使用GDB调试(上篇:配置、分析core文件)
在Linux系统中配置生成用于GDB分析的core dump(核心转储)文件,可以按照以下步骤进行:
步骤 1: 核心转储使能设置
首先,你需要确认系统的核心转储设置是否符合要求。可以通过以下命令检查当前设置:
ulimit -c
1.临时配置
这个命令会显示核心转储文件的最大大小。如果输出为 0,则表示核心转储功能被禁用。你可以使用以下命令临时修改为不限制大小:
ulimit -c unlimited
2.永久配置系统打开生成核心转储文件
-
永久性配置: 如果希望永久性地修改核心转储设置,可以编辑
/etc/security/limits.conf文件,添加如下内容: -
Copy Code
* hard core unlimited这会使得所有用户的核心转储文件大小限制为无限制。
格式是<domain> <type> <item> <value>
#<domain> can be:
# - a user name
# - a group name, with @group syntax
# - the wildcard *, for default entry
# - the wildcard %, can be also used with %group syntax,
# for maxlogin limit
#
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
#
#<item> can be one of the following:
# - core - limits the core file size (KB)
# - data - max data size (KB)
# - fsize - maximum filesize (KB)
# - memlock - max locked-in-memory address space (KB)
# - nofile - max number of open file descriptors
# - rss - max resident set size (KB)
# - stack - max stack size (KB)
# - cpu - max CPU time (MIN)
# - nproc - max number of processes
# - as - address space limit (KB)
# - maxlogins - max number of logins for this user
# - maxsyslogins - max number of logins on the system
# - priority - the priority to run user process with
# - locks - max number of file locks the user can hold
# - sigpending - max number of pending signals
# - msgqueue - max memory used by POSIX message queues (bytes)
# - nice - max nice priority allowed to raise to values: [-20, 19]
# - rtprio - max realtime priority
#
#<domain> <type> <item> <value>
步骤 2: 核心文件存放位置
核心转储文件默认情况下会存放在进程的当前工作目录下,通常以 core 为文件名前缀。你可以通过修改 /proc/sys/kernel/core_pattern 文件来自定义核心转储文件的存放位置和命名规则。
例如,通过以下命令查看当前的核心转储文件设置:
cat /proc/sys/kernel/core_pattern
默认情况下,可能会显示类似于 /var/core/core.%e.%p.%h.%t 的设置,其中 %e 表示可执行文件名,%p 表示进程ID,%h 表示主机名,%t 表示时间戳。你可以根据需要自定义这个模式,确保目录存在并且有合适的权限。
/var/core/core.%e.%p.%h.%t,这个模式使用了一些特殊变量:
%e:可执行文件名。%p:进程ID。%h:主机名。%t:时间戳。- %s:线程ID。
临时修改:
echo "/tmp/core.%e.%p.%h.%t" > /proc/sys/kernel/core_pattern
永久修改:
要永久修改核心转储文件的存放位置,你需要编辑系统的配置文件,通常是 /etc/sysctl.conf 或 /etc/sysctl.d/coredump.conf,然后sysctl --system或重启系统以确保修改生效
里面有这配置项
kernel.core_pattern = /new/path/core.%e.%p.%t
比如某嵌入式开发板的
/etc/sysctl.d/10-default.conf文件就有以下配置
kernel.core_pattern = /tmp/core.%e.%p.%t.%s
对于10-default.conf文件名,内核参数通常会根据文件名的数字前缀顺序加载,因此较高数字的文件(如99-xxx.conf)会在较低数字的文件(如10-xxx.conf)之后加载。这种顺序控制对于参数之间的依赖关系和优先级很重要
Ubuntu20的是用脚本配置
在启动脚本etc/init.d/apport中:
echo "|$AGENT -p%p -s%s -c%c -d%d -P%P -u%u -g%g -- %E" > /proc/sys/kernel/core_pattern
cat /proc/sys/kernel/core_pattern后可以看到
|/usr/share/apport/apport -p%p -s%s -c%c -d%d -P%P -u%u -g%g -- %E
这个配置文件/proc/sys/kernel/core_pattern指定了系统在出现核心转储(core dump)时,将核心转储的信息传递给apport工具,配置完了sysctl -p或重启生效
|/usr/share/apport/apport -p%p -s%s -c%c -d%d -P%P -u%u -g%g -- %E
。具体参数的含义如下:
-
-p%p: 进程号(PID)-s%s: 信号号-c%c: CPU 核心号-d%d: 当前工作目录-P%P: 父进程的 PID-u%u: 用户 ID-g%g: 用户组 ID--: 分隔符,之后是核心文件的路径%E
所以,当系统发生核心转储时,这个配置会将相关的信息传递给apport工具,用于处理和记录核心转储信息。Apport(应用程序错误报告)是一个用于处理和报告应用程序崩溃、错误和异常的工具。它主要用于Ubuntu及其衍生发行版中,用来捕获程序崩溃时的核心转储(core dump)和其他相关信息,然后生成错误报告并向开发者或维护团队发送。
可以在自启动脚本中,加入这两句命令也达到永久配置效果
ulimit -c unlimited
echo "/new/path/core.%e.%p.%t" > /proc/sys/kernel/core_pattern
步骤 3: 测试核心转储功能
为了验证配置是否生效,可以创建一个简单的程序,例如 test.c:
#include <stdio.h>
#include <stdlib.h>
void segfault() {
char *ptr = NULL;
*ptr = 'a'; // 引发段错误
}
int main() {
segfault();
return 0;
}
编译并运行该程序:
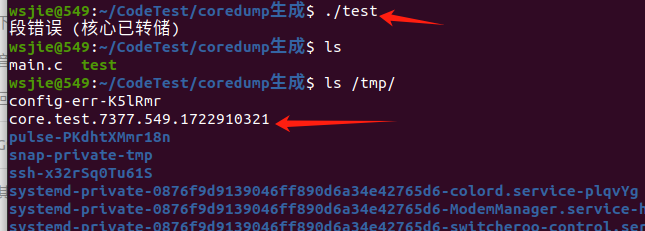
gcc test.c -o test
./test
如果一切配置正确,会在程序运行时生成一个名为 core 的文件(或者根据你设置的模式生成的文件),你可以用 GDB 进行后续分析:
gdb ./test core
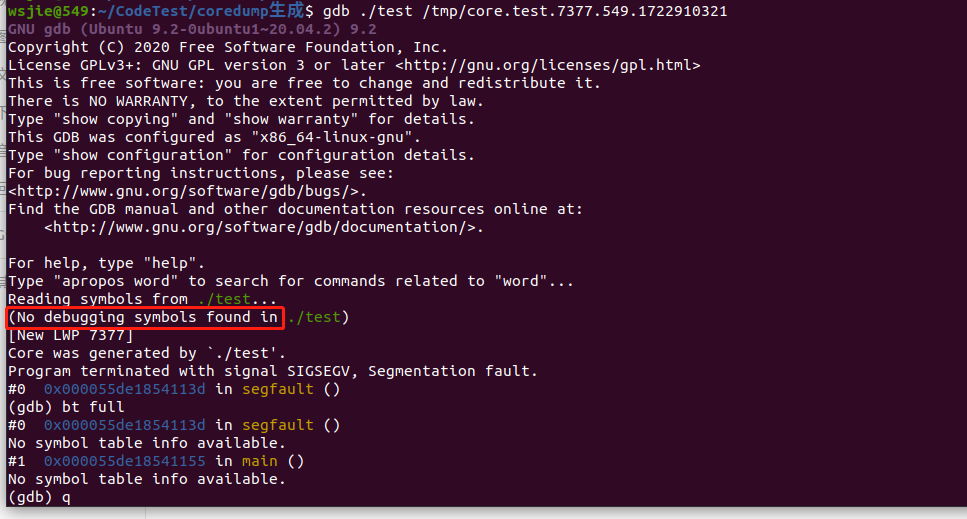
如果不加-g选项进行编译时,就会提示no debug信息,解开core文件后,看到的信息相对比较少,这里是只有函数信息
加入-g编译后

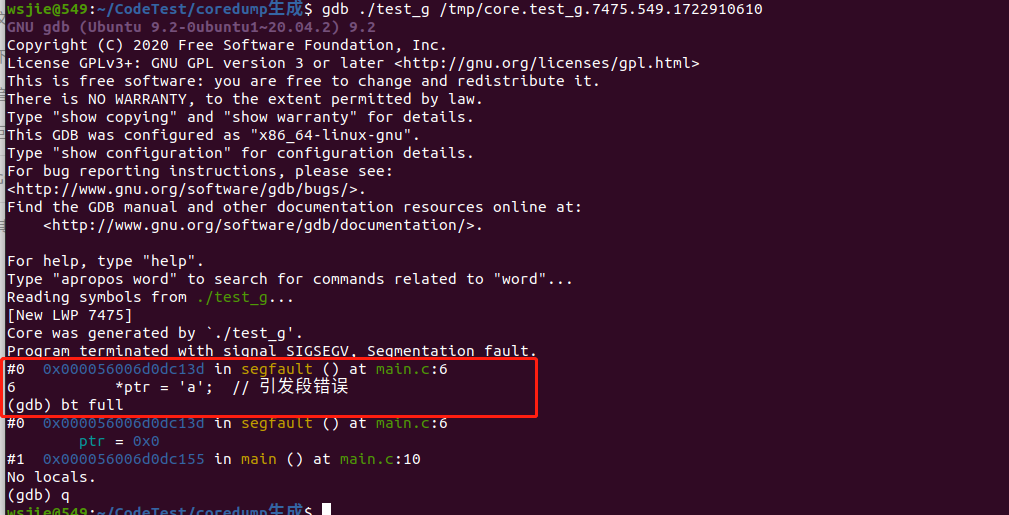
解开core文件后,看到的信息比较多,可以定位到代码的这一行
当有依赖库时,可以使用以下方式运行
先运行gdb
set auto-load safe-path / 加载自动加载的文件时,只从根目录开始寻找并加载,对于安全性很重要,因为它限制了 GDB 在加载文件时的搜索路径
set solib-search-path /lib /usr/lib 允许你设置一个或多个目录路径,告诉 GDB 在这些路径下搜索共享库文件.也可以使用冒号连接/lib:/usr/lib
set solib-absolute-prefix /lib /usr/lib 设置共享库文件所在的绝对路径前缀
file /bin/test_g 设置对应coredump的可执行文件(应用)
core-file tmp/core.test_g.7475.549.1722910610 设置对应coredump文件
可以写成脚本,解析coredump文件
gdb_parse.sh
#!/bin/bash # File: gdb_parse.sh # Brief: A bash script to quickly run arm-gdb on core files for the Gen GM12 project # ./gdb_parse.sh /bin/test_g /tmp/core.test_g.2396.1662184593 #可以导入环境变量 #source ./env_init.sh
if [ $# -ne 2 ]; then echo "Invalid arguments" echo "usage: $0 <Binary Path> <Core-file Path>" exit fi BINARY=$1 CORE_FILE=$2
#配置gdb路径,如果是arm的,可以配置绝对路径。导入环境后,也可以配置相对路径
ARM_GDB=xxx/xxx/xxx/xxxx/gdb function gdb_check { printOut "Check if xxxx/gdb exists." if [ -f "$ARM_GDB" ];then echo -e "Found $ARM_GDB \n" else echo -e "$ARM_GDB not found!exit gdb \n" exit fi } function gdb_parse { echo -e "Start GDB\n" $ARM_GDB << GDB_SHELL set auto-load safe-path / set solib-search-path /lib:/usr/lib file $BINARY core-file $CORE_FILE bt full GDB_SHELL }
gdb_check
gdb_parse
还可以使用以下的命令进一步分析
1.分析堆栈信息 一旦 GDB 加载了 core 文件,它会显示程序崩溃时的堆栈信息。可以使用 bt 命令查看完整的堆栈回溯: (gdb) bt #0 0x0000555555555206 in main () at crash_example.c:5 这里显示了程序在 crash_example.c 文件的第 5 行崩溃。通过查看堆栈信息,可以了解到程序是如何到达崩溃点的。 2.查看变量状态 可以使用 print 命令查看变量的当前状态。例如,假设我们想查看某个变量的值: (gdb) print some_variable 这将显示 some_variable 的当前值。 3.分析内存状态 可以查看内存中特定地址的内容。例如,查看某个地址的内容: (gdb) x/10xg 0x7fffffffde60 // 查看地址0x7fffffffde60处的10个64位长字 这在分析特定内存区域时非常有用。 4.查看源代码和行号 list: 查看当前位置附近的源代码。 (gdb) list list <function_name>: 查看特定函数的源代码。 (gdb) list main 5.查看内存和寄存器状态 info registers: 查看当前寄存器的值。 (gdb) info registers x/<n><fmt> <address>: 以不同格式查看内存中的数据。 (gdb) x/4xw 0x7fffffffe080 // 查看地址0x7fffffffe080处的四个字(每个字为32位) 6.管理线程和进程 info threads: 查看当前线程的信息。 (gdb) info threads thread <id>: 切换到特定的线程。 (gdb) thread 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号