
全面理解Python中的类型提示(Type Hints)
众所周知,Python 是动态类型语言,运行时不需要指定变量类型。这一点是不会改变的,但是2015年9月创始人 Guido van Rossum 在 Python 3.5 引入了一个类型系统,允许开发者指定变量类型。它的主要作用是方便开发,供IDE 和各种开发工具使用,对代码运行不产生影响,运行时会过滤类型信息。
Python的主要卖点之一就是它是动态类型的,这一点也不会改变。而在2014年9月,Guido van Rossum (Python BDFL) 创建了一个Python增强提议(PEP-484),为Python添加类型提示(Type Hints)。并在一年后,于2015年9月作为Python3.5.0的一部分发布了。于是对于存在了二十五年的Python,有了一种标准方法向代码中添加类型信息。在这篇博文中,我将探讨这个系统是如何成熟的,我们如何使用它以及类型提示的下一步是什么。
为什么需要类型提示?

类型提示的优点
首先,让我们看看为什么需要Python中的类型提示(Type Hints)。类型提示有很多优点,我将尝试按重要性顺序来列举这些优点:
易于理解代码
了解参数的类型,可以使得理解和维护代码库变得更加容易。
例如,现在有一个函数。虽然我们在创建函数时知道了参数类型,但几个月之后就不再是这种情况了。 在代码旁边陈述了所有参数的类型和返回类型,可以大大加快了理解这个代码片段的过程。永远记住你阅读的代码,比你写的代码要多得多。 因此,你应该优化函数以便于阅读。
有了类型提示(Type Hints),在调用函数时就可以告诉你需要传递哪些参数类型;以及需要扩展/修改函数时,也会告诉你输入和输出所需要的数据类型。 例如,想象一下以下这个发送请求的函数,
-
def send_request(request_data : Any,
-
headers: Optional[Dict[str, str]],
-
user_id: Optional[UserId] = None,
-
as_json: bool = True):
-
...
只看这个函数签名,我们就可以知道:
request_data可以是任何数据header的内容是一个可选的字符串字典UserId是可选的(默认为None),或者是符合编码UserId的任何数据as_json需要始终是一个布尔值(本质上是一个flag,即使名称可能没有提供这种提示)
事实上,我们中的许多人已经明白在代码中提供类型信息是必不可少的。但是由于缺乏更好的选择,往往是在文档中提到代码中的类型信息。
而类型提示系统可以将类型信息从文档中移动到更加接近函数的接口,然后以一个明确定义的方式来声明复杂的类型要求。同时,构建linters,并在每次更改代码后运行它们,可以检查这些类型提示约束,确保它们永远不会过时。
lint指代码静态分析工具
易于重构
类型提示可以在重构时,更好得帮助我们定位类的位置。
虽然许多IDE现在采用一些启发式方法提供了这项功能,但是类型提示可以使IDE具有100%的检测准确率,并定位到类的位置。这样可以更平滑,更准确地检测变量类型在代码中的运行方式。
请记住,虽然动态类型意味着任何变量都可以成为任何类型,但是所有变量在所有时间中都应只有一种类型。类型系统仍然是编程的核心组件,想想那些使用isinstance判断变量类型、应用逻辑所浪费的时间吧。
易于使用库
使用类型提示意味着IDE可以拥有更准确、更智能的建议引擎。当调用自动完成时,IDE会完全放心地知道对象上有哪些方法/属性可用。此外,如果用户尝试调用不存在的内容或传递不正确类型的参数,IDE可以立即警告它。
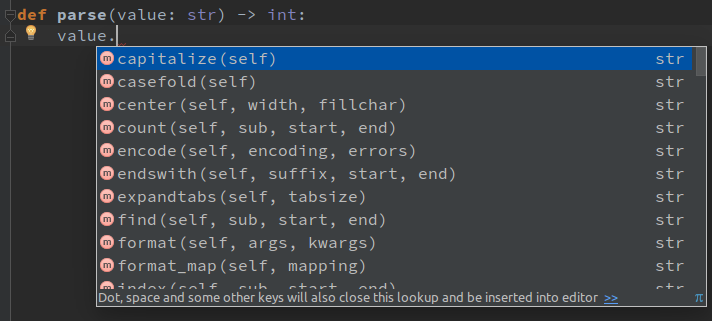
Type Linters
尽管IDE警告不正确的参数类型的功能很好,但使用linter工具扩展这个功能,以确保应用程序的逻辑类型则更加明智。这样的工具可以帮助你尽早捕获错误(例如,在输入后的示例必须是str类型,传入None会引发异常):
-
def transform(arg):
-
return 'transformed value {}'.format(arg.upper())
-
-
transform(None) # if arg would be type hinted as str the type linter could warn that this is an invalid call
虽然在这个例子中,有些人可能会认为很容易看到参数类型不匹配,但在更复杂的情况中,这种不匹配越来越难以看到。例如嵌套函数调用:
-
def construct(param=None):
-
return None if param is None else ''
-
-
def append(arg):
-
return arg + ' appended'
-
-
transform( append( construct() ) )
有许多的linters,但Python类型检查的参考实现是 mypy 。 mypy是一个Python命令行应用 (Python command line application ),可以轻松集成到我们的代码流中。
验证运行数据
类型提示可用于在运行时进行验证,以确保调用者不会破坏方法的约定。不再需要在函数的开始,使用一长串类型断言(type asserts); 取而代之,我们可以使用一个重用类型提示的框架,并在业务逻辑运行之前自动检查它们是否满足(例如使用 pydantic):
-
from datetime import datetime
-
from typing import List
-
from pydantic import BaseModel, ValidationError
-
-
class User(BaseModel):
-
id: int
-
name = 'John Doe'
-
signup_ts: datetime = None
-
friends: List[int] = []
-
-
external_data = {'id': '123', 'signup_ts': '2017-06-01 12:22',
-
'friends': [1, 2, 3]}
-
user = User(**external_data)
-
-
try:
-
User(signup_ts='broken', friends=[1, 2, 'not number'])
-
except ValidationError as e:
-
print(e.json())
类型检测不能做什么?
从一开始,Guido 明确表示类型提示并不意味着用于以下用例(当然,这并不意味着没有这样的 library/tools):
没有运行时类型推断
运行时解释器(CPython)不会尝试在运行时推断类型信息,或者验证基于此传递的参数。
没有性能调整
运行时解释器(CPython)不使用类型信息来优化生成的字节码以获得安全性或性能。
执行Python脚本时,类型提示被视为注释,解释器自动忽略。

需要什么样类型系统?
Python具有渐进的类型提示;意味着无论何时,对于给定的函数或变量,都没有指定类型提示。
我们可以假设它可以具有任何类型(即它仍然是动态类型的一部分)。
并且逐渐使你的代码库感知类型,例如一次一个函数或变量:
- function arguments,
- function return values,
- variables.
请记住,只有具有类型提示的代码才会类型检查!
当你在具有类型提示的代码上运行linter(例如 mypy)时,如果存在类型不匹配,则会出现错误:
-
# tests/test_magic_field.py
-
f = MagicField(name=1, MagicType.DEFAULT)
-
f.names()
此代码将生成以下输出:
-
bernat@uvm ~/python-magic (master●)$ mypy --ignore-missing-imports tests/test_magic_field.py
-
tests/test_magic_field.py:21: error: Argument 1 to "MagicField" has incompatible type "int";
-
expected "Union[str, bytes]"
-
tests/test_magic_field.py:22: error: "MagicField" has no attribute "names"; maybe "name" or "_name"?
注意,我们可以检测传入的参数的类型不兼容性,以及访问对象上不存在的属性。后者甚至可以提供有效的选项,使得更加容易的注意到和修复拼写错误。
如何加入类型信息
一旦你决定添加类型提示,就会发现可以通过很多种方式将其添加到代码库中。

Type annotations
-
from typing import List
-
-
class A(object):
-
def __init__() -> None:
-
self.elements : List[int] = []
-
-
def add(element: int) -> None:
-
self.elements.append(element)
类型标注(Type annotations)是一种直接的方式,并且是类型文档中最常见到的那种方式。
它使用通过PEP-3107(Python 3.0+)添加的函数标注以及通过PEP-526(Python 3.6+)添加的变量标注。这些可以使得在编写代码时,
- 使用
:语句将信息附加到变量或函数参数中。, ->运算符用于将信息附加到函数/方法的返回值中。
这种方法的好处是:
- 这是实现类型提示的规范方式,这意味着是类型提示中最干净的一种方式。
- 因为类型信息附加在代码的右侧,这样我们可以立刻明晰类型。
缺点是:
- 它不向后兼容。至少需要Python 3.6才能使用它。
- 强制你导入所有类型依赖项,即使它们根本不在运行时使用。
- 在类型提示中,会使用到复合类型,例如
List[int]。而为了构造这些复杂类型,解释器在首次加载此文件时需要执行一些操作。
这样发现,最后两点与我们之前列出的类型系统的初始目标相矛盾:
即在运行时基本上将所有类型信息作为注释处理。
为了解决这些矛盾,Python 3.7引入了 PEP-563 ~ postponed evaluation of annotations 。
加入以下语句,解释器将不再构造这些复合类型。
from __future__ import annotations一旦解释器解析脚本语法树后,它会识别类型提示并绕过评估它,将其保留为原始字符串。这种机制使得类型提示发生在需要它们的地方:由linter来进行类型检查。 在Python 4中,这种机制将成为默认行为。
Type comments
当标注语句(Type annotations)不可用时,可以使用类型注释:
沿着这条路走下去,我们确实得到了一些好处:
-
类型注释适用于任何Python版本。
尽管Python 3.5+中才将类型库添加到标准库中,但它可以作为Python 2.7+的PyPi包使用。此外,由于Python注释是任何Python代码下的有效语言特性,因此可以在Python 2.7或更高版本上代码中加入类型提示。有一些要求:类型提示注释(type hint comment)必须位于函数/变量定义所在的相同或下一行。 它也以
type:constant 开始。 -
此解决方案还解决了包装问题,因为注释很少会被删除。在源代码中打包类型提示信息可以使得那些使用你开发的库的人,使用类型提示信息来改善他们的开发体验。
但也会产生一些新问题:
- 缺点在于,虽然类型信息接近于参数,但是并不在更靠近参数的右边。这使得代码比其他方式更混乱。还有必须在一行中,这也可能会导致问题。例如,如果有一个长类型提示表达式(long type hint expression)并且你的代码库强制执行每一行的长度限制。
- 另一个问题在于,类型提示信息会与使用这些类型的注释标记的其他工具产生竞争(例如,抑制其他linter的错误)。
- 除了强制您导入所有类型信息外,这也会导致处于一个更加危险的地方。现在导入的类型仅在代码中使用,这使得大多数linter工具都认为所有这些导入都未使用。如果你允许他们删除这些语句,将会破坏代码的type linter。pylint通过将其AST解析器移动到 typed-ast parser 来解决这个问题,并且在Python 3.7第二个版本中发布。
为了避免将长行代码作为类型提示,可以通过类型注释逐个加入提示参数,然后将代码放入在返回类型注释后:
-
def add(element # type: List[int]
-
):
-
# type: (...) -> None
-
self.elements.append(element)
让我们简单看一下类型注释是如何使代码变得更加混乱。
下面是一个代码片段,它在类中交换两个属性值:
-
from typing import List
-
-
class A(object):
-
def __init__():
-
# type: () -> None
-
self.elements = [] # type: List[int]
-
-
def add(element):
-
# type: (List[int]) -> None
-
self.elements.append(element)
-
-
def swap_in_state(state, config, overrides):
-
old_config, old_overrides = state.config, state.overrides
-
state.config, state.overrides = config, overrides
-
yield old_config, old_overrides
-
state.config, state.overrides = old_config, old_overrides
首先,您必须添加类型提示。
因为类型提示会很长,所以你可以通过参数附加类型提示参数:
-
-
-
def swap_in_state(state, # type: State
-
config, # type: HasGetSetMutable
-
overrides # type: Optional[HasGetSetMutable]
-
):
-
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
-
old_config, old_overrides = state.config, state.overrides
-
state.config, state.overrides = config, overrides
-
yield old_config, old_overrides
-
state.config, state.overrides = old_config, old_overrides
-
-
但是等到加入使用的类型之后:
-
from typing import Generator, Tuple, Optional
-
from magic import RunSate
-
-
HasGetSetMutable = Union[Dict, List]
-
-
-
def swap_in_state(state, # type: State
-
config, # type: HasGetSetMutable
-
overrides # type: Optional[HasGetSetMutable]
-
):
-
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
-
old_config, old_overrides = state.config, state.overrides
-
state.config, state.overrides = config, overrides
-
yield old_config, old_overrides
-
state.config, state.overrides = old_config, old_overrides
现在这样的代码会导致静态linter(例如pylint)中产生的一些误报,所以需要为此添加一些抑制注释:
-
from typing import Generator, Tuple, Optional, Dict, List
-
from magic import RunSate
-
-
HasGetSetMutable = Union[Dict, List] # pylint: disable=invalid-name
-
-
-
def swap_in_state(state, # type: State
-
config, # type: HasGetSetMutable
-
overrides # type: Optional[HasGetSetMutable]
-
): # pylint: disable=bad-continuation
-
# type: (...) -> Generator[Tuple[HasGetSetMutable, Optional[HasGetSetMutable]], None, None]
-
old_config, old_overrides = state.config, state.overrides
-
state.config, state.overrides = config, overrides
-
yield old_config, old_overrides
-
state.config, state.overrides = old_config, old_overrides
现在已经完成了。然后,六行代码变为十六行,需要维护更多代码!
如果你通过编写的代码行数获得报酬,并且经理正在抱怨你最近表现不好,那么增加代码库听起来不错。
Interface stub files
这种方式以如下方式维护代码:
-
class A(object):
-
def __init__() -> None:
-
self.elements = []
-
-
def add(element):
-
self.elements.append(element)
与其它方式不同,这种方式在源文件旁边添加另一个 pyi 文件:
-
# a.pyi alongside a.py
-
from typing import List
-
-
class A(object):
-
elements = ... # type: List[int]
-
def __init__() -> None: ...
-
def add(element: int) -> None: ...
接口文件并不是一件新鲜事,C/C++ 已经使用了几十年了。
因为Python是一种解释性语言,通常不需要它,但是因为计算机科学中的每个问题都可以通过添加新的间接层来解决,我们可以添加它来存储类型信息。
这样做的好处是:
- 不需要修改源代码,可以在任何Python版本下工作,因为解释器从不执行它们。
- 在 stub 文件中,可以使用最新语法(例如类型注记,type annotations),因为应用在执行期间从不查看这些语法。
- 因为没有触及源代码,这意味着通过添加类型提示不会引入新的错误,添加的内容也不会与其他linter工具冲突。
- 这是方式经过了良好设计, typeshed 项目使用它来对整个标准库加入类型提示,以及一些其他流行的库,如requests,yaml,dateutil,等等。
- 可用于为那些你不拥有的源代码或者不能轻松改变的代码提供类型信息。
当然也要付出一些相对沉重的代价:
- 需要复制代码库,每个函数现在都会有两个定义(请注意不需要复制正文或默认参数,
...省略号 用作这些的占位符)。 - 会有一些额外的文件需要打包并随代码一起提供。
- 不能再在函数内部注释内容(这会导致方法存在内部方法以及局部变量)。
- 不会检查实现文件是否与stub的签名匹配(此外IDE最常使用stub定义)。
- 但是,最沉重的代价是无法通过stub检查加入类型提示的代码。stub 文件类型提示(stub file type hints),旨在检查使用该库的代码,而不是检查你自己加入类型提示的代码库。
最后两个缺点使得,特别难以通过stub文件检查加入类型提示代码库是否同步。在当前表单中,类型stubs是一种向用户提供类型提示的方法,但不是为您自己提供,并且难以维护。
为了解决这些问题,原文作者已经承担了将 stub 文件与 mypy 中的源文件合并的任务。从理论上讲,可以解决这两个问题,可以在 python/mypy ~ issue 5208 中查看进展。
Docstrings
也可以将类型信息添加到文档字符串中。即使这不是为Python设计的类型提示框架的一部分,但它也受到大多数主流IDE的支持。使用这种方式大多是传统的做法。
从积极的一面看:
- 在任何Python版本下工作,这在 PEP-257 中定义。
- 不与其他linter工具冲突,因为大多数工具不检查文档字符串,通常只检查其他代码部分。
但是,它有以下形式的严重缺陷:
- 没有一个标准方法来指定复杂类型提示(例如int或bool)。PyCharm有其专有方法,但Sphinx则使用不同的方法。
- 需要更改文档,并且难以保持准确/最新,因为没有工具来检查其有效性。
- 文档字符串类型会与类型提示代码不兼容。如果同时指定了类型注释和文档字符串,哪个优先于哪个?
哪些需要加入类型信息

让我们深入了解具体细节。有关可添加的类型信息的详尽列表,请参阅官方文档。在这里,我将为您快速做3分钟的概述,以便了解它。
有两种类型分类:nominal types 和 duck types (protocols)。
Nominal type
Nominal type 是那些在Python解释器中具有名称的类型。 例如所有内置类型(int,bolean,float,type,object等),然后我们有通用类型 (generic types),它们主要以容器的形式表现出来:
-
t : Tuple[int, float] = 0, 1.2
-
d : Dict[str, int] = {"a": 1, "b": 2}
-
d : MutableMapping[str, int] = {"a": 1, "b": 2}
-
l : List[int] = [1, 2, 3]
-
i : Iterable[Text] = [ u'1', u'2', u'3']
对于复合类型,一次又一次地写入它会变得很麻烦,因此系统允许通过以下方式对别名进行别名:
OptFList = Optional[List[float]]甚至可以提升内置类型来表示它们自己的类型,这对于避免错误是有用的,例如,您将错误顺序中具有相同类型的两个参数传递给函数:
-
UserId = NewType('UserId', int)
-
user_id = UserId(524313)
-
count = 1
-
call_with_user_id_n_times(user_id, count)
对于namedtuple,可以直接附加您的类型信息(请注意与Python 3.7+ 的数据类(data class)或 attrs 库非常相似):
-
class Employee(NamedTuple):
-
name: str
-
id: int
有以下的类型表示 one of 和 optional of:
-
Union[None, int, str] # one of
-
Optional[float] # either None or float
甚至可以对回调函数加入类型提示:
-
# syntax is Callable[[Arg1Type, Arg2Type], ReturnType]
-
def feeder(get_next_item: Callable[[], str]) -> None:
也可以使用TypeVar构造定义它自己的通用容器:
-
T = TypeVar('T')
-
class Magic(Generic[T]):
-
def __init__(self, value: T) -> None:
-
self.value : T = value
-
-
def square_values(vars: Iterable[Magic[int]]) -> None:
-
v.value = v.value * v.value
最后,使用Any类型提示,则禁用任何不需要的类型检查:
-
def foo(item: Any) -> int:
-
item.bar()
Duck types - protocols
在这种情况下,并不是一个实际的类型可以使得代码更加Pythonic,而是这样的一种考量:如果它像鸭子一样嘎嘎叫,并行为像鸭子一样,那么绝大多数预期认为它是一只鸭子。
在这种情况下,您可以定义对象所期望的操作和属性,而不是显式声明其类型。详见 PEP-544 ~ Protocols。
-
KEY = TypeVar('KEY', contravariant=true)
-
-
# this is a protocol having a generic type as argument
-
# it has a class variable of type var, and a getter with the same key type
-
class MagicGetter(Protocol[KEY], Sized):
-
var : KEY
-
def __getitem__(self, item: KEY) -> int: ...
-
-
def func_int(param: MagicGetter[int]) -> int:
-
return param['a'] * 2
-
-
def func_str(param: MagicGetter[str]) -> str:
-
return '{}'.format(param['a'])
Gotchas 陷阱
一旦开始向代码库添加类型提示,可能会遇到一些奇怪的问题。

在本节中,我将尝试介绍其中的一些内容,让你了解在向代码库添加类型信息时可能遇到的奇怪之处。
Gotchas
str difference in between Python 2/3
这是一个类的repr方法的快速实现:
-
from __future__ import unicode_literals
-
-
class A(object):
-
def __repr__(self) -> str:
-
return 'A({})'.format(self.full_name)
这段代码有错误。虽然这在Python 3下是正确的,但在python 2下错误(因为Python 2期望从repr返回字节,但是unicode_literals导入使得类型为unicode的返回值)。这种导入意味着不可能编写满足Python 2和3类型要求的repr。需要添加运行时的逻辑来使得代码正确运行:
-
from __future__ import unicode_literals
-
-
class A(object):
-
def __repr__(self) -> str:
-
res = 'A({})'.format(self.full_name)
-
if sys.version_info > (3, 0):
-
# noinspection PyTypeChecker
-
return res
-
# noinspection PyTypeChecker
-
return res.encode('utf-8')
为了使IDE接受这样的形式,还需加入一些 linter 注释,如上所示。这也导致了阅读代码变得更加困难,更重要的是,会存在额外的运行检查(runtime check)强制加入到类型检查器中。
Multiple return types
想象一下,你想编写一个函数,将一个字符串或一个int乘以2。 首先要考虑的是:
-
def magic(i: Union[str, int]) -> Union[str, int]:
-
return i * 2
您的输入是str或int,因此您的返回值也是str或int。 但是如果这样做的话,应告诉类型提示它确实可以是两种类型的输入。因此在调用端,需要断言调用的类型:
-
def other_func() -> int:
-
result = magic(2)
-
assert isinstance(result, int)
-
return result
这种不便可能会使一些人通过使返回值为Any来避免麻烦。
但是,有一个更好的解决方案。类型提示系统允许您定义重载。重载表示对于给定的输入类型,仅返回给定的输出类型。所以在这种情况下:
-
from typing import overload
-
-
-
def magic(i: int) -> int:
-
pass
-
-
-
def magic(i: str) -> str:
-
pass
-
-
def magic(i: Union[int, str]) -> Union[int, str]:
-
return i * 2
-
-
def other_func() -> int:
-
result = magic(2)
-
return result
但这也有存在缺点。静态linter工具会警告,正在重新定义具有相同名称的函数; 这是一个误报,所以添加静态linter禁用注释标记(#pylint:disable = function-redefined)。
Type lookup
想象一下,有一个类允许将包含的数据表示为多个类型,或者具有不同类型的字段。
你希望用户有一种快速简便的方法来引用它们,因此您添加了一个具有内置类型名称的函数:
-
class A(object):
-
def float(self):
-
# type: () -> float
-
return 1.0
一旦运行了linter,你会看到:
test.py:3: error: Invalid type "test.A.float"有人可能会问,这到底是什么?我已将返回值定义为float而不是test.A.float。
这种模糊错误的原因是类型提示器(type hinter)通过评估定义位置的每个作用域范围来解析类型。一旦找到名称匹配,它就会停止查找。这样它查找第一个级别是在A类中,然后它找到一个float(一个函数)并替换浮点数类型float。
解决这个问题的方案是明确定义我们不只是想要任何float,而是我们想要 builtin.float:
-
if typing.TYPE_CHECKING:
-
import builtins
-
-
class A(object):
-
def float(self):
-
# type: () -> builtins.float
-
return 1.0
注意到要执行此操作,还需要导入内置函数,并且为了避免在运行时出现问题,可以使用typing.TYPE_CHECKING标志来保护它,该标志仅在类型linter评估期间为true,否则始终为false。
Contravariant argument
考虑以下用例。定义包含常见操作的抽象基类,然后特定的类只处理一种类型和一种类型。你可以控制类的创建,以确保传递正确的类型,并且基类是抽象的,因此这似乎是一个令人愉快的设计:
-
from abc import ABCMeta, abstractmethod
-
from typing import Union
-
-
class A(metaclass=ABCMeta):
-
-
def func(self, key): # type: (Union[int, str]) -> str
-
raise NotImplementedError
-
-
class B(A):
-
def func(self, key): # type: (int) -> str
-
return str(key)
-
-
class C(A):
-
def func(self, key): # type: (str) -> str
-
return key
但是,一旦运行了linter检查,你会发现:
-
test.py:12: error: Argument 1 of "func" incompatible with supertype "A"
-
test.py:17: error: Argument 1 of "func" incompatible with supertype "A"
这样做的原因是类的参数是逆变的(contravariant )。这将被转换到派生类中,你必须处理父类的所有类型。但是,也可以添加其他类型。在函数参数中,可以扩展您所涵盖的内容,但不能以任何方式约束它:
-
from abc import ABCMeta, abstractmethod
-
from typing import Union
-
-
class A(metaclass=ABCMeta):
-
-
def func(self, key): # type: (Union[int, str]) -> str
-
raise NotImplementedError
-
-
class B(A):
-
def func(self, key): # type: (Union[int, str, bool]) -> str
-
return str(key)
-
-
class C(A):
-
def func(self, key): # type: (Union[int, str, List]) -> str
-
return key
Compatibility
考虑以下代码片段,注意其中的错误:
-
class A:
-
-
def magic(cls, a: int) -> 'A':
-
return cls()
-
-
class B(A):
-
-
def magic(cls, a: int, b: bool) -> 'B':
-
return cls()
如果还没有发现,请考虑如果编写以下脚本会发生什么:
-
from typing import List, Type
-
-
elements : List[Type[A]] = [A, B]
-
print( [e.magic(1) for e in elements])
如果您尝试运行它,则会因以下运行时错误而失败:
-
print( [e.magic(1) for e in elements])
-
TypeError: magic() missing 1 required positional argument: 'b'
原因在于B是A的子类型。因此B可以进入A类型的容器中(因为B扩展了A,因此B可以比A更多)。但是B的类方法定义违反了这个契约,它只能用一个参数调用magic。此外,类型linter将无法指出这一点:
test.py:9: error: Signature of "magic" incompatible with supertype "A"一个快速和简单的办法解决,就是使第二个参数可选,以确保B.magic带有1个参数可以正常工作。
现在看看下面这段代码:
-
class A:
-
def __init__(self, a: int) -> None:
-
pass
-
-
class B(A):
-
def __init__(self, a: int, b: bool) -> None:
-
super().__init__(a)
您认为这会发生什么? 注意我们将类方法移动到构造函数中,并且没有进行其他更改,因此我们的脚本也只需要稍作修改:
-
from typing import List, Type
-
-
elements : List[Type[A]]= [A, B]
-
print( [e(1) for e in elements])
这是运行错误,与之前大致相同,只是在__init__而不是magic:
-
print( [e(1) for e in elements])
-
TypeError: __init__() missing 1 required positional argument: 'b'
那么mypy会有什么反应吗?
如果你运行它,会发现mypy选择保持沉默。它会将此标记为正确,即使在运行时它会失败。
The mypy creators said that they found too common of type miss-match to prohibit incompatible
__init__and__new__.
mypy 创建者认为他们发现太多的类型错误匹配,所以禁止了不兼容的 __init__和__new__。
当遇到了问题
总之,请注意类型提示有时会引起奇怪的警告,例如以下tweet:
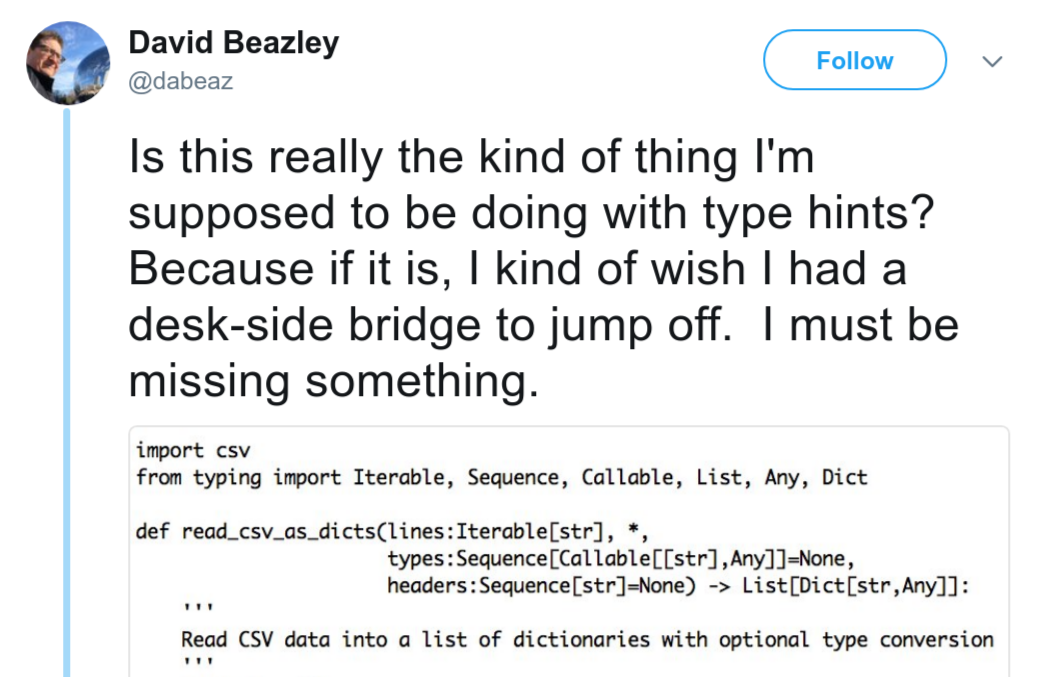
有一些工具可以帮助发现、理解并处理这些情况:
-
使用
reveal_type查看推断类型-
a = [4]
-
reveal_type(a) # -> error: Revealed type is 'builtins.list[builtins.int*]'
-
-
使用
cast来强制给定类型:-
from typing import List, cast
-
a = [4]
-
b = cast(List[int], a) # passes fine
-
c = cast(List[str], a) # type: List[str] # passes fine (no runtime check)
-
reveal_type(c) # -> error: Revealed type is 'builtins.list[builtins.str]'
-
-
使用type ignore marker 来禁用行中的错误:
x = confusing_function() # type: ignore # see mypy/issues/1167 -
询问社区。在Gitter chat的 python/typing 下示出代码与错误。
Tools 工具
这是围绕类型提示系统构建的一个不完全的工具列表。
type checkers
使用这些工具检查库或应用程序中的类型安全性:
-
mypy - Python (the reference type linting tool)
-
pyre - Facebook - 仅适用于Python 3,比 mypy 更快。一个有趣的用例是能够用它进行污点/安全代码分析-参见Pieter Hooimeijer - Types, Deeper Static Analysis, and you
type annotation generators
如果要将类型标注添加到现有代码库,可以使用这些工具来完成一些可以自动完成的部分:
mypy stubgencommand line(see)- pyannotate - Dropbox - 使用你的测试生成类型信息。
- monkeytype - Instagram. Instagram实际上使用它在他们的生产系统中运行它:每百万调用触发一次(使代码运行速度慢五倍,但每一百万次调用使其不那么明显)。
runtime code evaluator
可以使用这些工具在运行时检查,函数/方法的输入参数类型是否正确:
Documentation enrichment - merge docstrings and type hints
在这篇文章的第一部分中,我们提到人们很多已经在docstrings中存储了类型信息。这样做的原因是你的类型数据是希望在文档中包含库的类型信息契约的一部分。 所以问题仍然是你没有选择使用docstrings作为主要的类型信息存储系统,那么怎么能在文档的文档字符串中使用它们?
答案取决于用于生成该文档的工具。但是,我将在这里提供一个选项,使用Python中最流行的工具和格式:Sphinx和HTML。
在类型提示和文档字符串中明确声明类型信息是最终在它们之间发生冲突的可靠方法。你可以指望有人在某个地方将在一个地方更新但在另一个地方不会更新。因此,让我们从docstring中删除所有类型数据,并将其仅作为类型提示。现在,我们需要做的就是在文档构建时从类型提示中获取它并将其插入到文档中。
在Sphinx中,您可以通过插件实现此目的。最流行的版本是agronholm/sphinx-autodoc-typehints.
- 首先,对于要记录的每个函数/变量,它获取类型提示信息;
- 然后,它将Python类型转换为docstring表示(这涉及递归展开所有嵌套类型类,并用其字符串表示替换类型);
- 最后,将正确的参数附加到docstring中。
例如,Any映射到py:data:~ingtings.Any。对于复合类型,例如Mapping [str,bool]也需要转换,这样事情会变得更复杂:class:~intinging.Mapping\\[:class:str,:class:bool]。在这里,正确的转换(例如,具有类或数据命名空间)是必不可少的,这样intersphinx插件才能够正常工作(将类型直接链接到各自的Python标准库文档链接的插件)。
为了使用它,需要通过pip install sphinx-autodoc-types> = 2.1.1安装,然后在conf.py文件中启用:
-
# conf.py
-
extensions = ['sphinx_autodoc_typehints']
That’s it all.
一个示例是RookieGameDevs/revived的文档。 例如,以下源代码:

可以得到输出:

Conclusion 总结
所以在这篇长篇博文的最后,你可能会问:是否值得使用类型提示,或何时应该使用它们? 我认为类型提示基本上与单元测试相同,只是在代码中表达不同。它们提供的是标准(并可重用于其他目标)方式,以测试代码库的输入和输出类型。
因此,只要单元测试值得写,就应该使用类型提示。 哪怕只有十行代码,只要之后需要维护它。
同样,每当开始编写单元测试时,都应该开始添加类型提示。我不想添加它们的唯一地方是我不编写单元测试,例如REPL lines,或丢弃一次性使用脚本。
请记住,与单元测试类似,虽然它确实使您的代码库包含额外数量的行,但是添加的所有代码都是自动检查并强制纠正后的。它可以作为一个安全措施,以确保当你改变事物后,代码可以继续工作,所以值得承受这个额外代价。

作者: Sikasjc
链接: http://sikasjc.github.io/2018/07/14/type-hint-in-python/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号