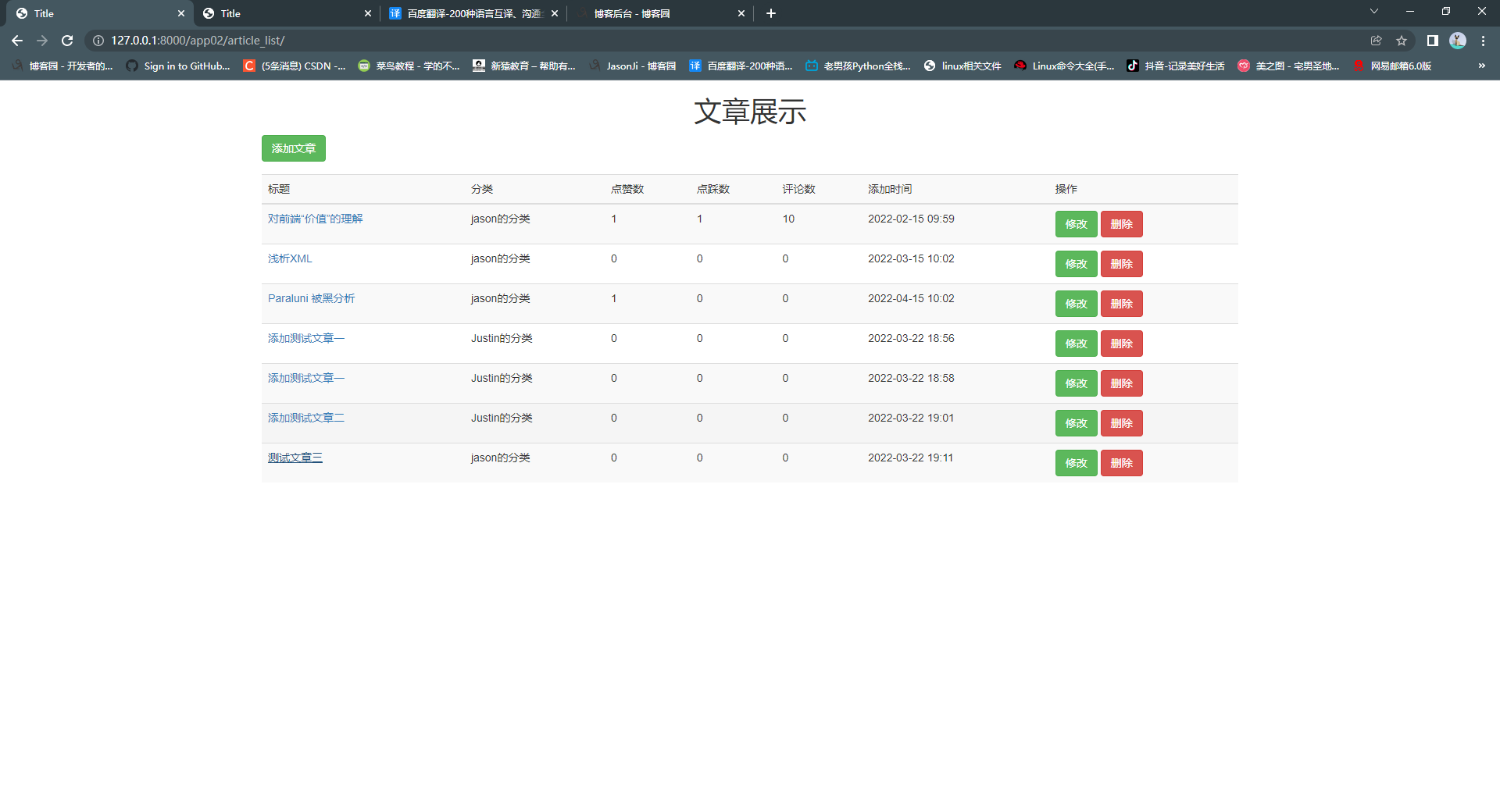
BBS项目补充知识(后台添加文章、修改文章功能完善)
1. 添加文章功能实现
from django.http import JsonResponse
def add_article(request):
if request.method == 'POST':
title = request.POST.get('title')
content = request.POST.get('content')
cate_id = request.POST.get('cate')
tag_list = request.POST.getlist('tags')
desc = content[0:100]
'''由于我们没有使用auth模块,所以,这里不能使用request.user,从session中手动获取'''
user_obj = models.UserInfo.objects.filter(pk=request.session.get('id')).first()
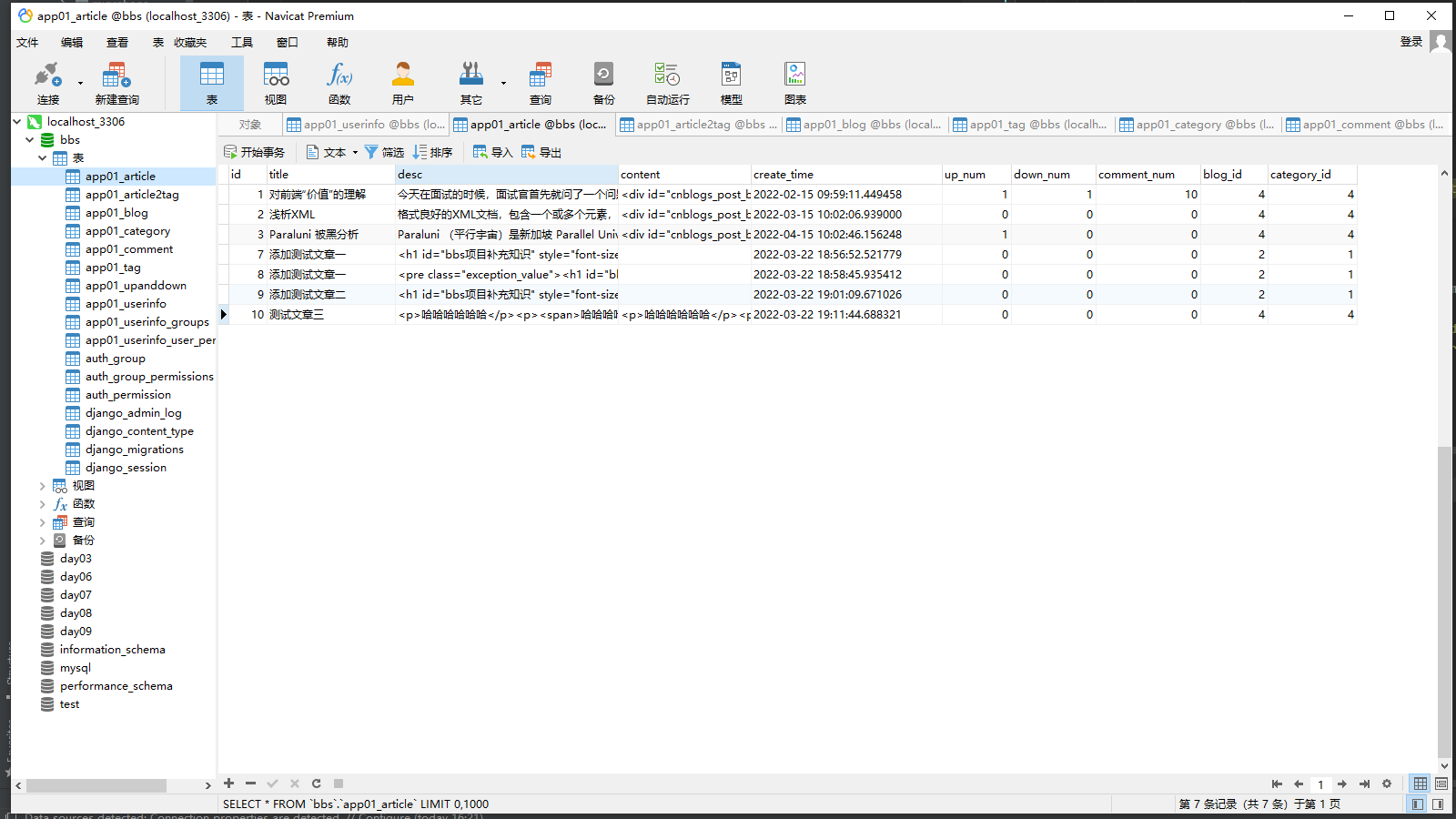
article_obj = models.Article.objects.create(title=title,
desc=desc,
content=content,
category_id=cate_id,
blog_id=user_obj.blog_id
)
'''由于操作数据库的次数过多,我们采用批量添加的形式,对数据库进行优化'''
article_obj_list = []
for i in tag_list:
tag_article_obj = models.Article2Tag(article_id=article_obj.pk, tag_id=i)
article_obj_list.append(tag_article_obj)
'''这样做的好处是:不管有多少个标签要入库,都是只操作一次数据库。'''
models.Article2Tag.objects.bulk_create(article_obj_list)
return redirect('/app02/article_list/')
cate_list = models.Category.objects.all()
tag_list = models.Tag.objects.all()
return render(request, 'backend/add_article.html', locals())
<div class="container-fluid">
<div class="row">
<h1 class="text-center">添加文章</h1>
<div class="col-md-8 col-md-offset-2">
<form action="" method="post">
<div class="form-group">
<label for="title">文章标题</label>
<input type="text" id="title" name="title" class="form-control">
</div>
<div class="form-group">
<label for="title">文章内容</label>
<textarea id="editor_id" name="content" style="width:500px;height:600px;"></textarea>
</div>
<div class="form-group">
<label for="title">文章分类</label>
<select name="cate" id="" class="form-control">
{% for cate in cate_list %}
<option value="{{ cate.pk }}">{{ cate.title }}</option>
{% endfor %}
</select>
</div>
<div class="form-group">
<label for="title">文章标签</label>
{% for tag in tag_list %}
<input type="checkbox" name="tags" value="{{ tag.pk }}"> {{ tag.title }}
{% endfor %}
</div>
<input type="submit" class="btn btn-success" value="提交">
</form>
</div>
</div>
</div>
2. 完善数据库存储信息
"""
数据库中文章表保存的文章内容是原生的html标签
为了截取文章的前100个汉字,不能使用直接切片,该方法截取出来的是html标签的范围
如何解决?
我们需要借助bs4模块,这个模块在爬虫当中用的超级多,是爬虫中用的最大的一个模块之一
"""
"""
为了截取文章的前100个汉字,不能使用该方法直接切片,截取出来的是html标签前100字符
# 如何解决?
我们需要借助bs4模块,这个模块在爬虫当中用的超级多,是爬虫中用的最大的一个模块之一
"""
soup = BeautifulSoup(content, 'lxml')
tags = soup.find_all()
for tag in tags:
'''针对xss攻击的核心:不能有script标签,如果没有这个标签,js代码就不会执行'''
print(tag.name)
if tag.name == 'script':
tag.decompose()
desc = soup.text[0:100]
'''由于我们没有使用auth模块,所以,这里不能使用request.user,从session中手动获取'''
user_obj = models.UserInfo.objects.filter(pk=request.session.get('id')).first()
article_obj = models.Article.objects.create(title=title,
desc=desc,
content=str(soup),
category_id=cate_id,
blog_id=user_obj.blog_id
)
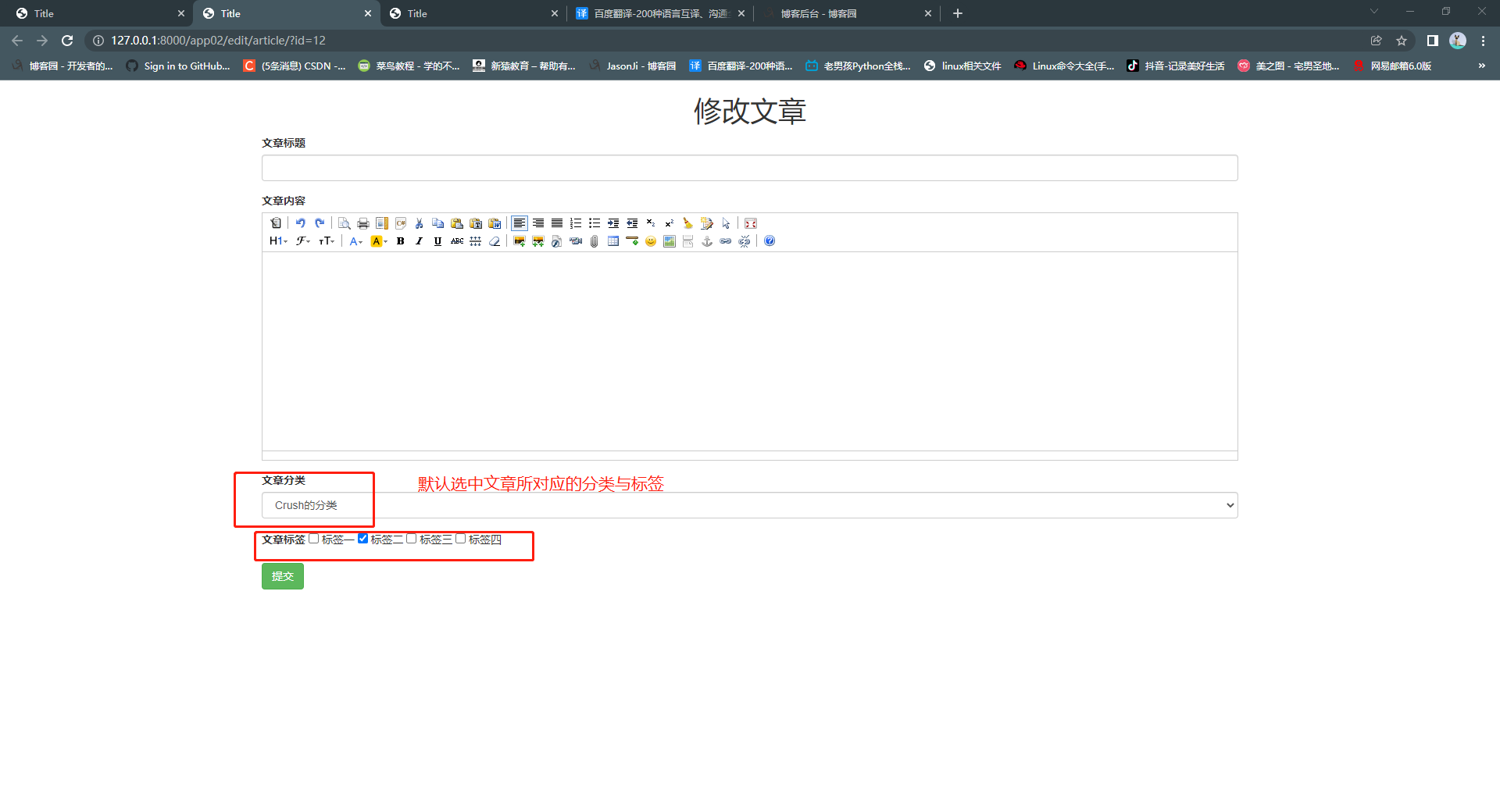
3. 修改文章功能前端页面逻辑实现
<a href="/app02/edit/article/?id={{ article.pk }}" target="_blank" class="btn btn-success">修改</a>
url(r'^edit/article/', views.edit_article),
def edit_article(request):
id = request.GET.get('id')
article_obj = models.Article.objects.filter(pk=id).first()
tag_ids_obj = models.Article2Tag.objects.filter(article_id=id).values_list('tag_id')
tag_ids = []
for tag in tag_ids_obj:
tag_id = tag[0]
tag_ids.append(tag_id)
cate_list = models.Category.objects.all()
tag_list = models.Tag.objects.all()
return render(request, 'backend/edit_article.html', locals())
"""将add_article.html内容复制过去并做部分修改即可 文章分类 文章标签 两个div即可"""
<div class="form-group">
<label for="title">文章分类</label>
<select name="cate" id="" class="form-control">
{% for cate in cate_list %}
{% if article_obj.category_id == cate.pk %}
<option value="{{ cate.pk }}" selected>{{ cate.title }}</option>
{% else %}
<option value="{{ cate.pk }}">{{ cate.title }}</option>
{% endif %}
{% endfor %}
</select>
</div>
<div class="form-group">
<label for="title">文章标签</label>
{% for tag in tag_list %}
{% if tag.pk in tag_ids %}
<input type="checkbox" name="tags" checked value="{{ tag.pk }}"> {{ tag.title }}
{% else %}
<input type="checkbox" name="tags" value="{{ tag.pk }}"> {{ tag.title }}
{% endif %}
{% endfor %}
</div>
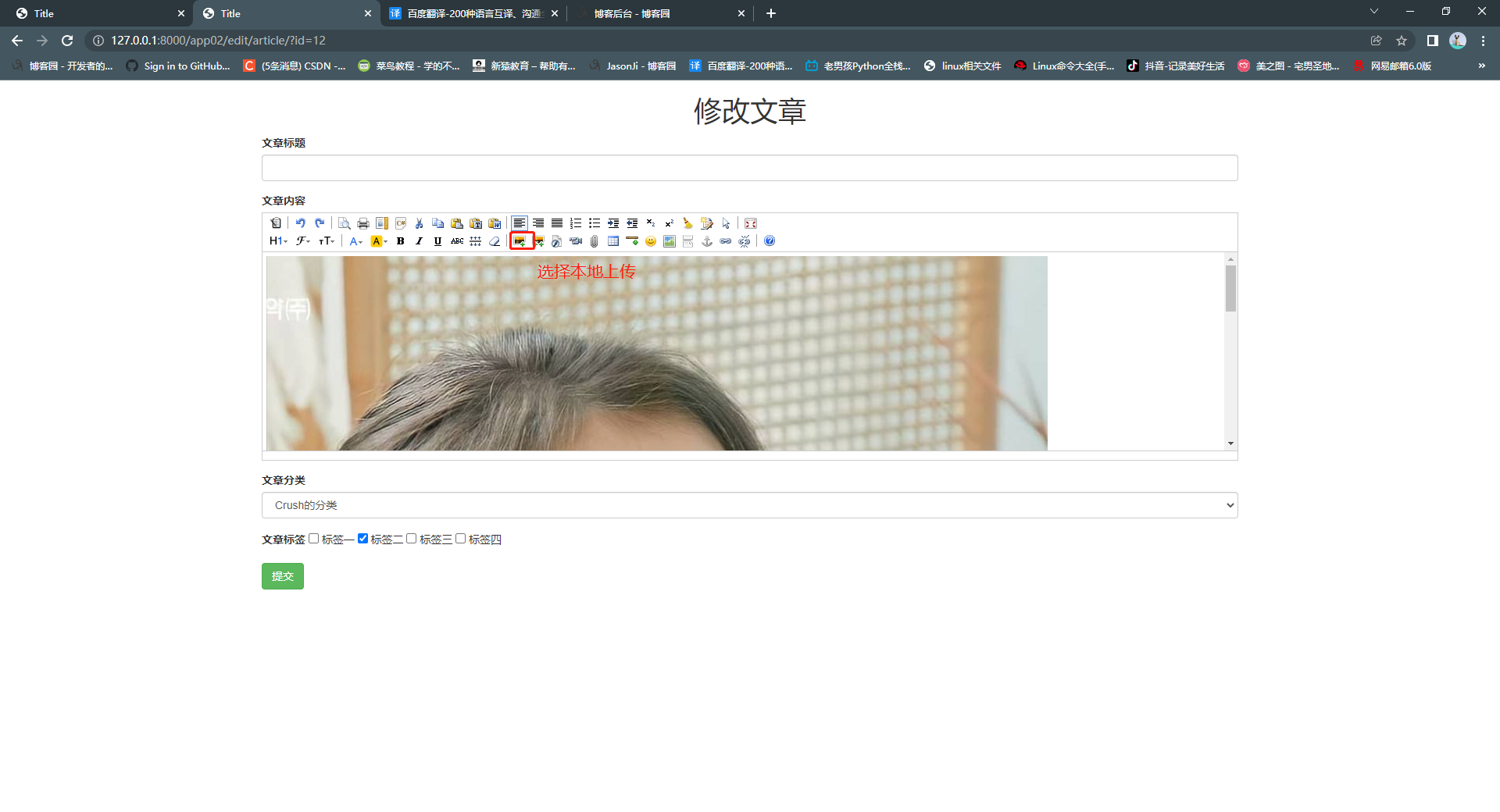
4. 富文本编辑器上传图片
resizeType: 0,
themeType: 'simple',
uploadJson:'/app02/upload_img/'
});
});
</script>
from django.views.static import serve
from django.conf import settings
url(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
url(r'^upload_img/', views.upload_img),
from django.http import JsonResponse
from django.conf import settings
import os
def upload_img(request):
'''
//成功时
{
"error" : 0,
"url" : "http://www.example.com/path/to/file.ext"
}
//失败时
{
"error" : 1,
"message" : "错误信息"
}
:param request:
:return:
'''
back_dic = {
"error": 0,
"url": ""
}
if request.method == 'POST':
file_obj = request.FILES.get('imgFile')
file_dir = os.path.join(settings.BASE_DIR, 'media', 'article_img')
if not os.path.exists(file_dir):
os.mkdir(file_dir)
'''
解决文件名被覆盖问题
1. 截取图片的后缀名
2. 生成随机字符串
3. 随机字符串 + 后缀名
'''
file_path = os.path.join(file_dir, file_obj.name)
with open(file_path, 'wb') as f:
for line in file_obj:
f.write(line)
back_dic['url'] = '/media/article_img/%s' % file_obj.name
return JsonResponse(back_dic)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现