~~函数基础(八):模块~~
进击のpython
模块
-
是什么?
其实随着开发的过程中,
你就能感受到两个问题,
一是代码越来越长,越来越长,是真的长
二是命名问题,是真的,你把你学过的工地英语全部用上也满足不了开发的需求
怎么办呢?
你说,我们钉钉子的时候,我们非要先做个锤子然后再钉嘛?
是不是锤子就已经有了,拿过来直接用就行啦!
而你写的代码有一部分就是在做锤子
而模块,就是锤子!
相比较做锤子钉钉子来说,直接拿锤子钉就可以了
-
能干啥?
能干个锤子!
还能干个扳手!
在迄今为止,python内置300+个锤子,再加上第三方18w+个锤子
基本上你想干啥,都能找到对应的工具
也就是为什么说python简单
因为库是真的多!
-
怎么用?
# 直接导入: import os os.path# 多模块导入: import os import sys import os,sysimport os os.path # 这两句就相当于: from os import path,replace path()from os import path path.split() # 可以写成: from os.path import split split()那我觉得 split 这个太长了,想给它起个名
from os.path import split as s s()那我想用这个模块,但是先不知道用那个方法,怎么办?
from os import *但是!不建议使用!
为什么?
我把os里所有的模块都调用出来
结果你就用一个方法?????
那多占内存啊!
虽然不差那么点东西,但是还有个更重要的原因!
from os import * from sys import * name好嘞,我现在调用了name,你知道是os的还是sys的嘛?
(是sys的,后调用的向前覆盖)
那我就想调用os的name你怎么办?对不!
还有要注意的就是,模块的调用要写在程序的开始!
不是说写中间不行,只是不规范!
那我要是想自己做一个锤子随身携带可以不?
当然可以啊
那我要怎么调用呢?
我现在先创建一个 a56.py 的文件
# a56.py print("这是自己写的模块") def func(n): print(f"你输入的是:{n}")再创建一个 a78.py 文件
# a78.py import a56执行之后就是这样的:
这是自己写的模块调用 a56.py里面的函数
# a78.py import a56 a56.func("jhgsrgxe")执行结果:
这是自己写的模块 你输入的是:jhgsrgxe
-
去哪下
通用方法:利用pip方法来下载(憋跟我说源码操作!没的卵用)
pip install #库名慢不慢???就问你慢不慢!!!!!!!!
为什么这么慢呢?
因为这种方法就相当于去国外的服务器下载
当然就会很慢(挂vpn的别bb)
所以我们一般都会去国内的镜像网站去下载相应的库
比较好的就是 豆瓣源(https://pypi.doubanio.com/simple/)
比如我想下载 paramiko 这个模块
怎么做呢?
pip install -i https://pypi.doubanio.com/simple/ maramiko执行了吗?什么情况?

如果你是这样 那就得讲一下了(其实你们大部分都是这种情况)
黄字是警告!红字是错误!
红字说没有这个模块!
不对啊!不是镜像网站嘛!怎么能没有呢?
来,我们看看黄字怎么说!
这是一个不安全或者不被信任的网站,你要是想下载的话就在后面加个东西
--trusted-host pypi.douban.com
OHOHOOOOOOHOHOHOHOHOHOHOHOHO~
-所以,应-这么写:
pip install -i https://pypi.doubanio.com/simple/ maramiko --trusted-host pypi.douban.com这样你就会发现!!!!很快!!!!!!!!!
-
常用模块
1、os/sys模块 :没啥说的,这个东西自己用到哪个就记住就完事了
2、time&datetime模块:时间模块
-
时间的显示
时间戳:从1970年1月1日到现在度过的秒数
time.time()
格式化的时间字符串:2019-07-22 12:00
元组(struck_time):九个元素
UTC时间:(世界协调时),就是格林威治时间
DST 夏令时
-
时间的转换(time模块)
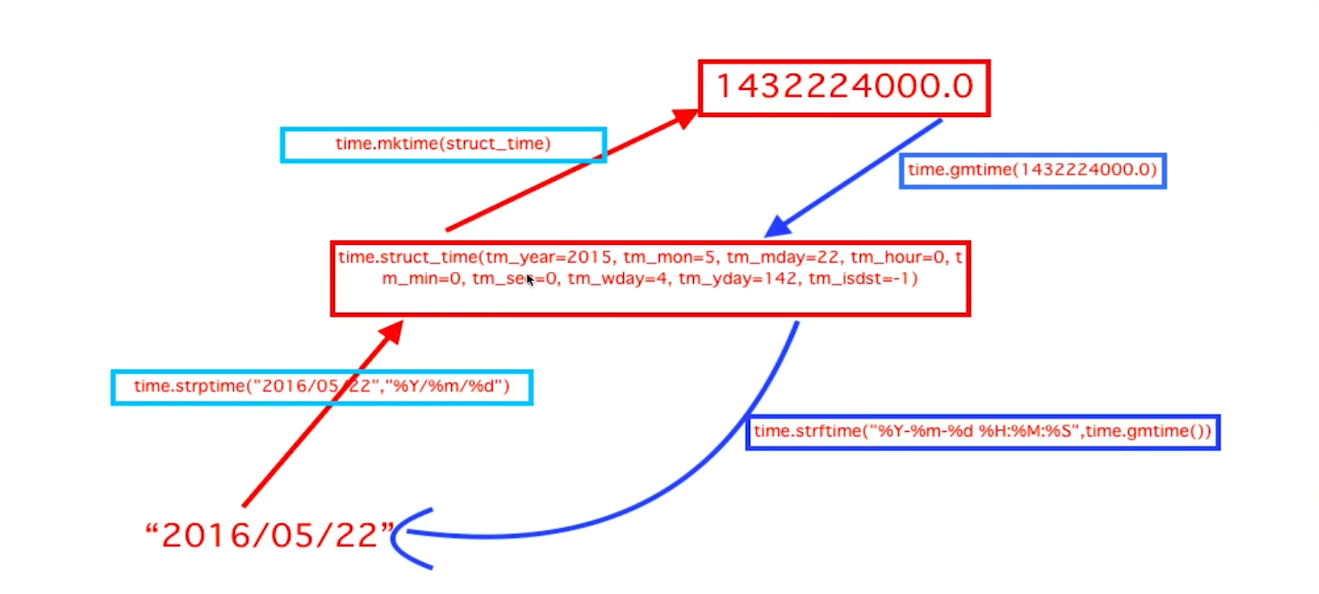
import time import zsh print(time.localtime()) # 将时间戳转换成元组形式,不指定参数,以当前时间为准 # time.struct_time(tm_year=2019, tm_mon=7, tm_mday=10, tm_hour=15, tm_min=15, tm_sec=37, tm_wday=2, tm_yday=191, tm_isdst=0) print(time.gmtime()) # 将时间戳转换成格林威治时间的元组形式,不指定参数,以当前时间为准 # time.struct_time(tm_year=2019, tm_mon=7, tm_mday=10, tm_hour=7, tm_min=19, tm_sec=24, tm_wday=2, tm_yday=191, tm_isdst=0) print(time.time()) # 打印当前时间戳 # 1562743243.4245543 g = time.gmtime() print(time.mktime(g)) # 将元组形式转换为时间戳 # 1562714591.0 time.sleep(3) # 让程序睡(停止)一会儿 print("___") print(time.asctime()) # 时间格式化 # Wed Jul 10 15:27:22 2019 print(time.ctime(1562714591.0)) # 将时间戳转化为asctime() # Wed Jul 10 07:23:11 2019 print(time.strftime("%Y", time.localtime())) # 时间格式化输出 # 2019除了有将时间转为字符串的,还有字符串转时间的:
import time print(time.strptime("2012/04/01", "%Y/%m/%d")) # 将字符串转换为时间 # time.struct_time(tm_year=2012, tm_mon=4, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=92, tm_isdst=-1)这有一张图,方便理解吧
-
时间的运算(datetime)
import datetime print(datetime.datetime.now()) # 当前时间 # 2019-07-10 21:15:41.342153 print(datetime.date.fromtimestamp(3333333)) # 传入时间戳,返回格式化时间 # 1970-02-08 t1 = datetime.date.fromtimestamp(3333333) # 1970-02-08 datetime.timedelta(days=3) # 3 days, 0:00:00 print(t1 - datetime.timedelta(days=3)) # 时间运算 还有 miuntes scounds # 1970-02-05 t1 = t1.replace(year=2015) # 时间替换 print(t1) # 2015-02-08
3、random模块:随机模块
-
程序中有很多地方需要用到随机字符,通过random模块可以很容易生成随机字符串
import random print(random.randint(1, 10)) # 生成 1,2,3,4,5,6,7,8,9,10 随机数 print(random.randrange(1, 10)) # 生成 1,2,3,4,5,6,7,8,9 随机数 print(random.randrange(1, 10, 2)) # 生成 1,3,5,7,9 随机数 print(random.random()) # 生成0~1之间的浮点数 0.10487793352120212 print(random.choice("123")) # 返回给定数据集合的随机字符 print(random.sample("123654", 2)) # 返回给定数据集合的随机字符,以及数量 ['6', '1']弄一个随机验证码来看看 顺便用一个新的模块 string
import random import string k = string.ascii_letters + string.digits #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 print("".join(random.sample(k, 4)))还有一个有趣的东西:洗牌
import random import string k = string.ascii_letters + string.digits #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 k_list = list(k) random.shuffle(k_list) print(k_list) #['K', 'H', 'a', 'Z', '8', 'B', '0', 'c', '2', 'A', 'h', 'e', 'P', 'X', '7', 'R', 'u', 'l', 'S', '6', 'o', 'O', 'I', 'f', 'E', 'Q', 'C', '5', 'j', 'd', 'n', 'r', 'x', 'G', 'b', 'Y', 'U', 'M', 'W', 'T', 'm', 'p', 'q', '4', 'i', 's', 'g', '3', 'N', 'V', 't', 'D', 'L', 'y', 'J', '9', 'F', 'z', '1', 'v', 'k', 'w']洗的乱吧!洗牌就是这样的东西!
4、pickel:序列化
-
一般拿到数据类型之后,我们想要存储到硬盘是不能的,因为只支持字符串和字节的模式的存储,所以才有了序列化存在的意义
dic = {"da": 135, "daf": 43, "gawe": 546, "fefw": 455} f = open("123.txt","w") f.write(dic) f.close() print(f)直接写就会报错!

如果用序列化呢?先看看序列化之后是什么
import pickle dic = {"da": 135, "daf": 43, "gawe": 546, "fefw": 455} print(pickle.dumps(dic)) # f = open("123.txt","w") # f.write(dic) # f.close() # print(f)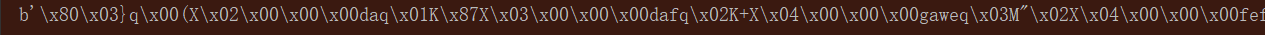
字节模式啊,那你就可以存储了,写入文件了是吧!
那我要是想把这个字节模式给返回呢?
那就叫反序列化:
import pickle dic = {"da": 135, "daf": 43, "gawe": 546, "fefw": 455} s = pickle.dumps(dic) print(pickle.loads(s))
那我们现在开始搞一些操作!将这些写在文件:
import pickle dic = {"da": 135, "daf": 43, "gawe": 546, "fefw": 455} s = pickle.dumps(dic) f = open("123.pkl", "wb") # 后缀用pkl 代表是序列化过的 wb 是因为是字节模式 # f.write(s) # 可以这么写,但是 pickel 提供了新的方法 pickle.dump(dic, f) f.close()那我们要是想拿出来呢?常规操作!
import pickle f = open("123.pkl", "rb") # rb 是因为是字节模式 print(pickle.load(f)) f.close()
要记住一个事
比如我分三次dump进去数据
那我到取出来的时候
每load一次,就取出一次数据
先进先出!
pickle&json区别
pickle 可以每次都dump() 然后循环load()
json 就是只能dump()一次,load()一次
pickle 只能用在python 支持所有数据类型 函数体啊对象啊都支持
json 所有语言都支持,只支持常规数据类型 str int dict set list tuple
5、hashlib模块:加密算法
-
就是通过算法,变换成固定长度的输出,该输出是个数列值。但是不能通过数列值来反推
比如:
dawaaaa⇨hashlib⇨1233211234567
fheigoesjgpejgp⇨hashlib⇨1233211234567
虽然说几率不大,但是是有可能的!
而这种现象,就是“撞库”
但是,每次启动的时候
相同的字符串的哈希是不一样的!
那我这随机加密??没什么用啊!!!
所以 就 根据 哈希算法 就研究出了 MD5 加密
-
MD5
想看概念,自己百度去
不可逆!!!
为啥用??
安全!!!防止被篡改!!!
防止直接看明文!!!!!!
数字签名(不知道也行)
import hashlib m = hashlib.md5() m.update("hello world") print(m.digest())直接这么写,会报错!

是因为没有转换成byte类型
import hashlib m = hashlib.md5() m.update(b"hello world") print(m.digest())返回值都是字节,所以为了好看,我们转换为16进制
import hashlib m = hashlib.md5() m.update(b"hello world") print(m.hexdigest()) # 5eb63bbbe01eeed093cb22bb8f5acdc3这就熟悉了吧!
6、shutil 模块:文件copy
-
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutilshutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在shutil.copy(src, dst)
拷贝文件和权限
import shutilshutil.copy('f1.log', 'f2.log')shutil.copy2(src, dst)
拷贝文件和状态信息
import shutilshutil.copy2('f1.log', 'f2.log')shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutilshutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutilshutil.rmtree('folder1')shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutilshutil.move('folder1', 'folder3')shutil.make_archive(base_name, format,…)
创建压缩包并返回文件路径,例如:zip、tar
可选参数如下:
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录 import shutil ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') #将 /data下的文件打包放置 /tmp/目录 import shutil ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩&解压缩
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall(path='.')z.close()tarfile压缩&解压缩
import tarfile # 压缩 >>> t=tarfile.open('/tmp/egon.tar','w') >>> t.add('/test1/a.py',arcname='a.bak') >>> t.add('/test1/b.py',arcname='b.bak') >>> t.close() # 解压 >>> t=tarfile.open('/tmp/egon.tar','r') >>> t.extractall('/egon') >>> t.close()
7、re模块:正则表达式
-
需求
请从以下文件里取出所有的手机号
姓名 地区 身高 体重 电话 张三 北京 171 48 13651054656 李四 上海 169 46 13813234455 王五 深圳 173 50 13744234545 赵六 广州 172 52 15823423569 刘能 北京 175 49 18623423478 大脚 北京 170 48 18623423789 长贵 深圳 177 54 18835324583 香秀 深圳 174 52 18933434482 大国 上海 171 49 18042432356 大拿 北京 167 49 13324523343你能想到的办法是什么?
必然是下面这种吧?
f = open("象牙山.txt",'r',encoding="gbk") phones = [] for line in f: name,city,height,weight,phone = line.split() if phone.startswith('1') and len(phone) == 11: phones.append(phone) print(phones)有没有更简单的方式?
手机号是有规则的,都是数字且是11位,再严格点,就都是1开头,如果能把这样的规则写成代码,直接拿规则代码匹配文件内容不就行了?
import re f = open("象牙山.txt") data = f.read() print(re.findall("[0-9]{11}", data))
这么nb的玩法是什么?它的名字叫正则表达式!
-
re模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re
常用规则!!!!!!!!!!!!!!!!!!

(偷的图,,,不不不,,读书人的事情怎么能叫偷呢?)
re的匹配语法有以下几种
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
有几个比较好玩的应用
你想通过数字将字符串进行分割,怎么办呢?
import re s = "f5few4f864f634g6sg4g48e" print(re.findall("\D+", s)) # ['f', 'few', 'f', 'f', 'g', 'sg', 'g', 'e']知道身份证号吧(230811199704147033)
知道组成格式吧(不知道去百度去)
那我们想拿到城市等相关信息怎么做呢?
import re s = "230811199704147033" print(re.search("([0-9]{3})([0-9]{3})([0-9]{4})", s).group()) # 2308111997那我想分开打印呢?(group⇨groups)
# ('230', '811', '1997')那我还想把它变成字典呢???(?P<字典的键>)
import re s = "230811199704147033" print(re.search("(?P<province>[0-9]{3})(?P<city>[0-9]{3})(?P<year>[0-9]{4})", s).groupdict()) # {'province': '230', 'city': '811', 'year': '1997'}其他的还有什么呢?
re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
import re obj = re.search('\d+', 'u123uu888asf') if obj: print obj.group()re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re obj = re.findall('\d+', 'fa123uu888asf') print objre.sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串,比str.replace功能更加强大
>>>re.sub('[a-z]+','sb','武配齐是abc123',) >>>re.sub('\d+','|','alex22wupeiqi33oldboy55',count=2) 'alex|wupeiqi|oldboy55're.split(pattern, string, maxsplit=0, flags=0)
用匹配到的值做为分割点,把值分割成列表
>>>s='9-2*5/3+7/3*99/4*2998+10*568/14' >>>re.split('[\*\-\/\+]',s) ['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14'] >>> re.split('[\*\-\/\+]',s,3) ['9', '2', '5', '3+7/3*99/4*2998+10*568/14']re.fullmatch(pattern, string, flags=0)
整个字符串匹配成功就返回re object, 否则返回None
re.fullmatch('\w+@\w+\.(com|cn|edu)',"alex@oldboyedu.cn")
-
标识符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变’^’和’$’的行为
- re.S(DOTALL): 改变’.’的行为,make the ‘.’ special character match any character at all, including a newline; without this flag, ‘.’ will match anything except a newline.
- re.X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样
a = re.compile(r"""\d + # the integral part \. # the decimal point\d * # some fractional digits""",re.X) b = re.compile(r"\d+\.\d*")
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号