutstandingStudent.class), Collectors.toList()))); // 组合joining Map<String, String> groupMapperThenJoin= students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.mapping(Student::getName, Collectors.joining(",")))); // 利用collectingAndThen处理joining后的结果 Map<String, String> groupMapperThenLink = students.stream() .collect(Collectors.groupingBy(Student::getCourse, Collectors.collectingAndThen(Collectors.mapping(Student::getName, Collectors.joining(",")), s -> "学生名单:" + s))); /** * 3、Collector:自定义downstream * * Collector<T, A, R>范型的含义: * <T>:规约操作(reduction operation)的输入元素类型 * <A>:是规约操作的输出结果类型,该类型是可变可累计的,可以是各种集合容器,或者具有累计操作(如add)的自定义对象。 * <R>:规约操作结果经过转换操作后返回的最终结果类型 * * Collector中方法定义,下面的方法的返回值都可以看作函数(function): * Supplier<A> supplier():该函数创建并返回新容器对象。 * BiConsumer<A, T> accumulator():该函数将把元素值放入容器对象,并返回容器。 * BinaryOperator<A> combiner():该函数会把两个容器(此时每个容器都是处理流元素的部分结果)合并,该函数可以返回这两个容器中的一个,也可以返回一个新的容器。 * Function<A, R> finisher():该函数将执行最终的转换,它会将combiner的最终合并结果A转变为R。 * Set<Characteristics> characteristics():提供集合列表,该列表将提供当前Collector的一些特征值。这些特征将会影响上述函数的表现。 * * 上述函数的语法: * Supplier<T>#T get():调用一个无参方法,返回一个结果。一般来说是构造方法的方法引用。 * BiConsumer<T, U>#void accept(T t, U u):根据给定的两个参数,执行相应的操作。 * BinaryOperator<T> extends BiFunction<T,T,T>#T apply(T t, T u):合并t和u,返回其中之一,或创建一个新对象放回。 * Function<T, R>#R apply(T t):处理给定的参数,并返回一个新的值。 * * public interface Collector<T, A, R> { * * Supplier<A> supplier(); * * BiConsumer<A, T> accumulator(); * * BinaryOperator<A> combiner(); * * Function<A, R> finisher(); * * Set<Characteristics> characteristics(); * } */
Map<String,List<ProductIncomeVo>> pckIncomeVo = productIncomeList2.stream().filter(vo -> vo.getProductId() != null && vo.getPolicyId() != null) .collect(Collectors.groupingBy( vo -> vo.getProductId() + "_" + vo.getPolicyId() ));
将List<OrderVisitorModel>转换成List<Long>
List<OrderVisitorRmModel> ovp = new ArrayList(); List<Long> oldOvrIds = ovp.stream().map(i -> i.getId()).collect(Collectors.toList())
//去重 List<String> rateDates = roomRates.stream().map(x -> x.getEffectiveDate()).distinct().collect(Collectors.toList());
将List<Object>中的字段转换成String(使用","隔开)并去重
String productIds = orderProductInfoModels.stream().map(o -> o.getProductId().toString()).distinct().collect(Collectors.joining(","));
List<Long> ticketProductIdList = new ArrayList<>(); String productIds = ticketProductIdList.stream().distinct().map(String::valueOf).collect(Collectors.joining(","));
将集合List<ChannelClassSetVo> channelClassSetVos进行过滤,筛选出id与pId相同的数据,并且根据sort进行排序
-- (不建议)pId是常量 filter进行筛选,返回相同的实体,sorted进行自然排序(升序),但是sort是null时候会抛出异常 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort)) .collect(Collectors.toList()); -- (不建议)pId是常量 filter进行筛选,返回相同的实体,sorted进行倒序 .reversed() 但是sort是null时候会抛出异常 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort).reversed()) .collect(Collectors.toList()); -- (建议)null值在前,非null按sort升序 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort, Comparator.nullsFirst(Comparator.naturalOrder()))) .collect(Collectors.toList()); -- (建议)null值在后,非null按sort升序 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort, Comparator.nullsLast(Comparator.naturalOrder()))) .collect(Collectors.toList()); -- (建议)null值在前,非null按sort倒序 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort, Comparator.nullsFirst(Comparator.reverseOrder()))) .collect(Collectors.toList()); -- (建议)null值在后,非null按sort倒序 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .filter(x -> pId.equals(x.getpId())) .sorted(Comparator.comparing(ChannelClassSetVo::getSort, Comparator.nullsLast(Comparator.reverseOrder()))) .collect(Collectors.toList());
将集合List<ChannelClassSetVo> channelClassSetVos中的元素进行去重,例如根据主键id返回首次出现的元素
-- 根据主键id对元素去重,返回首次出现的元素 List<ChannelClassSetVo> collect = channelClassSetVos.stream() .collect(Collectors.toMap( ChannelClassSetVo::getId, Function.identity(), (existing, replacement) -> existing, LinkedHashMap::new )) .values() .stream() .collect(Collectors.toList()); 当id为null时,不一定会抛出异常,具体取决于场景: 1. 单个id为null的元素 LinkedHashMap(及HashMap)支持null作为键,因此若集合中只有一个id为null的元素,代码不会抛异常,该元素会被正常保留到Map中。 2. 多个id为null的元素 此时合并函数(existing, replacement) -> existing会触发,保留第一个出现的id为null的元素,后续重复的id为null的元素会被丢弃,也不会抛异常。 3. 特殊情况:Java 版本或底层实现差异 Java 8 的Collectors.toMap底层依赖HashMap,本身支持null键,不会因null键抛NullPointerException; 但如果后续对Map的键进行操作(如某些序列化场景),null键可能引发其他问题,但这不属于当前代码的直接异常。 真正的风险点 若ChannelClassSetVo::getId返回null,且业务上不允许id为null,此时虽然代码不抛异常,但会导致null键的元素被保留,可能违反业务规则(而非程序异常)。 总结 代码本身不会因id为null抛出异常,但需注意业务逻辑是否允许id为null的元素存在。若需避免null键,可通过filter(x -> x.getId() != null)提前过滤。 -- 若ChannelClassSetVo已根据业务规则重写了equals()和hashCode()方法,可直接用distinct() List<ChannelClassSetVo> distinctList = channelClassSetVos.stream() .distinct() .collect(Collectors.toList()); -- 若不关心元素顺序,可通过HashSet快速去重 List<ChannelClassSetVo> distinctList = new ArrayList<>(new LinkedHashSet<>(channelClassSetVos));
一、Stream(流)基本介绍
JAVA 8 API添加了一个新的抽象称为流Stream,将要处理的元素集合看作一种流, 流在管道中传输,能够对每个元素进行一系列并行或串行的流水线操作。
- 数据源可以是集合,数组,I/O channel, 产生器generato…
- 数据源如:List<T> 的集合转换为 Stream<T> 类型的流,然后进行中间操作如过滤、排序、遍历、类型转换
- 终端可以选择将 Stream 流转换回一个新类型的集合中,如果中间对每个元素操作后,你的目的已达到,最后转不转回都行
- 很多中间操作的方法返回类型就是Stream,因此可以直接连起来,如操作List<Person> list
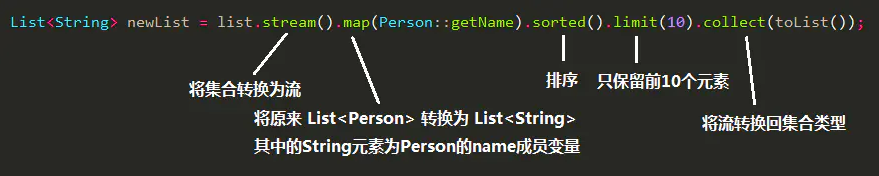
- 流的操作不会改变原集合,除非用原集合接,即list = list.stream().xxx…
- stream() - 为集合创建串行流
- parallelStream() − 为集合创建并行流
二、Stream(流)的常用方法
List<String> stringList = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
public class Person{
String name;
Integer age;
}
List<Person> list = new ArrayList<>();
list.add(new Person("Jack",23));
list.add(new Person("Jack",23));
list.add(new Person("Tom",30));
1、filter(element -> boolean表达式)
- 过滤元素,符合Boolean表达式的留下来
//过滤,只要空字符串 NewList<String> list = stringList.stream().filter(param -> param.isEmpty()).collect(Collectors.toList());
2、distinct()
- 去除重复元素
- 这个方法是通过类的equals方法来判断两个元素是否相等的
list = list.stream().distinct().collect(Collectors.toList());
这里不重写Person类的equals方法,两个数据不会被处理
3、sorted() / sorted((T, T) -> int)
- 对流中的元素进行排序
- 若流中元素的类实现了Comparable接口,即有自己的排序规则,此时可直接sorted()
- 否则,用sorted((T,T) -> int)说明排序规则
根据年龄大小来比较:
list = list.stream() .sorted((p1, p2) -> p1.getAge() - p2.getAge()).collect(Collectors.toList());
以上可优化为:
list = list.stream().sorted(Comparator.comparingInt(Person::getAge)).collect(Collectors.toList());
4、limit(long n)
- 返回前n个元素
list = list.stream().limit(1).collect(Collectors.toList());
5、skip(long n)
- 去除前n个元素
- limit(m).skip(n),先返回前m个元素,再从这m个元素中去除n个
- skip(n).limit(m),先去除n个元素,再返回剩余的前m个
list = list.stream().limit(2).skip(1).collect(Collectors.toList()); //即先拿前两个,再去掉这两个中的第一个
6、map(T -> R)
- 将流中的每一个元素映射为R
List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); list = list.stream().map(i -> i + 2).collect(Collectors.toList()); list.forEach(System.out::println); //输出3、4、5
除了处理基本数据类型,也可修改对象,但最后记得return element;
list = list.stream().map(p -> {
p.setAge(p.getAge() + 1);
p.setName(p.getName().equals("Tom")? "TomCat" : "Cat");
return p;
})
.collect(Collectors.toList());
//对每个对象的属性进行定制操作
也可映射抽出对象的一部分属性,收集到一个新类型的集合中:
List<String> newlist = list.stream().map(Person::getName).collect(Collectors.toList()); List<Integer> newlist = list.stream().map(p -> p.getAge()).collect(Collectors.toList()); //map方法接受一个lambda表达式,这个表达式是一个函数,输入类型是集合元素的类型, 输出类型是任意类型 , 即你可以选择将元素映射为任意类型, 并对映射后的值做下一步处理. it -> Integer.toString(it)
7、faltMap(T -> Stream)
当处理的是一个List<Person>,此时使用map方法,拿到的元素是一个个Person对象。当处理的是一个List<List<Person>>,此时使用map,拿到的是一个个list集合,此时想对每一个Person对象操作,就得用faltMap,flat,平铺的意思 .
List<Person> list1 = new ArrayList<>(); List<Person> list2 = new ArrayList<>(); list1.add(new Person("A",23)); list1.add(new Person("B",23)); list2.add(new Person("C",23)); list2.add(new Person("D",23)); List<List<Person>> listPlus = new ArrayList<>(); listPlus.add(list1); listPlus.add(list2);
List<String> nameList = listPlus.stream() .flatMap(t -> t.stream()) //此时流中元素为Person对象 .map(t -> t.getName()) .distinct() .collect(Collectors.toList()); //A B C D
8、anyMatch(T -> boolean表达式)
- 流中是否有元素满足这个Boolean表达式
//是否存在一个 person 对象的 age 等于 20: boolean b = list.stream().anyMatch(person -> person.getAge() == 20);
9、allMatch(T -> boolean)和noneMatch(T -> boolean)
- allMatch(T -> boolean)即流中所有元素是否都满足Boolean条件
- noneMatch(T -> boolean)即是否流中没有一个元素满足Boolean表达式
10、count()
- 返回流中元素的个数,返回Long型
11、reduce((T, T) -> T) / reduce(T, (T, T) -> T)
- 组合流中的元素,进行求数学运算值
- 价格使用BigDecimal防止精度损失
//计算年龄总和: int sum = list.stream().map(Person::getAge).reduce(0, (a, b) -> a + b); //与之相同: int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum); //BigDecimal计算,将所有商品的价格累加 BigDecimal totalPrice = goodList.stream().map(GoodsCode::getPrice()).reduce(BigDecimal.ZERO, BigDecimal::add);
12、forEach()
普通for循环或者增强for循环,break跳出整个循环,continue跳出本次循环。stream()的forEach则不同:
- 处理集合时不能使用break和continue中止循环
- 可以使用关键字return跳出本次循环,并执行下一次遍历
- 不能跳出整个流的forEach循环
//打印各个元素 list.stream().forEach(System.out::println);
也可对每个元素进行想要的操作:
list.stream().forEach(element -> {
java语句1;
java语句2;
}
);
13、Stream.iterate
指定一个常量seed,生成从seed到常量f(由UnaryOperator返回的值得到)的流。
Stream.iterate(0, n -> n + 1).limit(5).forEach(a -> { System.out.println(a); }); //以上:根据起始值seed(0),每次生成一个指定递增值(n+1)的数,limit(5)用于截断流的长度,即只获取前5个元素。 //输出: 0 1 2 3 4
三、收集方法collect()详解
收集流中元素的方法,传参是一个收集器接口, 常用写法:
- collect(Collectors.toList())收集到list集合
- collect(Collectors.toMap(x,x,x))收集到map集合
- collect(Collectors.groupingBy(xx))分组
- collect(Collectors.counting())统计集合总数
- collect(joining())连接字符串
1、.collect(Collectors.toMap(x,x,x))
Map<String,Person> newMap = lst.stream().collect(Collectors.toMap(p -> p.getName(), p -> p, (p1,p2) -> p1)); //各个参数的意义: /** * 第一个参数 p -> p.getName()即使用name做为Map集合的key
* p -> p.getName()可以写成Person::getName * 第二个参数 p -> p即将原来的对象做为map的value值,当然也可以Person::getAge继续用属性做value * 第三个参数(p1,p2) -> p1即若p1、p2的key相同,则取p1的value */
2、.collect(Collectors.groupingBy(xx))
将处理后的元素进行分组,得到一个Map集合
//数据准备 @Data @AllArgsConstructor public class Books { private Integer id; private Integer num; private String name; private Double price; private String category; } Books book1 = new Books(1,100,"Java入门",60.0,"互联网类") ; Books book2 = new Books(2,200,"Linux私房菜",100.0,"互联网类") ; Books book3 = new Books(3,200,"Docker进阶",70.0,"互联网类") ; Books book4 = new Books(4,600,"平凡的世界",200.0,"小说类") ; Books book5 = new Books(5,1000,"白鹿原",190.0,"小说类") ; List<Books> booksList = Lists.newArrayList(book1,book2,book3,book4,book5);
- case1:按照某个属性分组, 即以该属性为Map集合的key,把这个属性相同的对象放在一个List集合中做为value
//按照category分类 Map<String,List<Books>> map = booksList.stream().collect(Collectors.groupingBy(Books::getCategory));
//run
{
互联网类=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类), Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)],
小说类=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]
}
- case2: 按照某几个属性拼接分组
Map<String,List<Books>> map = booksList.stream().collect(Collectors.groupingBy(t -> t.getCategory() +"_" + t.getName()));
//run
{
互联网类_Linux私房菜=[Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类)],
小说类_平凡的世界=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类)],
互联网类_Docker进阶=[Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)],
互联网类_Java入门=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类)],
小说类_白鹿原=[Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]
}
- case3: 按照不同的条件分组
//不同条件下,使用不同的key Map<String,List<Books>> map = booksList.stream() .collect(Collectors.groupingBy(t -> { if(t.getNum() > 500){ return "数量充足"; }else{ return "数量较少"; } }));
//run
{
数量充足=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)],
数量较少=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类), Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)]
}
- case4:实现多级分组, 即由双参数版本的Collectors.groupingBy,对由第一个参数分类后的结果, 再进行分类,此时结果类型
//接case3,想先按照类别分组,再给每个组按照数量再分一次 Map<String,Map<String,List<Books>>> map = booksList.stream() .collect(Collectors.groupingBy(t -> t.getCategory(), Collectors.groupingBy( t -> { if(t.getNum() > 100){ return "数量充足"; }else{ return "数量较少"; } }))); //run { 互联网类={数量充足=[Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), Books(id=3, num=200, name=Docker进阶, price=70.0, category=互联网类)], 数量较少=[Books(id=1, num=100, name=Java入门, price=60.0, category=互联网类)]}, 小说类={数量充足=[Books(id=4, num=600, name=平凡的世界, price=200.0, category=小说类), Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)]} }
- case5:分组后,统计每个分组中元素的个数, Map集合的value类型为long型
Map<String,Long> map = booksList.stream().collect(Collectors.groupingBy(Books::getCategory,Collectors.counting())); //run {互联网类=3, 小说类=2}
- case6:分组后,统计每个分组中元素的某属性的总和
Map<String,Integer> map = booksList.stream().collect(Collectors.groupingBy(Books::getCategory,Collectors.summingInt(Books::getNum))); //run {互联网类=500, 小说类=1600}
- case7: 加比较器取某属性最值
Map<String,Books> map3 = booksList.stream().collect(Collectors.groupingBy(Books::getCategory, Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Books::getNum)), Optional::get))); //run {互联网类=Books(id=2, num=200, name=Linux私房菜, price=100.0, category=互联网类), 小说类=Books(id=5, num=1000, name=白鹿原, price=190.0, category=小说类)}
- case8:联合其他收集器
Map<String, Set<String>> map2 = booksList.stream().collect(Collectors.groupingBy(Books::getCategory,Collectors.mapping(t->t.getName(),Collectors.toSet()))); //run {互联网类=[Linux私房菜, Docker进阶, Java入门], 小说类=[平凡的世界, 白鹿原]}
3 、.collect(joining())
- 拼接收集到的元素
- 传参为拼接时的连接符
String s = list.stream().map(Person::getName).collect(joining()); //结果:jackmiketom
String s = list.stream().map(Person::getName).collect(joining(",")); //结果:jack,mike,tom
四、并行流parallelStream
stream是串行的流式计算, parallelStream是并行的流式计算.
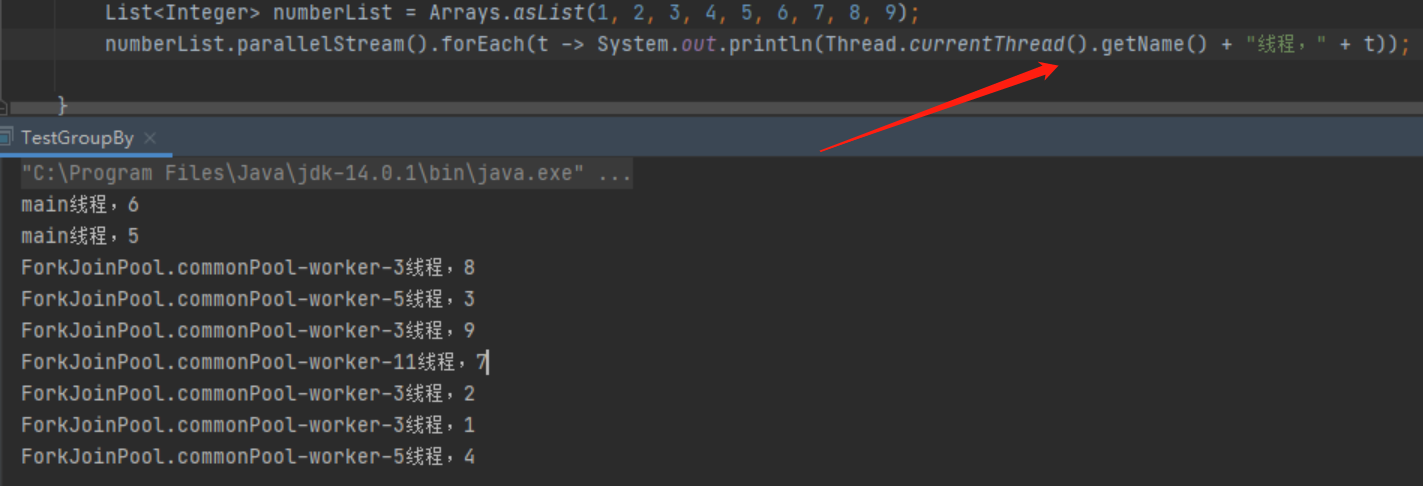
使用并行流遍历打印一个集合元素,并输出当前线程,可以看到线程抬头是ForkJoinPool.且遍历输出的元素是无序的
1、ForkJoin框架
- ForkJoin框架是java7中提供的并行执行框架
- 它的策略是分而治之。即将一个大任务拆分为若干互不依赖的子任务,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务
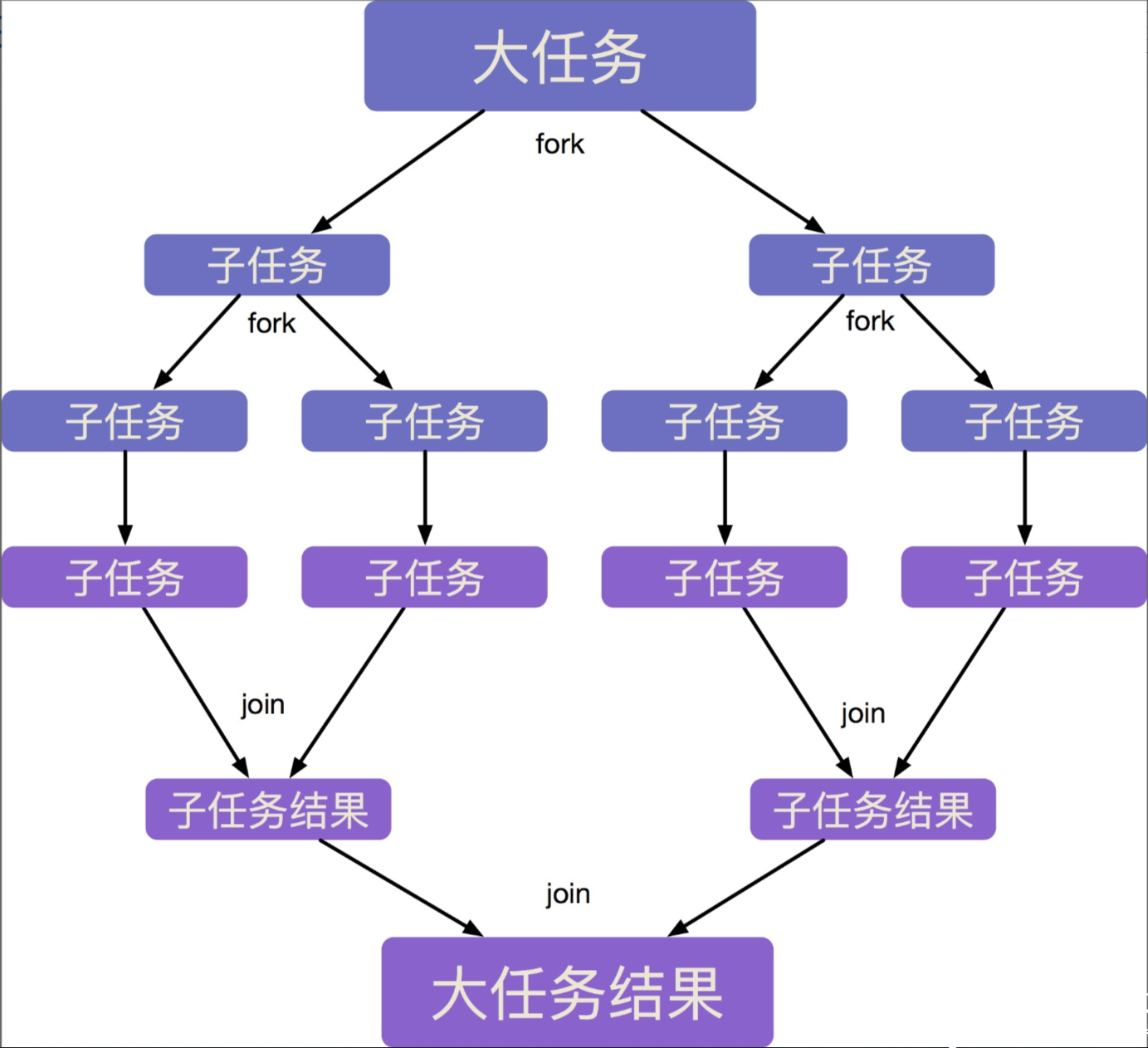
- 为了最大限度地提高并行处理能力,采用了 工作窃取算法 来运行任务,也就是说当某个线程处理完自己工作队列中的任务后,尝试当其他线程的工作队列中窃取一个任务来执行,直到所有任务处理完毕。(类比自己的任务做完了, 帮同事分一点任务,以求最早完成总任务)
- 为了减少线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行

2、parallelStream
- 调用ParallelStream() 和 Stream() 方法, 返回的都是一个流, 对forEach
- 并行流的创建可以xx.parallelStream()或者xx.stream().parallel()
- 并行流内部使用了默认的ForkJoinPool
- parallelStream默认的并发线程数比CPU处理器的数量少1个(最优的策略是每个CPU处理器分配一个线程,然而主线程也算一个线程)
// 获取当前机器CPU处理器的数量 System.out.println(Runtime.getRuntime().availableProcessors());// 输出 6 // parallelStream默认的并发线程数 System.out.println(ForkJoinPool.getCommonPoolParallelism());// 输出 5 // 设置全局并行流并发线程数 //这是全局配置,会影响所有的并行流 System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "3");
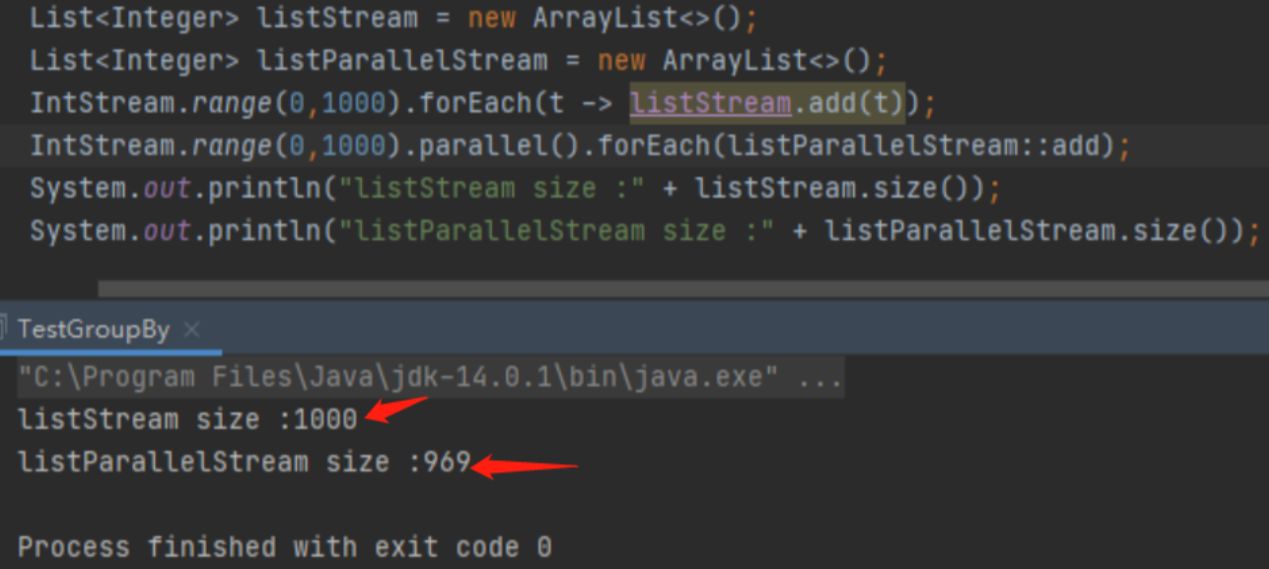
- parallelStream是线程不安全的
-
并发并不一定就能提高性能, CPU资源不足, 存在频繁的线程切换反而会降低性能
三、Collectors中的方法:

其中我们常用的是前三个:将流中的元素放到集合中、分组、toMap。 下面我们逐个介绍这些方法的使用.
//测试数据 public class Student { private Integer id; private String name; private String className; private Double score; private Long timeStamp; }
1、将流中的元素放到集合中:
-
toCollection(Supplier<C> collectionFactory) :
//源码 public static <T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) { return new CollectorImpl<>(collectionFactory, Collection<T>::add, (r1, r2) -> { r1.addAll(r2); return r1; }, CH_ID);
} //使用示例 List<Student> studentList = new ArrayList<>(); LinkedList<Integer> collect = studentList.stream().map(Student::getId).collect(Collectors.toCollection(LinkedList::new));
-
toList() 、toSet() :
List<Integer> list = studentList.stream().map(Student::getId).collect(Collectors.toList());
Set<String> nameSet = studentList.stream().map(Student::getName).collect(Collectors.toSet());
2、分组
-
groupingBy 它有三个重载方法:
//源码 public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function classifier) { return groupingBy(classifier, toList()); } public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(Function classifier, Collector downstream) { return groupingBy(classifier, HashMap::new, downstream); } public static <T, K, D, A, M extends Map<K, D>> Collector<T, ?, M> groupingBy(Function classifier, Supplier mapFactory, Collector downstream) { ...... }
第一个方法只需一个分组参数classifier,内部自动将结果保存到一个map中,每个map的键为 ‘?’ 类型(即classifier的结果类型),值为一个list,这个list中保存在属于这个组的元素。
但是它实际是调用了第二个方法-- Collector 默认为list。
而第二个方法实际是调用第三个方法,默认Map的生成方式为HashMap。
第三个方法才是真实完整的分组逻辑处理。
Stream<Student> stream = studentList.stream(); Map<Double, List<Student>> m1 = stream.collect(Collectors.groupingBy(Student::getScore)); Map<Double, Set<Student>> m2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toSet())); Map<Double, Set<Student>> m3 = stream.collect(Collectors.groupingBy(Student::getScore,TreeMap::new, Collectors.toSet()));
-
groupingByConcurrent
返回一个并发Collector收集器对T类型的输入元素执行"group by"操作, 也有三个重载的方法, 其使用与groupingBy 基本相同。
-
partitioningBy
该方法将流中的元素按照给定的校验规则的结果分为两个部分,放到一个map中返回,map的键是Boolean类型,值为元素的集合
//源码(两个重载方法) public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) { return partitioningBy(predicate, toList()); } public static <T, D, A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate, Collector<? super T, A, D> downstream) { ...... } //从上面的重载方法中可以看出,partitioningBy 与 groupingBy 类似, 只不过partitioningBy 生成的map的key的类型限制只能是Boolean类型。 //示例 Stream<Student> stream = studentList.stream(); Map<Boolean, List<Student>> m4 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60)); Map<Boolean, Set<Student>> m5 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60, Collectors.toSet()));
3、toMap
toMap方法是根据给定的键生成器和值生成器生成的键和值保存到一个map中返回,键和值的生成都依赖于元素,可以指定出现重复键时的处理方案和保存结果的map。
//源码(三个重载方法) public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper) { return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new); } public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction) { return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new); } public static <T, K, U, M extends Map<K, U>> Collector<T, ?, M> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction,Supplier mapSupplier){ ...... } //三个重载的方法,最终都是调用第三个方法来实现, 第一个方法中默认指定了key重复的处理方式和map的生成方式; 而第二个方法默认指定了map的生成方式,用户可以自定义key重复的处理方式。 //示例 Map<Integer, Student> map1 = stream.collect(Collectors.toMap(Student::getId, v->v)); Map<Integer, String> map2 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a)); Map<Integer, String> map3 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a, HashMap::new));
4、元素拼接joining
- joining() : 没有分隔符和前后缀,直接拼接
- joining(CharSequence delimiter) : 指定元素间的分隔符
- joining(CharSequence delimiter,CharSequence prefix, CharSequence suffix): 指定分隔符和整个字符串的前后缀。
Stream<String> stream = Stream.of("1", "2", "3", "4", "5", "6");
String s = stream.collect(Collectors.joining(",", "prefix", "suffix"));
//joining 之前,Stream 必须是Stream<String> 类型
5、类型转换
mapping:这个映射是首先对流中的每个元素进行映射,即类型转换,然后再将新元素以给定的Collector进行归纳。 类似与Stream的map方法。
collectingAndThen:在归纳动作结束之后,对归纳的结果进行再处理。
Stream<Student> stream = studentList.stream(); List<Integer> idList = stream.collect(Collectors.mapping(Student::getId, Collectors.toList())); Integer size = stream.collect(Collectors.collectingAndThen(Collectors.mapping(Student::getId, Collectors.toList()), o -> o.size()));
6、聚合
- counting: 同 stream.count()
- minBy: 同stream.min()
- maxBy: 同stream.max()
- summingInt:
- summingLong:
- summingDouble:
- averagingInt:
- averagingLong:
- averagingDouble:
Long count = stream.collect(Collectors.counting()); stream.count(); stream.collect(Collectors.minBy((a,b)-> a.getId() - b.getId())); stream.min(Comparator.comparingInt(Student::getId)); stream.collect(Collectors.summarizingInt(Student::getId)); stream.collect(Collectors.summarizingLong(Student::getTimeStamp)); stream.collect(Collectors.averagingDouble(Student::getScore));
7、reducing
reducing方法有三个重载方法,其实是和Stream里的三个reduce方法对应的,二者是可以替换使用的,作用完全一致,也是对流中的元素做统计归纳作用。
//源码(三个重载方法) public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) { ...... } public static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op) { ...... } public static <T, U> Collector<T, ?, U> reducing(U identity,Function mapper, BinaryOperator<U> op) { ...... }
//示例 List<String> list2 = Arrays.asList("123","456","789","qaz","wsx","edc"); Optional<Integer> optional = list2.stream().map(String::length).collect(Collectors.reducing(Integer::sum)); Integer sum1 = list2.stream().map(String::length).collect(Collectors.reducing(0, Integer::sum)); Integer sum2 = list2.stream().limit(4).collect(Collectors.reducing(0, String::length, Integer::sum));
//拓展:实际运用中,可能会用到比较复杂的 groupingBy、mapping、toMap 嵌套、组合使用,进行多级分组处理数据。如: Stream<Student> stream = studentList.stream(); // 根据score分组,并提取ID作为集合元素 Map<Double, List<Integer>> map1 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.mapping(Student::getId, Collectors.toList()))); // 根据score分组, 并将ID和name组成map作为元素 Map<Double, Map<Integer, String>> map2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toMap(Student::getId, Student::getName))); // 先根据score分组,再根据name进行二次分组 Map<Double, Map<String, List<Student>>> map3 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.groupingBy(Student::getName))); //当然也可以根据我们想要的条件,设置分组的组合条件,只需要替换 Student::getScore ,换成我们想要的条件即可, 如: Map<String, List<Integer>> map3 = stream.collect(Collectors.groupingBy(stu -> { if (stu.getScore() > 60) { return "PASS"; } else { return "FAIL"; } }, Collectors.mapping(Student::getId, Collectors.toList()))); //按照这种思路,我们可以随意处理stream中的元素成我们想要的结果数据。
转载:https://blog.csdn.net/llg___/article/details/129720760
转载:https://blog.csdn.net/zhoushimiao1990/article/details/128080919

 浙公网安备 33010602011771号
浙公网安备 33010602011771号