node50行代码实现壁纸爬取
刚入门node的cheerio模块,写了个特简单的壁纸爬虫玩玩
话不多说,先上成品图
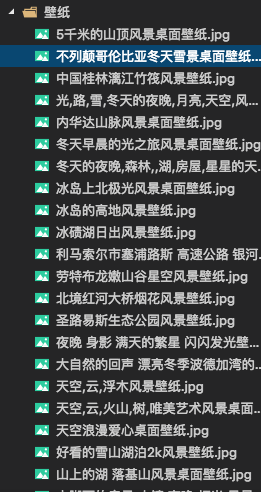


这里用到了http://www.netbian.com/fengjing
也可以爬妹纸图片哦。
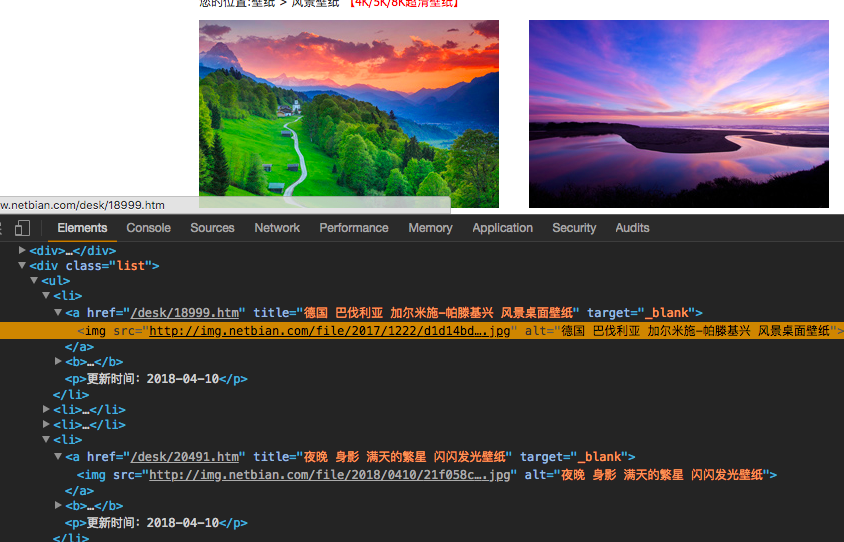
这里可以看到,图片区域放置于一个class为list的区域内,图片的img在a标签中,我们的目标就是获取图片的url和alt
首先
const cheerio = require("cheerio");
const fs = require("fs");
const request = require("request");
const iconv = require("iconv-lite");
这是个模块我就不多说了,至于iconv的作用在我另一篇文章里有介绍
我们先来实现获取图片信息,这里用到了request模块
request.get({ encoding: null, url: imgUrl }, function (err, res, body) { if (!err && res.statusCode == 200) { let html = iconv.decode(body, "gb2312"); //console.log(html); $ = cheerio.load(html); let lis = $(".list ul li a img"); //console.log(lis); for (let i = 0; i < lis.length; i++) { if (lis[i].attribs && i !== 2) { urls.push(lis[i].attribs); } } } else { console.log(err); } });
这里先用request获取网页的res.body信息,用cheerio.load转换为一个cheerio可操作的对象,后面的操作和jQuery是一样的
这样,我们获取的图片信息就存储在了urls数组中
下面加上下载图片的代码
request.get({ encoding: null, url: imgUrl }, function (err, res, body) { if (!err && res.statusCode == 200) { let html = iconv.decode(body, "gb2312"); //console.log(html); $ = cheerio.load(html); let lis = $(".list ul li a img"); //console.log(lis); for (let i = 0; i < lis.length; i++) { if (lis[i].attribs && i !== 2) { urls.push(lis[i].attribs); } } console.log(`开始下载...`); let startTime = new Date(); for (let i = 0; i < urls.length; i++) { request(urls[i].src, function (err, res, body) { if(err) { console.log(err); } }).pipe(fs.createWriteStream(`../壁纸/${urls[i].alt}.jpg`)); } let endTime = new Date(); console.log(`下载完成,共${urls.length}张图片,耗时${endTime-startTime}ms`) } else { console.log(err); } });
用函数封装起来,就是完整版啦
const cheerio = require("cheerio");
const fs = require("fs");
const request = require("request");
const iconv = require("iconv-lite");
let imgUrl = "http://www.netbian.com/fengjing/";
const urls = [];
//获取图片的地址和名字到urls中
function getImg(page) {
console.log(`正在获取第${page}页的图片`)
let path;//页数/index_?.htm
if (page === 1) {
path = "index.htm";
}
else if (typeof page !== "number" || page < 1) {
console.log("请输入正确的页数");
return;
}
else {
path = `index_${page}.htm`;
}
imgUrl += path;
request.get({
encoding: null,
url: imgUrl
},
function (err, res, body) {
if (!err && res.statusCode == 200) {
let html = iconv.decode(body, "gb2312");
//console.log(html);
$ = cheerio.load(html);
let lis = $(".list ul li a img");
//console.log(lis);
for (let i = 0; i < lis.length; i++) {
if (lis[i].attribs && i !== 2) {
urls.push(lis[i].attribs);
}
}
console.log(`开始下载...`);
let startTime = new Date();
for (let i = 0; i < urls.length; i++) {
request(urls[i].src, function (err, res, body) {
if(err) {
console.log(err);
}
}).pipe(fs.createWriteStream(`../壁纸/${urls[i].alt}.jpg`));
}
let endTime = new Date();
console.log(`下载完成,共${urls.length}张图片,耗时${endTime-startTime}ms`)
}
else {
console.log(err);
}
});
}
getImg(4);
这个入门级的爬虫功能还比较简单,我还会慢慢完善。最近在尝试一些复杂的爬虫,希望能和大家多多交流,共同进步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号