PyTorch-利用神经网络对常见水果进行分类(CPU没有跑出结果)
Kaggle Fruits360 数据集包含131种不同类型的水果和蔬菜的90483张图像。
数据集
https://blog.csdn.net/weixin_42216109/article/details/105826026
或者也可以从下面这个链接下载
数据集:https://www.kaggle.com/moltean/fruits
代码链接:https://jovian.ml/limyingying2000/fruitsfinal
公众号文章链接:https://mp.weixin.qq.com/s/f5OVv36AMX_EfH-JJ4RhFA
首先,我们导入数据和所需的库。
#导入所需要的库
import torch
import os
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
导入训练集和测试集
dataset=ImageFolder('./fruits-360/Training',transform=ToTensor())
test=ImageFolder('./fruits-360/Test',transform=ToTensor())
print('Size of raw dataset :',len(dataset))
print('Size of test dataset :',len(test))

把训练集中67692图像取出10000张作为验证集,57692作为训练集
#把训练集中67692图像取出10000张作为验证集,57692作为训练集
#设置随机种子
random_seed = 42
torch.manual_seed(random_seed);
val_size=10000 #验证集
train_size=len(dataset)-val_size #训练集
train_ds,val_ds=random_split(dataset,[train_size,val_size])
print(len(train_ds)) #输出训练集的图像数目
print(len(val_ds)) #输出验证集的图像数目

随机导入数据集 输出Apple Pink Lady文件夹中5张图片的名称
#随机导入数据集
jovian.log_dataset(data_dir = './fruits-360', val_size=val_size, random_seed=random_seed)
Apple_Pink_Lady_File = os.listdir('./fruits-360/Training/Apple Pink Lady')
print('No. of training examples for Apple Pink Lady:', len(Apple_Pink_Lady_File)) #输出Apple Pink Lady文件夹中图片的数目
print(Apple_Pink_Lady_File[:5]) #输出Apple Pink Lady文件夹中5张图片的名称
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
#print(Apple_Pink_Lady_File) #输出Apple Pink Lady文件夹中所有图片的名称

随机导入数据集 输出 Banana 文件夹中5张图片的名称
#随机导入数据集
jovian.log_dataset(data_dir = './fruits-360', val_size=val_size, random_seed=random_seed)
Banana_File = os.listdir('./fruits-360/Training/Banana') #输出Banana文件夹中图片的数目
print('No. of training examples for Banana:', len(Banana_File))
print(Banana_File[:5]) #输出Banana文件夹中5张图片的名称

fruits-360文件夹中整个结构为
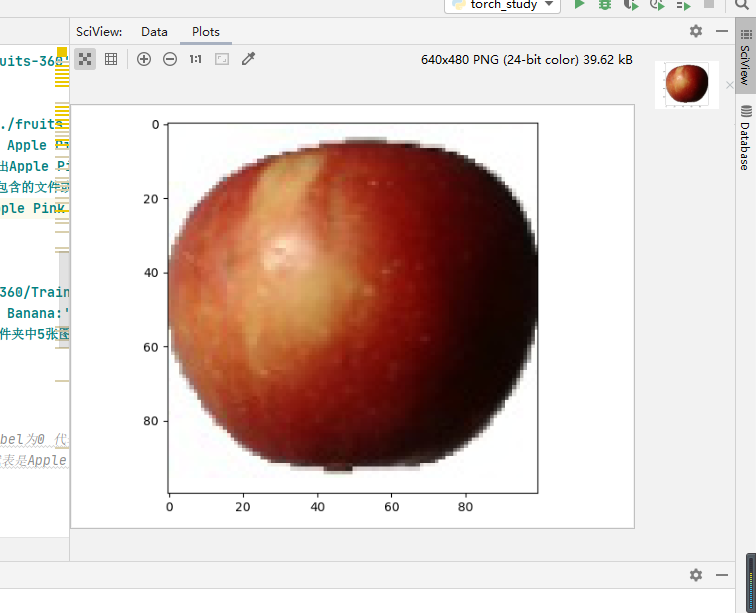
使用matplotlib库显示彩色图像
def show_example(img, label):
print('Label: ', dataset.classes[label], "("+str(label)+")")
plt.imshow(img.permute(1, 2, 0))
#permute(dims) 将tensor的维度换位。原来是3×100×100 现在变成100×100×3
img, label = dataset[0]
#dataset里面的0 是第1张图片 他所对应的label为0 代表是Apple Braeburn
#当dataset里面是492 所对应的label是1 代表是Apple Crimson Snow
print(img.shape, label)
print(img) #输出图片信息
show_example(img,label)
plt.show()


有3个通道(红,绿,蓝) ,100 * 100图像大小。每个值表示颜色强度相对于通道颜色。
输出数据集中的所有类别
print(dataset.classes) #输出数据集中的所有类别

Data Exploratory
Apple Red Delicious (10)
# Apple Red Delicious (10)
show_example(*dataset[5000])
# 在参数名之前使用—个星号,就是让函数接受任意多的位置参数
plt.show()

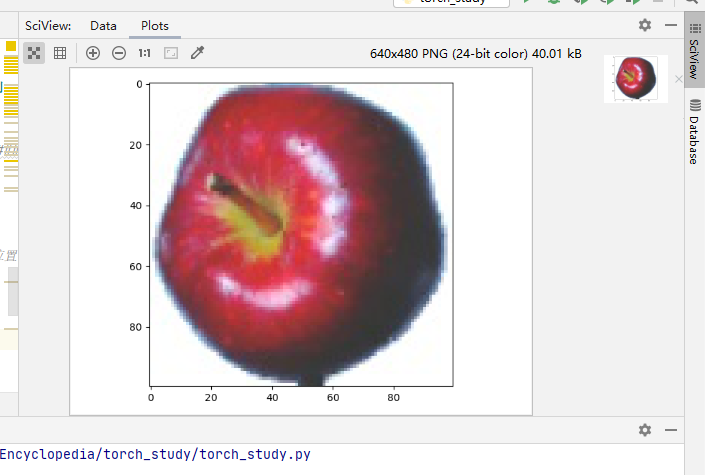
Apple Golden 1 (2)
#Apple Golden 1 (2)
show_example(*dataset[1000])
# 在参数名之前使用—个星号,就是让函数接受任意多的位置参数
plt.show()
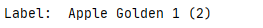
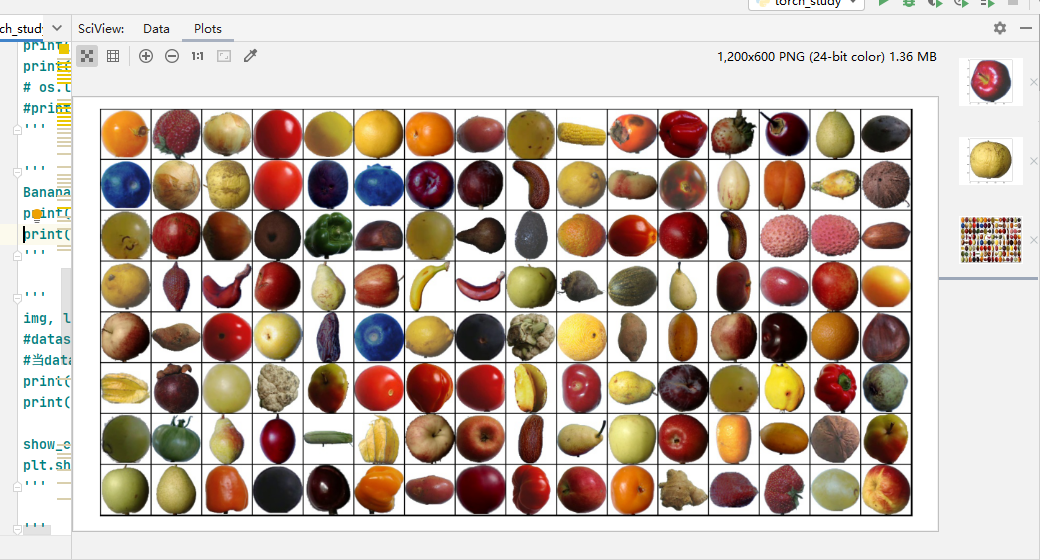
Dataloader
数据集的划分

分批训练
由于我们总共有57,692个训练图像,在使用 Dataloader 训练模型之前,我们应该将图像分成更小的批量。使用较小的数据集会减少内存空间,从而提高训练速度。
对于我们的数据集,我们将设置 batch 为 128。
batch_size=128
train_dl = DataLoader(train_ds, batch_size, shuffle=True,pin_memory=True)
val_dl = DataLoader(val_ds, batch_size*2, pin_memory=True)
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))
break
show_batch(train_dl)
plt.show()
代码
#导入所需要的库
import torch
import os
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
def show_example(img, label):
print('Label: ', dataset.classes[label], "("+str(label)+")")
plt.imshow(img.permute(1, 2, 0))
#permute(dims) 将tensor的维度换位。原来是3×100×100 现在变成100×100×3
dataset=ImageFolder('./fruits-360/Training',transform=ToTensor())
test=ImageFolder('./fruits-360/Test',transform=ToTensor())
#print('Size of raw dataset :',len(dataset))
#print('Size of test dataset :',len(test))
#把训练集中67692图像取出10000张作为验证集,57692作为训练集
#设置随机种子
random_seed = 42
torch.manual_seed(random_seed);
val_size=10000 #验证集
train_size=len(dataset)-val_size #训练集
train_ds,val_ds=random_split(dataset,[train_size,val_size])
# print(len(train_ds)) #输出训练集的图像数目
# print(len(val_ds)) #输出验证集的图像数目
#随机导入数据集
jovian.log_dataset(data_dir = './fruits-360', val_size=val_size, random_seed=random_seed)
'''
Apple_Pink_Lady_File = os.listdir('./fruits-360/Training/Apple Pink Lady')
print('No. of training examples for Apple Pink Lady:', len(Apple_Pink_Lady_File)) #输出Apple Pink Lady文件夹中图片的数目
print(Apple_Pink_Lady_File[:5]) #输出Apple Pink Lady文件夹中5张图片的名称
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
#print(Apple_Pink_Lady_File) #输出Apple Pink Lady文件夹中所有图片的名称
'''
'''
Banana_File = os.listdir('./fruits-360/Training/Banana') #输出Banana文件夹中图片的数目
print('No. of training examples for Banana:', len(Banana_File))
print(Banana_File[:5]) #输出Banana文件夹中5张图片的名称
'''
'''
img, label = dataset[0]
#dataset里面的0 是第1张图片 他所对应的label为0 代表是Apple Braeburn
#当dataset里面是492 所对应的label是1 代表是Apple Crimson Snow
print(img.shape, label)
print(img) #输出图片信息
show_example(img,label)
plt.show()
'''
'''
print(dataset.classes) #输出数据集中的所有类别
'''
##################### Data Exploratory ############################
'''
# Apple Red Delicious (10)
show_example(*dataset[5000])
# 在参数名之前使用—个星号,就是让函数接受任意多的位置参数
plt.show()
'''
'''
#Apple Golden 1 (2)
show_example(*dataset[1000])
# 在参数名之前使用—个星号,就是让函数接受任意多的位置参数
plt.show()
'''
#################### Dataloader ##################################
batch_size=128
train_dl = DataLoader(train_ds, batch_size, shuffle=True,pin_memory=True)
val_dl = DataLoader(val_ds, batch_size*2, pin_memory=True)
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))
break
show_batch(train_dl)
plt.show()
现在,我们将开始构建我们的模型
由于CPU没有跑出结果 我就只进行了CNN模型的搭建
#导入所需要的库
import torch
import os
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import jovian
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
from torch_study import train_dl
class FruitsModel(nn.Module):
def __init__(self):
super(FruitsModel,self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 3 channels to 32 channels
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.conv6 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(256 * 5 * 5, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 131)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.max_pool2d(x,kernel_size=2, stride=2)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.max_pool2d(x,kernel_size=2, stride=2)
x = F.relu(self.conv5(x))
x = F.relu(self.conv6(x))
x = F.max_pool2d(x,kernel_size=5, stride=5)
x = x.reshape(-1, 256 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x,dim=1)
#创建网络实例
fruitsmodel=FruitsModel()
print(fruitsmodel)
for name,param in fruitsmodel.named_parameters():
print(name,param.shape)
#准确度的评估
optimizer=torch.optim.SGD(fruitsmodel.parameters(),lr=0.1,momentum=0.5)
for epoch in range(5):
total_loss=0
total_correct=0
for batch in train_dl:
image,labels=batch
optimizer.zero_grad()
out=fruitsmodel(image)
loss=F.cross_entropy(out,labels)
total_loss+=loss.item() #把数值取出来
loss.backward()
optimizer.step()
total_correct+=out.argmax(dim=1).eq(labels).sum().item()
print("epoch:",epoch,"loss:",total_loss,"acc:",total_correct/57692)
会输出网络结构及参数
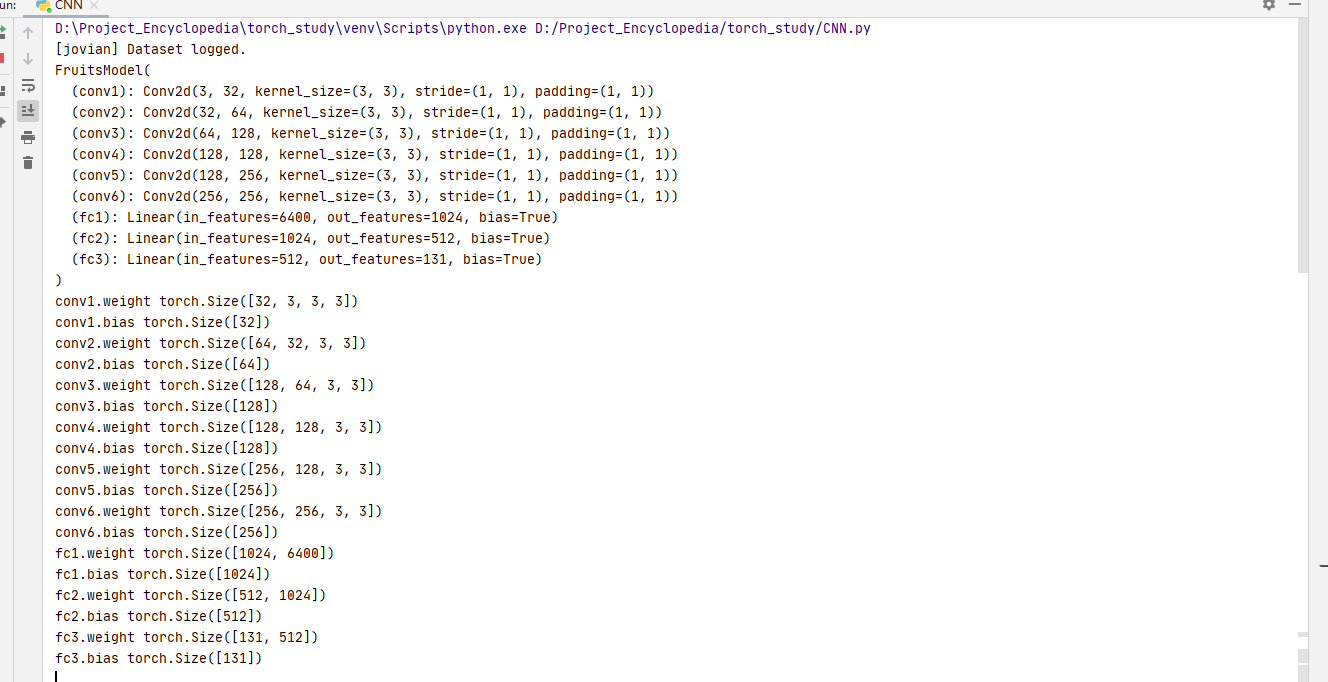
但是在CPU上没有跑出结果 很可惜
转载请注明出处,欢迎讨论和交流!

