PyTorch-CNN Model
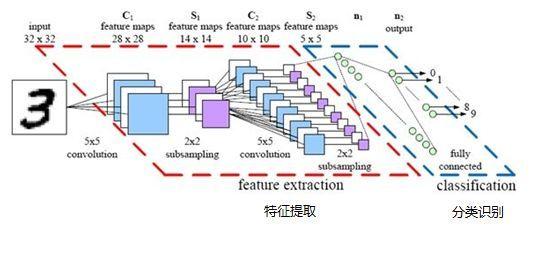
- 利用卷积神经网络对MINIST数据集进行训练
代码:
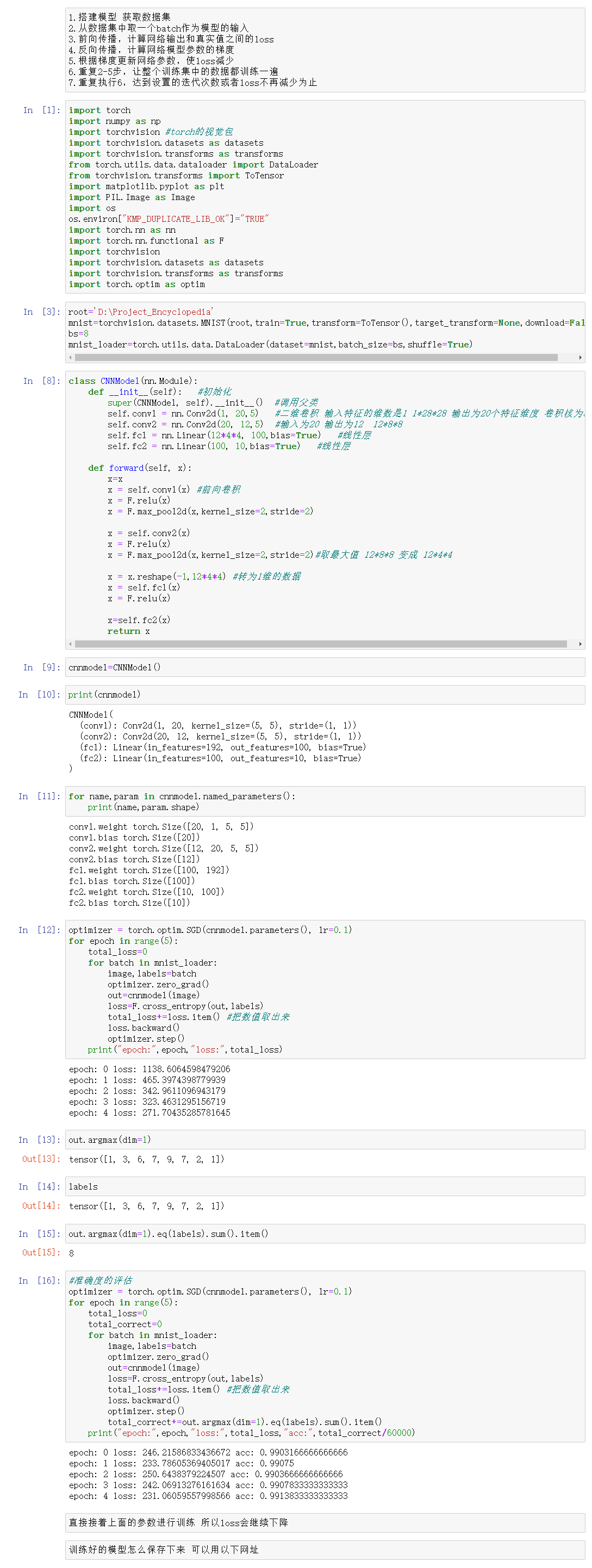
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | import torchimport numpy as npimport torchvision #torch的视觉包import torchvision.datasets as datasetsimport torchvision.transforms as transformsfrom torch.utils.data.dataloader import DataLoaderfrom torchvision.transforms import ToTensorimport matplotlib.pyplot as pltimport PIL.Image as Imageimport osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"import torch.nn as nnimport torch.nn.functional as Fimport torchvisionimport torchvision.datasets as datasetsimport torchvision.transforms as transformsimport torch.optim as optimroot='D:\Project_Encyclopedia'mnist=torchvision.datasets.MNIST(root,train=True,transform=ToTensor(),target_transform=None,download=False)bs=8mnist_loader=torch.utils.data.DataLoader(dataset=mnist,batch_size=bs,shuffle=True)class CNNModel(nn.Module): def __init__(self): #初始化 super(CNNModel, self).__init__() #调用父类 self.conv1 = nn.Conv2d(1, 20,5) #二维卷积 输入特征的维数是1 1*28*28 输出为20个特征维度 卷积核为5 self.conv2 = nn.Conv2d(20, 12,5) #输入为20 输出为12 12*8*8 self.fc1 = nn.Linear(12*4*4, 100,bias=True) #线性层 self.fc2 = nn.Linear(100, 10,bias=True) #线性层 def forward(self, x): x=x x = self.conv1(x) #前向卷积 x = F.relu(x) x = F.max_pool2d(x,kernel_size=2,stride=2) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x,kernel_size=2,stride=2)#取最大值 12*8*8 变成 12*4*4 x = x.reshape(-1,12*4*4) #转为1维的数据 x = self.fc1(x) x = F.relu(x) x=self.fc2(x) return xcnnmodel=CNNModel()print(cnnmodel)for name,param in cnnmodel.named_parameters(): print(name,param.shape)optimizer = torch.optim.SGD(cnnmodel.parameters(), lr=0.1)for epoch in range(5): total_loss=0 for batch in mnist_loader: image,labels=batch optimizer.zero_grad() out=cnnmodel(image) loss=F.cross_entropy(out,labels) total_loss+=loss.item() #把数值取出来 loss.backward() optimizer.step() print("epoch:",epoch,"loss:",total_loss)out.argmax(dim=1)labelsout.argmax(dim=1).eq(labels).sum().item()#准确度的评估optimizer = torch.optim.SGD(cnnmodel.parameters(), lr=0.1)for epoch in range(5): total_loss=0 total_correct=0 for batch in mnist_loader: image,labels=batch optimizer.zero_grad() out=cnnmodel(image) loss=F.cross_entropy(out,labels) total_loss+=loss.item() #把数值取出来 loss.backward() optimizer.step() total_correct+=out.argmax(dim=1).eq(labels).sum().item() print("epoch:",epoch,"loss:",total_loss,"acc:",total_correct/60000) |
- 训练好的模型怎么保存下来
1 | #http://www.jianshu.com/p/4905bf8e06e5 |
可以查看上述的网站 有两种方法可以进行保存
1 2 3 4 | #http://www.jianshu.com/p/4905bf8e06e5torch.save(cnnmodel,'D:/Project_Encyclopedia/cnnmodel.pkl')#还有别的保存方法torch.save(cnnmodel.state_dict(),'D:/Project_Encyclopedia/cnnmodel.pt') |

- Pooling Layer(池化层
在卷积神经网络中,卷积层之间往往会加上一个池化层。池化层可以非常有效地缩小参数矩阵的尺寸,从而减少最后全连层中的参数数量。使用池化层即可以加快计算速度也有防止过拟合的作用。在图像识别领域,有时图像太大,我们需要减少训练参数的数量,它被要求在随后的卷积层之间周期性地引进池化层。池化的唯一目的是减少图像的空间大小。池化在每一个纵深维度上独自完成,因此图像的纵深保持不变。池化层的最常见形式是最大池化,还有平均池化层。即对一块局部的特征做求最大值的操作或者做求平均值的操作。
- Batch Normalization
1)加快训练速度,这样我们就可以使用较大的学习率来训练网络。
2)提高网络的泛化能力。
3)BN层本质上是一个归一化网络层,可以替代局部响应归一化层(LRN层)。
4)可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)。

1.计算样本均值。
2.计算样本方差。
3.样本数据标准化处理。
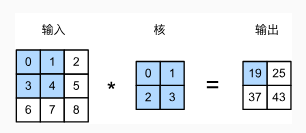
- 卷积神经网络和卷积核的运转
- 将batch_size改为32 并对网络进行调整
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 | import torchimport numpy as npimport torchvision #torch的视觉包import torchvision.datasets as datasetsimport torchvision.transforms as transformsfrom torch.utils.data.dataloader import DataLoaderfrom torchvision.transforms import ToTensorimport matplotlib.pyplot as pltimport PIL.Image as Imageimport osos.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"import torch.nn as nnimport torch.nn.functional as Fimport torchvisionimport torchvision.datasets as datasetsimport torchvision.transforms as transformsimport torch.optim as optimroot='D:\Project_Encyclopedia'mnist=torchvision.datasets.MNIST(root,train=True,transform=ToTensor(),target_transform=None,download=False)mnistdata=[d[0].data.cpu().numpy() for d in mnist]np.mean(data) #整个数据集的均值np.std(data) #整个数据集的标准差bs=32train_dataloader=torch.utils.data.DataLoader( dataset=torchvision.datasets.MNIST(root,train=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))]), target_transform=None,download=False), batch_size=bs, shuffle=True, pin_memory=True)test_dataloader=torch.utils.data.DataLoader( dataset=torchvision.datasets.MNIST(root,train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))]), target_transform=None,download=False), batch_size=bs, shuffle=True, pin_memory=True)class CNNModel(nn.Module): def __init__(self): #初始化 super(CNNModel, self).__init__() #调用父类 self.conv1 = nn.Conv2d(1, 20,5,1) # 1维->20维 卷积核大小为5 self.conv2 = nn.Conv2d(20, 50,5,1) # 20维->50维 卷积核大小为5 self.fc1 = nn.Linear(4*4*50, 500) #线性层 self.fc2 = nn.Linear(500, 10) #线性层 def forward(self, x): #x:1*28*28 1代表通道 x = F.relu(self.conv1(x)) #前向卷积 28*28 -> (28+1-5)=24 24*24 x = F.max_pool2d(x,kernel_size=2,stride=2) #12*12 x = F.relu(self.conv2(x)) #8*8 x = F.max_pool2d(x,kernel_size=2,stride=2)#4*4 x = x.reshape(-1,4*4*50) #或者用 x = x.view(-1,4*4*50) x = F.relu(self.fc1(x)) x=self.fc2(x) return F.log_softmax(x,dim=1)cnnmodel=CNNModel()print(cnnmodel)for name,param in cnnmodel.named_parameters(): print(name,param.shape)optimizer = torch.optim.SGD(cnnmodel.parameters(), lr=0.1,momentum=0.5)for epoch in range(5): total_loss=0 for batch in train_dataloader: image,labels=batch optimizer.zero_grad() out=cnnmodel(image) loss=F.cross_entropy(out,labels) total_loss+=loss.item() #把数值取出来 loss.backward() optimizer.step() print("epoch:",epoch,"loss:",total_loss)out.argmax(dim=1)labelsout.argmax(dim=1).eq(labels).sum().item()#准确度的评估optimizer = torch.optim.SGD(cnnmodel.parameters(), lr=0.1,momentum=0.5)for epoch in range(5): total_loss=0 total_correct=0 for batch in train_dataloader: image,labels=batch optimizer.zero_grad() out=cnnmodel(image) loss=F.cross_entropy(out,labels) total_loss+=loss.item() #把数值取出来 loss.backward() optimizer.step() total_correct+=out.argmax(dim=1).eq(labels).sum().item() print("epoch:",epoch,"loss:",total_loss,"acc:",total_correct/60000)#http://www.jianshu.com/p/4905bf8e06e5torch.save(cnnmodel,'D:/Project_Encyclopedia/cnnmodel.pkl')#还有别的保存方法torch.save(cnnmodel.state_dict(),'D:/Project_Encyclopedia/cnnmodel.pt') |

转载请注明出处,欢迎讨论和交流!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具