网络爬虫分析b站弹幕生成词云
引言:这几天正不知道写点分析点什么有意思的事情,于是去b站上我的日常大学去了。我不看“微薄”的·,比较喜欢在b站去水。这两天突然看到推到热搜的力宏的视频。打开一看,也就这两天的弹幕。不管了,先分析一波力宏的弹幕。做一个吃瓜群众的弹幕词云。岂不妙哉?

上次做过一个很励志的弹幕,这次也这样做,代码基本没有改变。因为个人后面做的分词基本都是一样的。但是每次分析网站并没有那么简单。这次还得去重新从b站去检查源代码,去抓取关键的信息。以及处理cookis。等等。后面的图片也需要合理去改,不然就会
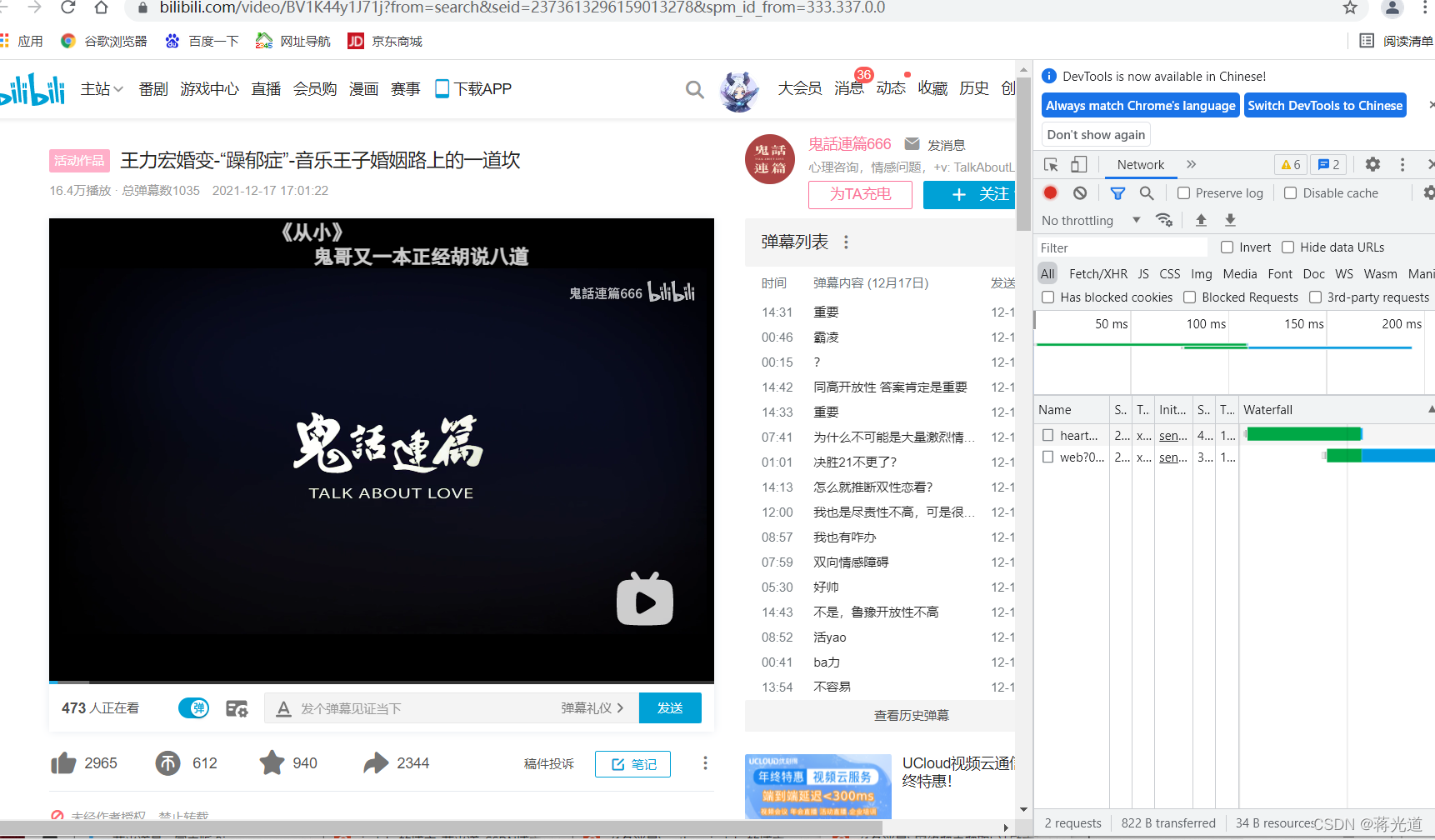
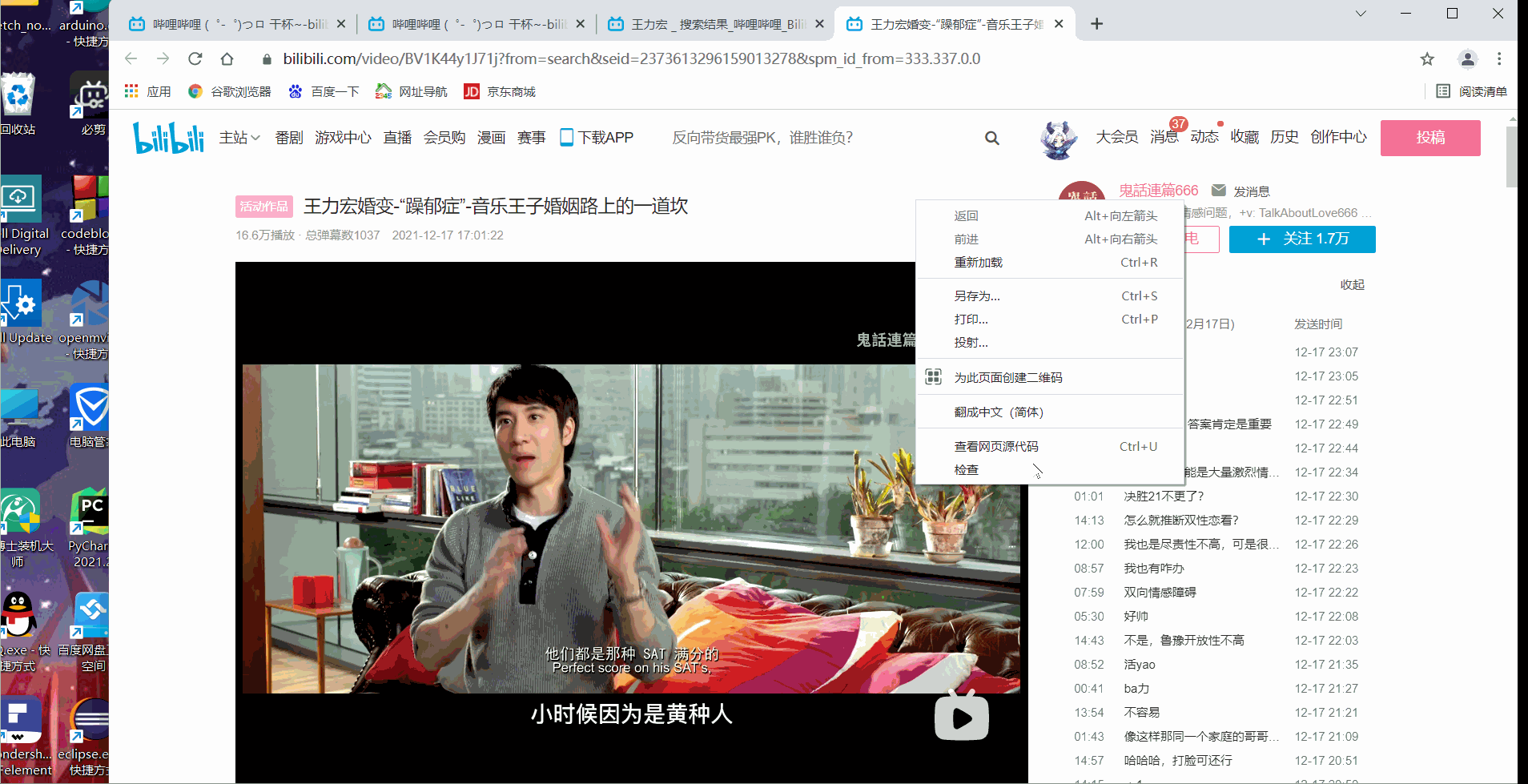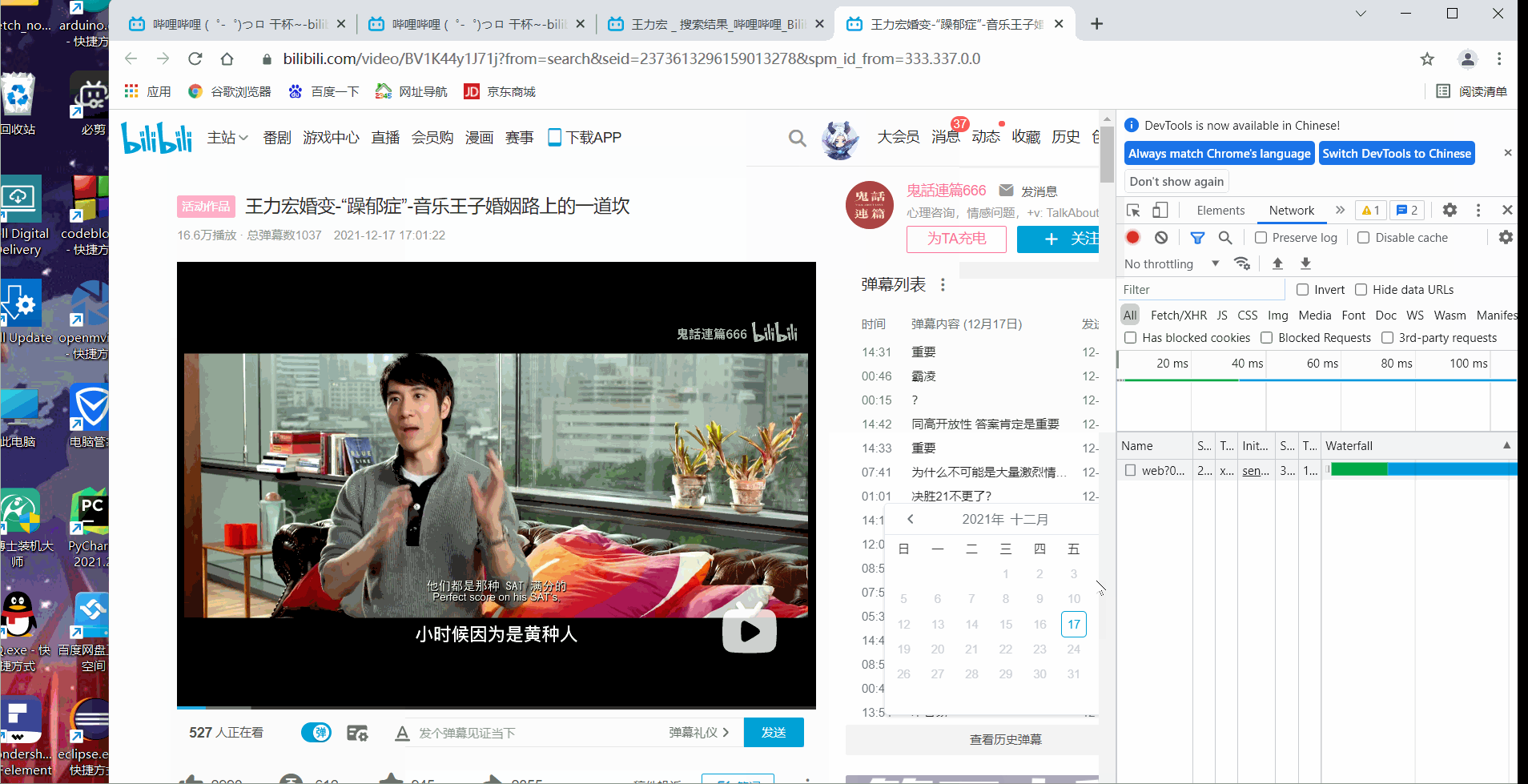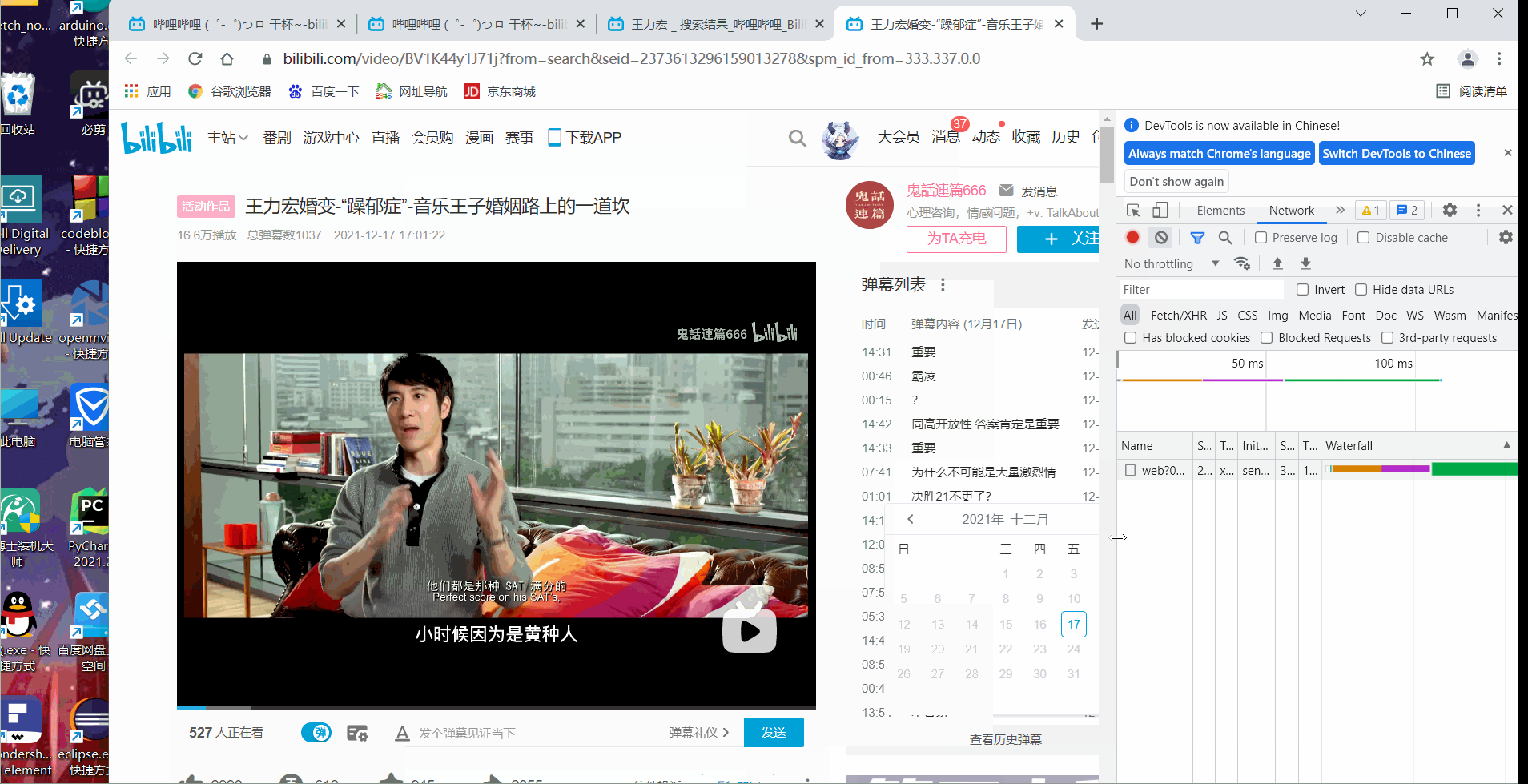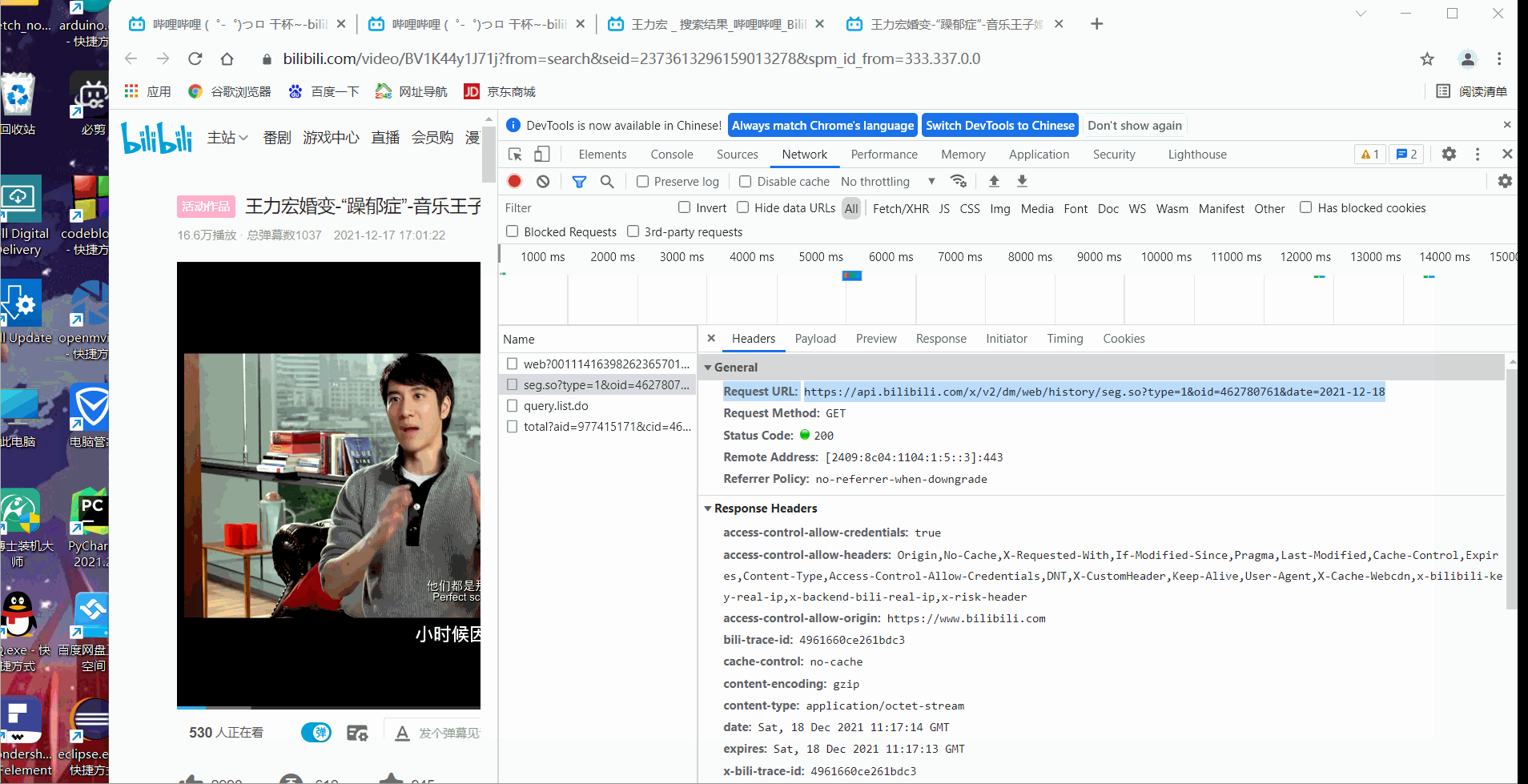
在下是老手了。这种包一下就找到了。我们在日期上的17,18号上进行点击,那么网站就一定会有响应,数据包就出现了。下面蓝色的这个,你看它的请求头,是有日期参数的。和2今天也符合,所以断定就是它了。
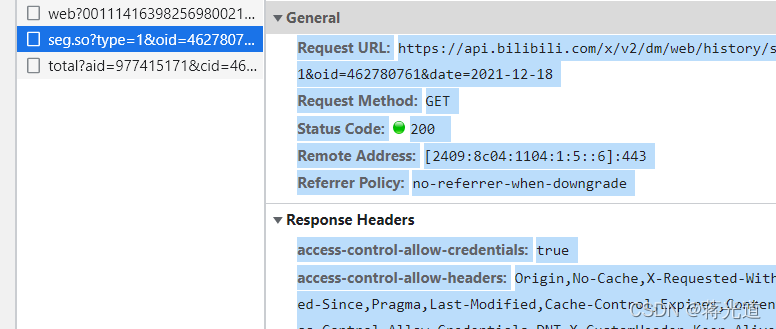
git图片简单给大家演示一下(针对小白)这个给大家展示如何进行找这个链接,只能到这里了,录制太多会超出大小。
接下来我们就用代码来进行操作
#流程
#导入工具
import requests #第三方工具
import re #正则
import csv #处理保存csv文件格式
import jieba #用来分词的国人开发的库 import wordcloud
import imageio # 读图片
import wordcloud #词云库
#目标网站
url = ' https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=462780761&date=2021-12-17'
#模拟浏览器发送请求,接受返回的数据
headers = {
# 用户代理 身份证
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
# 账号已登录信息
'cookie': 'i-wanna-go-back=1; _uuid=28710BECE-F4A10-61011-82F8-8DBA2766329818646infoc; buvid3=6499A90D-9064-4E9C-B99A-191DD85D9E0A148809infoc; sid=jgh3df1n; buvid_fp=6499A90D-9064-4E9C-B99A-191DD85D9E0A148809infoc; video_page_version=v_old_home_8; blackside_state=1; rpdid=|(J~Rk|)lYum0JuYJ~kkYRJ); PVID=1; b_lsid=1045D1095C_17DCCF879B6; bsource=search_baidu; CURRENT_FNVAL=2000; fingerprint=6cfabadc2b400e0e2df77ba05aad6854; buvid_fp_plain=1076B0E2-1AF1-459E-86AE-06CC9D0C7034167624infoc; _jct=cd8659505feb11ec9c2eb65f4b1a7e8f; DedeUserID=650586683; DedeUserID__ckMd5=673346effe04fe44; SESSDATA=53dfbe21%2C1655374695%2C47965*c1; bili_jct=69e79bf9587c7db111c395d7474c00cf; b_ut=6; innersign=1'
}
resp = requests.get(url,headers=headers)
print(resp) # 打印输出一下看是否可以正常访问
print(resp.text)#以文本的形式打印网页源代码
# 获取弹幕数据
#中文
Danmu = re.findall("[\u4e00-\u9fa5]+",resp.text) # 用到的正则,匹配中文
print(Danmu)
# 4.数据保存
for i in Danmu : #相当于一个遍历保存
with open('B站弹幕1.csv','a',newline='',encoding='utf-8') as f :
writer = csv.writer(f) #这里可以理解为传入文件句柄
#文件句柄可以帮助我们找到该文件,作用是这个。
danmu = []
danmu.append(i)
writer.writerow(danmu)
# 绘制词云
f = open('B站弹幕1.csv','r',encoding='utf-8')
txt = f.read()
#print(txt)
# 1.分词处理
textlist = jieba.lcut(txt)
print(textlist)
string1 = ' '.join(textlist) #拼接成整个字符串,将一句完整的中文字符串转换成了以空格分隔的词组成的字符串
#print(string)
mk = imageio.imread(r'xx.jpg')
w=wordcloud.WordCloud(
width = 1000,
height =700,
background_color ='white',
font_path='msyh.ttc',
mask =mk,
scale = 18,
stopwords = {'','\n','\r'},#停用词
contour_width =5,
contour_color ='red'
)
# 将string变量传入w的generate()方法,给词云输入文字
w.generate(string1)
#将词云图片导出到当前文件夹
w.to_file('out1.png')
知识点就不会再细讲了在网络爬虫爬取b站励志弹幕并生成词云(精心笔记总结)就有详细的·讲解。
不过还是具体捋一下思路和流程,以及用到的东西。这次再做一次爬虫词云制作也算是一次复习巩固学过的知识。
1:爬虫库:requests
这是一个做爬虫比较经典的库。
2:re规则库,又称之正则表达式
一般用在匹配的代码之中,爬虫中可以用到。
3:csv文件库
CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。所以说我们在以csv文件存储信息后,后面还需要进行分词。
4:jieba库
用来进行分词处理
5:imageio库
用来进行图片的读取
6:wordcloud库
用来做词云图
1:我们所做的第一步就是去找到弹幕存储的真实链接,上面已经介绍方法了。然后通过一个请求获取网站响应信息,不过你需要登录提供cookis信息,这边也就提供了cookie信息以及模拟浏览器。
2:将链接网址的文本信息进行保存,当然我们只需要保存中文,所以用到了一个具体的正则表达式,这个表达方法可以在网站查到,当然你要是学会了规则的话,自己也可以写出来。
3:re.findall()会返回一个列表类型,那么列表中就存储了我们需要的信息,然后我们通过遍历保存就保存到我们文件中了。不过之后会有换行符,回车符这些,以及逗号这些,我们做词云图是不需要这些的。所以我们后面需要去掉他们,也就是停用。
4:所以将含有词的数据保存后就可以制作词云了。读取文件然后用分词库进行分词。然后我们进行分词拼接这些自己需要做出的处理。后面的话是需要自己找合适的图片,为了方便,我直接找了白色的图片。
来看词云图效果




感觉挺好玩的,我比较喜欢花里胡哨的。最后温馨提示,个人因为爬虫已经付出了一些代价,小伙伴们想要玩的话就悠着点。比如本人这个例子也有代价,虽然我认为不是一件严重的事情。
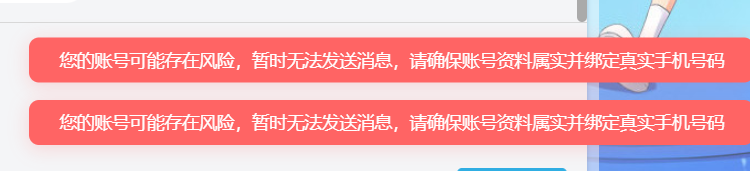
说明一下,爬这个弹幕阿,b站是要你登陆的,你登录后b站就可以检验了,随后就可以看你的账号是否存在异常操作。因为你提供cookie信息啊,就是相当于你的身份证。可能在某次倒霉被检测到了,这个cookie存在异常,相应就把账号限制了一部分功能。本人b站账号已经不具备私聊功能了。
上一年干完这件事丝毫没有意识,后来某天突然发现这样了,怎么也想不通,都是真实的,怎么会不真实呢?后来联系客服,说存在异常使用,这个无法处理。最后想来半天也没相通,后来才想到自己的异常也就爬了一下弹幕,做个词云就被制裁了。
欢迎评论指点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号