
集合框架笔记
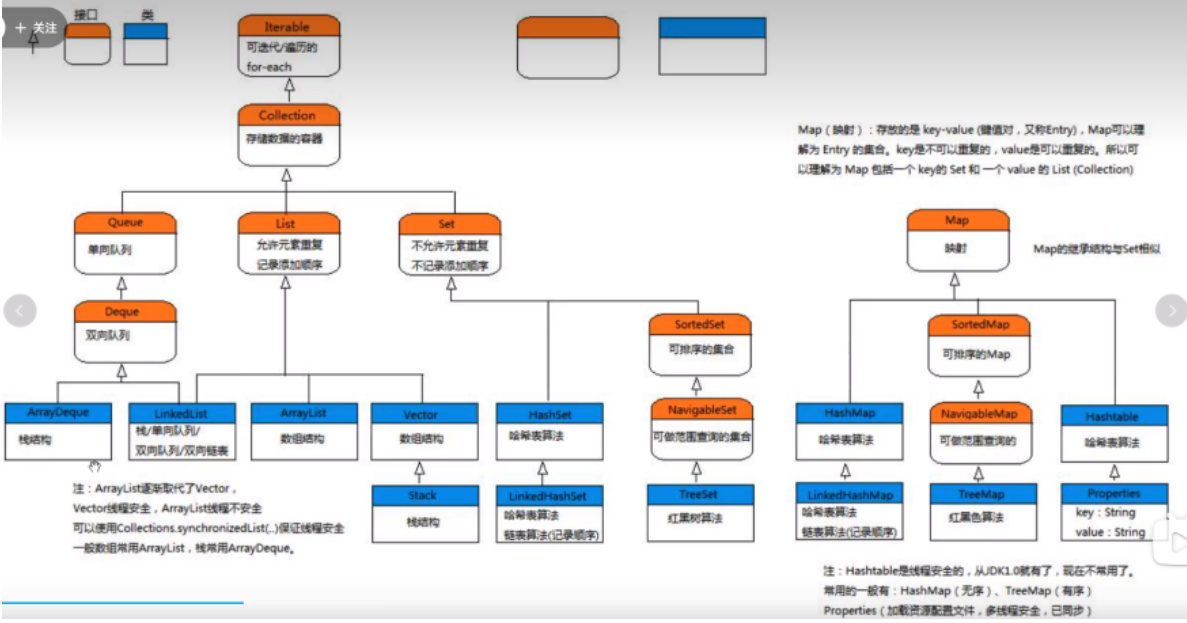
集合框架
ArrayList和LinkedList
-
两者都是实现 list 接口的
LinkedList 的几个常用方法:
-
addFirst( ); addLast( ) ; removeFirst( ); removeLast( ); getFirst( ); getLast( );
Vector:List的古老实现类,线程安全,效率低;底层使用Object[ ]存储;基本不使用了;
ArrayList:List的实现类,线程不安全,添加,查询效率高,时间复杂度为O(1)
插入,删除效率低,时间复杂度为O(n),底层使用数组Object[ ]存储;
new ArrayList( ) :底层创建长度为10的数组;
new ArrayList(int capacity) :底层数组长度由capacity决定,所以在实际开发中遇到确定的数组长 度,可以自定义长度,不使用默认长度,这样避免频繁地扩容操作
LinkedList:List的实现类,线程不安全,添加,查询效率低,时间复杂度为O(n),
插入,删除效率高,时间复杂度为O(1),底层使用双向链表存储
是没有扩容机制的。
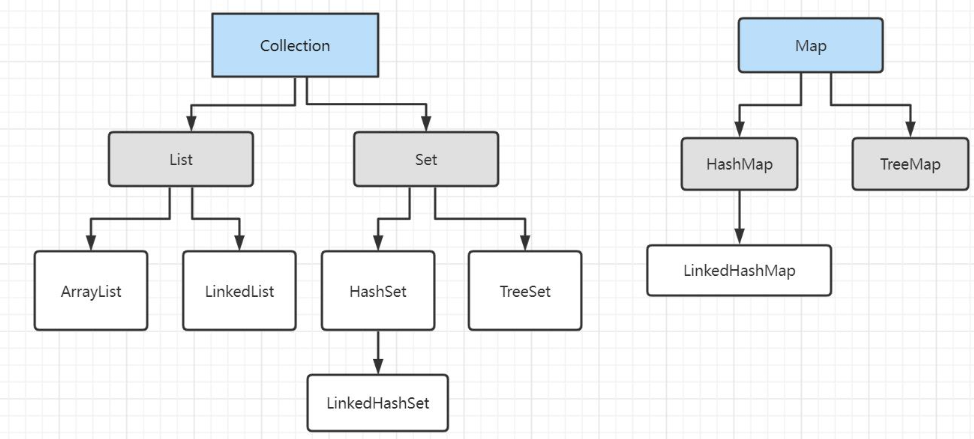
Set
特点:无序的,不可重复的(高中所学的集合)
HashSet
-
底层是使用hashMap,使用了数组+单向链表+红黑树结构进行储存
-
在add一个对象的时候,就是保存它的hashcode值,所以在保存时,存储的时候,会遇到不唯一的现象
解决:在所在对象重写hashcode,equal方法,避免出现重复现象
-
equals方法比较的是内存地址是否相等,因此一般情况下也无法满足两个对象值的比较。
重写equals方法是为了比较两个不同对象的值是否相等 重写hashCode是为了让同一个Class对象的两个具有相同值的对象的Hash值相等。 同时重写hashCode()与equals()是为了满足HashSet、HashMap等此类集合的相同对象的不重复存储。 ————————————————
public class HashSetTest {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student("ljx",15));
set.add(new Student("wal",19));
//输出不了Student("wal",19)
set.add(new Student("wal",19));
System.out.println(set);
System.out.println("------------------");
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(15);
hashSet.add(16);
hashSet.add(17);
//输出不了第二个17
hashSet.add(17);
System.out.println(hashSet);
}
}
//[Student{name='ljx', age=15}, Student{name='wal', age=19}]
------------------
//[16, 17, 15]
LinkedHashSet:
是hashSet的子类,底层是使用LinkedMap结构,是一个双向链表的,用于记录元素的添加顺序,我们可以按照添加元素的顺序实现遍历,这样的好处在于,方便查询,也便于频繁的遍历。
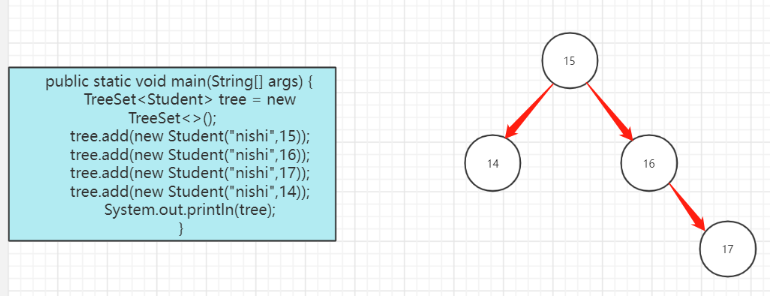
TreeSet
-
底层使用红黑树进行存储
-
在存储的时候要存储同一个类型的对象,否则会报错ClassCastException,不需要重写hashcode和equals方法了
-
在使用时,treeSet在Domain包里面的对象类是需要重写Comparable接口的
不然会出现爆红!
比如:
-
树是在重写compareTo接口,来自定义比较规则
-
树的储存方法:
Map
都是继承java.util.map接口
-
HashMap(源码要熟悉,流程要知道)
• 采用 数组+单向链表+红黑树(jdk8开始) 存储结构
• 优点:添加速度快 查询速度快 删除速度快
• 缺点:key无序,线程不安全
key:是一个不可重复的,无序的,所有key构成一个set集合。需要重写equals和hashcode这两个方法
value:是一个可重复的,无序的,所有value构成一个Collection集合。需要重写equals方法
key-value构成一个entry对象,entry是不可重复的,无序的
-
Hashtable(了解就好)
线程安全的
采用的是数组+单向链表
是很古老的,少用
还有一个子类:Properties其中key和value都是String类型,常用来处理属性文件
-
TreeMap
• 采用二叉树(红黑树)的存储结构
• 优点:key有序 查询速度比List快(按照内容查询)
• 缺点:查询速度没有HashMap快
/*
这个返回值是整数,
若是返回正数,则是从小到大排序
若是返回负数,则是从大到小排序
若是返回0,则是两个数相等
*/ -
LinkedHashMap(源码要熟悉)
• 采用与hashMap同样的存储结构,只是增加了一个双向链表结构,同时使用链表维护次序
• key有序(添加顺序)
• 是一个双向链表的结构,便于频繁的查询

这三种方式在使用的时候差不多,就是在key排序有些差异
put()是保存
get()是获取
遍历
三种方式:
public class TestMap02 {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(1,"123");
map.put(2,"12");
map.put(3,"1255");
map.put(4,"366");
//方式一:
Set<Integer> set = map.keySet();
for (Integer s : set) {
System.out.println(s + "---" + map.get(s));
}
//方式二:
Set<Map.Entry<Integer, String>> entries = map.entrySet();
for (Map.Entry<Integer,String> entry: entries) {
System.out.println(entry);
}
//方式三: 推荐
Collection<String> str = map.values();
for (String v:str) {
System.out.println(v);
}
}
}

-
迭代器:不能遍历map,他只能遍历Collocations接口下的
hashmap源码解析
参数解析:

通配符
在集合中常常遇到限制通配符的情况:
例如:List< ? extends A > : 可以将extends看成一个小于等于号,
也就是说A类的子类或自己可以赋值给List< ? extends A >
List< ? super A > : 可以将super看成一个大于等于号,
也就是说A类的父类(Object)或自己可以赋值给List< ? super A >

Collections
基本用法
public class TestCollection {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//向list添加数据
Collections.addAll(list,"ss","ee","ees");
//将list从小到大排序
Collections.sort(list);
//从list里面选择最大值
String max = Collections.max(list);
//从list里面选择最小值
String min = Collections.min(list);
//System.out.println(max+"--*--"+min);
//取数组下标
int temp = Collections.binarySearch(list, "ee");
//System.out.println(temp);
System.out.println(list);
// List<String> arrayList = new ArrayList<>();
//目的list>=被复制的list,否则会报Source does not fit in dest错误
// Collections.addAll(arrayList,"a","b","c","6");
// Collections.copy(list,arrayList);
// System.out.println(list);
//保证集合安全
Collections.synchronizedList(list);
}

