数模-缺失值和异常值的处理
缺失值和异常值的处理
在数据既有缺失值又有异常值时,先处理哪个并没有严格的顺序。我习惯先处理异常值,再处理缺失值。
异常值的识别方法
异常值,指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群点。常见的异常值判断方法可以分为以下两种情况:
(1) 数据有一个给定范围
例如调查问卷中,需要对某个事物进行打分,满分为0-10分。如果填问卷的人填了一个30分,那么这个数据就是异常值。
这种情况比较简单,我们可以使用MATLAB的逻辑运算快速的找到这些异常值:
x = [8 9 10 7 6 3 30 4 13 9 2];
find(x<0 | x>10)
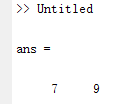
返回7和9,意味着第7个位置和第9个位置的元素不在0-10的范围内。
(2) 数据没有给定的范围
这种情况下我们介绍两种最常用的判定方法:
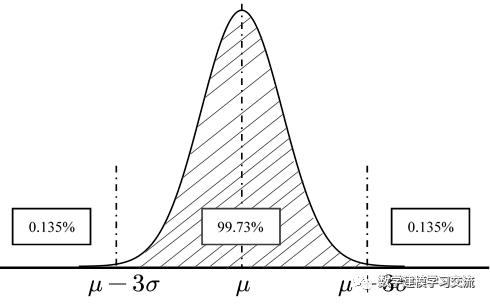

x = [48 51 57 57 49 86 48 53 59 50 48 47 53 56 60];
u = mean(x,'omitnan');
sigma = std(x,'omitnan');
lb = u - 3*sigma; % 区间下界,low bound的缩写
ub = u + 3*sigma; % 区间上界,upper bound的缩写
tmp = (x < lb) | (x > ub);
ind = find(tmp)
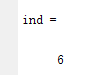
返回6,意味着第6个位置是异常值
第二:箱线图识别异常值
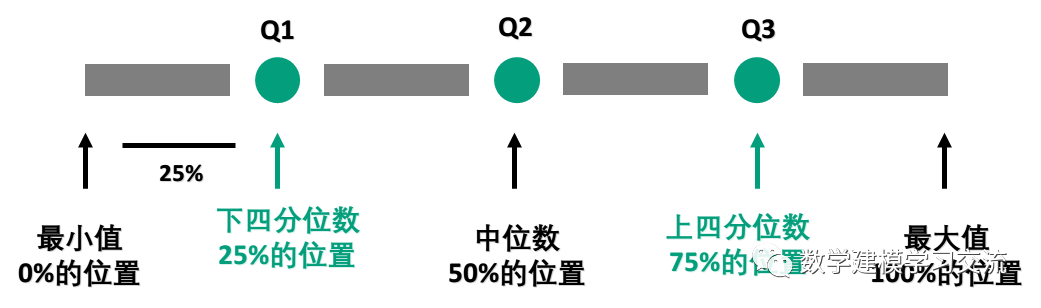
箱线图又称为盒须图、盒式图或箱形图,是一种用作显示数据分散情况资料的统计图,因形状如箱子而得名。下方左侧给出了一个用来反映某班男女同学身高分布情况的箱线图,右侧是箱线图上各元素所代表的含义。可以看到,箱线图可以反映数据的许多统计信息,例如均值、中位数、上四分位数和下四分位数。另外,箱线图中规定了数据的异常值,因此我们可以借助箱线图来识别数据的异常值,下面我们来介绍箱线图中异常值的定义方法。(注意:箱线图的画法不唯一,下面给的是一种典型画法)
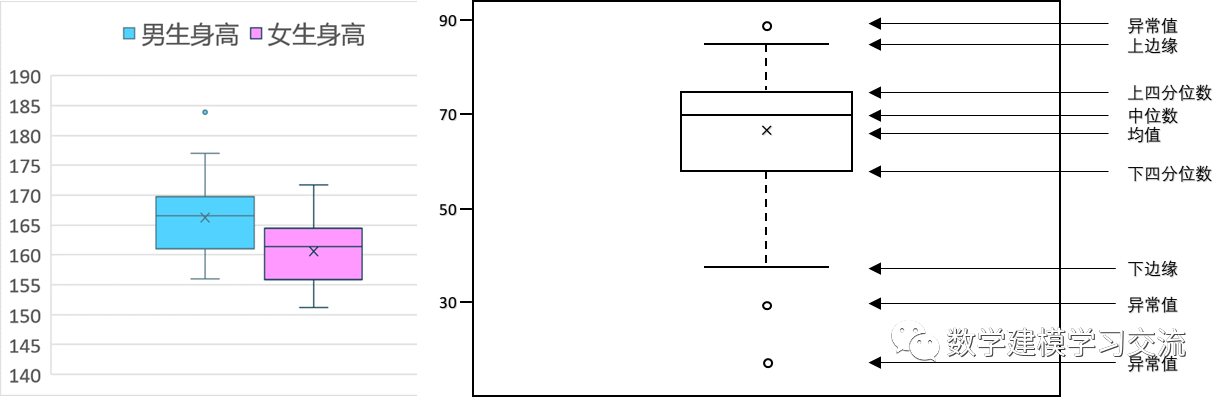
首先回顾下中位数的定义:我们将数据按从小到大的顺序排列,在排列后的数据中居于中间位置的数就是中位数,我们用Q2表示。
下四分位数则是位于排列后的数据25%位置上的数值,我们用Q1表示;上四分位数则是处在排列后的数据75%位置上的数值,我们用Q3表示。

x = [48 53 59 50 48 47 53 56 60 48 51 57 57 49 86];
% 计算分位数的函数需要MATLAB安装了统计机器学习工具箱
Q1 = prctile(x,25); % 下四分位数
Q3 = prctile(x,75); % 上四分位数
IQR = Q3-Q1; % 四分位距
lb = Q1 - 1.5*IQR; % 下界
ub = Q3 + 1.5*IQR; % 上界
tmp = (x < lb) | (x > ub);
ind = find(tmp)
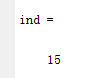
返回15,意味着第15个位置是异常值
识别出异常值后,我们通常可以将异常值视为缺失值,然后交给缺失值处理方法来处理。
缺失值的处理
如何处理数据的缺失值是一门很深的学问,事实上数据缺失在许多研究领域都是一个复杂的问题。下面我们介绍的只是一些比较简单的处理方法。
首先我们要计算异常值缺失的数量,举一个具体的例子,这是我随机生成的20个北京房价的数据,每一列是一个指标,每一行是一个样本:
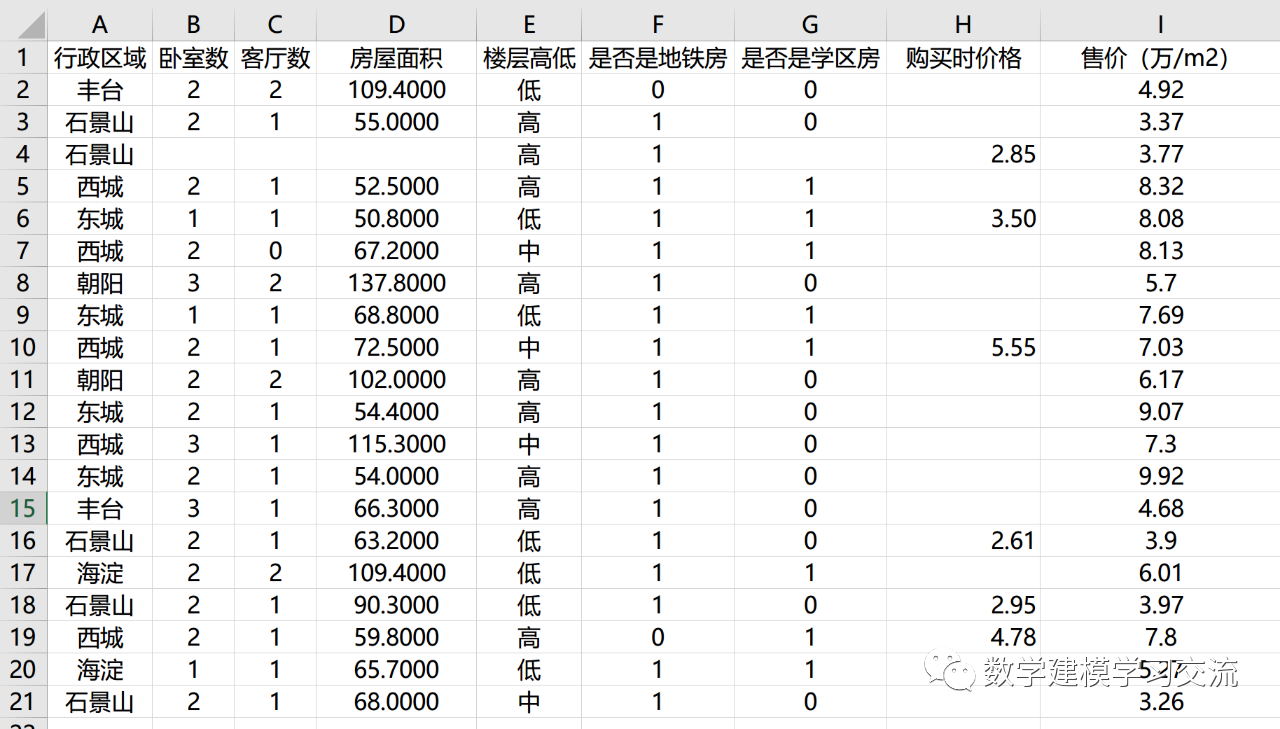
可以看到,“购买时价格”这个指标的缺失值有14个,占到总样本数的70%,缺失的有点太多了,所以这一个指标我们可以考虑删除。至于存在多大比例的缺失值我们可以接受,这个并没有一个标准,总之缺失值越少越好,缺的过多就要考虑删除。
另外,我们可以看到,位于BCDG四列的指标都有一个缺失值,但是这个缺失值都位于第4行的样本中,因此我们可以考虑直接删除这个样本。当然,如果你觉得样本搜集的成本过高或者样本量太少,你也考虑使用后面介绍的缺失值填补的方法。

上面的ismissing函数需要在2017版本以上的MATLAB里面运行,2016及以下的版本用下面的!
MATLAB中计算缺失值数量的函数非常简单,我们可以使用isnan函数和sum函数,下面举个例子:
A = [3,NaN,5,6,7,NaN,NaN,9];
TF = isnan(A)
% TF = 1x8 的逻辑数组(为1的位置表示是缺失值)
% 0 1 0 0 0 1 1 0
sum(TF)
% 对TF向量求和,结果为3,代表有3个缺失值

下面我们再来介绍缺失值填补,我们需要对缺失的数据类型进行区分:横截面数据和时间序列数据。这两种数据的缺失值处理方法有所不同。
横截面数据是指在某一时点收集的不同对象的数据,例如北京、上海、广州、深圳等30个城市今天的最高气温;时间序列数据是指对同一对象在不同时间连续观察所取得的数据,例如北京今年来每天的最高气温。

对于横截面数据,我们通常使用某个具体的数值来代替缺失值,例如非缺失数据的平均值、中位数或者众数。


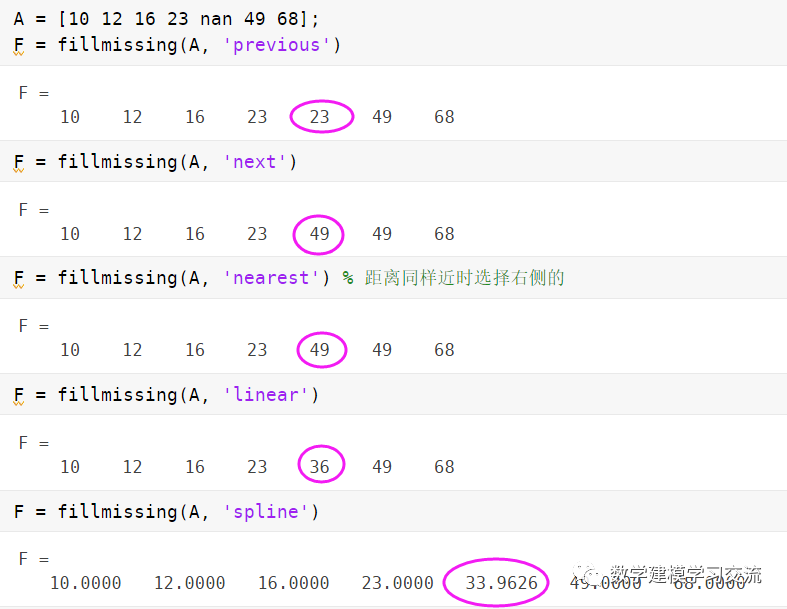
当然,我们这里介绍的方法比较简单,如果你专门做数据挖掘,还可以使用一些其他的方法来填补缺失值,例如KNN填补、随机森林填补、多重插补等方法。
