

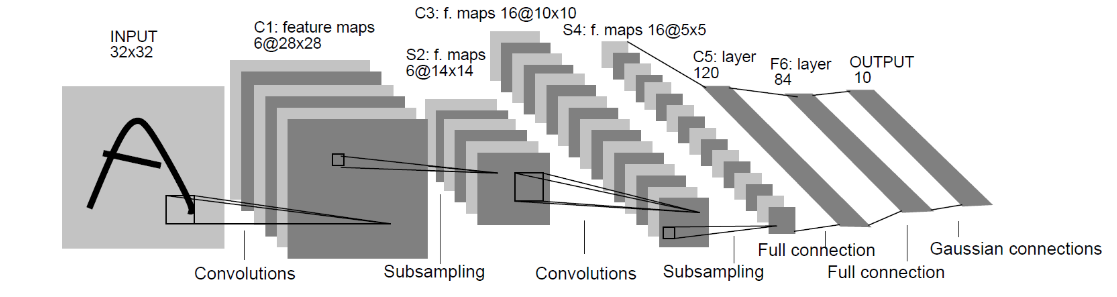

1 import torch 2 from torch.utils.data import DataLoader 3 from torchvision import transforms 4 from torchvision import datasets 5 6 ########################################################## 7 # ==> 1.准备数据 8 ########################################################## 9 # 预处理 10 transfrom = transforms.Compose([ 11 transforms.ToTensor() 12 ]) 13 # 准备训练集数据和验证集 14 train_transfrom= transforms.Compose([ 15 # 此处可以添加你所用到的数据增强方法 16 transforms.RandomHorizontalFlip(p=0.5), 17 transforms.ToTensor() 18 ]) 19 train_dataset = datasets.CIFAR100(root='你的路径',transform=train_transfrom,train=True,download=True)#注意在训练集中添加数据增强方法 20 val_dataset = datasets.CIFAR100(root='你的路径',transform=transfrom,train=False,download=True) 21 22 # 训练集dataloader,验证集dataloader 23 train_loader = DataLoader( 24 dataset=train_dataset, 25 batch_size=128, 26 shuffle=True 27 ) 28 val_loader = DataLoader( 29 dataset=val_dataset, 30 batch_size=128, 31 shuffle=False 32 ) 33 ########################################################## 34 # ==> 2.搭建网络 35 ########################################################## 36 # 重写nn.Module类,使用自己的网络 37 from torch import nn 38 # 此处可以在网络中添加一些卷积层(或其他层) 39 from torch import nn 40 # 定义LeNet-5网络 41 class My_Net(nn.Module): 42 def __init__(self): 43 super(My_Net, self).__init__() 44 # 输入3×32×32的CIFAR-100图像,经过卷积后输出大小为6×28×28 45 self.conv1 = nn.Conv2d(in_channels=3, 46 out_channels=6, 47 kernel_size=(5, 5), 48 stride=1, 49 bias=True) 50 # 卷积操作后使用Tanh激活函数,激活函数不改变其大小 51 self.tanh1 = nn.Tanh() 52 # 使用最大池化进行下采样,输出大小为6×14×14 53 self.pool1 = nn.MaxPool2d(kernel_size=(2, 2), 54 stride=2) 55 # 输出大小为16×10×10 56 self.conv2 = nn.Conv2d(in_channels=6, 57 out_channels=16, 58 kernel_size=(5, 5), 59 stride=1, 60 bias=True) 61 self.tanh2 = nn.Tanh() 62 # 输出大小为16×5×5 63 self.pool2 = nn.MaxPool2d(kernel_size=(2, 2), 64 stride=2) 65 # 两个卷积层和最大池化层后接三个全连接层 66 self.fc1 = nn.Linear(16*5*5, 120) 67 self.tanh3 = nn.Tanh() 68 self.fc2 = nn.Linear(120, 84) 69 self.tanh4 = nn.Tanh() 70 # 第三个全连接层是输出层,输出单元个数即是数据集中类的个数,CIFAR-100数据集有100个类 71 self.classifier = nn.Linear(84, 100) 72 73 # 定义前向传播过程 74 def forward(self, x): 75 x = self.conv1(x) 76 x = self.tanh1(x) 77 x = self.pool1(x) 78 x = self.conv2(x) 79 x = self.tanh2(x) 80 x = self.pool2(x) 81 # 在全连接操作前将数据平展开 82 x = x.view(x.size(0), -1) 83 x = self.fc1(x) 84 x = self.tanh3(x) 85 x = self.fc2(x) 86 x = self.tanh4(x) 87 output = self.classifier(x) 88 return output 89 # 将网络类实例化,变成对象 90 91 # 定义训练的设备 92 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') 93 net = My_Net() 94 net = net.to(device) 95 ########################################################## 96 # ==> 3.定义损失函数,优化器,学习率调整方式 97 ########################################################## 98 # 3.1损失函数 99 loss_fn = nn.CrossEntropyLoss() # 使用CE Loss 100 loss_fn = loss_fn.to(device) 101 # 3.2优化器,学习率调整器 102 from torch import optim 103 # 使用SGD优化器,初始学习率为0.1 104 optimizer = optim.SGD(net.parameters(), lr=0.1) 105 # 使用StepLR学习率调整方式,每隔5个Epoch学习率变为原来的0.1倍 106 scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) 107 108 ########################################################## 109 # ==> 4.进行训练 110 ########################################################## 111 # 迭代训练20个Epoch 112 num_epochs = 50 113 print("Start Train!") 114 for epoch in range(1, num_epochs+1): 115 train_loss = 0 116 train_acc = 0 117 val_loss = 0 118 val_acc = 0 119 # 训练阶段,设为训练状态 120 net.train() 121 train_confusion_matrix = torch.zeros(100, 100).cuda() # 训练集混淆矩阵 122 val_confusion_matrix = torch.zeros(100, 100).cuda() # 验证集混淆矩阵 123 for batch_index, (imgs,labels) in enumerate(train_loader): 124 imgs,labels = imgs.to(device),labels.to(device) 125 output = net(imgs) 126 loss = loss_fn(output,labels) #计算损失 127 optimizer.zero_grad()# 梯度清零 128 loss.backward()# 反向传播 129 optimizer.step()# 梯度更新 130 # 计算精确度 131 _,predict = torch.max(output,dim=1) 132 corec = (predict == labels).sum().item() 133 acc = corec / imgs.shape[0] 134 train_loss += loss.item() 135 train_acc += acc 136 137 for t, p in zip(labels.view(-1), output.argmax(dim=1).view(-1)): 138 train_confusion_matrix[t.long(), p.long()] += 1 139 140 # 查看训练集每个类的准确率 141 acc_per_class = train_confusion_matrix.diag() / train_confusion_matrix.sum(1) 142 acc_per_class = acc_per_class.cpu().numpy() 143 print() 144 print('train acc_per_class:\n',acc_per_class) 145 # 验证阶段 146 net.eval() 147 for batch_index, (imgs, labels) in enumerate(val_loader): 148 imgs, labels = imgs.to(device), labels.to(device) 149 output = net(imgs) 150 loss = loss_fn(output,labels) 151 _, predict = torch.max(output, dim=1) 152 corec = (predict == labels).sum().item() 153 acc = corec / imgs.shape[0] 154 val_loss += loss.item() 155 val_acc += acc 156 for t, p in zip(labels.view(-1), output.argmax(dim=1).view(-1)): 157 val_confusion_matrix[t.long(), p.long()] += 1 158 159 # 查看验证集每个类的准确率 160 acc_per_class = val_confusion_matrix.diag() / val_confusion_matrix.sum(1) 161 acc_per_class = acc_per_class.cpu().numpy() 162 print() 163 print('val acc_per_class:\n',acc_per_class) 164 scheduler.step() 165 # 依次输出当前epoch、总的num_epochs, 166 # 训练过程中当前epoch的训练损失、训练精确度、验证损失、验证精确度和学习率 167 print() 168 print(epoch, '/', num_epochs, 169 train_acc/len(train_loader), 170 train_loss/len(train_loader), 171 val_acc / len(val_loader), 172 val_loss/len(val_loader), 173 optimizer.param_groups[0]['lr'])
知识产权声明: 本博文中的ppt素材及相关内容和知识产权,均属于河南大学张重生老师所讲授的《深度学习》课程及张重生老师在2025年出版的著作《新一代人工智能 从深度学习到大模型》(机械工业出版社)。特此声明。
真挚地感谢张重生老师在本人于河南大学学习期间的教导。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律