中文新词发现相关算法调研
(一)专业领域的新词发现竞赛:“AIIA”杯-国家电网-电力专业领域词汇挖掘
地址:https://www.datafountain.cn/competitions/320/datasets
(二)新词发现,基于信息熵和词的凝合度算法(无预定义词库)
参考文章:互联网时代的社会语言学:基于SNS的文本数据挖掘http://www.matrix67.com/blog/archives/5044
挖掘新词的传统方法是,先对文本进行分词,然后猜测未能成功匹配的剩余片段就是新词。这似乎陷入了一个怪圈:分词的准确性本身就依赖于词库的完整性,如果词库中根本没有新词,我们又怎么能信任分词结果呢?此时,一种大胆的想法是,首先不依赖于任何已有的词库,仅仅根据词的共同特征,将一段大规模语料中可能成词的文本片段全部提取出来,不管它是新词还是旧词。然后,再把所有抽出来的词和已有词库进行比较,不就能找出新词么。这篇文章基于信息熵和词的凝合度给出了一套完整的新词发现算法方案。最后,还通过分析不同时间段发现的新词进行了热词、热点趋势分析。
代码实现地址:https://spaces.ac.cn/archives/3491
(1)词的凝合度:要想从一段文本中抽出词来,我们的第一个问题就是,怎样的文本片段才算一个词?大家想到的第一个标准或许是,看这个文本片段出现的次数是否足够多。我们可以把所有出现频数超过某个阈值的片段提取出来,作为该语料中的词汇输出。不过,光是出现频数高还不够,一个经常出现的文本片段有可能不是一个词,而是多个词构成的词组。在人人网用户状态中,“的电影”出现了 389 次,“电影院”只出现了 175 次,然而我们却更倾向于把“电影院”当作一个词,因为直觉上看,“电影”和“院”凝固得更紧一些。为了证明“电影院”一词的内部凝固程度确实很高,我们可以计算一下,如果“电影”和“院”真的是各自独立地在文本中随机出现,它俩正好拼到一起的概率会有多小。在整个 2400 万字的数据中,“电影”一共出现了 2774 次,出现的概率约为 0.000113 。“院”字则出现了 4797 次,出现的概率约为 0.0001969 。如果两者之间真的毫无关系,它们恰好拼在了一起的概率就应该是 0.000113 × 0.0001969 ,约为 2.223 × 10-8 次方。但事实上,“电影院”在语料中一共出现了 175 次,出现概率约为 7.183 × 10-6 次方,是预测值的 300 多倍。类似地,统计可得“的”字的出现概率约为 0.0166 ,因而“的”和“电影”随机组合到了一起的理论概率值为 0.0166 × 0.000113 ,约为 1.875 × 10-6 ,这与“的电影”出现的真实概率很接近——真实概率约为 1.6 × 10-5 次方,是预测值的 8.5 倍。计算结果表明,“电影院”更可能是一个有意义的搭配,而“的电影”则更像是“的”和“电影”这两个成分偶然拼到一起的。
(2)信息熵:“信息熵”是一个非常神奇的概念,它能够反映知道一个事件的结果后平均会给你带来多大的信息量。如果某个结果的发生概率为 p ,当你知道它确实发生了,你得到的信息量就被定义为 – log(p) 。 p 越小,你得到的信息量就越大。如果一颗骰子的六个面分别是 1 、 1 、 1 、 2 、 2 、 3 ,那么你知道了投掷的结果是 1 时可能并不会那么吃惊,它给你带来的信息量是 – log(1/2) ,约为 0.693 。知道投掷结果是 2 ,给你带来的信息量则是 – log(1/3) ≈ 1.0986 。知道投掷结果是 3 ,给你带来的信息量则有 – log(1/6) ≈ 1.79 。但是,你只有 1/2 的机会得到 0.693 的信息量,只有 1/3 的机会得到 1.0986 的信息量,只有 1/6 的机会得到 1.79 的信息量,因而平均情况下你会得到 0.693/2 + 1.0986/3 + 1.79/6 ≈ 1.0114 的信息量。这个 1.0114 就是那颗骰子的信息熵。现在,假如某颗骰子有 100 个面,其中 99 个面都是 1 ,只有一个面上写的 2 。知道骰子的抛掷结果是 2 会给你带来一个巨大无比的信息量,它等于 – log(1/100) ,约为 4.605 ;但你只有百分之一的概率获取到这么大的信息量,其他情况下你只能得到 – log(99/100) ≈ 0.01005 的信息量。平均情况下,你只能获得 0.056 的信息量,这就是这颗骰子的信息熵。再考虑一个最极端的情况:如果一颗骰子的六个面都是 1 ,投掷它不会给你带来任何信息,它的信息熵为 – log(1) = 0 。什么时候信息熵会更大呢?换句话说,发生了怎样的事件之后,你最想问一下它的结果如何?直觉上看,当然就是那些结果最不确定的事件。没错,信息熵直观地反映了一个事件的结果有多么的随机。我们用信息熵来衡量一个文本片段的左邻字集合和右邻字集合有多随机。考虑这么一句话“吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮”,“葡萄”一词出现了四次,其中左邻字分别为 {吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} 。根据公式,“葡萄”一词的左邻字的信息熵为 – (1/2) · log(1/2) – (1/2) · log(1/2) ≈ 0.693 ,它的右邻字的信息熵则为 – (1/2) · log(1/2) – (1/4) · log(1/4) – (1/4) · log(1/4) ≈ 1.04 。可见,在这个句子中,“葡萄”一词的右邻字更加丰富一些。
(3)新词发现结合已有词库就可以识别出当前文本中出现了那些新词。对于按天产生的文本将每一天发现的新词的词频与昨天进行比较从而提取出这一天里特有的词。这样一来,我们就能从用户状态中提取出每日热点。
(三)新词发现:基于切分的新词发现
参考文献:【中文分词系列】 2. 基于切分的新词发现
https://spaces.ac.cn/archives/3913
文献(二)《互联网时代的社会语言学:基于SNS的文本数据挖掘》在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到n字词,就需要找出1∼n字的切片,然后分别做计算,这对于n比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
如果a,b是语料中相邻两字,那么可以统计(a,b)成对出现的次数#(a,b),继而估计它的频率P(a,b),然后我们分别统计a,b出现的次数#a,#b,然后估计它们的频率P(a),P(b),如果

那么就应该在原来的语料中把这两个字断开。这个操作本质上就是——我们根据这个指标,对原始语料进行初步的分词!在完成初步分词后,我们就可以统计词频了,然后根据词频来筛选。
(四)语言模型进行无监督分词从而进行新词发现
文章参考:《【中文分词系列】 5. 基于语言模型的无监督分词 》[Blog post]. https://spaces.ac.cn/archives/3956
本文要介绍的分词方法,就是以“基于字的语言模型”为基础的。我们从最大概率法出发,如果一个长度为l的字符串s1,s2,…,sl,最优分词结果为w1,w2,…,wm,那么它应该是所有切分中,概率乘积p(w1)p(w2)…p(wm)最大的一个。假如没有词表,自然也就不存在w1,w2,…,wm这些词了。但是,我们可以用贝叶斯公式,将词的概率转化为字的组合概率:
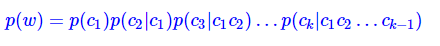
其中w是一个k字词,c1,c2,…,ck分别是w的第1,2,…,k个字。可以发现,p(ck|c1c2…ck−1)就是我们前面提到的字的语言模型(可以使Ngram语言模型,因为一个词的长度一般不会很长)。
(五)基于凝合度+语言模型的新词发现算法
参考文献:《【中文分词系列】 8. 更好的新词发现算法 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/4256
本文在文献(三)和(四)的基础上提出将两者优点相结合的方法进行新词发现。最后在微信300万篇文章中构建词库并取得了较好的效果。
文献(三)认为,文本的相关性仅由相邻两字(2grams)来决定,这在很多时候都是不合理的,比如“林心如”中的“心如”、“共和国”中的“和国”,凝固度(相关性)都不是很强,容易错切。因此,本文就是在前文的基础上改进,那里只考虑了相邻字的凝固度,这里同时考虑多字的内部的凝固度(ngrams),比如,定义三字的字符串内部凝固度为:
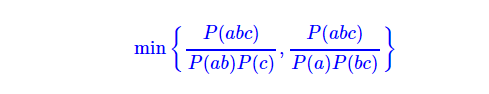
这个定义其实也就是说,要枚举所有可能的切法,因为一个词应该是处处都很“结实”的,4字或以上的字符串凝固度类似定义。一般地,我们只需要考虑到4字(4grams)就好(但是注意,我们依旧是可以切出4字以上的词来的)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号