Microsoft.mshtml VS HtmlAgilityPack
爬虫清洗数据时除了正则表达式有时候解析HTML文档能更快更方便的拿到数据
解析HTML的库除了微软自带的Microsoft.mshtml 之外比较受欢迎的是HtmlAgilityPack,之前一直用的是前者,后面发现他俩差别还是蛮大的;
①效率:
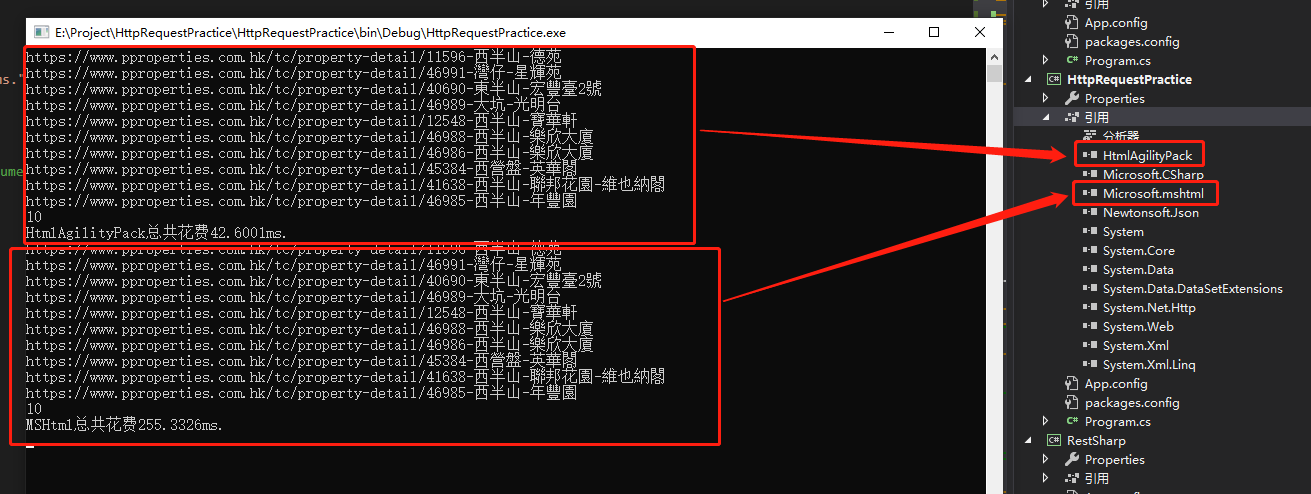
②代码
Microsoft.mshtml
static List<string> GetHouseLinks2(string strDoc) { Stopwatch sw = new Stopwatch(); sw.Start(); var doc = GetHTMLDocument(strDoc); var list = new List<string>(); var anchors = doc.getElementsByTagName("a"); foreach (HTMLAnchorElement anchor in anchors) { var href = ((string)anchor.getAttribute("href")); if (href != null) { if (href.Contains("property-detail")) { list.Add(href); Console.WriteLine(href); } } } Console.WriteLine(list.Count); sw.Stop(); TimeSpan ts2 = sw.Elapsed; Console.WriteLine("MSHtml总共花费{0}ms.", ts2.TotalMilliseconds); return list; }
public static HTMLDocument GetHTMLDocument(string html) { var doc = new HTMLDocument(); var doc2 = doc as IHTMLDocument2; doc2.designMode = "on"; doc2.write(new object[] { html }); doc = (HTMLDocument)doc2; return doc; }
HtmlAgilityPack:
static List<string> GetHouseLinks(string strDoc) { Stopwatch sw = new Stopwatch(); sw.Start(); HtmlDocument htmlDoc = new HtmlDocument(); htmlDoc.LoadHtml(strDoc);//string转HtmlDocument //获取属性值 var houseLinks = new List<string>(); string url = "https://www.pproperties.com.hk/tc/property-search-result"; HtmlNodeCollection linkNodes = htmlDoc.DocumentNode.SelectNodes(@"//a[@href]"); foreach (var link in linkNodes) { string href = link.Attributes["href"].Value; if (href.Contains("detail")) { houseLinks.Add(href); Console.WriteLine(href); } } Console.WriteLine(houseLinks.Count); sw.Stop(); TimeSpan ts2 = sw.Elapsed; Console.WriteLine("HtmlAgilityPack总共花费{0}ms.", ts2.TotalMilliseconds); return houseLinks; }
传入的strDoc是接响应的Html字符串;后者string转HTML文档只需要两句代码方可实现;
而最大的区别是HtmlAgilityPack可以用XPath获取标签路径属性,非常方便,而Microsoft.mshtml只能一层一层获取或者只能一次性获取某种类型的标签如下获取h1标签下的span标签:
//标题 var heads = doc.getElementsByTagName("h1"); foreach (HTMLHeadElement h in heads) { if (!string.IsNullOrEmpty(h.innerText)) { var spanElement = h.getElementsByTagName("span")?.item(0) as HTMLSpanElement; property.District = spanElement?.innerText?.Trim() ?? string.Empty; var ename = h.innerText.Split(property.District[0]); if (ename.Length > 0) property.EstateName = ename[0]; Msg = " 抓取" + " [" + property.District + " " + property.EstateName + "]"; Console.WriteLine(Msg); break; } }
而XPath仅需"//h1/span"即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号