
结巴分词原理介绍
转自一个很不错的博客,结合自己的理解,记录一下。作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明。谢谢!
https://www.cnblogs.com/zhbzz2007/p/6076246.html?utm_source=itdadao&utm_medium=referral
结巴分词的原理,结合一个面试题:有一个词典,词典里面有每个词对应的权重,有一句话,用这个词典进行分词,要求分完之后的每个词都必须在这个词典中出现过,目标是让这句话的权重最大。
涉及算法:
- 基于前缀词典实现词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG),采用动态规划查找最大概率路径,找出基于词频的最大切分组合;
- 对于未登录词,采用了基于汉字成词能力的 HMM模型,采用Viterbi算法进行计算;
- 基于Viterbi算法的词性标注;
- 分别基于tfidf和textrank模型抽取关键词;
基于前缀词典及动态规划实现分词
http://www.cnblogs.com/zhbzz2007/p/6084196.html
jieba分词主要是基于统计词典,构造一个前缀词典;然后利用前缀词典对输入句子进行切分,得到所有的切分可能,根据切分位置,构造一个有向无环图;通过动态规划算法,计算得到最大概率路径,也就得到了最终的切分形式。
1.前缀词典构建:如统计词典中的词“北京大学”的前缀分别是“北”、“北京”、“北京大”;词“大学”的前缀是“大”。
2.有向无环图构建:然后基于前缀词典,对输入文本进行切分,对于“去”,没有前缀,那么就只有一种划分方式;对于“北”,则有“北”、“北京”、“北京大学”三种划分方式;对于“京”,也只有一种划分方式;对于“大”,则有“大”、“大学”两种划分方式,依次类推,可以得到每个字开始的前缀词的划分方式。
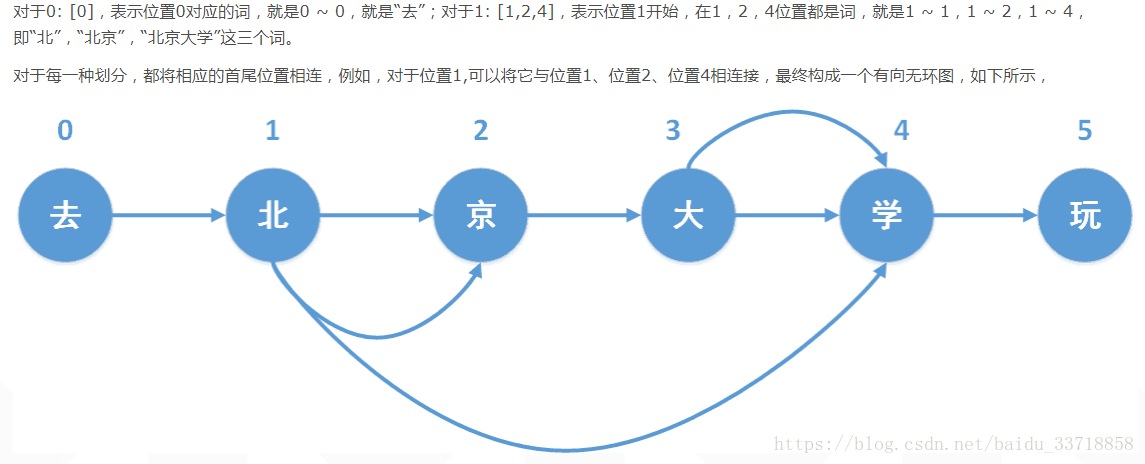
3.最大概率路径计算:
在得到所有可能的切分方式构成的有向无环图后,我们发现从起点到终点存在多条路径,多条路径也就意味着存在多种分词结果。因此,我们需要计算最大概率路径,也即按照这种方式切分后的分词结果的概率最大。在采用动态规划计算最大概率路径时,每到达一个节点,它前面的节点到终点的最大路径概率已经计算出来。
有向无环图DAG的每个节点,都是带权的,对于在前缀词典里面的词语,其权重就是它的词频;我们想要求得route = (w1,w2,w3,...,wn),使得 ∑weight(wi) 最大。
如果需要使用动态规划求解,需要满足两个条件,
- 重复子问题
- 最优子结构
我们来分析一下最大概率路径问题,是否满足动态规划的两个条件。


基于汉字成词能力的HMM模型识别未登录词
利用HMM模型进行分词,主要是将分词问题视为一个序列标注(sequence labeling)问题,其中,句子为观测序列,分词结果为状态序列。首先通过语料训练出HMM相关的模型,然后利用Viterbi算法进行求解,最终得到最优的状态序列,然后再根据状态序列,输出分词结果。
HMM的两个基本假设:
1.齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其它时刻的状态及观测无关,也与时刻t无关;
2.观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其它观测和状态无关。
HMM模型的三个基本问题:



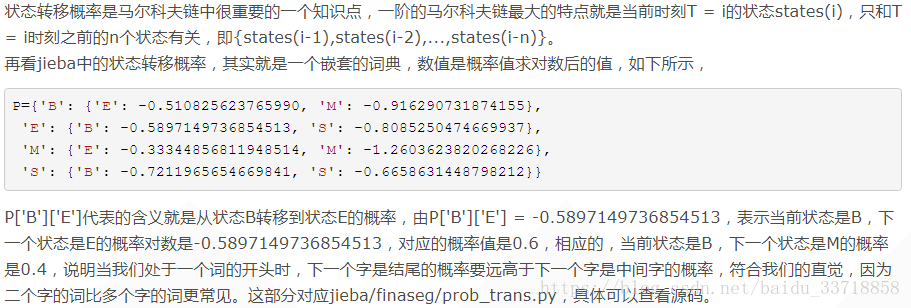
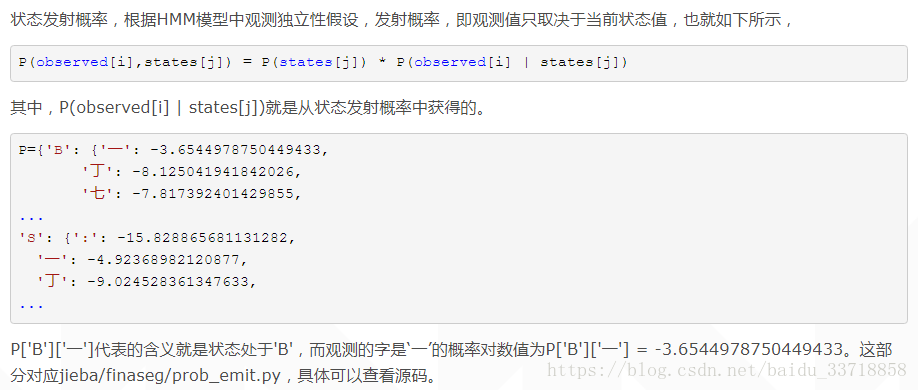
Viterbi算法
Viterbi算法实际上是用动态规划求解HMM模型预测问题,即用动态规划求概率路径最大(最优路径)。这时候,一条路径对应着一个状态序列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号