今日内容概要
- 发布订阅
- bitmap位图
- HyperLogLog
- GEO地理位置信息
- 持久化rdb
- 持久化aof
- 主从复制
内容详细
1、发布订阅
# 发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型升级(后订阅了,无法获取历史消息)---》观察者模式
# redis支持,不仅仅用redis可以实现---》消息队列:rabbimq都支持发布订阅
# 其中一个客户端发布消息
publish lqz:channel "hello world"
# 其他客户端订阅消息
subscribe lqz:channel # 一个客户端可以收听多个频道
# 只要客户端在这个频道发消息,所有订阅的都能收到
publish lqz:channel "hello world"
# 发布订阅和消息队列
消息队列---》多个客户端抢,谁抢到是谁的
发布订阅---》多个客户端都能收到
基本所有的专业的消息队列都支持发布订阅---》往消息队列中放一条消息,其实是消息队列这个软件负责把消息复制了多份,分别放到了订阅者订阅的队列中
2、bitmap位图
# 本质就是字符串类型
# 存到redis中,字符串会对应相应的二进制---》可以操作字符串的每个比特位
# 假设放了个big----》
set name big
getbit name 0 # 取到某个位置比特位
setbit name 7 1 # 把第7个位置设为1
bitcount name 0 3 # 取出起始位置到终止位置1的个数, 起始位置和终止位置指的是字节数
# 作用:独立用户统计---》统计日活
-用户id号,一般是自增数字----》假设10亿的用户量
-统计日活跃用户---》只要用户登录了就把用户id放到集合中,统计集合大小即可--》大数据量非常占空间
-go中:int8----》能表示数字范围 8个比特位 能表示数字范围:2的7次方-1
int类型:
int32----》2的31次方-1
-假设活跃用户5千万:
-使用集合:32位*5千万=200MB
-使用bitmap:1位*1亿=12.5MB # 只要登陆了,相应数字的位置设为1,没登陆是0
# 注意:
1 位图类型是string类型,最大512M # redis key和value类型最大能存多少?512m
2 使用 setbit时偏移量如果过大,会有较大消耗
3 位图不是绝对好用,需要合理使用
3、HyperLogLog
# 基于 HyperLogLog算法:
极小的空间完成独立数量统计---->本质还是字符串
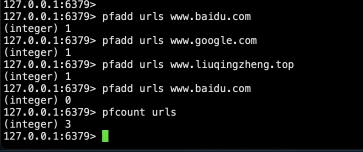
pfadd key element # 向hyperloglog添加元素,可以同时添加多个,自带去重
pfcount key # 计算hyperloglog的独立总数
pfmerge destroy sourcekey1 sourcekey2 # 把sourcekey1和sourcekey2的内容合并到destroy中
# 带去重,为什么不用集合?
-HyperLogLog只能放,不能取,只能做统计,和去重,占得空间比set小的都得多
-百万级别独立用户统计,百万条数据只占15k
-错误率 0.81%
-无法取出单条数据,只能统计个数
# 用户的主键id,可能不是数字,是uuid,唯一的字符串,如果用bitmap就做不了,就可以使用HyperLogLog
# 在能忍受有误差的情况下,使用HyperLogLog做独立用户统计或去重
![image]()
3.1 布隆过滤器
# bloomfilter:
是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素在一个集合内是否存在,具有很好的空间和时间效率
# 示例一:
from pybloom_live import ScalableBloomFilter
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
url = "www.cnblogs.com"
url2 = "www.liuqingzheng.top"
bloom.add(url)
print(url in bloom)
print(url2 in bloom)
# 示例二:
# BloomFilter 是定长的
from pybloom_live import BloomFilter
bf = BloomFilter(capacity=1000)
url='www.baidu.com'
bf.add(url)
print(url in bf)
print("www.liuqingzheng.top" in bf)
### redis实现布隆过滤器--》布隆不是官方的---》第三方使用c开发了---》编译---》so,dll文件动态链接库
# 把所有代码都打包到 xx.exe--->200m非常大---》go只能这样
# 动态链接(python 的包)---》可执行文件只有1kb---》从硬盘加载内存---》先占1kb内存--》运行---》动态加载dll,so文件----》完成后续的功能
# win下是 dll,linux是so文件---》C语言写的编译过后的动态链接库
# redis已经编译完成了---》挂载 布隆过滤器---》编译成so,redis启动时加载进去就行了
# go 语言代码编译成动态链接库,python调用
https://zhuanlan.zhihu.com/p/355538331
# 第三方提供了一些动态链接库,让我们使用---》华为硬件设备(摄像头)
# xx.so文件,说明文本(函数作用,参数)---》python写代码控制摄像头
# xx.so 内用c语言已经写好了,比如有个openVideo方法
from ctypes import cdll
lib = cdll.LoadLibrary('./s1.so')
lib.openVideo() # 打开了摄像头
4、GEO地理位置信息
# 地理位置信息:
GEO(地理信息定位):存储经纬度,计算两地距离,范围等,计算你跟xx店之间距离是多少,计算你方圆5公里内有多少你关注美女----》直线距离,不是路线距离
# 增加数据
geoadd redis的key 经度 纬度 名字
geoadd cities:locations 116.28 39.55 beijing
geoadd cities:locations 117.12 39.08 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
# 软件,app,经纬度,都是前端传给你的,app申请访问你的位置信息--》后台偷偷用借口传入到服务器---》存到redis中
# 获取经纬度
geopos cities:locations beijing # 取出是经纬度---》把经纬度转成具体位置
# 计算两个位置的距离
geodist cities:locations beijing tianjin km
# 计算某个位置方圆 100km内有哪些---》包括自己---》
georadiusbymember cities:locations beijing 100 km
5、持久化rdb
# redis的所有数据保存在内存中,对数据的更新将异步的保存到硬盘上
# 三种方案:
rdb,aof,混合持久化(rdb+aof)-->恢复更快
# 无论什么数据库,都会有相应的持久化方案
1 快照:某时某刻数据的一个完成备份
-mysql的Dump
-redis的RDB
2 写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可
-mysql的 Binlog
-Redis的 AOF
# rdb 三种触发形式
-第一种:客户端命令敲---》 save ---》同步,阻塞当前线程,把当前内存中数据保存到硬盘上
-redis的工作路径下会多出dump.rdb
-下次再启动会自动加载
-第二种:客户端命令敲---》 bgsave ---》异步保存
-第三种:配置文件
'''
自动(通过配置)
配置 seconds changes
save 900 1
save 300 10
save 60 10000
如果60s中改变了1w条数据,自动生成rdb
如果300s中改变了10条数据,自动生成rdb
如果900s中改变了1条数据,自动生成rdb
以上三条符合任意一条,就自动生成rdb,内部使用bgsave
'''
save 60 2
dbfilename lqz.rdb
# rdb方案可能会丢数据,但是如果redis只作为缓存数据库,这个就够了
6、持久化aof
# 日志方案---》每更改一条记录,都会记录一条日志
# 操作内存,速度非常快,记录日志---》日志要同步到硬盘---》跟不上节奏
# AOF的三种策略
always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件 # 基本跟不上
everysec(默认值):redis——》写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件
no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件
# AOF 重写
随着命令的逐步写入,并发量的变大, AOF文件会越来越大,通过AOF重写来解决该问题
本质就是把过期的,无用的,重复的,可以优化的命令,来优化
这样可以减少磁盘占用量,加速恢复速度
# 如何实现aof重写---》配置文件--》触发了配置条件,就会开启线程进行重写
appendonly yes # 将该选项设置为yes,打开aof持久化策略
appendfilename appendonly.aof # 文件保存的名字,aof日志的文件名,不写有默认
appendfsync everysec # 采用第二种策略
no-appendfsync-on-rewrite yes # 在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失
auto-aof-rewrite-min-size = 10 # AOF文件重写需要尺寸
auto-aof-rewrite-percentage= 2 # 文件增长率
# 咱们配置
appendonly yes
appendfilename appendonly.aof
appendfsync everysec
no-appendfsync-on-rewrite yes
# 混合持久化---》恢复速度问题
重启Redis时,我们很少使用rdb来恢复内存状态,因为会丢失大量数据。我们通常使用AOF日志重写
AOF重写性能相对rdb来说要慢很多
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化
重启,恢复的时候,使用rdb恢复,有差距的再用aof补上
# 配置---》记日志---》过一段时间---》把aof重写,rdb+日志
# aof一重写:rdb文件路径 + 后续的aof
aof-use-rdb-preamble yes
7、主从复制
# 单实例redis出现问题:
机器故障----》
容量瓶颈 ----》100g数据 内存64g,
QPS瓶颈----》
# 主从原理
一主一从,一主多从
做读写分离---》写数据写到主库---》读数据从从库读---》压力就小了
做数据副本---》从库和主库数据是完全一样的,主库被火烧了-->从库还有数据
一个maskter可以有多个slave
一个slave只能有一个master
数据流向是单向的,从master到slave # 从库不能再写入数据了
# reids主从原理
1. 副本库通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库
2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
3. 副本库接收后会应用RDB快照
4. 主库会陆续将中间产生的新的操作,保存并发送给副本库
5. 到此,我们主复制集就正常工作了
6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库.
7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在.
8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
# 要不要开启持久化---》一般开启持久化
如果不开有可能,主库重启操作,造成所有主从数据丢失!
# 主从辅助配置
min-slaves-to-write 1
min-slaves-max-lag 3
在从服务器的数量少于1个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
# 主从同步配置---》一台机器起两个redis进程模拟,正常应该有多台机器
# 方式一:命令方式
slaveof 127.0.0.1 6379 # 异步 从库中redis.conf配置
slaveof no one # 取消复制,不会把之前的数据清除
# 方式二:配置文件
# 在从库配置
slaveof 127.0.0.1 6379
slave-read-only yes
# 一主多从
只需要在从库配置上面两句就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号