
高速缓冲存储器Cache
概述
问题的提出
避免CPU“空等”的现象
CPU和主存的速度差异
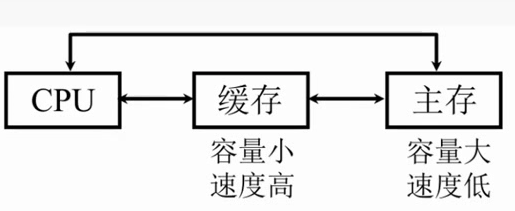
容量非常小,但是速度非常高,他就能提高CPU的访存速率了。
为了充分发挥cache的作用,切实提高CPU的访存速率,所以CPU的访问数据和指令要求能大多数都能在cache中能够取到,这样就不需要到主存中去取了。这需要依靠局部性原理。
局部性原理
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是临近的。
顺序存放。
所以我们未来要用的信息很可能和我们现在使用的信息的存储空间上是临近的
交换的单位是以块为单位的。
主存分成大小相同的块,Cache也分成了大小相同的块
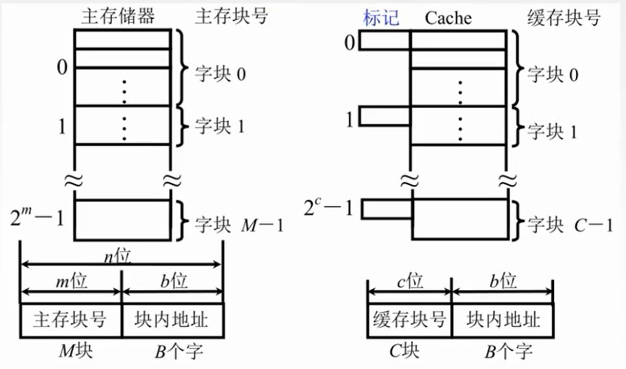
主存和缓存按块存储,块的大小相同,B为块长。
M要远远大于C
块内地址的位数决定了块的大小。假如有16个字节,块内地址就有4位???
主存和缓存的块内地址是完全相同
标记是用来说明主存块和cache的对应关系。
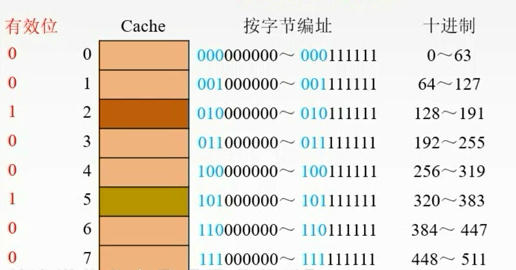
命中与未命中
缓存中有C块
主存中有M块M>>C
命中:主存块已经调入缓存,主存块与缓存块建立了对应关系,用标记记录与某缓存块建立了对应关系的主存块号。
未命中:主存块未调入缓存,主存块与缓存块未建立对应关系。
Cache的命中率
CPU欲访问的信息在Cache中的比率
设一个程序在执行期间,Cache的总命中次数为Nc,访问主存的总次数为Nm,则命中率
命中率和Cache的容量和块长有关
一般每块可取4~8个字
块长取一个存取周期内从主存调出的信息长度
失效率=1-H
Cache-主存系统的效率
效率e与 命中率 有关
如何计算平均访问时间?命中时访问Cache的时间加上不命中在主存的时间
设Cache命中率为h,访问Cache的时间为tc,访问主存的时间为tm
最小值是命中率为0的时候,最大值是命中率为1的时候
例题

设Cache的存储周期是t,则主存的存储周期是5t
Cache和主存同时访问,不命中时访问时间为5t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 5t=1.2t
设每个周期可存取的数据量为S,
则存储系统带宽为S/1.2t
不采用Cache时带宽为S/5t
故性能为原来的
提高了3.17倍
若改为先访问Cache再访问主存的方式:
不命中时,访问Cache耗时t
发现不命中后在访问主存,耗时5t
总耗时6t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 6t = 1.25t
故性能为原来的5t/1.25t=4倍,提高了3倍
工作原理
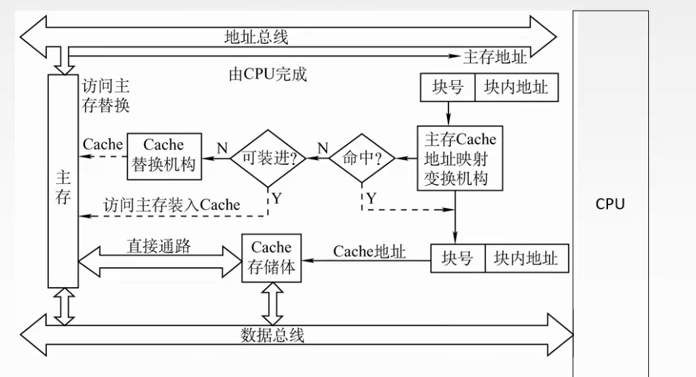
当Cache要读的时候
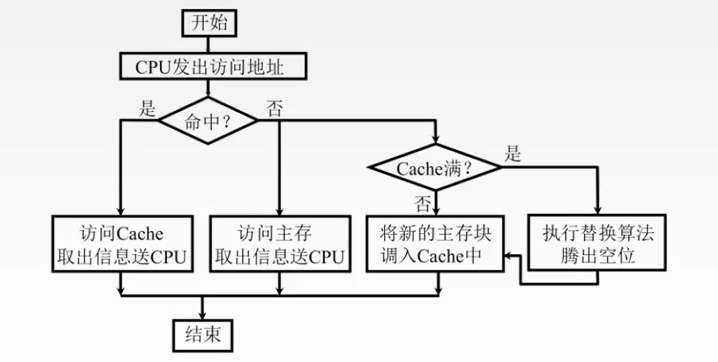
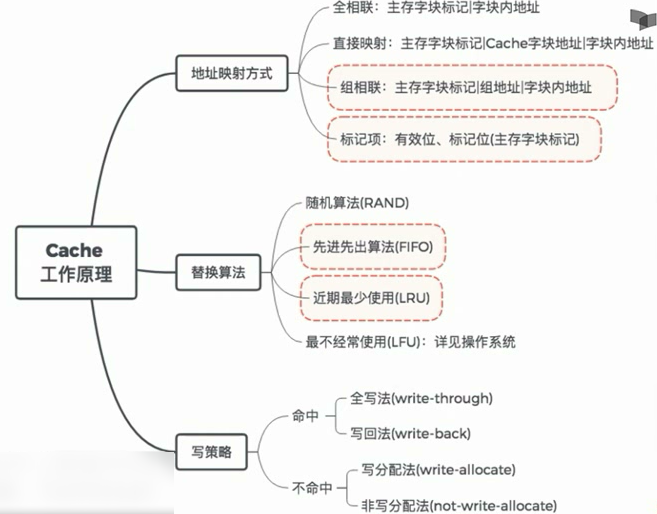
地址映射方式(本节最重要)
1.主存中的块放到Cache中哪个位置?
(1)空位随意放:全相联映射
(2)对号入座:直接映射
(3)按号分组,组内随意放:组相联映射
2.对于(1),Cache满了如何处理?对于(2)(3),对应位置被占用如何处理?
随机(RAND)算法
先进先出(FIFO)算法
近期最少使用(LRU)算法
最不经常使用(LFU)算法
3.修改Cache中的内容后,如何保持主存中相应内容的一致性?
命中:全写法(write-through)、写回法(write-back)
不命中:写分配法(write-allocate)、非写分配法(not-write-allocate)
直接映射
主存当中的数据块只能够装入到Cache的唯一位置。
把主存划分为若干个区,每个区大小和Cache是相等的,每个去的子块数也是相等的。
每个区的对应单元只能对应Cache对应的单元。
主存地址的高m位就被划分为两个部分——主存子块标记,Cache子块地址
记录建立对应关系的缓存位的标记位当中
当缓存接到CPU接来的一个主存地址之后,根据中间的c位(Cache子块地址)找到cache字块,然后根据这个子块的标记,判断****是否与主存的高t位相符,如果相符,并且有效位**是有效(1)的,那么就表示Cache块已经和主存的某一块地址建立了对应关系。
如果不符合的话,就要从主存中读入新的子块。
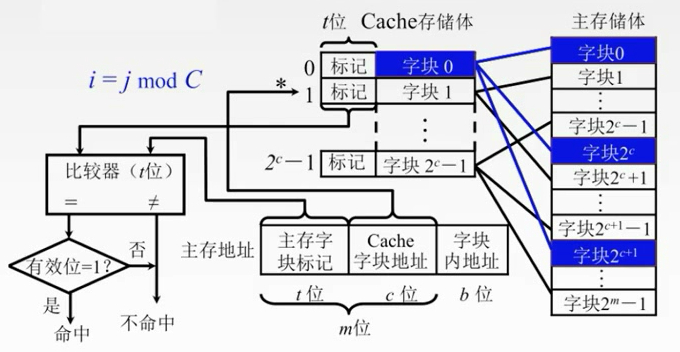
每个缓存块i 可以和若干个主存块对应
每个主存块j 只能和一个缓存块对应
直接映射主存地址被划分为三个部分

j是Cache的块号。i是主存的块号
特点简单,但是不够灵活,容易发生冲突。
即使Cache有很多空位置,但是我还是要找到对应位置的来换
全相联映射
大大提高了利用率,只要有位置就放。但是速度很慢。对比子块标记很麻烦,每块都要比较。
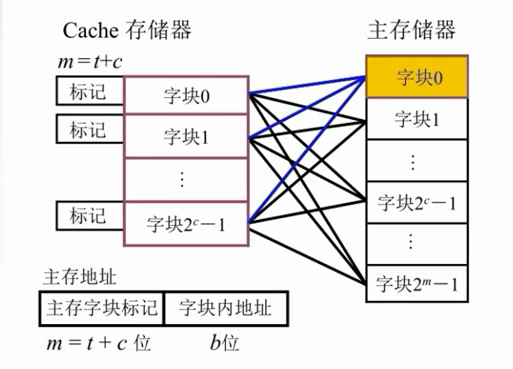
主存中的任一块可以映射到缓存中的任一块
组相联映射
折中。
先把主存储器划分为块,在把每个块划分为组。
先把Cache地址分成大小相同的组,每一个主存的数据块可以装入到一个组内的任何位置。
组间采用直接映射,组内全相联映射。
01,23,45,67,。。。
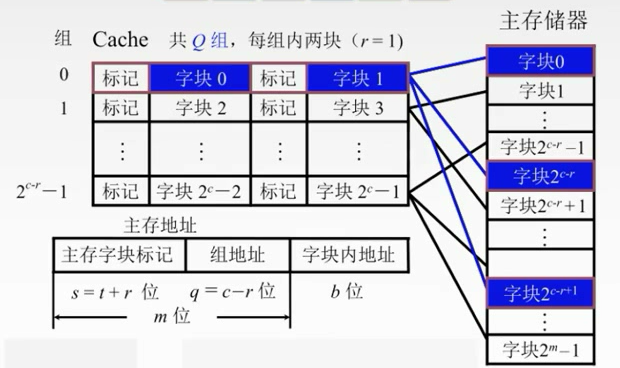

二路组相联映射。
速度快:直接映射
一般:组相联
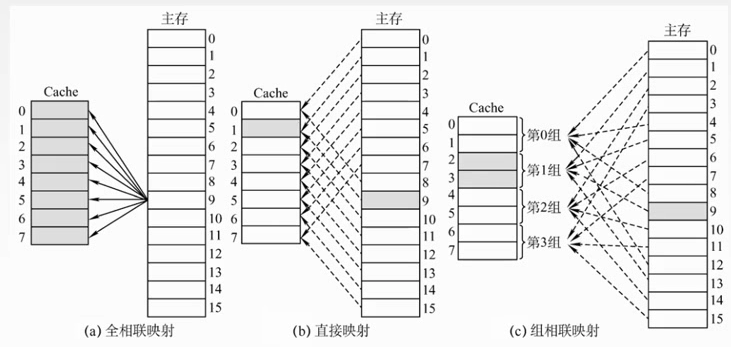
例子

全相联

直接映射

组相联

替换策略
- 随机算法(RAND):随机地确定替换的Cache块。实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低。(基本不考)
- 先进先出算法(FIFO): 选择最早调入的行进行替换。容易实现,但也没有依据程序访问的局部性原理,可能会把一些经常使用的程序块(如循环程序)也作为最早进入的Cache的块替换掉。
- 近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,平均命中率要比FIFO高,是堆栈类算法。LRU算法对每行设置一个计数器,Cache每命中一次,命中行计数器清零,而其他各行计数器均加1,需要替换时比较各特定行的计数值,将计数值最大的行换出。
- 最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从0开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。
例题

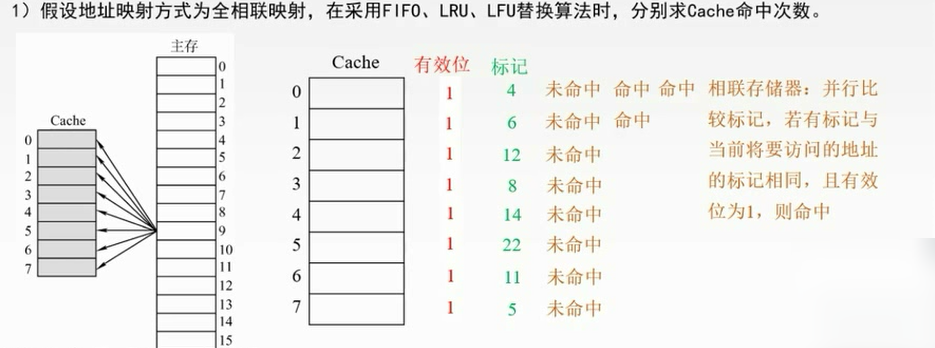
FIFO:把4替换掉
LRU:最近最少使用的是12,替换掉。从后往前数,最后那个就是最不常用的

LFU:4号块用了3次,6号块用了2次,其他均用了1次,需要更多的判断依据。换12

只命中了1次。
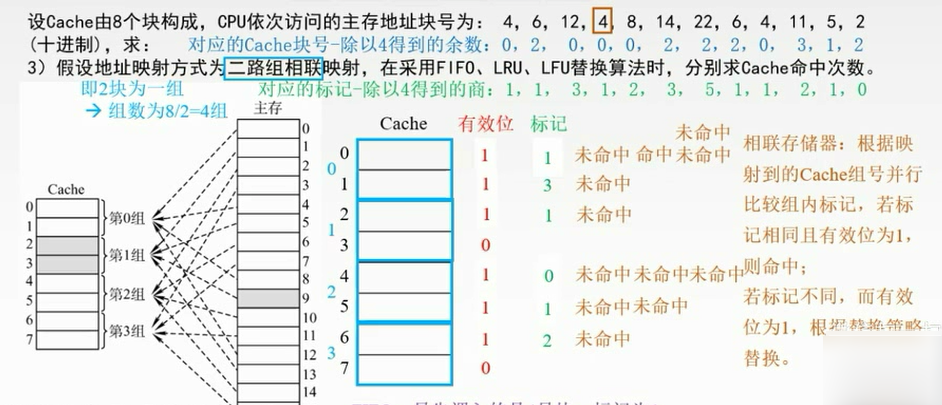
在组内是用不同的替换算法的。
FIFO:在第0组中,最先调入的是4号块,标记为1,命中0次
列表的方法。
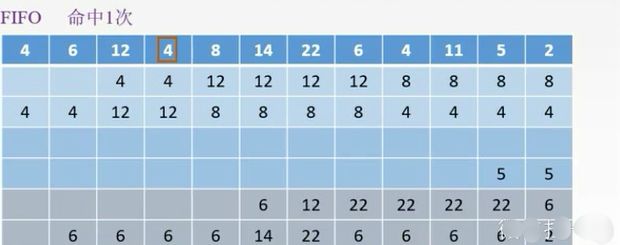
每次都放到每组的最下面,然后出去的就是先进先出的。
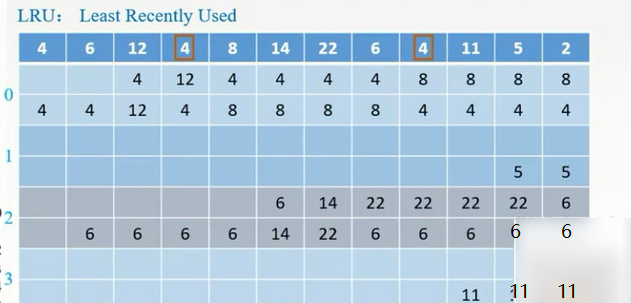
如果用了就把它移上去。
LFU:操作系统。
写策略
命中

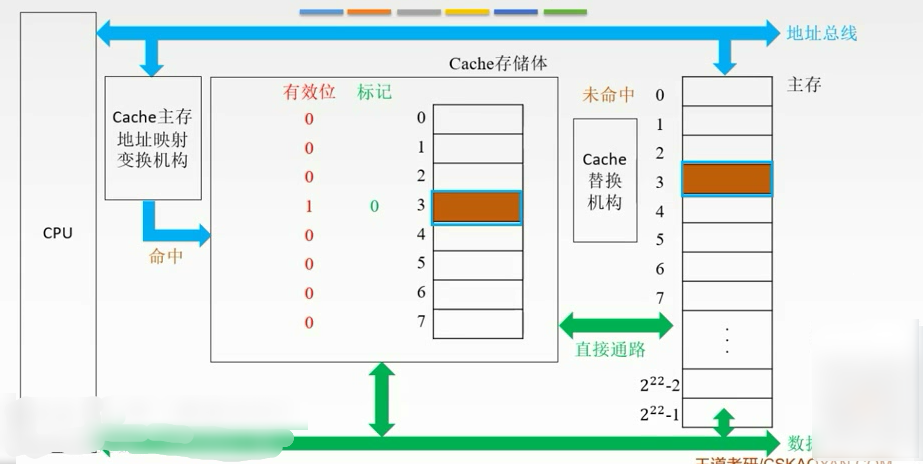
如果对Cache的内容进行修改,就要修改主存中对应的块。
命中:要访问的主存内容已经在Cache当中。
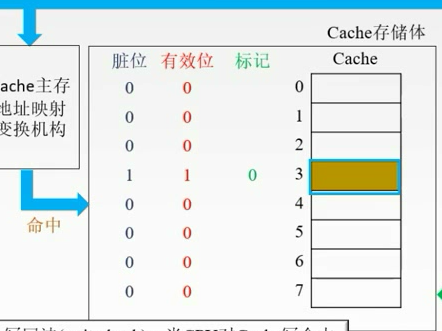
这块要被换掉之后才把主存的修改掉。写回法。加多一个脏位
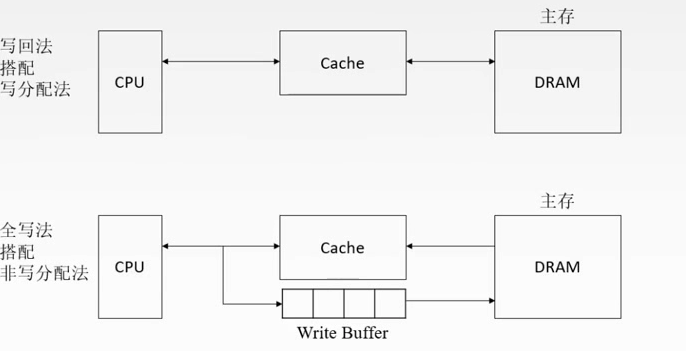
写回法(write-back):当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
每次有修改就改,不用脏位了,但是增加访存次数。
全写法(write-through):当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
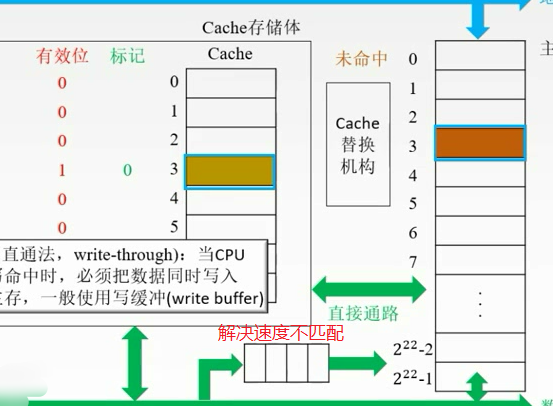
写的太频繁,会有队列的溢出。
未命中
写分配法(write-allocate):把主存中的块调入Cache,在Cache中修改,搭配写回法使用。
缺点:每次不命中都要从主存中读取块。
非写分配法(not-write-allocate):只写入主存,不调入Cache,搭配全写法使用。
小结
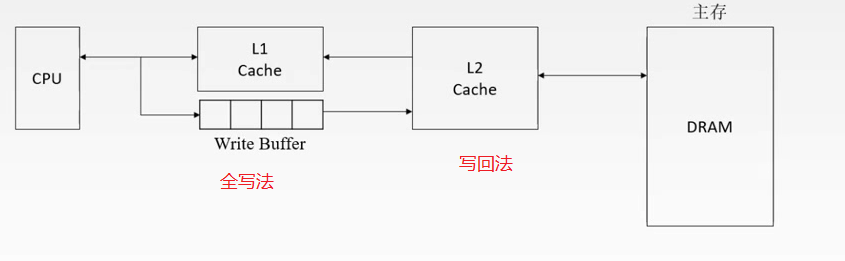
多级Cache
本节小结
本文作者:Jev_0987
本文链接:https://www.cnblogs.com/jev-0987/p/13561115.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步