搜索引擎项目的一点总结
前几天刚做完一个搜索引擎的项目,趁着今天有时间,把做这个项目的一些关键点,包括一些关键的算法、思路都整理一下,做一个总结,方便日后温习,也方便以后对这个项目的扩展(PS:博客园上的第一篇博客,排版可能不是太好,大家将就一下),废话不多说,先上源码:https://github.com/Jeysin/searchEngine
- 并发服务器方案
这个项目的整体框架部分采用的是Reactor+ThreadPool方案。说到Reactor+ThreadPool方案,简单来说,其实就是一个线程作为IO线程,线程池内的线程做为计算线程,采用epoll实现多路复用。IO线程负责监听TCP连接请求和接收客户端发来的数据,用一个大的loop,如果是有新的连接请求,就调用accept,将新的文件描述符添加进epoll的监听链表中;如果是客户端发送过来的数据,就用bind将这些数据做为传入的参数绑定到一个函数上,再将这个函数作为一个任务添加进线程池的任务队列,这里不得不顺带提一下我的线程池的实现方法,我在这里采用了一种基于对象的线程池设计方法(关于面向对象和基于对象,见:http://blog.csdn.net/jiangxinnju/article/details/40163215),将线程池中任务队列的元素设置为function类型,也就是说,将一个一个封装好的函数作为线程池中的任务,线程池中的计算线程只要有空闲,就会执行事先已经绑定好参数的函数。基于这种线程池的实现方式,IO线程就可以很方便地将数据绑定到一个函数上,然后将函数交给线程池,计算线程拿到函数,执行计算任务,计算完以后,再将计算结果放到一个待发送队列,用一个eventfd(事先在epoll中注册好的)通知IO线程,IO线程收到通知以后去待发送队列中取出计算结果,并将其发送给对应的客户端。所以这里是用了一个eventfd来实现IO线程和计算线程的同步。至此,整个项目的网络框架部分基本就是这样了。
- 业务逻辑部分
既然是做搜索引擎,那么肯定涉及到搜索引擎的常用技术和原理。简单来说,一个好的搜索引擎,首先需要一个好的爬虫,能够帮你把网络上的各种网页抓取到本地;能够对网页进行去重;考虑到时间或资源成本,还要求爬虫能对网页的重要性进行一定的判断,即先抓取“重要”的网页;还要能及时地更新已有的网页…… 其次,一个搜索引擎还需要有一套行之有效的索引系统,能够将搜索效率提高,这里涉及到太多东西,想深入了解请戳北大天网:https://gitee.com/lewsn2008/LBTSE。下面谈谈我的简单实现。
首先,手动下载rss网页作为本地网页库(爬虫就留到以后再写吧),当然,如果想要网页库全一点的话,可以去搜狗实验室获取网页资源:http://www.sogou.com/labs/resource/list_pingce.php。先用tinyxml2解析rss源文件,提取出有效信息,去除xml标记,建成一个网页库,网页库结构如下:
<doc>
<docid>id</docid>
<link>www.example.com</link>
<description>summary</description>
<content>...</constent>
</doc>
网页库建好以后,用simhash算法进行网页去重,关于simhash算法,详见:https://yanyiwu.com/work/2014/01/30/simhash-shi-xian-xiang-jie.html。这里简单描述一下:对于一篇网页而言,抽取若干个特征词和其对应的权重(权重依据TF-IDF算法得来,关于TF-IDF算法,详见:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html),生成若干(feature, weight)对,对于每一个feature,映射成64位(也就是8字节大小)的一个特征序列,对于特征序列上的每一位,是1,就记为+weight,是0, 就记为-weight。最后将一篇文章所有的特征序列加和,得到一个总的特征序列,对于这个总的特征序列的每一位,大于0就记为1,小于0就记为0,得到最终的特征序列。只要比较两篇文章最终的特征序列对应位置上的0和1有多少个不同(海明距离),就知道两篇文章是否相似了。一般海明距离小于3则认为两篇文章相似。网页去重完毕后,生成一个新的网页库文件和一个偏移库文件(记录下每篇网页在网页库文件中的id号、起始位置和长度,这样方便根据id号找到偏移信息然后直接获取到网页),接下来就到了搜索引擎最核心的一步:生成倒排索引。
倒排索引其实就是记录下每一个词(中文词或英文词)对应的网页id号,以及对于某一篇网页而言这个词的权重(依据TF-IDF算法计算而来)。先用cppjieba对网页进行分词,利用STL中的map可以很方便地插入网页中的每个词,插入的同时记下每个词对应的网页id号。到所有的词插入完毕以后,就可以利用TF-IDF算法计算对于某一篇网页而言,每个词的权重。至此,倒排索引生成完毕,最后的数据结构应该是map<string, map<int, double>>,其中string为每个词,int为包含这个词的网页的id,double记录下对于某一篇网页而言,这个词的权重。最后提一下TF-IDF算法的公式:weight=TF*IDF=TF*log(N/DF),其中TF表示一篇网页中某个词的词频,N表示整个网页库的网页总数,DF表示在整个网页库中,包含这个词的网页的篇数。所以最后得出的weight值与TF成正比,与DF成反比,即对于某一个词和某一篇网页而言,这个词在这篇网页中的词频越大、这个词在别的网页中出现得越少(网页区分度越高),则认为这个词在这篇网页中的权重越大。
倒排索引建好以后,一个简单的搜索引擎基本上也成型了。下面只剩下两个问题:
1.利用倒排索引找到和用户输入的关键词相匹配的网页后,网页怎么排序?
2.对于一篇网页,如何自动生成摘要返回给用户?
第一个问题,采用的策略是将用户的输入先分词,再去停用词,然后得到若干关键字,然后根据关键字去倒排索引中获取若干map<int, double>,把他们都插入到一个新的map<int, double>中,插入的时候得分相加,所以这个map中的double记录下的是每篇网页的总得分,包涵的关键词越多的网页得分会越高,包涵的关键词权重越大,对应的网页得分也会越高,最后按网页得分对网页进行排序。第二个问题,如何自动生成摘要?详见:http://www.ruanyifeng.com/blog/2013/03/automatic_summarization.html。我这里用一个简单的方法:将一篇网页文章拆分成句子,找到每个关键词第一次和第二次出现的那些句子,拼接起来作为摘要。
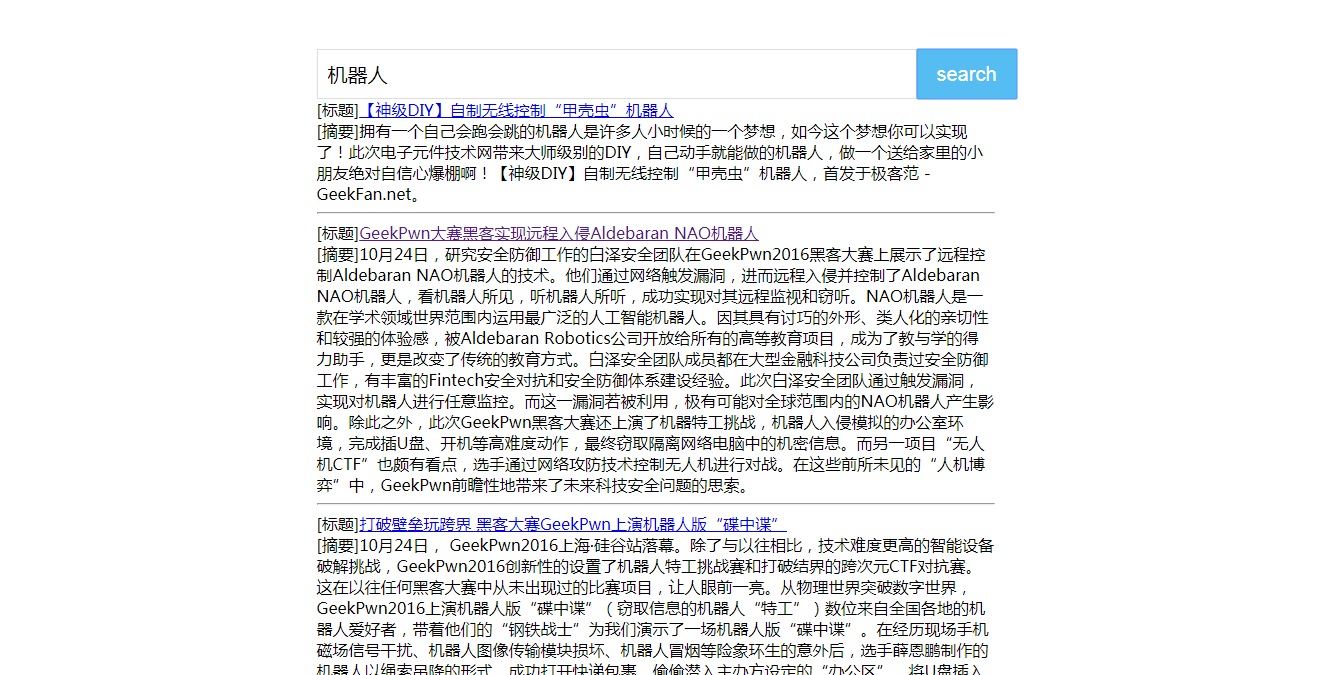
至此,一个简单的搜索引擎打造完毕,贴上效果图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号