Python-统计txt文本中出现频率最高的词语
- Jieba是一个中文分词组件,可用于中文句子/词性分割、词性标注、未登录词识别,支持用户词典等功能。
- Matplotlib是Python中最常用的可视化工具之一,可以非常方便地创建海量类型的2D图表和一些基本的3D图表。
- 首先用pip安装需要的两个库
pip install jieba pip install matplotlib
- 实验代码
import jieba
from collections import Counter
import json
import matplotlib.pyplot as plt
import matplotlib
import sys
#在引入jieba模块后加入这行代码,代码即可不报错
jieba.setLogLevel(jieba.logging.INFO)
#解决matplotlib显示中文乱码的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family']='sans-serif'
xianni=open('paper.txt','r').read()
xianni_words = [x for x in jieba.cut(xianni) if len(x) >= 2] #将全文分割,并将大于两个字的词语放入列表
c=Counter(xianni_words).most_common(10) #取最多的10组
print(json.dumps(c, ensure_ascii=False))
name_list=[x[0] for x in c] #X轴的值
num_list=[x[1] for x in c] #Y轴的值
b=plt.bar(range(len(num_list)), num_list,tick_label=name_list)#画图
plt.xlabel(u'词语')
plt.ylabel(u'次数')
plt.title(u'文本分词统计')
plt.show()#展示
- 实验结果

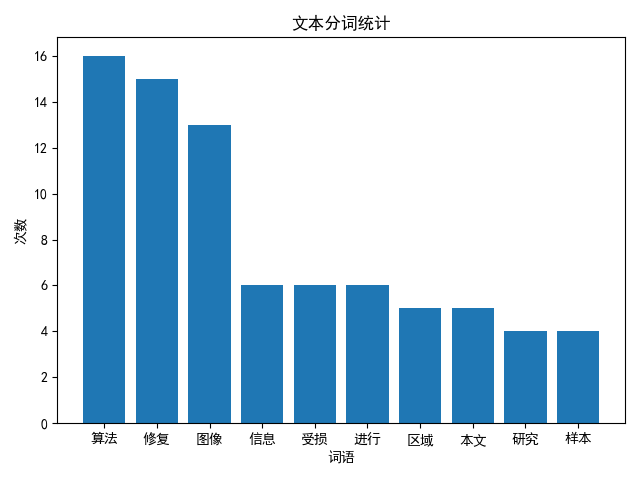
转载请注明出处,欢迎讨论和交流!

